Xiannong Meng,
Richard Fowler
Department of Computer Science
University of Texas - Pan American
Edinburg, TX 78539-2999
meng@panam.edu,
fowler@panam.edu
Eric Rieken
Department of Physics and Geology
University of Texas - Pan American
Edinburg, TX 78539-2999
ericr@panam.edu
The geographic information system (GIS) user community depends heavily on special purpose software that has evolved quite apart from the WWW. Yet, the general acceptance of the WWW for the distribution and display of information suggests that mechanisms for WWW delivery of GIS information will be of increasing importance. Gis2web is a system intended to bridge the gap between GIS software and datasets and the WWW. The system operates by periodically accessing distributed datasets of GIS information and creating a common repository of WWW accessible information on a gis2web server. In this way gis2web users are provided seamless access to different datasets which may be of quite different forms. This paper details the gis2web architecture and presents some of the implementation issues.
Geographic Information Systems (GIS) such as Arc/Info[2] and GRASS [18] can contain rich and diverse information such as census data, municipal data, business data, highway networks, and geologic data. Information is stored in formats including tables, images, and text. Typical GIS software maintains, manipulates, and displays this information in dynamic and graphical ways. The traditional mode of operation is to have the data accessible from within a specific GIS application on a single platform.
With the recent wide-spread acceptance and availability of World Wide Web (WWW)[3] technology, it is natural to look toward building linkages between the two distinct worlds of GIS and the WWW in order to make the wealth of information available in the GIS world publicly available through the WWW.
This paper describes the design and architecture of gis2web, a system intended to bridge the gap between existing GIS software and the WWW. The gis2web prototype accesses distributed datasets in different Arc/Info formats, converts the data to forms appropriate for WWW distribution, and provides access through a gis2web server. Gis2web allows distributed GIS to dynamically update their databases and have this information available to the WWW through automatic retrieval by gis2web.
Section 2 presents background information and related works. Section 3 discusses the design and architecture of gis2web. Some implementation issues are presented in Section 4, followed by concluding remarks in Section 5.
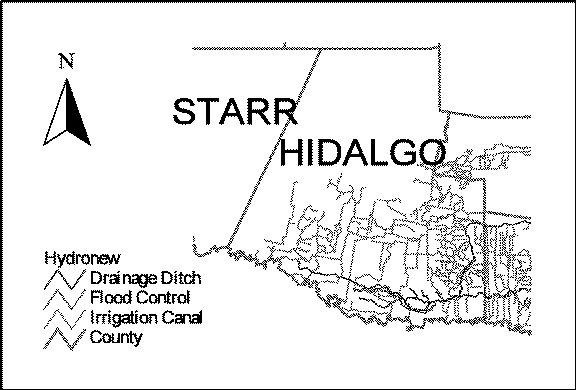
Geographic information systems store and access many and varied kinds of information. Typical sorts of information range from geologic and biologic inventory maps to census and remote sensing data[4, 5]. Use of such information is increasing in a wide range of decision making and research contexts. Any collection of GIS information would include vector maps, raster images, tables, graphs, and text which are interrelated and dependent on each other. Thus, GIS users can manipulate the database by interacting with any form of the data, whether geographic, tabular, or text. These basic data are used to generate different output maps with associated tabular data for different users. For example, a GIS database might have files of irrigation canals, such as the network depicted in Figure 1 for counties in south Texas. Users may be interested in overlaying flood channel data to determine suitable locations for water delivery and flood mitigation considerations. This could be of interest to builders, home buyers, planning groups, or government agencies. A typical GIS maintains the geographic information in the form of attribute tables, polygons and image maps. Depending the type of information and analysis of interest to users, the GIS performs operations to generate the results and display them in a suitable format.
Internet-based information systems have seen a tremendous growth in the past few years, e.g., FTP (File Transfer Protocol) [6], Gopher [7], WAIS (Wide Area Information Servers) [8], and WWW (World Wide Web) [9]. The WWW is gaining wide acceptance due in part to its flexible capabilities for transferring multi-media information and its integration with many existing, successful network tools. WWW employs a client-server computing paradigm in which the client requests the information, the server provides the data in multi-media and hyper-media formats such as text, audio, video, and links to other information sites. Today, almost all information on the Internet is accessible from the WWW.
Due to the very nature of GIS, which requires specialized operations on stored data, information in a GIS is not readily available to the WWW community. WWW servers and browsers today use the hyper-text transfer protocol (HTTP) [10] and the hyper-text markup language (HTML) [11] which operate on text and a relatively small set of pre-defined types of images. HTML in general does not support the features required by a GIS, nor are they appropriate, given that HTML is a hypertext language.
A number of projects have focused on making GIS information readily available for WWW users in order to close the gap between the two communities. BADGER (Bay Area Digital GeoResource) is a project that provides geographic information in the San Francisco Bay area in digital format accessible through the WWW [12]. BADGER generates a sequence of digital maps of different details, and users can view or download the images as needed. The U.S. government has made efforts to standardize catalog repositories of datasets so that users can browse, evaluate, and order them efficiently. As part of this effort, the Federal Geographic Data Committee (FGDC) [13] has published its geospatial metadata standard [14]. At the state level, similar projects are underway. For example, the Texas Natural Resources Information System (TNRIS) [15] has made available on the WWW a library of remotely sensed data, a set of topographic maps, and other information describing land use, vegetation, and hydrology. The Texas General Land Office [16] lists land and minerals information, as well as environmental and economic information on the U.S./Mexico border. The information presented in these web sites requires significant human resources to enter and maintain the data to ensure that the contents are accurate and up-to-date.
GIS databases are a significant resource that is underutilized through the WWW. To address this problem, many existing sites extract information from a GIS and enter it into a WWW server manually. This approach is expensive, and often leads to inaccurate, out-dated information. Gis2web supplies automated processes that can extract information from GIS servers, utilize a gis2web server to parse the information, translate it into HTML, and make the formatted data available for WWW servers which WWW clients can access.
Our goal is to maintain autonomous operations on GIS servers, gis2web servers, and WWW servers. This allows GIS servers to update GIS databases independently of gis2web servers' extraction and collection operations and the WWW servers' responses to clients' requests. This eliminates manual intervention and supplies GIS information to WWW users on demand.
Gis2web is designed to provide the following functionality.
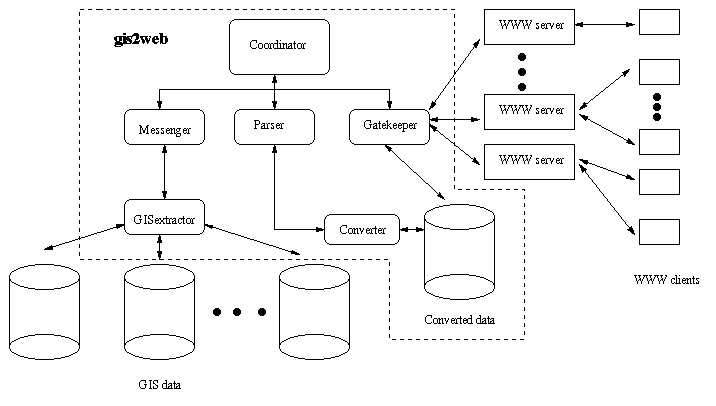
Gis2web consists of five different modules, as shown below in Figure 2 within the dotted box. The modules act as independent processes and communicate with each other using Internet protocols. The GISextractor accesses information on GIS servers. The Parser interprets the GIS information, creating the HTML format and storing it on the gis2web server. The Messenger passes the data between the GISextractor and the Parser. The Gatekeeper acts as an interface between gis2web and WWW servers, and the Coordinator schedules and controls the other modules. The following is a detailed description of each of the modules.
The architecture and design of gis2web is general enough that it can be implemented in any language and operating systems environment that supports WWW, a programming interface to the GIS, and Internet protocols. Our current implementation includes the Coordinator, the Gatekeeper, the Parser, and the Messenger on the UNIX platform written in C++, and the GISextractor on the UNIX platform written in the Arc/View native programming language.
In the prototype implementation, the GIS server is an Arc/View server. As such, the files are organized as a base map with various geographic themes and tabular attributes. For example, the themes might cover hydrographic distributions, highways, and geologic information, as well as political boundaries. Attribute data might have integrated census data, hydrologic parameters, and environmental parameters with the geographic themes. See Figure 1 for an example. The base map and various themes are stored in separate files, with attributes typically stored in a database format. Themes can be selectively displayed to create combinations of map information or to support queries of the tabular data requested by the users. Furthermore, any of the data can be updated as they would in a typical GIS environment. All of the operations such as search, join, print are supported. The task of the GISextractor is to extract information from these sources and pass them along to the gis2web server.
The GISextractor operates on the GIS database. In the prototype it interprets various Arc/View file formats and directory structures, including tables of attributes, vector geographic files, and raster image files. We have used Avenue, the native programming language in Arc/View because of these requirements. Avenue provides a convenient interface to the rest of the UNIX programming environment through RPC, or Remote Procedure Calls, which can directly communicate with a UNIX process.
The regular operations of the GIS server such as creating new GIS projects and updating current information are independent of the gis2web operations. Because of this, gis2web is transparent to the GIS users; they can use the GIS as if no other processes exist. The GISextractor works as a process to periodically extract information from the GIS server and pass it to gis2web's Messenger.
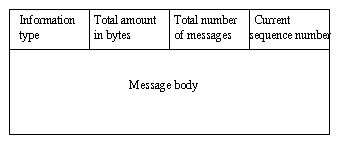
The Messenger receives information from the GISextractor and passes it to the Parser to be interpreted. Because the information is in various formats, a protocol is needed between the GISextractor and the Messenger for them to communicate. Three types of information are recognized and processed by the gis2web agents:
The Parser converts the various file formats received from the Messenger to a HTML compatible format for display. Currently, the Parser is responsible for putting plain text into HTML format with possible hyper-links; converting comma delimited Arc/View table information into HTML compatible table format; and converting PostScript-based image to GIF image using an external program.
In this paper, we described the design and architecture of gis2web, a system that bridges the existing gap between widely used GIS software and the WWW. Gis2web provides one element in making the wealth of information stored in GIS databases available through the WWW. The software consists of five major modules: the GISextractor directly accesses GIS databases; the Messenger transfers information from the GIS server to the gis2web server; the Parser converts GIS information into formats for the WWW server; the Gatekeeper acts as an interface between the WWW server and gis2web; and, finally, the Coordinator controls the general operation of the software. The key features of gis2web include the autonomous operations of the GIS server and the WWW server allowing the GIS information to be updated independently of the WWW operation; automatic, periodic retrieval and transfer of GIS information to WWW servers; and support of multiple data formats. The framework proposed here can be used in other similar applications.
Our future work will focus on efficient implementation of the design using the Java language, studying and improving performance, and exploring the potentials of applying the same ideas -- transparent extraction of information, sharing heterogeneous information among different applications, autonomous operations among independent, interacting information agents -- to other applications.
This research was supported by NASA grant NAG9-852.