
Kazunori Horikiri, Shigehisa Kawabe
Document Engineering Lab., Fuji Xerox Co., Ltd.
430 Sakai, Nakai-machi, Ashigarakami-gun,
Kanagawa 259-01, Japan
{horikiri,kawabe}@rsl.crl.fujixerox.co.jp
This paper describes a method to construct Web pages from heterogeneous distributed objects using a generalized name resolution mechanism. In order to extract and process information from the Web space on users' demands, each user has to collect heterogeneous and ill-fitting Web pages and process them on a local environment. This is because the locating and processing of the Web pages are separated in the Web environment. However, users wish to access specific information on their demands by specifying URL or filling values in forms without additional processing. It is also desired to give a global identifier to the specific processed page in order to re-utilize information among users. Moreover, it is desired that users can utilize various resources and methods for processing provided in a distributed environment as well as the Web pages. Therefore, we need a mechanism that composes such Web pages from heterogeneous Web pages with appropriate processing in a distributed environment by specifying a identifier, URL. We name these composed Web pages virtual Web Pages and URLs of these pages virtual links .
We have built HTTP Context Object Server based on a name resolution mechanism to ease the task of constructing virtual Web pages which meet users' demands. The HTTP Context Object Servers act as HTTP servers and co-operate to interpret virtual links and serve the corresponding virtual Web pages in a distributed environment. In this connection, virtual Web pages can be designed to include the links to other virtual Web pages that reflect users' demands. A set of these virtual Web pages compose User Oriented Web Space.
- Keywords
- name resolution, naming context, name server, HTTP, Web Space
Requirements to design an architecture of User Oriented Web Space are as follows;
For the Web environment, Brooks et al.[5] have developed HTTP Stream Transducers OreO in a distributed environment,which is an answer to the request described above.
OreO is placed between a HTTP server and a client as a HTTP Proxy server.It acts as a transducer of the HTTP stream in an application-specific way.
However, users can not customize the post-processing of objects freely for their purpose in a distributed environment such as the Internet.
It is because no framework is available for end users to connect processing components to get desired objects in a distributed environment.
In addition, it is difficult to share the connected objects with other users in a widely distributed environment.
And it is also difficult to give the identifier to the composition and customize the composition.
To solve these problems, we introduce a framework to compose objects and give them global identifiers by providing generalized naming context that interprets the identifiers.
The basic idea is to give an implementation of an object in naming contexts using existing distributed objects as raw materials.
Naming contexts act as distributed components, and they are connected to compose a object in a name resolution.
Methods of each naming context are invoked in the process of name resolution and implement a virtual Web page.
The first advantage of using naming contexts is that it does not require any changes in the conventional applications such as Web browsers, because the access to the virtual Web pages is accomplished by specifying the name of the virtual Web pages in the same way as the present way.
Another advantage is that users are not imposed the information in the providers' way to manage and export their various objects. Virtual objects can be accessed in the way of users' demands, which may be in their most suitable protocol, content type, aggregate and links with desired web pages. Any user can implement own virtual Web pages which include arbitrary links to naming contexts representing individual standpoints.
The distributed computing environment consists of a set of objects.
Each object communicates with other objects only at its ports
[8].
Each port is labeled and distinguished within the object.
And each port is connected to a port of another object.
Communication is accomplished by sending and receiving a message at a pair of ports synchronously.
Ports are denoted by the blobs in Figure 1.
A name is defined as a string which is a sequence of symbols and used as a message to identify an object.
We don't distinguish human-oriented names from system-oriented names.
From this, we uniformly treat path names of conventional file systems, two dimensional positions on some images and network addresses.
Some objects have ports which are connected to some special objects which interpret names.
By sending names at these ports, objects cooperate to resolve a route to the named objects.
These objects which interpret names are called naming contexts or simply contexts.
Because, all names are defined and interpreted relative to naming contexts,we have to treat each name with its naming context.
We call a pair of a port and a name, where the port is bound to a naming context, as a qualified name [2].
If we restrict naming contexts to a class of deterministic, single threaded and synchronous request/reply objects,the behavior of a naming context C in a state s is defined by the following equations of process calculus[8].
Note: To simplify the notation, handling of the message body to pass objects is omitted.
| C(s) = recv(p, n).C3(p, qnames(n), trans(s, n)) | (1) |
| C3(p, list, s) = send(p, reply_in(s)).C(s), if s is in a final state set Sf or list is empty; | (2) |
|
C3(p, list, s) = send(f1(f1(list)), f2(f1(list))).recv(f1(f1(list)),r).C3(p, rest(list), trans(s, r)) otherwise
|
(3) |
where "." denotes a combinator to specify an action prefix, and fi denotes a selector function that returns the i-th component of a given list, and rest denotes a selector function that returns a given list excluding the first component.
send(p, m) and recv(p, m) denote the actions to send a message m at port p and to receive a message m at port p respectively.
The equation (1) describes that the context in a state s receives a name n at port p, and extracts a list of qualified names using function qnames and changes its state using function trans based on parameters included in the name n and then proceeds to behave according to the definition of C3.
The qnames,
denotes a look up function, where N denotes a set of names and * denotes a closure of concatenation, and P denotes a set of ports in the context.
The function qnames typically parses a given name and composes a parse tree and evaluates the tree to return a list of qualified names.
The trans,
denotes a state transition function, where S is a set of states and M is a set of messages.
The equation (2) describes that if the state s is in a final state set Sf or list is empty, the context sends a reply message based on the state s using function reply_in and then proceeds to behave according to the definition of C in the equation (1).
The function reply_in,
denotes a reply generating function, which typically composes a reply from the replies received at ports of qualified names.
The equation (3) describes that the context sends a name at a port of the first qualified name in list, and receives a reply at the port, and changes its state using trans based on the reply, and then proceeds to behave according to the definition of C3.
For example, suppose a context CNT0 in Figure 1 behaves as an object selector and see how it resolves a name.
CNT0 looks up a head part of a path name to get a list of ports, and sends the rest of the path name at the ports.
Suppose CNT0 receives a path name name1/name2 at the port p00 and has a mapping from name1 to a list of ports (p01, p02).
The context CNT0 parses a path name name1/name2 and composes a parse tree (name1, name2).
Then CNT0 evaluates the tree using the mapping from name1 to ports and composes a list of qualified names ((p01, name2), (p02, name2)).
The context CNT0 sends name2 at the port p01.
As a result, the context CNT1 receives name2 at the port p10 and eventually sends reply R1 at the port p10.
The context CNT0 receives reply R1 at the port p01 from CNT1.
Next, CNT0 sends name2 at the port p02.
The context CNT2 receives name2 at the port p20 and eventually sends reply R2 at the port p20.
CNT0 receives reply R2 from CNT2 at the port p02.
The context CNT0 tests replies of R1 and R2, and selects R2 based on some algorithm, then sends R2 at the port p00.
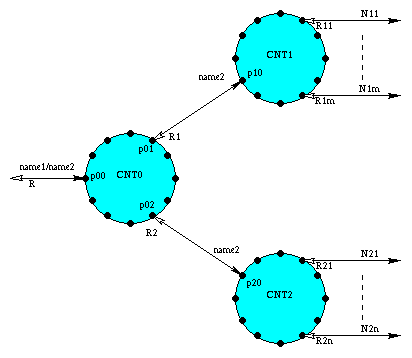
Figure 1: Name Resolution Tree through the Naming Contexts
By using this model as a naming context;
We mapped each context object to a HTTP object, HTTP context object.
Each HTTP context object implements HTTP methods and these methods are used for name resolution.
While we used single threaded naming contexts as a formal model, we don't impose the restriction on the HTTP context objects.
That is, each HTTP context object can handle multiple requests concurrently, and handle recursive name resolution as well.
As for the mapping of the qualified name to specify the port and name, a URL of a HTTP object is to be resolved into a route to a port of the HTTP object through the underlying system naming contexts, so we can use a URL as a label of the port connected to the context object.
Therefore, the pair (URL, name) can be regarded as a qualified name.
By the way, a set of names which a naming context accepts forms a language.
Besides the resolution of names, to get a language of a naming context is also important for users.
For example, each directory of conventional file system has a language of file names and interface to tell its language by listing each name.
In the same way, HTTP context object exports the HTML page including URLs which are to be resolved by the context.
If the language of names is a small finite set, listing each name is a proper method.
However, in a case of expressing a language of a infinite set or a huge finite set, some notation of grammar have to be introduced.
As an experimental way to handle these cases, we made a choice that context objects export their languages as pages of fill out form with some annotations about the grammar.
As a result of using a fill out form to express a language, we naturally use the coding scheme of query string[3] for names.
Therefore, a qualified name is expressed as "url?name", where "url" is a URL of the HTTP context object and "name" is a string for the naming context in the coding scheme of query string.
This type of name acts as a virtual URL or a virtual link and is interpreted by the HTTP context object.
As shown in Figure 2, HTTP context objects are implemented in a HTTP Context Server.
We used CERN HTTP server as a base for HTTP Context Server.
And we used CGI programs written in PERL and C to implement HTTP context objects.
Therefore, each HTTP context object is allocated as a process on the request to the context and deallocated after the reply.
Multiple processes are allocated for the concurrent requests to the same HTTP context object.
File system is used to share the state between concurrent requests or to save the state beyond the lifetime of the process.
For the purpose of sending messages to objects other than HTTP objects, we have implemented HTTP context objects that converts naming scheme and object manipulation protocols.
This type of context object acts as a protocol gateway.
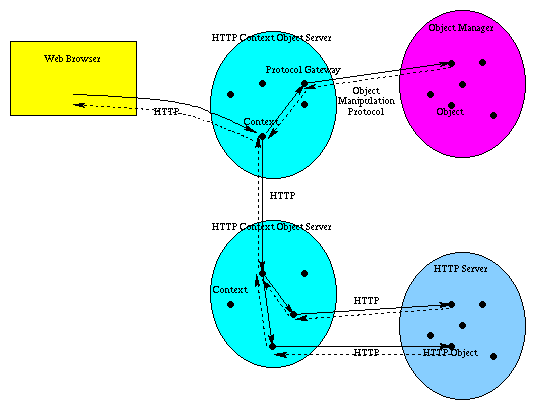
Figure 2: HTTP Context Object Server
Note: Parenthesized parts denote escaped query strings and are left unescaped for readability.
Each user constructs a composite URL filling values and URL from bottom to up along the tree structure of the URL. A composite URL is resolved through a distributed tree of HTTP context objects.
We have built several table manipulating objects. These objects are intended to demonstrate how end users construct component objects to extract and view information from tables in a distributed environment.
Suppose hard drive Company 1 and Company 2 export data sheets of their products on the Web. The data sheet of Company 1 has a table in which the attributes of each product are aligned in rows. The data sheet of Company 2 has two tables in which the attributes of each product are aligned in columns. The attribute set of Company 1 is different from the set of Company 2. Suppose we are interested in some attributes common in these two attribute sets. Both tables contain the URLs of pages of detailed specifications. In this case, both Company 1 and Company 2 intend to present their products to the customer on the Web pages of static tables.
User constructs a composite URL in the following steps.
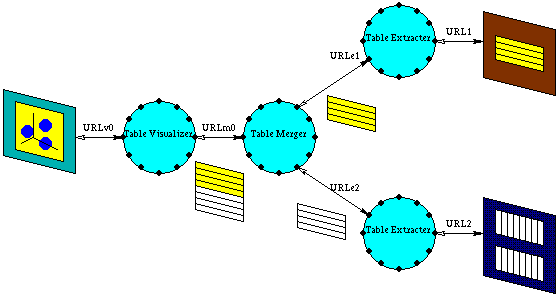
Figure 3: Name Resolution Tree for 3 Dimensional Viewing
In this example, the name resolution is performed in the following steps as shown in Figure 3.
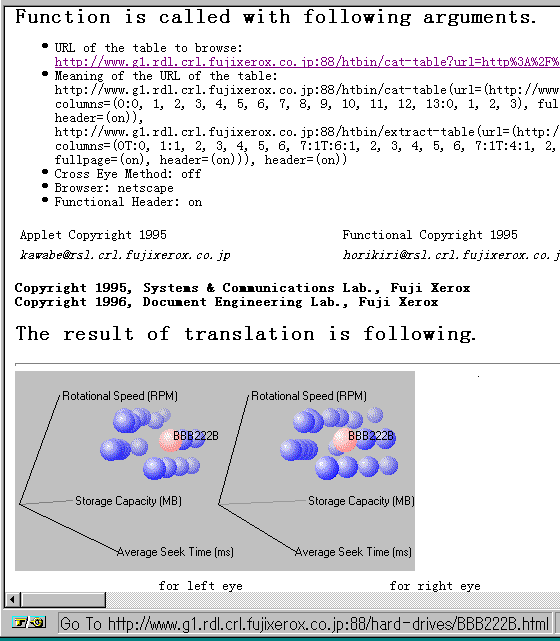
Figure 4: Page Composed by the Table Visualizer
The Figure 4 contains parameters including the URL of the Web table, the long URL shown below the line of "URL of the table to browse:" denotes a qualified name. By following the URLs indicating qualified names, users can navigate along the distributed name resolution tree.
In addition, 3D viewer page contains URLs which refer to the detailed specification pages attached to the balls. The presentation style of the Web space on this page is very different from the style of the original pages exported by the Company 1 and Company 2.
The summary of the abilities shown in this example are as follows;
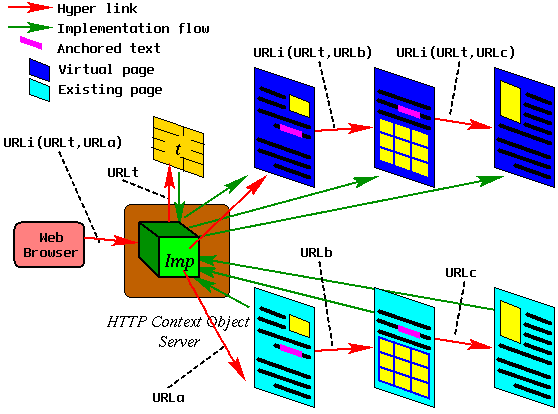
Figure 5: Converted Web Space
In Figure 5, Imp denotes a HTTP context object for contents conversion.
Imp is referred to as URLi.
Imp interprets a pair of (URLt, URLx) as a name.
URLt is for a Web page which contains word-to-word translation rules as a table t.
The table t consists of tuples < Regexp, Regexp >
, where Regexp denotes a regular expression.
Imp generates a virtual Web page URLi(URLt,URLx) from two raw pages, URLt and URLx, using a simple word translator that applies each rule in the table t to the page of URLx.
Imp serves converted Web pages that include
composite URL of URLi(URLt,URLy), where URLy is extracted from the raw pages of URLx.
Take note that the virtual Web page of URLi(URLt,URLa) shown in Figure 5 includes a virtual link URLi(URLt,URLb) instead of URLb.
If Imp is designed to change all or some links such as URLy to URL(URLt, URLy), the pages referred from the page URLi(URLt,URLx) will be modified and inherit some characteristics from the starting page, which acts as the entrance to such converted Web space.
One of the future work is to make the naming context more practical. We identified several areas on our naming context approach to provide user oriented Web spaces as follows;