

Next:Okapi
Similarity Measurement (Okapi)Up:Combining
the HITS-based AlgorithmsPrevious:Combining
the HITS-based Algorithms
Vector Space Model (VSM)
The vector space model has been widely used in the traditional IR field
[11,12].
Most search engines also use similarity measures based on this model to
rank Web documents. The model creates a space in which both documents and
queries are represented by vectors. For a fixed collection of documents,
an 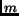 -dimensional
vector is generated for each document and each query from sets of terms
with associated weights, where
is the number of unique terms in the document collection. Then, a vector
similarity function, such as the inner product, can be used to compute
the similarity between a document and a query.
-dimensional
vector is generated for each document and each query from sets of terms
with associated weights, where
is the number of unique terms in the document collection. Then, a vector
similarity function, such as the inner product, can be used to compute
the similarity between a document and a query.
In VSM, weights associated with the terms are calculated based
on the following two numbers:
-
term frequency,
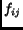 ,
the number of occurrence of term
,
the number of occurrence of term 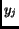 in document
in document 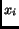 ;
and
;
and
-
inverse document frequency,
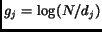 ,
where
,
where 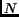 is the total number of documents in the collection and
is the total number of documents in the collection and 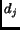 is the number of documents containing term .
is the number of documents containing term .
The similarity 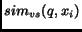 ,
between a query
,
between a query 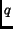 and a document ,
can be defined as the inner product of the query vector
and a document ,
can be defined as the inner product of the query vector 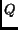 and the document vector
and the document vector 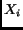 :
:
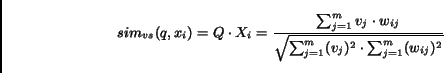 |
(5) |
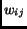 and query weight
and query weight 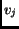 are
are
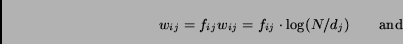
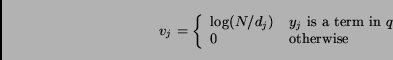 |
(6) |
Due to the dynamic nature of the Web and inability to access the whole
Web, the VSM method cannot be applied directly in evaluating the
precision of search engines [20]. In Equation
(5), the inverse document frequency 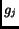 is not available because
and
are often unknown for the documents on the Web. There are three ways to
deal with this problem: (1) making simple assumptions such as
is a constant for all the documents [22];
(2) estimating parameter values by sampling the Web [1];
and (3) using information from search engines, or/and experts' estimation.
In this paper, we use a combination of the second and third approaches.
is not available because
and
are often unknown for the documents on the Web. There are three ways to
deal with this problem: (1) making simple assumptions such as
is a constant for all the documents [22];
(2) estimating parameter values by sampling the Web [1];
and (3) using information from search engines, or/and experts' estimation.
In this paper, we use a combination of the second and third approaches.
To apply VSM to the Web, we treat the Web as a big database and
estimate the parameter values of VSM. To estimate ,
we use the coverage of Google because Google is the search
engine with the largest size, which contains about 1 billion pages in August,
2001 as reported in [24]. But because
Google uses link data, it can actually achieve a larger coverage of over
1.3 billion pages. Thus, we set 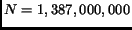 which is the number of pages in
Google's index. To estimate ,
the number of documents containing a certain term ,
we use information extracted from several search engines as follows:
which is the number of pages in
Google's index. To estimate ,
the number of documents containing a certain term ,
we use information extracted from several search engines as follows:
-
Submit the term
to several search engines (we use five search engines in our experiments).
Each search engine
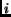 returns
returns 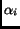 ,
the number of documents containing the term.
,
the number of documents containing the term.
-
Calculate the normalized value
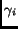 for each search engine ,
based on
and the relative size (
for each search engine ,
based on
and the relative size (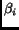 )
of the search engine to that of the whole Web:
)
of the search engine to that of the whole Web: 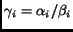 .
The sizes of the five search engines, AltaVista, Fast, Google, HotBot,
and NorthernLight, used in our experiments are 550, 625, 1000, 500,
and 350 million documents, respectively, as reported in previous studies
[24]. Since the total size of the Web
is estimated to be about 1.387 billion documents, the relative sizes ()
of these search engines are 0.397, 0.451, 0.721, 0.360, and 0.252, respectively.
.
The sizes of the five search engines, AltaVista, Fast, Google, HotBot,
and NorthernLight, used in our experiments are 550, 625, 1000, 500,
and 350 million documents, respectively, as reported in previous studies
[24]. Since the total size of the Web
is estimated to be about 1.387 billion documents, the relative sizes ()
of these search engines are 0.397, 0.451, 0.721, 0.360, and 0.252, respectively.
-
Take the median of the normalized values of the search engines as the final
result.
After getting the values of
and , 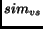 can be easily computed.
can be easily computed.
Next:Okapi
Similarity Measurement (Okapi)Up:Combining
the HITS-based AlgorithmsPrevious:Combining
the HITS-based Algorithms
2002-02-18