David Eichmann
Repository Based Software Engineering Program
Research Institute for Computing and Information Systems
University of Houston - Clear Lake
Houston, TX 77586
eichmann@ricis.cl.uh.edu
Achieving the holy grail of the paperless, Webbed office doesn't make your information management problems go away, it just shifts them from your physical desktop to your virtual desktop. The Web has proven to be an incredible boon to organizations trying to share information, but it comes with a price... keeping up with the information flow and accessing what you need without being forced into exploratory navigation. We discuss our work in Web-based repositories, involving support for multiple, collaborating servers presenting a seamless integration of both data and metadata.
Stuff. Everyone's got it. And increasingly, it's digital stuff - papers, images, video clips, news feeds, email, presentation slides, scanned faxes - you name it. Achieving the holy grail of the paperless, Webbed office doesn't make your information management problems go away, it just shifts them from your physical desktop to your virtual desktop. The Web has proven to be an incredible boon to organizations trying to share information, but it comes with a price... keeping up with the information flow and accessing what you need without being forced into exploratory navigation.
And that's what the Web is all about - access. Private search engines can ease some of the difficulties in access, but they don't do a very good job in a key dimension - they fail to provide a context for that search hit. Winnowing through hundreds or thousands (or millions!) of hits, either through brute force browsing or through trial-and-error search respecification, still leaves a significant comprehension burden on the user. The utility of 'pathfinder' pages (human maintained directories of links relevant to a given subject) provides support for this perspective; if search engines performed as well in this regard, people would not go to the effort of creating and maintaining these pages. Yahoo is a particularly visible example of this can be carried.
Our previous work on the MORE repository [1] focused on supporting librarian teams in the creation, maintenance and evolution of Web-based repositories of metadata about Web artifacts. It supported distributed, fine-grained librarian privileges and the ability to restrict access to portions of the repository to only members of defined groups. Hence, it was technically capable of supporting a large organization in their information management activities. However, this single server approach to repository architecture was not particularly organizationally aware [2], in that it required the various components of an organization to integrate (and resolve conflicts regarding representation of) their information management requirements.
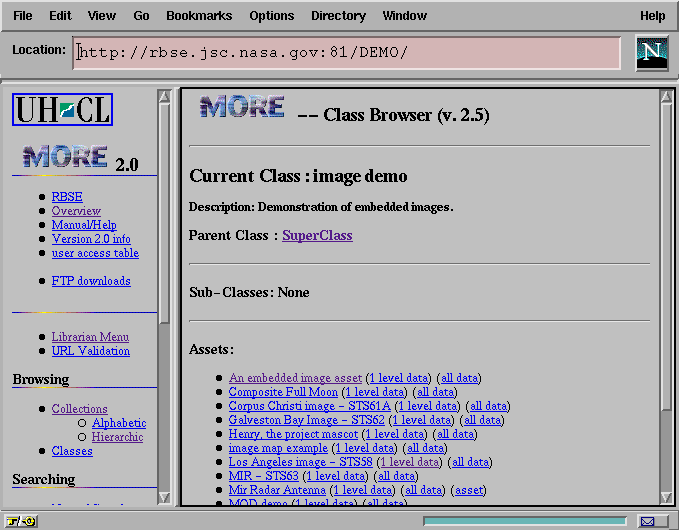
MORE version 1 supported two means of structuring a single information space. The class mechanism provided a means of shaping the metadata that MORE stored regarding an artifact, and the corresponding browser (Figure 1) provided a means of navigating up and down the class hierarchy and observing the instances of the class as sets of hyperlinks to homogeneous virtual pages. This interface provided access comparable to that provided by most object-oriented database systems.
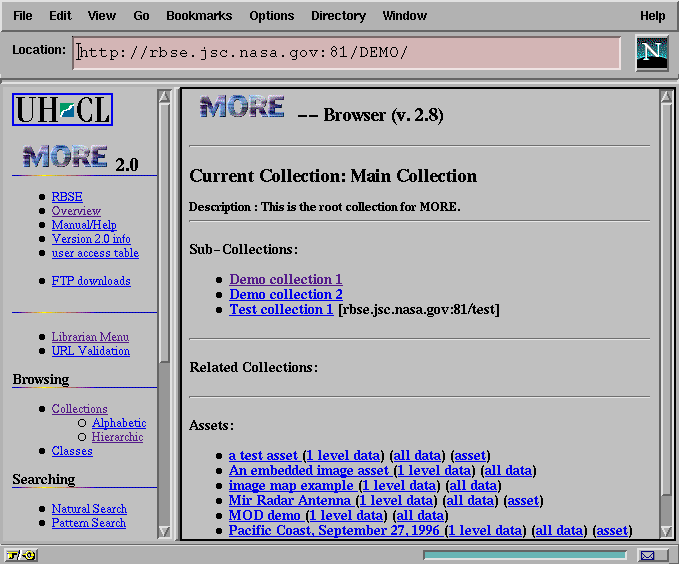
The collection mechanism allowed librarians to define a variety of organizing schemes, all rooted in a single main collection. A metadata instance was a member of one or more collections, as information management needs demanded; and the collections could be heterogeneous (i.e., the metadata instances of a given collection could be drawn from any number of classes). Figure 2 shows the main collection of our demonstration instance.
Navigating within the collection hierarchy simply involves clicking on a particular anchor on the virtual page. As can be seen in Figure 3, users can navigate both down and up the collection hierarchy.
What we soon discovered was that our user community frequently had a need for a much more autonomous, decentralized approach to information management, particularly in large organizations where there were very different policies at the team, division and corporate levels on what and where things should appear in a repository. The role that a repository plays with respect to a software development team - that of a shared collection of new and evolving artifacts - is very different than for a division - that of a collection of a stable, trusted collection of key intellectual property.
Hence a key requirement for MORE version 1 was the relaxation of the single storage site requirement found in version 1. We followed Neuman's virtual system model [3], which he had used to build a network-based virtual directory structure [4], to quite naturally extend our existing collection concept to support the existence of relationships with remote servers. We did not extend the class concept or mechanisms because of serious difficulties in coordination of inheritance and security requirements. The current implementation only supports 'public' access (i.e., non-authenticated access to the CGI executables) to the contents and structure of a remote MORE instance.
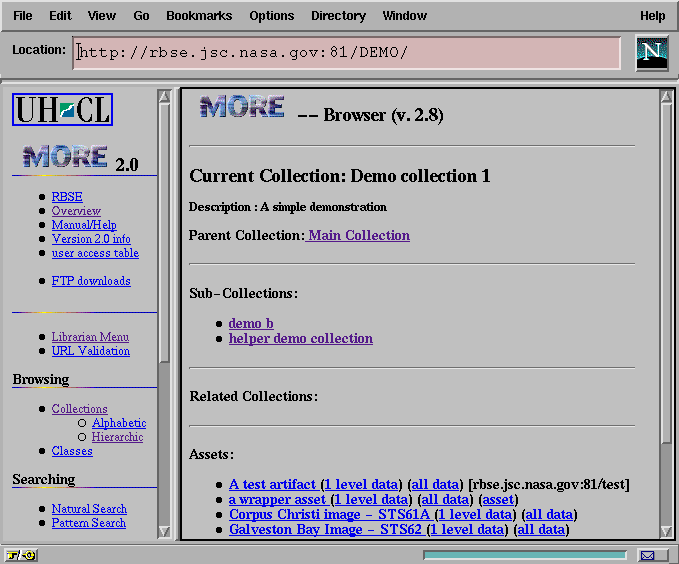
The first and most natural extension to the collection mechanism involved the ability to specify remote collections visible on another MORE server as subcollections and/or related collections for a given local server. This allows a librarian to reference existing collection hierarchies on other machines without the need to alter either the local or remote collection hierarchies to fit one or the other organizing approach. A user navigating down to a remote subcollection seamlessly transitions from one server responding to CGI requests to another server, without the need to know how the aggregate virtual repository is actually organized. Figure 2 shows an example collection containing two local collections and one remote collection. Note that remote collections are tagged with the remote server and MORE instance. We found that the integration was sufficiently seamless so as to confuse users as to which MORE instance they were currently interacting with, and subsequently, who questions regarding content should be directed to - hence the tagging.
Remote subcollections and related collections work well for top-down hierarchical delegation of repository structure, but they are not well suited for peer-to-peer forms of information sharing. We have used Neuman's notion of union and filter links to extend our collection concept with the notions of union collections, where the contents of a remote collection are treated as if they are part of the local collection, and filter collections, which extends the union collection notion with the ability to specify patterns that are used to match against artifact URLs to select only certain types of artifacts for participation as local collection artifacts. The demo collection in Figure x has such a relationship with a remote collection. Note again that the first asset in the list is attributed with the server and instance where it actually resides, in order to flag the origin of the artifact for the user.
Extending the relevance feedback search mechanism to support remote collections required modification only of the user interface code. An additional checkbox was added to the search specification form to allow the user to specify whether the search should cascade to remote subcollections or examine only local collections (Figure 4).
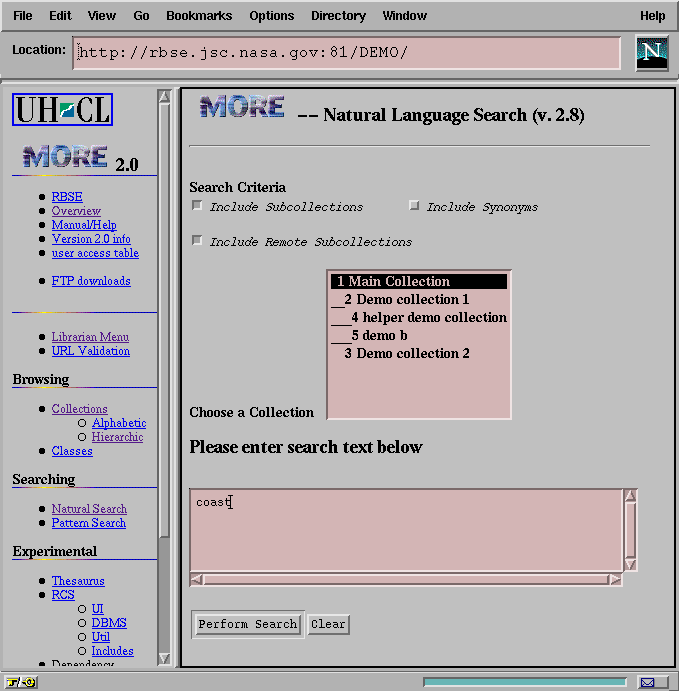
Figure 4: The Search Specification Page
In our initial approach, if the user selected the 'include remote subcollections' option, the locally executing search requested a remote search execution as if it was actually a Web browser, allowing the existing user interface to be used without modification. We have subsequently defined distinct entry points into the remote CGI interfaces, which rather than emitting HTML markup of the data, emit more easily interpretable, formatted data. This was done solely to improve the maintainability of the CGI-to-CGI interfaces, all other semantics are the same for user requests and MORE requests to a server instance.
To prevent cyclic cascades of search requests, the locally requesting search instance feeds a server - collection id pair to the remote search instance, along with any such server - collection id pairs that it was provided. The newly invoked remote search then checks for cycles in the chain of invocations and suppresses any further propagation of the search.
As mentioned above, we have added additional CGI entry points into the collection and search interfaces to customize the data emitted by the remotely invoked code. We have also added an application into our user interface suite to support the maintenance of the information regarding remote relationships. Only the specifying (i.e., local) MORE instance stores any information regarding remote collections. All changes to the database schema were limited to the addition of a single new table, RemoteCollections, shown in Figure 5.
CREATE TABLE RemoteColl ( Collection_ID NUMBER(38) NOT NULL, Host_Name VARCHAR(50) NOT NULL, Remote_Collection_ID NUMBER(38) NOT NULL, Node_Type VARCHAR(80) NOT NULL, Alternate_Name VARCHAR(80) );
Figure 5: The RemoteColl Table
The Collection_ID is for the local collection associated with this remote collection relationship. The Host_Name and Remote_Collection_ID together specify the remote server and MORE collection instance, while the Node_Type indicates whether it is a subcollection, related collection, union collection or filtered collection. The Alternate_Name field allows for local overriding of the remote collection name. A null here indicates that the remote MORE instance should be interrogated for the current name of the collection.
Another strong desire out of our existing MORE version 1 user base was to increase the representation ability of the repository with regards to the relationships that might exist between metadata instances. This ranged from a simple desire to indicate related instances without having to create related collection relationships to the wish to represent traceability across the software development life cycle. We accommodated these requests with the addition of two new attribute types for metadata, one-to-one and one-to-many, which support reference to a single or multiple instances of a class, respectively. When adding a metadata instance for a class that contains one or more such attributes, they are presented with a list of current instances of the appropriate class for a single or multi- select.
When a user then accesses the metadata instance through the UI_Metadata browser, any interobject link is presented as an anchor, with the referenced metadata title as the text of the anchor and an invocation of UI_Metadata on the referred instance as the URL (Figure 6). Users can then accomplish both inter-class and intra-class navigation of metadata instances in a manner very similar to that used to browse related collections.
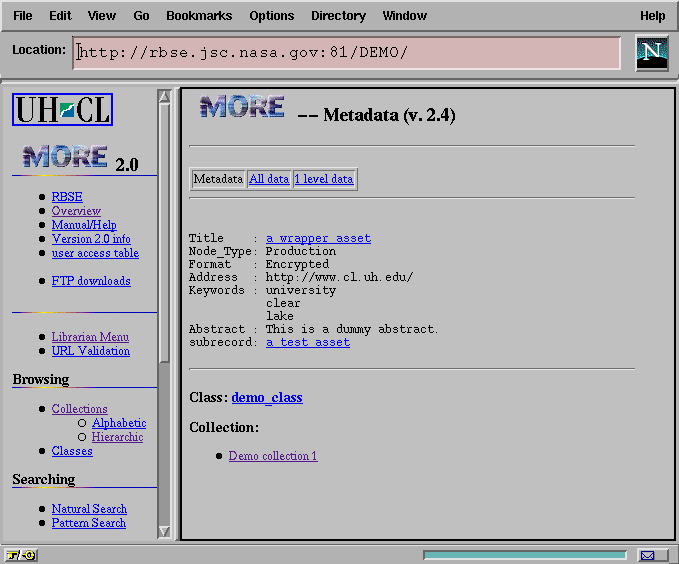
Figure 6: The Tabular View of Metadata with an Object Link
The provision for interobject linking within MORE version 2 lead rather naturally to the perspective that rather than always referring to external data through metadata, MORE was now increasingly data. With this shift came the opportunity to provide a more comprehensive scheme for presenting that data - in particular, the ability to create virtual pages from data/metadata that were completely encapsulated within the repository.
We accomplished this by an additional in the class definition structures to carry HTML tags for the various fields and adding a new user interface routine, called UI_Data, which was substantially similar to UI_Metadata, but which renders only the contents of a data/metadata instance, marked up with the HTML tags stored with the respective attribute definitions, as shown in Figure 7.
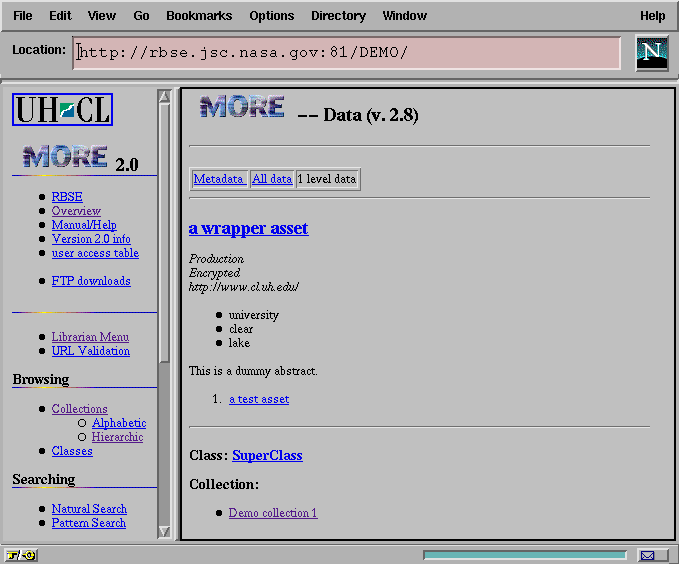
Figure 7: The Render View of Metadata with an Object Link
Clicking on the anchor for a referenced interobject link shifts the users focus to that instance, as shown in Figure 8. Note that in addition to the containing class and collection references at the bottom of the page, there is now also a referring object list, with back-links to any object that refers to this object with an interobject link. This has proven to be very useful in establishing the context for data/metadata instances that are returned out-of-context by a search request.
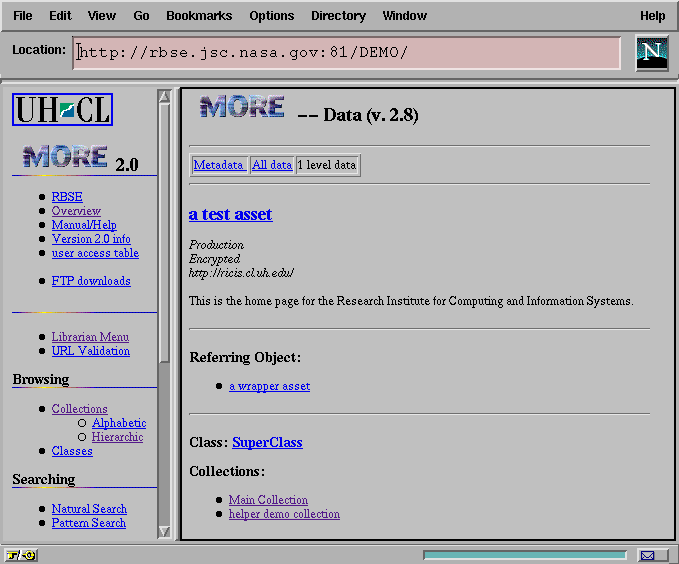
Figure 8: The Render View of a Referenced Object
UI_Data also supports an "all data" view, as shown in Figure 9, which traverses the interobject links for a given instance and constructs a single virtual page out of all referenced data/metadata instances. This has proven to be of particular interest to those users and librarians seeking to maintain dual views of instances, both singular (e.g., a specific requirements element) and aggregate (e.g., the entire requirements document), each with their own respective interobject relationships.
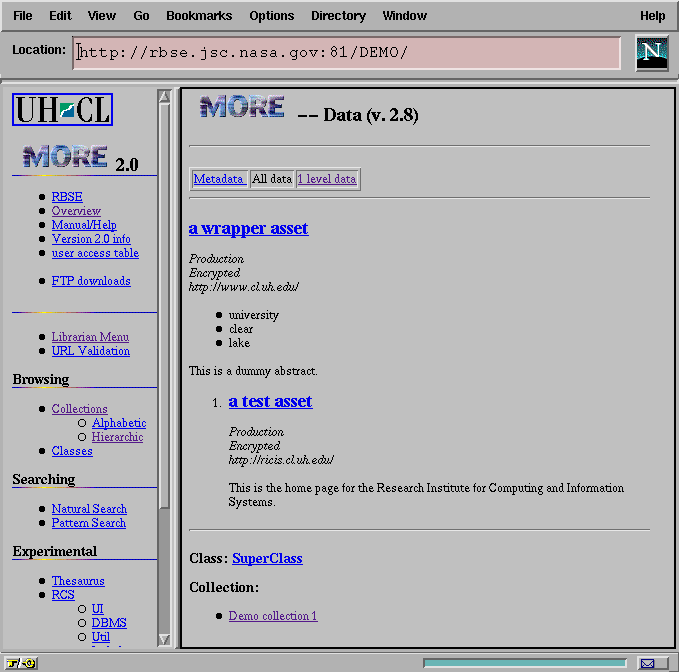
Figure 9: The Render All View of Metadata with an Object Link
By allowing IMAGE as one of the HTML tags used for UI_Data, we have also responded to that portion of our user base seeking to use MORE as a cataloging facility for imagery, etc. Figure 10 shows our original formatting of a metadata record which refers to an image of the California coastline at Los Angeles taken during Space Shuttle flight STS58. Note that the image field contains a URL referencing a JPEG file.
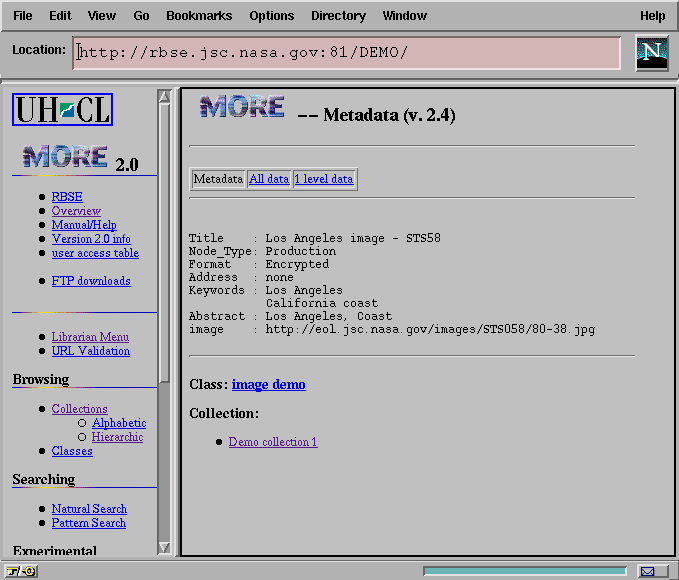
Figure 10: The Tabular View of Metadata with an Image Tag
Figure 11 shows the same metadata record displayed with UI_Data. Since the image field was tagged as IMAGE, UI_Data marks the field contents up so as to in-line the JPEG as part of the virtual page returned to the user.
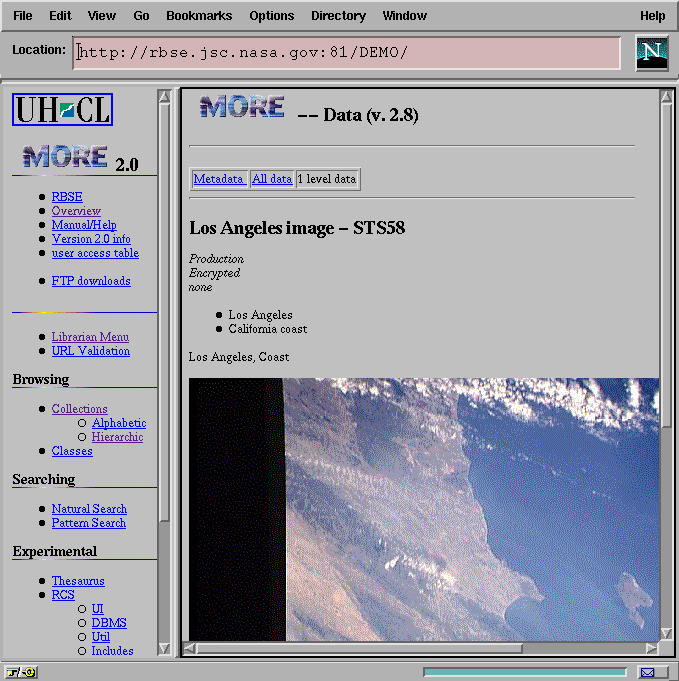
Figure 11: The Rendered View of Metadata with an Image Tag
As mentioned above, we added an entire new interface, UI_Data, to support rendered views, and altered UI_Metadata to crosslink to UI_Data, as well as to reinvoke itself on interobject links. UI_Data required adding a single additional field to the class definition tables to hold the HTML tag. Interobject linking required the addition of a new table, shown in Figure 12, to support the potentially multiple values referenced by a given object.
CREATE TABLE ObjectLinks ( Source_Class_Name VARCHAR(80) NOT NULL, Source_Object_ID NUMBER(38) NOT NULL, Source_SeqNum NUMBER NOT NULL, Target_Class_Name VARCHAR(80) NOT NULL, Target_Object_ID NUMBER(38) NOT NULL);
Figure 12: The ObjectLinks Schema
Figure 13 shows the result of the directory scan for a portion of the MORE source code.
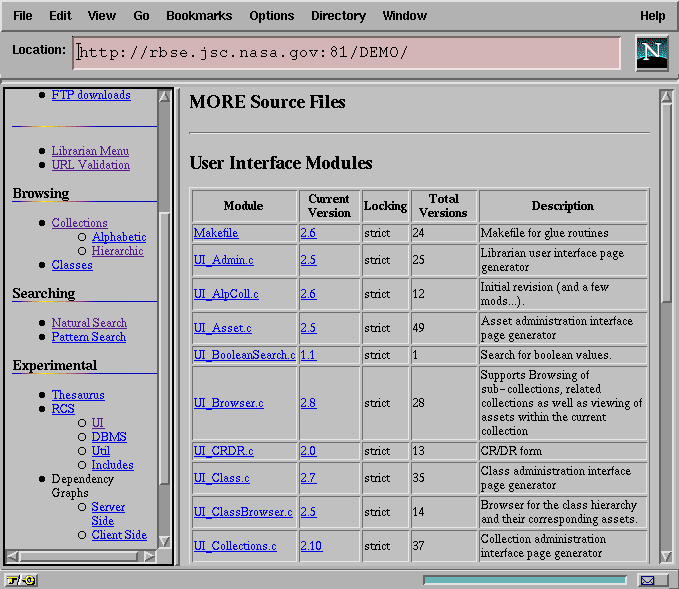
Figure 13: A Set of Artifacts Under Revision Control
This interface provides the general particulars regarding the artifact (a brief description, the number of revisions and the type of locking currently in use) and supports access to both the full revision history for the artifact (by clicking on the artifact name) and directly to the current version. The full revision history, as shown in Figure 14, provides particulars regarding each revision.
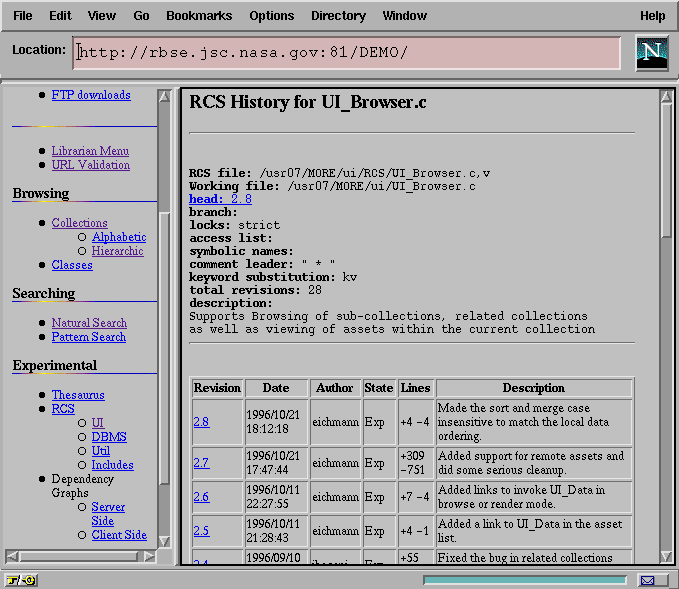
Figure 14: The Revision History for a Specific Artifact
An interesting requirement for the rendering of source code artifacts (Figure 15) is that the content must be massaged to prevent string literals containing HTML markup from actually rendering on the user's browser. Escaping the opening angle bracket by means of a filter proved sufficient to prevent this from occurring.
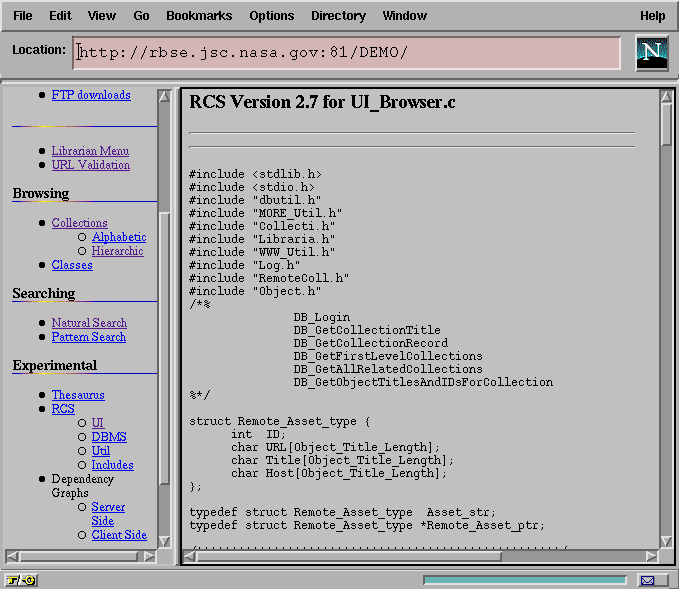
Figure 15: A Specific Artifact Version
Extending MORE version 1 with the ability to support interaction between multiple autonomous MORE instances and the ability to provide multiple user interface rendering alternatives proved to be surprisingly lightweight in terms of new and modified code. The major additions to the code base involved the newly defined UI_Data and the UI_RemoteCollection interface necessary to maintain the RemoteColl table. The code has proved to be quite robust as well, we've not received any serious bug reports for the extensions as yet, and expect that our previous experience with the stability of the system will not be changed with this revision.
A number of people have worked on MORE over its lifetime. Jim Helm, George Widerquist, Joseph Basani, and Gopal Tammareddy participated in the definition and implementation of version 2. Terry MacGregor and Dan Dannley were instrumental in our original conceptualization and realization of a Web-based repository (that became MORE version 1) back when browsers barely supported forms.
This work has been supported by NASA Cooperative Agreements NCC-9-16 and NCC-9-30, RICIS research activities RB-02 and RB-02a.