
With the tremendous growth of the World-Wide Web, accessing information on the Internet has become less a question of determining whether the information is out there, but rather, in what form, and how to find it. New sites often duplicate information that is already available in a different form, multiplying data storage and maintenance costs. Instead, we can use metadata to construct specialized models of heterogeneous information by defining search and presentation layers on top of existing resources. We introduce the notion of an abstract data source, which provides seamless access to both physical information resources and logical views. Instead of designing yet another search engine, we enable the creation of virtual containers that logically group related resources and may be associated with any available indexing technology. We have designed and implemented a hierarchy of Java classes that support data modeling capabilities. These classes extend object-oriented functionality currently provided by W3C's Jigsaw server, and are capable of being adapted to work with the coming generation of object-oriented Web servers.
Our model focuses on the creation of MetaMagicTM resources, logical entities that use metadata to retrieve their content by accessing one or more data sources and that have one or more methods of presenting that content via the Web. Our notion of a data source is abstract, in that a data source may represent a local file, a URL, a database query, or any other entity that may yield a stream of data. The notion is also recursive; a MetaMagic resource utilizes data sources in order to access its content, but also, through its presentation method (or methods), may itself be utilized as a data source. To support customized search, we enable the creation of virtual containers, logical groupings of related MetaMagic resources that may be associated with any available content-based indexing technology. These containers, in turn, are grouped together into repositories to form a virtual Web site.
An important advantage of our solution is advanced support for automated generation of MetaMagic resources. As in [shk95-2], we define and implement high-level operations to control data analysis and metadata generation, as well as logical grouping of resources based on search, traversal, and presentation requirements. We provide a form-based interface to repository generation and are currently working on evolving the operations into a high-level modeling language. The metadata generation process is closely integrated with content presentation, which is important for maintaining referential integrity of MetaMagic resources.
In addition to supporting flexible access to existing information, MetaMagic provides a reason to seriously rethink the way to design and build new Web sites. With MetaMagic supporting multiple dynamic views of the same data, it becomes beneficial to separate content from presentation. The main task of the site design is then to logically collect the content in the most transparent form (e.g., plain text files or database entries), without moving data to a single file system or redesigning data maintenance procedures. An important additional benefit of such approach is in protecting Web sites from the assault of new presentation technologies that have long outdated early HTML pages. Achieving a cutting-edge presentation would only involve upgrading presentation methods without changing physical content.
Instead of implementing yet another HTTP server in order to support the MetaMagic model, we have designed and implemented a hierarchy of Java classes that support data modeling capabilities. These classes extend functionality currently provided by W3C's object-oriented Jigsaw server [bai96], and are capable of being adapted to work with the coming generation of commercial object-oriented Web servers.
In the following section, we introduce the MetaMagic model, centered around the notion of a data source. We discuss basic operations for generating metadata entities that implement MetaMagic resources. We discuss MetaMagic architecture and implementation in section 3.0. In section 4.0 we discuss a sample MetaMagic application for imposing different views on Internet Requests for Comments (RFCs). Section 5.0 discusses related work and is followed by conclusions and our plans for future work.
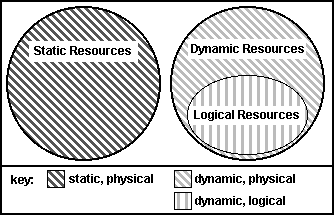
Fig. 1. Classification of resources.
The MetaMagic object model is defined to provide seamless access to static and dynamic information resources (fig. 1). We use the term resource to refer to an object exported by a Web server. Static resources map directly to the file system objects: directories, files, etc. Dynamic resources generate their content upon request. We are interested in a special kind of dynamic resources, logical resources, which are represented by object specifications. We refer to the rest of the resources as physical, implying that they are either static or, if dynamic, are generated by running executables that are directly specified in the requests. In MetaMagic, we create logical resources that are composed of metadata attributes. At presentation time, when a request for such a resource arrives at the MetaMagic server, these metadata attributes, in combination with the request information, determine content of the reply.
We begin this section by defining the notion of a data source (section 2.1). This notion is central to the concept of MetaMagic resources, described in section 2.2. Finally, in section 2.3, we discuss operations for generating and logically grouping together MetaMagic resources to support the desired search and presentation of the original information.
Although various data sources may use different retrieval mechanisms, all
of them maintain the same interface for presenting their content. For
example, a data source for an HTTP URL obtains content through the HTTP
get request, while a data source for an SQL query may execute a
shell command utilizing an ad-hoc query tool. Regardless of these
differences, both present their content as a stream
after receiving a "present content" request.
A MetaMagic resource is a data source capable of packaging its content as an HTTP response. MetaMagic resources can be collected into virtual containers. A virtual container is a MetaMagic resource possessing an interface for listing its component resources. MetaMagic resources that are not virtual containers are called leaf resources. In addition to component resources, virtual containers may be associated with descriptive content. By default, the content of a virtual container is a listing of its component resources. Alternatively, the content may be a textual description or a query front-end to independent data structures (e.g., full-text indices) referencing component resources.
Consider, for example, a collection of papers on the topic of maintaining reference integrity on the Web. One way of providing access to these papers is to associate a MetaMagic resource with every paper and then to collect these resources as components of a virtual container. To represent the content of the container resource, we associate it with two data sources: one that presents a general description of the problem of maintaining referential integrity, and another that presents a WAIS index of the papers. To present itself via the Web the virtual container might generate formatted HTML, consisting of the general description followed by a search form.
Encapsulation is the process of analyzing a data stream to generate leaf resources associated with portions of the data. It is this analysis that yields the access-descriptive and content-descriptive metadata attributes that constitute the leaf resources. The encapsulate operation generates leaf resources when supplied with a data stream and an encapsulation type, which controls the selection of a data analysis method. Data analysis methods, which are ultimately responsible for generating MetaMagic resources, follow a common pattern and are implemented by extending abstract classes.
The index operation supports generation of MetaMagic resources associated with query interfaces. The operation generates a new leaf resource when supplied with a set of resources and an encapsulation type, which, in this context, controls the selection of third-party indexing technologies. These technologies (e.g., WAIS, Excite, etc.) are used to index the contents and/or metadata attributes of supplied resources. The new leaf resource contains references to the generated index and to a cross-reference table that gets generated by the same operation and that is necessary for mapping the results of future queries into MetaMagic resources.
Another core operation is the group operation, which is responsible for combining resources into virtual containers. It generates a new virtual container resource when supplied with a set of resources. We have defined set union and set intersection operations to support the formation of such sets. We also have defined the extend operation that supports adding descriptive content to a virtual container resource. The primary objective of this operation is to associate descriptions and query interfaces with container resources (section 2.2).
At this time, access to individual operations is provided through
their API (section 3.3.2).
Specification of a new repository structure
involves subclassing the abstract MetaMagicRepository
class and overriding the "generate" method, which is
responsible for building new metadata repositories.
However, the operations were designed to be naturally combined in
a high-level scripting language that would also include set variables
and set iterations. Both the scripting language and its visual front-end
are currently under development and are not discussed in this paper.
Albeit with certain qualifications, the choice of Java as an implementation language allows us to take platform-independence in the traditional sense for granted. Instead, we consider portability in terms of server platforms. In this context, the challenge is to ensure that our class hierarchy is general enough to extend different HTTP servers.
We have formulated a number of requirements for HTTP servers that qualify them as acceptable MetaMagic platforms:
Having adopted such an approach, we determined that the Jigsaw reference server from W3C was the natural and obvious choice as the basis for our initial prototyping. Jigsaw is implemented in Java and provides a Java API with all of our required features. Furthermore, the Jigsaw server is publicly available, including complete source code.
Although some of the classes in our hierarchy extend those provided by the Jigsaw API, every attempt has been made to ensure that the design itself relies upon the minimal set of requirements specified earlier in this section. Jigsaw is currently unique in providing all of these features simultaneously, but we are confident that the coming generation of object-oriented commercial servers will have the extensibility characteristics necessary to support the MetaMagic model. In support of this assertion, we note the following:
When the Jigsaw server receives an HTTP request, it initiates a lookup
process, creating a LookupState object from the path
information of the requested URL (fig. 2).
The path information is broken into
slash-separated components, each of which maps to some server resource
(such as a directory, a file, etc.). It is the job of each of these
resources to look up the next component and pass on the request,
along with the remaining path information. This iterative process
continues until either the components are exhausted or a resource is reached
that is not a directory. This final resource is the target of the
lookup operation, and is referenced by a field of the
LookupResult object.
MetaMagic virtual container resources (see section 2.2) play a similar role in the lookup process to that of directories. The URL of a MetaMagic virtual container resource looks just like that of any normal directory:
http://www.server.org/dir_1/dir_2/my_virtual_container/
The URL of a MetaMagic leaf resource contained within such a container may
look like:
http://www.server.org/dir_1/dir_2/my_virtual_container/my_resource
Note that my_virtual_container and my_resource
appear in the path information of the URL, even though these paths do not
map to file system objects.
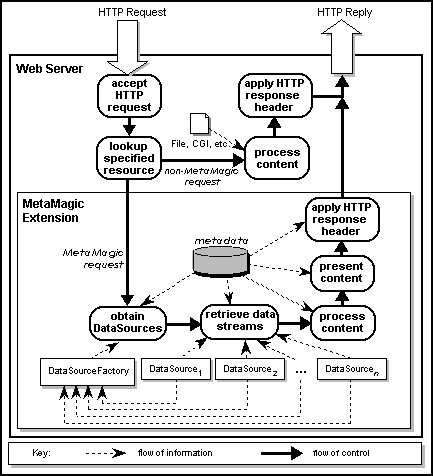
If the Jigsaw server is MetaMagic-enabled but the target of the lookup
is not a MetaMagic resource, then the server simply processes this request
as if MetaMagic classes were not there. If, however,
the lookup refers to a MetaMagic resource, then that resource
responds by sending a presentContent()
message to itself, initiating the following procedure:
DataSourceFactory to instantiate the appropriate
data source classes.
presentContent() method for each
data source, obtaining its content as an InputStream.
InputStreams provided by its data sources,
filtering, integrating, processing or interpreting these
streams to generate its own content.
InputStream containing the generated content.
This stream is returned by the getContent() method.
To complete its response to the HTTP request, the MetaMagic resource
attaches the generated content to an HTTPReply object,
fills in any applicable HTTP header fields in the reply, and then
passes the reply to the server to send back to the browser.
Note that the MetaMagic resource, rather than the server, is responsible
for attaching the reply header. This has important implications,
particularly for the Content-type field. While a typical Web
server sets the Content-type field based upon a configurable
but static mapping between file extensions and MIME types, MetaMagic
resources set their MIME types dynamically at presentation time. This
allows a single MetaMagic resource to present its content flexibly, based
on information that may be passed in through the HTTP request.
DataSource interface. We have implemented DataSource
as a Java interface in order to take maximum advantage of code reuse.
Any Java class may be easily extended and made to implement
the DataSource interface.
Since a Java interface is essentially a special kind of an abstract class,
and cannot be directly instantiated, the instantiation of
DataSources is supported through the
DataSourceFactory class. Every DataSource has a
unique identifier in the form of a URL (e.g., http://...,
jdbc://..., etc.). The identifier is passed as an argument to
the DataSourceFactory's createDataSource() method
to help it select a class to be instantiated. Having selected the class,
the createDataSource() method creates an instance of this
class, and returns a reference to the resulting object. The
DataSourceFactory is designed to be configurable, so that even
within one server, different DataSourceFactory objects may
have different rules for creating DataSources, and different
mappings between unique identifiers and DataSource classes.
We have implemented several classes for simple DataSources,
such as FileDataSource, FtpDataSource,
HTTPDataSource, and GopherDataSource, as well as
several derived DataSource classes, which will be discussed in
section 3.3.3.
The first operation that must be performed to generate a repository is the
encapsulate operation. To support this operation, we define
a class Encapsulator with an abstract method
encapsulate(). Subclasses of Encapsulator must
implement this method in order to provide a specification for the analysis
of data streams.
Recall that the encapsulate operation takes as its input
one or more data streams and an encapsulation type. The data streams are
specified by DataSources passed to the constructor of the
Encapsulator. The encapsulation type is determined by the
class of the Encapsulator, whose distinctiveness lies in the
analysis specified by its encapsulate() method.
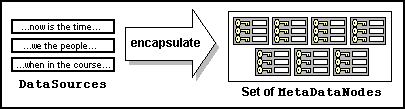
While performing the analysis, the Encapsulator obtains
metadata, which it stores in MetaDataNode objects (see
fig. 3). On completion of the analysis, these
objects are returned as a set. Each instance of MetaDataNode
is essentially a collection of name-value pairs, and may contain references
to a parent node and zero or more child nodes. Neither parent nor child
references are set by the encapsulate() method; parent-child
relationships are established later by the group
operation.
Although the encapsulate operation, as defined in section
2.2, is responsible for generating a set of leaf resources,
the MetaDataNodes generated by our Encapsulators are
actually intermediate objects that are only later translated into leaf
resources. There are two motivations for this approach. First,
encapsulation is a bottom-up process: the leaves are generated, and then
grouped into containers. However, registering Jigsaw resources, like
creating file-system objects, is a top-down process: only after a directory
has been created may files be placed in it. Thus, it makes sense to
build a hierarchy of MetaDataNodes first, and only make the
translation into Jigsaw resources after the hierarchy is completed. The
second advantage of this approach is that the process of building the
hierarchy remains independent of Jigsaw's architecture.
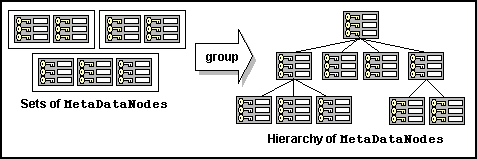
After the Encapsulators have analyzed their streams, and each
has returned a set of MetaDataNodes, set operations may be
performed in order to remove elements from the sets, combine sets, or
create new sets from existing elements. Sets of MetaDataNodes
are then grouped together by creating a new MetaDataNode to
contain them. The group operation is illustrated in
fig. 4. The container node is designated as the parent,
and the contained nodes become its children.
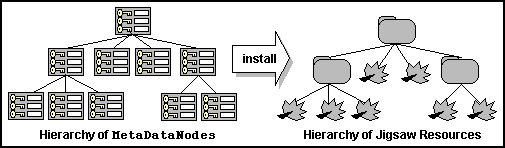
MetaDataNodes to
Jigsaw resources.
Finally, after the MetaDataNodes have been arranged in a
suitable hierarchy, the nodes are converted into Jigsaw resources and
installed into the server's information space, in a configuration mirroring
the hierarchy of MetaDataNodes
(fig. 5). This is accomplished via a
pre-order traversal of the hierarchy, converting each
MetaDataNode as it is visited. MetaDataNodes
with children are converted into VirtualContainerResources,
and those without children are converted into LeafResources
(see section 3.3.3).
Currently, the above process is specified by subclassing
MetaRepository and implementing the generate()
method. However, it is our intention to create a scripting language so
that creating new types of MetaRepository will not require
writing and compiling Java code. With this in mind, we have defined
an abstract class Operation, and several subclasses
implementing operations that comprise the repository generation
process.
Current subclasses of Operation include the following:
CreateEncapsulator,Encapsulate- These classes implement the encapsulate operation.
SetUnion,SetIntersection,ForEach- These classes implement operations supporting the manipulation of sets returned by the encapsulation process. The
ForEachoperation supports iteration over elements of a set.
CreateIndexNode- This class implements the index operation. It utilizes third-party indexing technologies to create content-based and metadata-based indices for a set of nodes returned by the encapsulation process. The operation generates an
IndexNodethat presents its content as a query interface.
CreateContainerNode,ExtendContainer- These classes implement the group and extend operations.
CreateContainerNodetakes a set ofMetaDataNodes and makes them the children of a newMetaDataNode;ExtendContaineraddsMetaDataNodes as children to an existing container node. Normally, all children will have been grouped together prior to creating theContainerNode, soExtendContainerserves primarily for adding child nodes that either contain content describing theContainerNodeor provide query interfaces to its elements. The special treatment of such child nodes is supported by the so-called favorite child mechanism that will be described in section 3.3.3).
InstallVirtualContainer- This operation recursively converts a
MetaDataNodeand all of its children into Jigsaw resources, registering them with the server as it traverses the hierarchy.
DataSource interface, but also
include methods for presenting their content in the form of an HTTP
response.
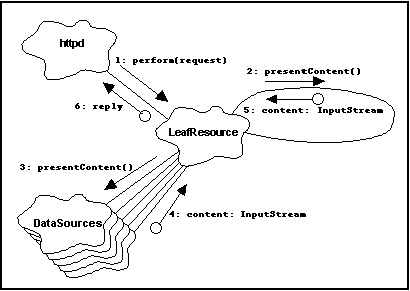
LeafResource presenting its content.
We implemented LeafResource as an extension of the Jigsaw
class w3c.jigsaw.resources.FilteredResource. This
class provides all the basic functionality of an exportable Jigsaw
object, but unlike w3c.jigsaw.resources.FileResource,
it does not imply a physical file system location. Recall that a
LeafResource is a derived DataSource, which
presents its content utilizing the streams presented by other
DataSources. Fig. 6 shows an
object-oriented view of this scenario, using a slightly modified Booch
[boo94] notation.
Note the correlation between this diagram and
fig. 2, which shows the process-oriented view of
handling an HTTP request.
For VirtualContainerResource, we took a slightly different
approach, and extended w3c.jigsaw.resources.DirectoryResource
rather than the more abstract and skeletal
w3c.jigsaw.resources.ContainerResource.
This was because we wanted VirtualContainerResource
to have much of the same functionality as a normal directory,
and it was relatively easy to override any behavior of
DirectoryResource that depended upon physical
directories. From there, we were able to add behavior specific to
VirtualContainerResource.
Particularly interesting is the case where an
instance of VirtualContainerResource has descriptive content
of its own, as in the general description and search query example
described in section 2.2. To present such content, we
were able to adapt a mechanism already built into most Web servers: the
ability to designate a default resource to be returned in response to a
request for a URL that denotes a directory. In a typical non-MetaMagic
server environment, this default resource conventionally has a name such as
index.html, default.html or
Overview.html.
We developed an extension of this mechanism, which we have termed the
favorite child mechanism. This mechanism differs slightly
from the default resource mechanism; while a directory on a typical Web
server may have at most one default resource, a MetaMagic
VirtualContainerResource may have any number of favorite
children. By default, a VirtualContainerResource concatenates
the content of its favorite children in order to present itself, but may be
extended to provide different behavior.
If a VirtualContainerResource has no children marked as
favorite, then it presents its content simply by listing all children.
|
|
|
| Fig. 7. | Fig. 8a. | Fig. 8b. |
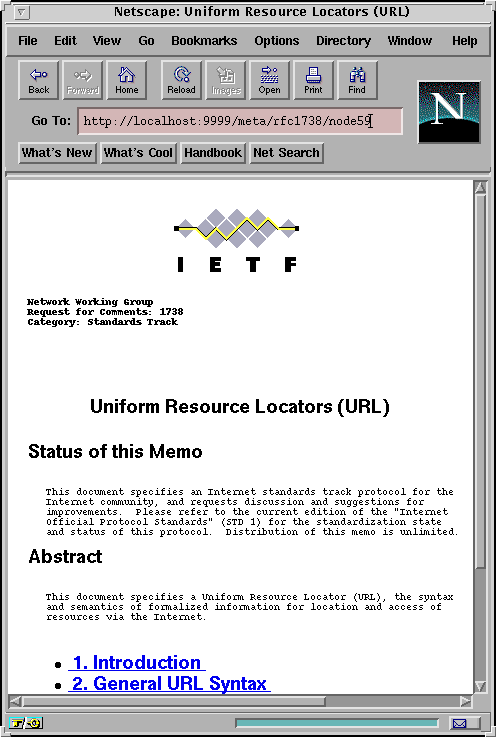
ftp://ds2.internic.net/rfc/rfc1738.txt.
First, the encapsulation process associates MetaMagic resources with the smallest logical units of information, which, depending on the desired view, may be either sections or subsections of the RFC. Every such resource is also a data source, which, when instantiated, creates and stores information describing where to obtain and how to process the content of RFC 1738 to extract the encapsulated content. When an RFC resource is required to present its content, it fetches the file from the ftp site, extracts the proper section or subsection, converts it to HTML, and generates an HTTP response.
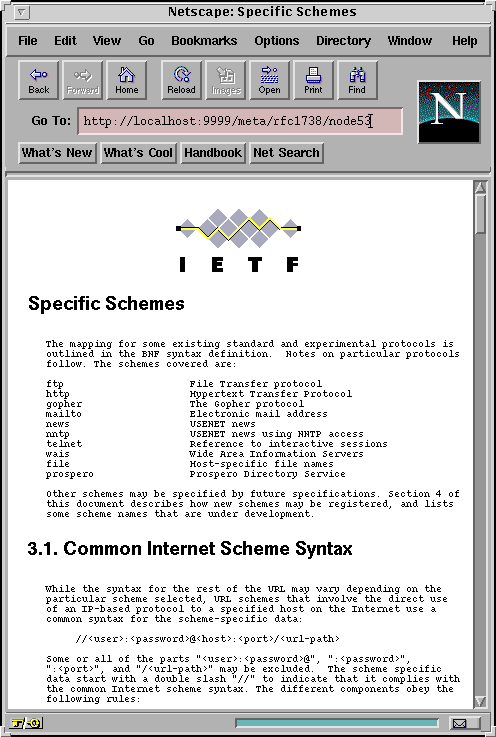
Figures 7 and 8 illustrate two alternative views imposed on the RFC 1738. In both views, the document is presented as a general description plus hyperlinks to individual sections (fig. 7). However, the presentation of sections is quite different for the two views (figures 8a and 8b). In the first case section resources present themselves by displaying the full contents of the encapsulated sections (fig. 8a). In the second case, section resources are presented through headers, which are hyperlinked to resources encapsulating individual subsections.
Closely related to CorbaWeb is the "ANSA Workprogramme" [ree95], which focuses on using CORBA to optimize the communication problems of HTTP by using CORBA's more advanced IIOP communications protocol. In the simplest form, they propose IIOP-to-HTTP and HTTP-to-IIOP gateways. In the future, they hope to add IIOP support to Web browsers and to build native IIOP servers. The work concentrates on the details of using CORBA rather than on defining abstractions.
"InfoHarness" is another example of the use of data modeling for building Web sites [shk95-1]. This earlier work was targeted primarily at providing Web access to legacy information, and the InfoHarness object model did not provide for the encapsulation of logical resources. InfoHarness objects were served by a proprietary server through a CGI interface and object specifications were loaded into the main memory when the server came up. A commercial version of the system stores object specifications in a relational database.
In contrast to papers that concentrate on constructing and accessing server-based object frameworks, the "Distributed Active Objects" work [bro96] applies object-oriented approach to building distributed applets. In the context of this work, applets have very relaxed communication restrictions, which raises a variety of security concerns. We do not believe that it is beneficial to consider client-side objects out of the context of server-based object networks.
We believe MetaMagic to be a step in changing the approach to building Web sites because it provides technology for separating information content from its presentation. This division maps neatly to practical reality: content often changes independently of the method for presenting it, and vice versa. As new extensions to HTML find their way into the latest browsers, only the presentation methods of a MetaMagic-enabled Web site need to change in order to remain in step with cutting-edge trends; the content does not need to change. Conversely, as content is updated, presentation methods can remain the same, providing a consistent look-and-feel to a Web site. It is clear that the double advantage of separating content from presentation is desirable for both the Internet and the corporate Intranets. MetaMagic enables a very smooth transition to this new approach because it was created to provide flexible access to legacy data.
In addition to streamlining Web site design, MetaMagic provides very high flexibility in personalizing data presentation based on client information. We foresee many possible applications for such personalization, including, but not limited to:
Our current work is mainly concentrated on designing and implementing a scripting language for building information repositories and a visual front-end for this language. We are also investigating ways to maintain referential integrity of both logical and physical resources.