
To present relevant information to users, more and more applications on the World Wide Web are using personalization techniques. Such methods require Web providers to manage and store user profiles. The most common architectures for personalized Web applications are to store the user profiles either at the server or at the client (browser). Both architectures have advantages and disadvantages, but neither can at the same time support the "collaborative filtering" personalization technique and the sharing of user profiles between different applications. Furthermore, programmers do not get the benefit of a standard environment for developing personalized applications. We therefore introduce the concept of a user profile management agent and locate it at a Web proxy. Our proxy manages and stores the user profiles and mediates the communications between the users and the Web servers. This not only relieves the personalized servers from the tasks of user profile management but also makes it possible to provide support for advanced personalization techniques such as collaborative filtering. The effectiveness of the proposed architecture has been demonstrated by a prototype of the proxy and by two implemented applications.
Keywords:
personalization, user profile, proxy, agent, HTTP
Although the World Wide Web is without doubt the widest source of electronic information, it lacks effective tools for retrieving, filtering, and displaying the information that each user needs. And as the size of the Internet keeps increasing, the task of retrieving useful information keeps becoming more and more difficult and time consuming.
To meet the growing demand for seeking tools, several Web sites already offer general search engines which, given a combination of keywords, provide a list of hypertext links potentially matching the user's interest (Lycos [1], Yahoo [2], AltaVista [3], etc.). Web applications that extract relevant information can be built on the top of these search engines, but such applications can only produce satisfying results if the targeted information can be characterized by a combination of keywords.
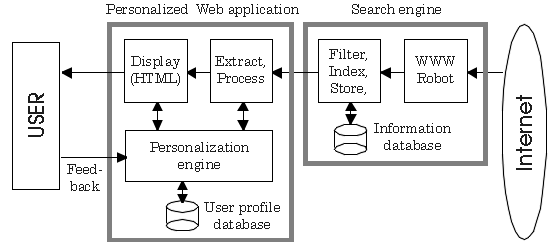
We think that many Web applications will, as a next step, adopt a personalization architecture (Fig. 1) and provide services that suit the interest of the user as an individual or as a member of a group. The Krakatoa Chronicle [4] is a prime example of what can be achieved when using the "content-based filtering" personalization technique. The layout of this electronic newspaper is personalized (the most interesting articles are displayed first) according to a user profile that reflects the user's interests. By scoring articles, the user provides a feedback that enables a learning engine to regularly update the user profile to reflect the changes of the user's interest. The popularity of other personalized Web applications such as Crayon [5], PowerStart [6], and PointCast Network [7] suggests that personalization techniques have a bright future.
In this paper we propose an architecture
that provides support for personalized Web applications. The proposed
user profile management agent relieves the Web applications from
the tasks of managing the user profiles and facilitates the use
of advanced personalization techniques. To demonstrate the effectiveness
of this architecture, we have implemented the agent as a user
profile management proxy and have built two applications using
its services.
Although there is no standard definition
of a personalized application, for the purposes of this paper
we consider a personalized application to be one that requires
data specific to an individual or a group. A personalized application
uses a user profile to offer a service that is not identical
for all users, but that is tailored to suit the individual user's
preferences or interests.
The most common way to use a profile
is to store information that enables personalization on an individual
basis (Fig. 2A). Included in this category is content-based filtering
which, applied to a textual document, evaluates the document's
relevance by matching the keywords contained in a user profile
with the keywords extracted from the text [8].
On the Web, the most efficient location for storing this type
of information is at the server so the user profiles do not have
to be transmitted through the network.
Social or collaborative filtering [9]
is another effective way to take advantage of user profiles. This
method collects the user profiles of a group of people and generates
recommendations based on the similarities of the profiles (Fig.
2B). To implement collaborative filtering, the profiles of all
users must be compared - and therefore the best storage location
is also to centralize them at the server.
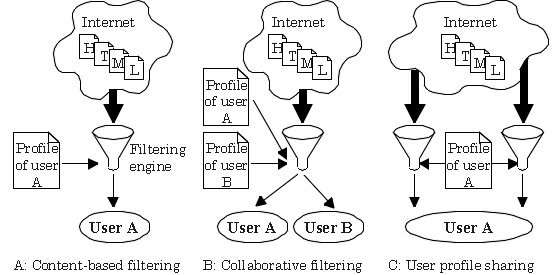
A user profile can also be shared
between different personalized applications that require the same
user profile's
content (Fig. 2C). For example, two providers of personalized
newspapers can collaboratively contribute to the building of a
user profile that reflects the interest of the reader. This collaboration
enables both applications to gain a deeper knowledge about the
user's
interest. Because all the personalized Web applications (even
on different servers) need to have access to the complete set
of profiles for a specific user, the best place to store a user
profile is at the browser.
Several architectures are used for personalized
services on the Web and they differ mainly in the locations of
the management and storage functions.
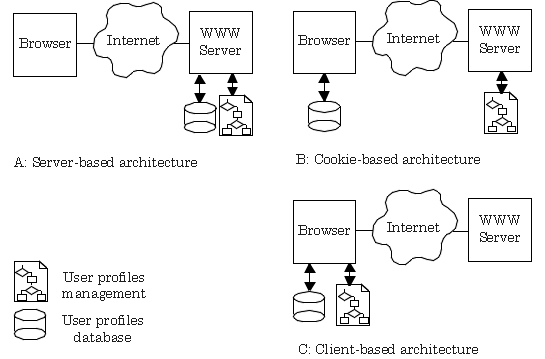
The most common architecture (adopted
for the Krakatoa Chronicle) is the server-based
architecture, in which the user profiles are both stored and managed
at the server (Fig. 3A). Since the profiles of all users are centralized,
the server needs to identify the user in order to extract the
right user profile. This is done by using an authentication mechanism
(ID + password). This architecture is efficient in that the user
profiles do not transit through the network. The centralization
of all the user profiles enables the use of both content-based
and collaborative filtering but prevents user profiles from being
shared between applications on different servers. With this architecture,
the service provider has to supply both hardware and software
for the management and storage of the users'
profiles. For a worldwide service, those profiles may represent
a large amount of data.
The second architecture (adopted for
PowerStart) stores the user profiles on the client side
and manages them on server side (Fig. 3B). This architecture enables
the use of content-based filtering and profile sharing but not
of collaborative filtering. The browser must provide a mechanism
for permanently storing data on the user's
computer, and this is a sensitive issue because most browsers,
for security reasons, do not allow a Web application (e.g., a
Java applet[10])
to permanently store any information on the terminal. The "Cookie"
mechanism introduced by Netscape [11]
[12]
is an exception to this rule. By setting a cookie, an application
can get data permanently stored by the browser and automatically
sent back when the user accesses the application again. The main advantage of this second architecture is the distributed
nature of the storage, which frees the service provider from supplying
software and disk space for the database, but the transmission
of the user profile between its storage location (client) and
the management location (server) increases the response delay.
The third architecture (adopted by PointCast
Network) manages and stores the user profiles on the client
side (Fig. 3C). In PointCast Network the personalization
is done by the browser, and the architecture is therefore not
a client-server architecture anymore (at least with respect to
the personalization). This architecture enables the use of content-based
filtering and user profile sharing but not of collaborative filtering.
Although all these architectures enable the
use of content-based filtering, none of them can at the same time
support collaborative filtering and the sharing of user profiles
among different applications. Furthermore, no standard such as
the Common Gateway Interface (CGI) [13]
has been defined for the management and storage of the user profiles
on the server side. Each personalized Web application that uses
the server-based architecture has to interface individually with
the database that contains the user profiles.
To solve the problems described in the previous
section, we introduce the concept of a user profile management
agent. One can define an agent as "anyone
who acts on behalf or in the interest of somebody else"
[14].
Accordingly, our agent is one responsible for managing and storing
the user profiles and thus for providing personalization support
to Web applications. The tasks of this agent are storing and retrieving
user profiles, enabling these profiles to be shared, and providing
support for collaborative filtering.
One way to implement the user profile management
agent would be to use an RPC (Remote Procedure Call) architecture
and put the agent on a separate server. The main drawback of this
model is that it requires a network connection to be made each
time that a Web application needs a service from the agent. This
adds a significant delay to the overall execution time of the
application.
Nowadays many companies use one or more proxies
between their intranet and the Internet. A proxy acts as a firewall,
prohibiting unauthorized visitors from accessing the intranet
and denying accesses from the intranet to certain Web sites (e.g.,
pornographic sites).
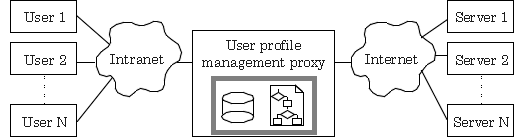
Our proposal takes advantage of this
existing bottleneck and locates the user profile management agent
there (Fig. 4). We refer to this extended proxy as a user profile
management proxy.
The proposed architecture has the following advantages:
The use of a user profile management proxy
is not restricted to companies that own a firewall; a Web provider
can use it to centralize the authentication of its clients, to
store the user profiles, and to share them between the services
it provides.
The user profile management proxy acts as a regular proxy for any URL not known to be one providing a personalized service. To indicate the presence of a user profile management agent along the communication path, the agent adds a flag to each HTTP (Hypertext Transfer Protocol [15]) request before forwarding it.
To be able to retrieve the user profiles
owned by the user that issued an HTTP request and to prevent any
abuse from inside the firewall, access to the proxy is protected
by a username-password pair (as it is when a user is accessing
a restricted WWW server).
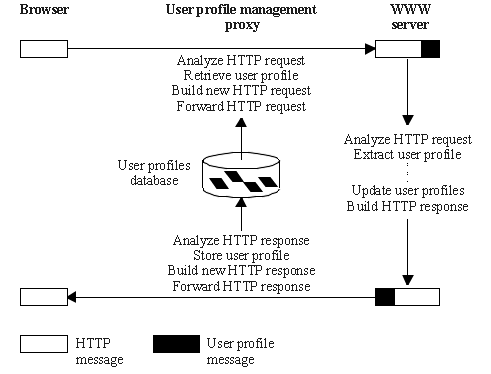
Whenever the proxy receives an HTTP request,
it checks to see if the pair of the target URL and the username
is registered (Fig. 5). If it is, and if the corresponding user
profile exists, the profile is retrieved from the database and
added to the HTTP request, which is then forwarded to the Web
server. The application uses the user profile for personalization
purposes and then, if the user profile needs to be updated, includes
a new profile within the HTTP response. As this response goes
through the proxy, the profile is extracted, stored into the database,
and removed from the HTTP response. This assures complete transparency
with respect to the browser. Every time a user profile is stored,
the agent updates the list of URLs known to be providing a personalized
service.
Support for collaborative filtering is provided
by managing individual user profiles that contribute to a group
profile. We refer to an element of a group profile as a group
profile component. For example, to create a personalized Web
newspaper, each reader can contribute to a group profile that
reflects the most popular articles. In this case, each group profile
component is associated to a different user and contains a list
of the best articles that user selected. The storage of a group
profile component is similar to the storage of a regular user
profile, but the retrieval is different because the user profile
management agent has to transfer to the Web application all the
group profile components of the group to which the user that issued
the HTTP request belongs.
To provide user profile sharing, the user
profile management agent generates a catalogue that enumerates
the sharable profiles. Each entry of this catalogue contains not
only the name of a user profile and its creator (name of the application,
URL, etc.) but also a description of the profile's
content. This description includes such information as a list
of keywords, a textual summary of the content, a formal description
of the syntax (e.g., profile type and position of fields). To
free the user profile management agent from the tasks associated
with managing the descriptions and to avoid the problems of duplicate
storage in a distributed environment, we decided to create a separate
text file for each user profile's
description and to locate it at the same Web site as the Web application.
The agent thus must store only the URL of the description text
file associated with each user profile.
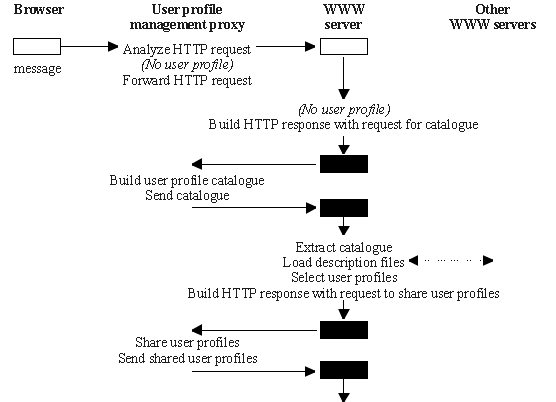
The communication flow for sharing
a user profile is divided into two steps (Fig. 6). The application
first gets a catalogue of all the user profiles that belongs to
the user that issued of the HTTP request. The application can
then get more details by downloading the description text files
of the candidate user profiles. Once the selection has been made,
the application indicates to the user profile management agent
which user profiles it wants to share. As a response to this request,
the agent sends the content of the shared user profiles to the
application. The shared user profiles are subsequently accessed
via the regular "get"
and "set"
operations. Therefore, the process of selecting a user profile
occurs only at the first access (when no user profile is available).
Our user profile management proxy prototype
provides all the services mentioned in the previous section: storage
and retrieval of user profiles, sharing user profiles, and management
of group profile components.
The prototype has been implemented on a Unix
platform by inserting a user profile management agent into the
publicly available CERN proxy-server [16].
The proxy authentication schema implemented follows the specification
of the proposed standard HTTP 1.1 [17].
Since the common browsers are caching proxy authentication, the
user has to be authenticated only once per browser session.
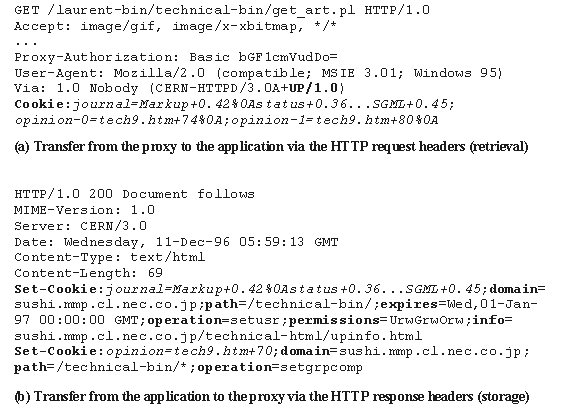
The prototype mediates the communications
under HTTP and uses an extended version of the Cookie syntax to
transmit the user profiles. As shown in Fig. 7, extra fields have
been added to transfer the information necessary for extended
services, but our syntax extension is upper compatible with Netscape's
Cookie specifications [11]. In this implementation, we decided
to extend the Cookie syntax instead of defining new HTTP headers,
so that the user profile management agent stores not only the
user profiles, but also all the cookies that would normally be
handled by the browser.
The proxy always inserts the flag "UP/version"
in the "via"
header to indicate the presence and the version of a user profile
agent. Given that information, the application can optimize the
requests for services (plain cookies, catalogue or sharing services,
etc.).
A program library has been built to ease and standardize the management of user profiles for CGI scripts written in Perl. This library provides high level routines to store and retrieve user profiles, filter and search a catalogue of user profiles, download description files, etc. The library optimizes the requests for the user profile services according to the version of the user profile management agent's flag. For example, if no flag is specified, the library stores user profiles as regular Cookies, and a request to get the catalogue of the existing user profiles is ignored.
To demonstrate the effectiveness of our user
profile management proxy and evaluate its performance, we have
created two personalized applications that use the full extent
of the support it provides.
The first application is a personalized newspaper
very similar to the Krakatoa Chronicle. This application
presents news articles gathered from a newspaper publisher, and
its personalization is the result of content-based learning and
scoring engines. The scoring engine uses a user profile (list
of keywords with weights) to rate daily articles. The articles
which get the highest scores are considered the most relevant
to the user and are presented first. Whenever the user has read
an article, he can indicate the level of interest and the learning
engine of the newspaper can update the user profile to reflect
the new information.
The second application is a personalized
technical journal. This application offers to scientists a journal
containing abstracts of scientific papers gathered on the Internet.
The scientific articles are gathered by a robot [18]
that visits several Web sites known for hosting scientific papers.
We use the public domain robot called Harvest [19]
to download the technical papers, extract the abstracts, and store
them in a database. Whenever the user accesses the technical journal,
the engine retrieves the abstracts from the database, scores them
to match the user's interest, and
presents them in a way similar to the way our personalized newspaper
presents articles (Fig. 8). Each abstract is linked to the original
document, and the user can read the entire paper if the abstract
seems interesting. This application also makes use of content-based
learning and scoring engines in order to anticipate the relevance
of articles for each user.
Scientists who are working on the same project
usually have similar interests in technical papers, and scientists
often mention a URL to a co-worker who is looking for information
about a specific topic. We have therefore integrated the collaborative
filtering technique to the learning and scoring engines of the
technical journal. The learning engine generates not only the
user profile containing the keywords, but also a group profile
component which contains the references to the best-rated (by
the user, not the engine) abstracts along with their scores. The
scoring engine then implements collaborative filtering by first
rating the articles according to the user profile containing the
keywords and then by adjusting the scores according to the recommendations
of the co-workers.
Since both applications require a user profile
that reflects the user's interest,
it is shared between the two applications. Whenever one of the
applications is accessed and no user profile is associated with
the HTTP request, the application queries the user profile management
proxy about the existing user profiles. If the query reveals that
the user profile associated with the other application exists,
the newspaper requests the user profile management proxy to share
the existing user profile between the two applications.
Brooks, Maze, Meeks, and Miller [20]
propose to extend proxies by using specialized HTTP transducers
(called OreO). A transducer is a specialized processing module
that gets an input stream, performs some operations on it, and
generates an output stream. Although the architectures of the
OreO system and the user profile management proxy look very similar,
in the OreO system, documents are personalized by installing a
personalization oriented transducer at an OreO extended proxy,
but a Web application has no control on the personalization performed
by the transducer. In our architecture, the user profile management
proxy provides support by managing the necessary user profiles
but does not itself perform any personalization. This task is
performed by the Web application which can therefore keep full
control on the type and quality of personalization performed.
To estimate the performance of the user profile
management proxy, we have measured the time elapsed between the
reception of an HTTP request at the proxy and the forwarding of
the corresponding HTTP response. These measures have been held
when the user sends a feedback to two different versions of the
personalized newspaper presented earlier. Both applications have
a similar personalization engine, but in the first case the storage
of the user profile is done by the user profile management proxy
and in the second case the application stores the profiles at
the server. Our measures show that the proxy based architecture
is about 20-30% slower than the server based architecture. This
result should be considered as a "worst
case" because, in order to have
identical performance for storage, the user profiles management
proxy and both newspaper applications are running on the same
machine implying that the network latency between the proxy and
the server is minimum. From the point of view of the user, the
delay added by the user profile management agent is imperceptible
because it is in the range of half a second, much smaller than
the delay due to the transfer of the HTTP request and HTTP response
through the network.
No measurement has been held when a personalized
Web application uses the catalogue/share services. However, the
user can notice some extra delay - especially when the application
has to download several user profile's
description files. These services though, are designed to be used
only in special circumstances; for example, when a user accesses
a personalized application for the first time.
Our current aim is to gain experience in
the design and implementation of personalized Web applications
that are supported by our user profile management agent. One ongoing
project is the improvement of the personalization of the newspaper
and the technical journal by combining content-based filtering
and collaborative filtering more effectively.
Another goal is to design a system in which
user profile management proxies cooperate. The current model
does not enforce storage consistency when user profile management
proxies are cascaded, as within a company (group, department,
and company proxies). Cascaded proxies can also be used to provide
hierarchical collaborative filtering: between members of a group,
members of a department, etc.
We are also considering the use of a distributed
database for the storage of the user profiles. Some firewalls
have several proxies that connect, in parallel, the intranet to
the Internet. In this situation, the user should have transparent
access to his user profile regardless of the proxy he is using.
We have pointed out the limitations of the
current user profile management architectures and have proposed
the concept of a user profile management agent providing a standardized
support for personalized World Wide Web applications. An architecture
in which this agent is located at a proxy instead of at the browsers
or servers enables the use of advanced personalization techniques
(including user profile sharing and collaborative filtering),
transfers the storage of user profiles to the client side, and
is efficient in terms of service latency and network load.
Several issues, such as the dynamic configuration
of groups for collaborative filtering support and how user profile
management proxies can cooperate, have not yet been resolved.
Nevertheless, the prototype and the personalized Web applications
implemented have already demonstrated that support for personalized
Web applications can be efficiently implemented as a user profile
management proxy.
Personalization is an important technology for presenting effective information to people. We think our user profile management agent can help Web service providers manage personalized services more easily and can thus encourage the development of personalized applications on the World Wide Web.
[1] Lycos, http://www.lycos.com/
[2] Yahoo, http://www.yahoo.com/
[3] Alta Vista, http://altavista.digital.com/
[4] Kamba T., Bharat K., Michael Albers M.
C., The Krakatoa Chronicle-An interactive personalized newspaper
on the Web, in Proceedings of the Fourth International
Conference on the World Wide Web, Boston, December 1995, pp.
159-170
[5] Crayon,
http://crayon.net/
[6] Power Start,
http://personal.netscape.com/custom/
[7] What is Pointcast Network,
http://www.pointcast.com/whatis.html
[8] Morita M., Shinoda, Y., Information
Filtering Based on User Behaviour Analysis and Best Match Retrieval,
in Proceedings of the 17th International ACM-SIGIR
Conference on Research and Development in Information Retrieval,
1994, pp. 272-281
[9] Shardanand U., Pattie M., Social Information
Filtering: Algorithms for Automating "Word
of mouth,"
in Proceedings of the Human Factors in Computing System,
Denver, May 1995, pp. 210-217
[10] The Java Tutorial,
http://java.sun.com:80/books/Series/Tutorial/index.html
[11] Persistent Client State, HTTP Cookies,
http://home.netscape.com/newsref/std/cookie_spec.html
[12] HTTP State Management Mechanism,
ftp://ftp.ietf.org/internet-drafts/draft-ietf-http-state-mgmt-05.txt
[13] CGI Documentation,
http://hoohoo.ncsa.uiuc.edu/cgi/
[14] Lingnau A., Drobnik O., Domel P., An
HTTP-Based Infrastructure for mobile agents, in Proceedings
of the Fourth International Conference on the World Wide Web,
Boston, December 1995, pp. 461-471.
[15] HTTP/1.0 (Informational RFC 1945),
http://www.w3.org/pub/WWW/Protocols/Specs.html
[16] Nielsen H.-F.,CERN httpd,
http://www.w3.org/pub/WWW/Daemon
[17] HTTP/1.1 - Proposed Standard,
http://www.w3.org/pub/WWW/Protocols/Specs.html
[18] Dr. P.M.E De Bra, Introduction to
the WWW robot technology, in Tutorial Notes of the Fifth
Conference on the World Wide Web, Paris, May 1996, pp. 257-270.
[19] Harvest,
http://harvest.transarc.com
[20] Brooks Ch., Maze M.S., Meeks S., Miller
J., Application-Specific Proxy Servers as HTTP Stream Transducers,
in Proceedings of the Fourth International Conference on the
World Wide Web, Boston, December 1995, pp. 539-548.
Return to Top of Page
Return to Posters Index