

Next:Three-Level
Scoring Method (TLS)Up:Combining
the HITS-based AlgorithmsPrevious:Okapi
Similarity Measurement (Okapi)
Cover Density Ranking (CDR)
Instead of computing the relevance based on term appearance, such as
VSM,
other methods including CDR are based on the appearance of phrases.
CDR is developed to meet user expectation better - a document containing
most or all of the query terms should be ranked higher than a document
containing fewer terms, regardless of the frequency of term occurrence
[25]. In CDR, the results of phrase
queries are ranked in the following two steps [7]:
-
Documents containing one or more query terms are ranked by coordination
level, i.e., a document with a larger number of distinct query terms ranks
higher. The documents are thus sorted into groups according to the number
of distinct query terms each contains, with the initial ranking given to
each document based on the group in which it appears.
-
The documents at each coordination level are ranked to produce the overall
ranking. The score of the cover set
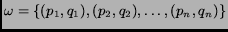 is calculated as follows:
is calculated as follows:
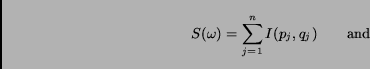
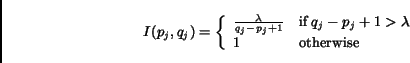 |
(9) |
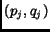 is an ordered pair over a document, called cover, specifying the
shortest interval of two distinct terms in the document [7].
is an ordered pair over a document, called cover, specifying the
shortest interval of two distinct terms in the document [7]. 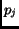 is the position of one term,
is the position of one term, 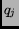 the position of another term, and
is assumed to be larger than .
the position of another term, and
is assumed to be larger than . 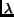 is a constant and is set to 16 in our experiments because it has been shown
to produce good results [6]. Covers of
length
or shorter are given score 1, and longer covers are assigned scores less
than 1 in proportional to the inverse of their lengths.
is a constant and is set to 16 in our experiments because it has been shown
to produce good results [6]. Covers of
length
or shorter are given score 1, and longer covers are assigned scores less
than 1 in proportional to the inverse of their lengths.
To adapt CDR to the Web, we need to find out how many distinct query
terms a document has and rank the documents with more distinct terms higher.
Our version of CDR method computes the relevance scores of documents
in two steps:
-
Documents are scored according to the regular CDR method. Each document
belongs to a coordination level group and has a score within that group.
-
The scores are normalized to range (0, 1] for documents containing only
one term, to range (1, 2] for documents containing two different terms,
and so on, so forth.
The benefit of this method is that it not only considers the number of
distinct terms in a document, but also how these distinct terms appeared
in the document, such as how close they are.
Next:Three-Level
Scoring Method (TLS)Up:Combining
the HITS-based AlgorithmsPrevious:Okapi
Similarity Measurement (Okapi)
2002-02-18