
Virtual Yahoo!
An Example of Virtual Access to Remote Web Catalogues
M. Angelaccio, S. Passiglia
Dip. di Ingegneria Informatica dei Sistemi e Produzione
Universita' di Roma "Tor Vergata"
Via della Ricerca Scientifica
00133 - ROMA (Italy)
angelaccio@utovrm.it
Abstract
We present the description of a WWW Information Retrieval system called Virtual Yahoo!
based on a Yahoo mirroring, i.e. a local copy of a subset of the remote Yahoo hypertext.
The aim is to access
the well known but overloaded WWW Catalogue in a virtual context, by extending
the memory virtual system organization to the Yahoo hypertext. The result is a tool that
may be considered
intermediate between a mirroring system and caching system able to
reduce the number of remote accesses.
The key issue is a page prefetching mechanism in cascade connection with
Search Engine answers. In particular the Virtual Yahoo! access depends on a
category fault event (analogous to the page fault event in
Virtual Memory Systems) that may occur in search engine answers.
This allows a virtual search process that simulates the hand procedure of
"loading a remote page-while browsing the local one".
1. Introduction
Subject tree catalogues (or A2Z lists) are an important alternative
to database search engines because categories are explicit.
The user can integrate local search engine queries with browsing steps.
The main disadvantage is the network traffic overload
that in most cases degrades the browsing efficiency.
For example Yahoo, which is considered the most diffuse Subject Tree
on the Web (see [Bray95]),
combines a wide thematic description with query capability
and as consequence it often registers high workload at the server site.
By remarking that (as pointed out by Denning [Den96])
the Web extends virtual memory to the world, it seems clear
the analogy with the inefficiency due to memory hierarchies.
In this case the slow-access level corresponds to the remote site,
whereas the local site might be considered as a fast-access level.
One of the most common internet solutions is mirroring
(e.g. sites mirroring internet services like software ftp and Usenet news).
However these mirroring sites are not based on a virtual schema
because they do not introduce a virtual level.
The local reference is explicit at every time for the user.
In addition, because new link are frequently added, it holds that
implementing a Yahoo mirroring like ftp mirroring
is practically impossible due to the growing size of the Catalogue.
Another solution is given by the caching techniques that locally
save the most recently visited pages to improve browsing efficiency.
However, the caching approach gives
fast access only for a very small subset of the remote hypertext.
To better motivate the implementation of Subject Trees
as a virtual system, we show two examples of remote Yahoo access
each giving evidence of
a strong relationship between network traffic conditions and time intervals.
- Netscape session example
- Table 1 shows the varying time accesses registered at different intervals by
a Netscape browsing session. It plots the remote page
loading time values that correspond to
three different accesses to Yahoo
(home, search and one remote category).
The measures are taken during three different periods from
an Ethernet-connected workstation of our university.
| day period |
Yahoo home (sec) | search (sec) |
remote category (sec) |
|---|
| 9.00-9.30 am |
4.6 | 28.2 | 30.5 |
|---|
| 12.00-12.30 am | 27.6 | 53.6 |
123.5 |
|---|
| 7.00-7.30 pm |
2.6 | 28.1 | 10.4 |
|---|
Table 1. Access time values for three Yahoo pages taken
during different periods
- Partial mirroring script example
- The second set of data has been obtained by taking the time values registered
from the execution of a mirroring script applied to a category subtree
composed of 20 remote pages.
This shows that subcategory mirroring is effective and it depends on a careful choice
of an uncongestioned period too.
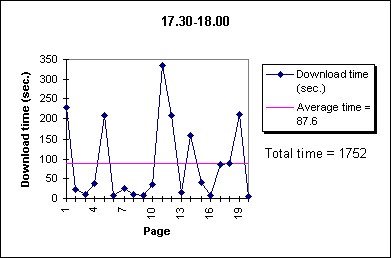
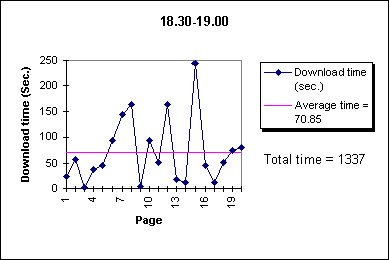
Figure 1. Access Time Values for a Sequence
of 20 Yahoo pages taken during different periods
The proposed solution, named VirtualYahoo!, aims to maintain a local copy by
offering the capability to virtually access such a well known (but overloaded)
Catalogue. The main issues are the following ones:
- a local hypertext that mirrors a subset of the Yahoo hypertext;
- an embedded search engine, that provides a transparent reference to the
local/remote hypertext.
2. Virtual Yahoo Organization
Fig. 1 shows the architecture of the system with its components.
The goal is to furnish a tool that allows the user to access
Yahoo without taking care of network traffic conditions.
This has been obtained by distinguishing between local hypertext searching
and mirroring operations that automatically update a part of the local hypertext.
It is composed as follows:
- Local hypertext that partially mirrors Yahoo. To keep disk storage at a
minimum, mirroring has been done according to the following criteria:
- the hypertext to be mirrored is restricted to
a main subcategory (e.g. Computers_and_Internet);
-
the tree is pruned of all external subcategories links
(like Business_and_Economy).
- Local search engine based on a category fault mechanism
(analogous to page fault mechanism) that allows remote page prefetching.
- Mirroring agent that is responsible for remote page loading.
Its main purpose is to guarantee a suitable consistency of local hypertext copy in an efficient way.
Consistency is not obtained for all Yahoo documents, but is restricted to documents close
to the ones containing answers matching a user query.
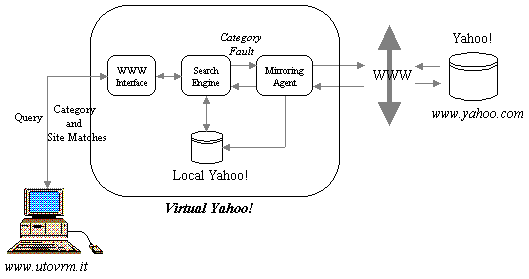
Figure 2. Virtual Yahoo! Organization
To force the user to keep his/her searching close to local copy,
a frame based interface has been adopted.
The idea is to furnish a separated index frame for the hypertext documents showing
a tree-oriented view of local categories by using a Java applet
communicating with the search engine and mirroring agent.

Figure 3. Example of Java-Frame Based HTML Interface
3 Virtual Subject Tree Searching
Differently from database search engines, Subject Tree searching
is characterized by a mixture of
query submission and browsing through category links,
with the aim of refining previous answers.
This type of searching is a trial and error process.
For instance let us consider the following example of a Yahoo searching session.
The user submits a query given by the keyword
"ATM" or "Hardware", and the returned answers are the following
(we restrict answers to the first two):
The displayed answers correspond to
- a link matching ATM as a subcategory in category \Communication&Networking
- a link matching ATM and Hardware as a site in category \Communication&Networking\Intranet
After visiting link1 (subcategory match) and link2 (site match),
the user can decide whether to contact the Yahoo
"\Communication&Networking\Intranet" category again for better answers.
This can be regarded as a category completion
browsing process carried out from the user in order to better satisfy her/his needs.
The problem is the cost due to network congestion
because proxy caching servers are not able to support
such user actions.
The virtual approach gives the opportunity to organize a form of prefetching
for all pages that could be visited in the future.
The pages that must be loaded can be chosen in correspondence with the type
of resulting answers, thus automatically starting remote page loading
independently from user actions.
Note that a practical example of such behaviour
is given by the well-known technique of
"opening a new browser-window on the remote site while continuing to browse".
The main question is now:
how to utilize the
answers returned from search engine for
choosing the pages to be prefetched?
To this purpose, in analogy with virtual memory systems,
the notion of Category Fault event is introduced.
This acts as the Page Fault event for virtual memory systems.
Instead of an "out-of-cache" reference, there are a set of ("potential")
out-of-LAN references.
To be more precise, recall the (ATM,Hardware) query example.
From the answer given by the link1, a
Category Fault event associated with the "Communication&Networking"
category may be derived. In fact this answer has no matches for the keyword
"hardware". In this case to support future references to those categories that
are missing in the local hypertext, a category completion process
for the "Communication&Networking" category occurs.
Basically, such a category completion process allows
remote access avoidance from the user, by accomplishing the following actions:
- reloading of the "\Communication&Networking\Intranet" category. This
operation gets all links that are missing in the local copy
from remote server ( update by
subcategory completion);
- partial mirroring of the remote
"\Communication&Networking" category. This has been obtained
by taking as links to be mirrored
all the ones resulting from a query refinement automatically submitted
to remote Yahoo server (update by search refinement).
4. The Current Virtual Yahoo Effort
The Virtual Yahoo! system is being developed
at the site http://www.ce.utovrm.it/mirror.
A prototype with user interface and an example of Yahoo mirroring
has been implemented. For the creation of the local hypertext,
a software module of the BOTH project [Ang96] has been used.
The implementation of the search engine and mirroring agent
is still in progress but a demo exists at (http://www.ce.utovrm.it/mirror/w6demo.html) that shows
the layout of the html interface with the Java class that implements
the dynamic tree index visualization.
Another issue to be developed is
the introduction of a network congestion analysis tool able to support remote accesses.
The purpose is to estimate the best network bandwidth
before accessing the remote site.
There exists a great deal of effort for network bandwith estimations.
However, Virtual Yahoo! is characterized
by a sequence of remote accesses carried out from the mirroring agent.
Hence, a good level of efficiency requires the
ability to predict the available bandwith in the future.
As pointed out by ([Car96]) this question remains open
and it will be a topic of future investigations.
5. Other Sources
There is an increasing interest on the Web for caching/mirroring tools.
- The idea to have page prefetching, driven from user actions, has been introduced in Letizia ([Li95])
that make use of AI techniques to model user behaviour.
- A few public domain scripts for WWW mirroring exist (e.g. the w3mir
Perl package). But as noted by [Kov96], the topic is in a somewhat premature state
according to the evolving needs of the Internet society.
References
[Ang96] M. Angelaccio, L. Zamburru, D. Genovese,
BOTH:Cooperative Automatic Web Navigation with Hierarchical Filtering,
AusWeb96 conference July 1996
http://elmo.scu.edu.au/sponsored/ausweb/ausweb96/tech/
[Bray95] T. Bray,
Measuring the Web,
Fifth International World Wide Web Conference,
May 6-10, 1996, Paris, France
http://www5conf.inria.fr/fich_html/papers/P9/Overview.html
[Car96] Robert L. Carter, Mark Crovella
Measuring Bottleneck Link Speed in Packed Switching Network,
Technical Report CS Dept. Boston University, BU-CS-96-0006, March 15 1996
[Den96] Peter J.
Denning, Virtual Memory,
ACM Computing Surveys , Vol. 28, No. 1, March 1996
[Li95] H. Lieberman, Letizia: An Agent That Assists WebBrowsing,
Proceedings of AAAI 95 - AI Applications in Knowledge Navigation and Retrieval,
MIT Cambridge MA, USA, 1995, pp. 97 - 103
[Kov96] L. Kovacs Caching and Mirroring Techniques in WWW and Digital Library
Architectures,
ERCIM news 96, No.27, October 1996
http://www-ercim.inria.fr/www-ercim.inria.fr/publication/Ercim_News/enw27/kovacs.html
Return to Top of Page
Return to Posters Index