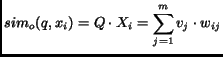 |
(7) |
where ![]() is the number of unique terms in the document collection;
is the number of unique terms in the document collection; ![]() is the frequency of a term
is the frequency of a term ![]() in the query
in the query ![]() ;
and
;
and ![]() is the document weight:
is the document weight:
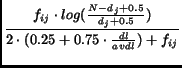 |
(8) |
where ![]() is the term frequency of a term
is the term frequency of a term ![]() in the document
in the document ![]() ;
;![]() is the total number of documents in the collection;
is the total number of documents in the collection; ![]() is the number of documents in the collection that contain the query term
is the number of documents in the collection that contain the query term ![]() ;
; ![]() is the length of the document (in bytes); and
is the length of the document (in bytes); and ![]() is the average document length in the collection (in bytes).
is the average document length in the collection (in bytes).
For reasons similar to the VSM method, the Okapi similarity
measurement cannot be applied directly in evaluating the precision of search
engines [20]. We need values for ![]() and
and![]() .
In our research, we estimate the values of
.
In our research, we estimate the values of ![]() and
and ![]() in the way described in the last section for VSM. In addition, the
average length of a Web document (
in the way described in the last section for VSM. In addition, the
average length of a Web document (![]() )
is estimated as to be 10,939 bytes after removing all the HTML tags and
Java scripts.
)
is estimated as to be 10,939 bytes after removing all the HTML tags and
Java scripts.