
Figure 1: The Flowchart of CWS System.
In this section, we
give an overview of our CWS system. Figure 1 illustrates the flowchart of our system.
For simplicity, our system allows users to give two comparative
queries ![]() and
and ![]() as input. Both queries are submitted to a search
engine to get the ranked list of pages from the Web. Then, we
re-organize these two lists to get the comparative page pairs
and rank them. This is the pair-view output. To help the users
to digest the information, we also adopted one clustering
algorithm to group the similar pairs together. The keyphrases
are extracted from the clusters to highlight the contents of
the clusters. This gives the cluster-view output.
as input. Both queries are submitted to a search
engine to get the ranked list of pages from the Web. Then, we
re-organize these two lists to get the comparative page pairs
and rank them. This is the pair-view output. To help the users
to digest the information, we also adopted one clustering
algorithm to group the similar pairs together. The keyphrases
are extracted from the clusters to highlight the contents of
the clusters. This gives the cluster-view output.
Figure 2 gives an example of the CWS system interface. The pair-veiw is illustrated in Figure 2(a) and the cluster-view is given in Figure 2(b). In both modes, two text boxes are provided to input the comparative queries. In the pair-view mode, after queries are submitted, two lists of Web pages are generated by the system and are displayed in two columns. The left list of pages correspond to the query contained in the left textbox, while the right list corresponds to the right query. For each result page, the information including title, URL, and snippet is displayed. There are two differences between the pair-view result and that of traditional search engines. (1) The left page and its corresponding right one share comparative information and they two form a page pair. That is, both pages discuss common topics related to the two input queries. (2) The page pairs are ranked based on their relevance to the queries and the amount of comparative information they contain. In the cluster-view mode, result pages are organized into flat clusters. Each of them contains pages of similar topics. The keyphrases reflecting the common contents of each cluster are extracted and displayed on the left. If a user clicks on these phrases, all the pages of the corresponding cluster will be displayed on the right using the format similar to the pair-view mode. For each of the two page lists in one cluster, the keyphrases unique to this list are also extracted and displayed on the top.


4 ALGORITHMS
Our CWS system is based on an existent
search engine, denoted by ![]() .
Given two queries,
.
Given two queries, ![]() will return
two lists of pages ranked by their relevance to the two input
queries respectively. We then re-organize the search result
pages to facilitate Web users' comparison needs.
will return
two lists of pages ranked by their relevance to the two input
queries respectively. We then re-organize the search result
pages to facilitate Web users' comparison needs.
4.1 Ranking Comparative Page Pairs
In order to return
comparative information for the input queries ![]() and
and ![]() , our first
approach is to automatically re-rank the search results
returned by
, our first
approach is to automatically re-rank the search results
returned by ![]() . Assume
. Assume ![]() and
and ![]() represent the result pages corresponding to queries
represent the result pages corresponding to queries
![]() and
and ![]() respectively. In a traditional search, these result
pages are ranked by their relevance to the query. In contrast,
our purpose is to re-rank
respectively. In a traditional search, these result
pages are ranked by their relevance to the query. In contrast,
our purpose is to re-rank ![]() and
and
![]() to display the comparative
page pairs. Assume
to display the comparative
page pairs. Assume ![]() and
and
![]() are two pages from
are two pages from
![]() and
and ![]() respectively. If
respectively. If
![]() is
a good comparative pair,
is
a good comparative pair, ![]() and
and
![]() should contain information
about
should contain information
about ![]() and
and ![]() respectively and both pages should discuss some
common aspects about both queries. Our assumption is: if
respectively and both pages should discuss some
common aspects about both queries. Our assumption is: if
![]() is
a comparative page pair, they should satisfy:
is
a comparative page pair, they should satisfy:
(1) ![]() is relevant to
is relevant to ![]() ;
;
(2) ![]() is relevant to
is relevant to ![]() ;
;
(3) If ![]() and
and ![]() are removed from
are removed from ![]() and
and ![]() respectively, the remaining contents of
respectively, the remaining contents of ![]() and
and ![]() are
similar.
are
similar.
We use ![]() to denote the relevance
of a query to a page, and
to denote the relevance
of a query to a page, and ![]() to
denote the similarity between two text segments. The function
below is used to estimate the likeliness that two pages form a
comparative pair with regard to the input queries:
to
denote the similarity between two text segments. The function
below is used to estimate the likeliness that two pages form a
comparative pair with regard to the input queries:
In Equation (1),
![]() measures the amount of comparative information of
measures the amount of comparative information of
![]() and
and ![]() associated with
associated with
![]() and
and ![]() . The function
. The function
![]() considers the relevance
between pages and their corresponding queries, as well as
the comparative information contained in the two pages.
Parameters
considers the relevance
between pages and their corresponding queries, as well as
the comparative information contained in the two pages.
Parameters ![]() and
and
![]() are set to be equal
in order to guarantee the relevance measures corresponding
with the two queries are treated equally.
are set to be equal
in order to guarantee the relevance measures corresponding
with the two queries are treated equally. ![]() is a tradeoff
parameter, balancing the relevance measure and the
comparison measure. When
is a tradeoff
parameter, balancing the relevance measure and the
comparison measure. When ![]() is zero, the above equation is only a linear
combination of relevance information. In Equation (2), the comparative information of
is zero, the above equation is only a linear
combination of relevance information. In Equation (2), the comparative information of
![]() and
and ![]() is computed based on
their contents and URLs, with
is computed based on
their contents and URLs, with ![]() balancing the two kinds of information.
balancing the two kinds of information.
![]() and
and
![]() denote
the remaining text contents of page
denote
the remaining text contents of page ![]() and
and ![]() after
removing terms contained in their snippet texts
respectively.
after
removing terms contained in their snippet texts
respectively.
![]() denotes the
similarity between the URL strings of
denotes the
similarity between the URL strings of ![]() and
and ![]() .
.
The computation of ![]() is straightforward. In traditional search,
is straightforward. In traditional search, ![]() is used to rank Web
pages. Usually two factors are considered: the first is the
importance of a page, which is usually computed based on
the links among Web pages (e.g. PageRank [13]); the second is the
similarity between a query and a page, which can be
computed by traditional information retrieval models, such
as probabilistic model, vector space model, etc [2]. These models can also be
used for the computation of
is used to rank Web
pages. Usually two factors are considered: the first is the
importance of a page, which is usually computed based on
the links among Web pages (e.g. PageRank [13]); the second is the
similarity between a query and a page, which can be
computed by traditional information retrieval models, such
as probabilistic model, vector space model, etc [2]. These models can also be
used for the computation of ![]() .
.
It is quite common for a page editor to put some
comparative contents about ![]() and
and ![]() in one
single page. Such kinds of pages will be in both
in one
single page. Such kinds of pages will be in both ![]() and
and ![]() . In this paper, we
regard these kinds of pages themselves as comparative pages.
The ranking of these pages can also be handled by our
approach. In this case,
. In this paper, we
regard these kinds of pages themselves as comparative pages.
The ranking of these pages can also be handled by our
approach. In this case,
![]() is
maximal because the same contenst are left if
is
maximal because the same contenst are left if ![]() and
and ![]() are removed from the
original pages and both pages share the same URL. Thus only
are removed from the
original pages and both pages share the same URL. Thus only
![]() is
needed for ranking purpose.
is
needed for ranking purpose.
Our purpose is to identify the comparative page pairs
from the pages of ![]() and
and ![]() . Those pages form a
bipartite graph, where the edge weight is computed by
. Those pages form a
bipartite graph, where the edge weight is computed by
![]() . Although traditional
maximum matching algorithms can also be used to for pair
matching [14], they are
not suitable for the comparative search task for two
reasons: 1) The maximum matching algorithms are not
efficient, while CWS is an online application. 2) When Web
users make comparisons in a search scenario, they are
usually interested in the top results rather than the whole
list. Thus it is unnecessary to find a group of page pairs
based on maximizing an objective function. In this paper,
we proposed a greedy algorithm to rank the comparative page
pairs, as discussed below.
. Although traditional
maximum matching algorithms can also be used to for pair
matching [14], they are
not suitable for the comparative search task for two
reasons: 1) The maximum matching algorithms are not
efficient, while CWS is an online application. 2) When Web
users make comparisons in a search scenario, they are
usually interested in the top results rather than the whole
list. Thus it is unnecessary to find a group of page pairs
based on maximizing an objective function. In this paper,
we proposed a greedy algorithm to rank the comparative page
pairs, as discussed below.
All page pairs
![]() are first ranked in decreasing order according to
are first ranked in decreasing order according to
![]() . The
pair with the highest score will be selected as a
comparative pair and both pages of this pair are inserted
in set
. The
pair with the highest score will be selected as a
comparative pair and both pages of this pair are inserted
in set ![]() . All the
remaining page pairs will be filtered and those containing
pages in
. All the
remaining page pairs will be filtered and those containing
pages in ![]() are removed from
are removed from
![]() . Then the second
comparative pair is selected from the updated set
. Then the second
comparative pair is selected from the updated set
![]() . This process iterates
until
. This process iterates
until ![]() is empty. With this
strategy, we can remove those pairs containing duplicate
pages and rank all the comparative page pairs according to
is empty. With this
strategy, we can remove those pairs containing duplicate
pages and rank all the comparative page pairs according to
![]() .
.
4.2 Clustering Comparative Page Pairs
In Section 4.1, we did not consider the redundancy
among the comparative page pairs. That is, there may exist
several page pairs describing the similar aspects of the
two input queries. For example, all the comparative pairs
ranked at top may compare the prices of two products, thus
users have to navigate down through the pair list to find
comparative contents about other aspects. In order to
address this problem, we propose a comparative page
clustering approach to improve the comparison results. At
the user end, we present comparative page clusters instead
of page pairs. Each cluster consists of pages describing
similar aspect(s) of the comparative contents. Pages in a
cluster ![]() are divided into
two parts:
are divided into
two parts: ![]() and
and
![]() , which contains
contents specific to
, which contains
contents specific to ![]() and
and ![]() respectively.
respectively.
We cluster the comparative page pairs produced in
Section 4.1 to generate the
comparative clusters. Each page pair
![]() is treated as a whole consisting of all the snippets
associated with
is treated as a whole consisting of all the snippets
associated with ![]() and
and
![]() . Then all the page
pairs are clustered by a probabilistic clustering
algorithm. For each cluster, its page pairs are displayed
side by side for comparison purpose.
. Then all the page
pairs are clustered by a probabilistic clustering
algorithm. For each cluster, its page pairs are displayed
side by side for comparison purpose.
The clustering algorithm is based on the simple mixture generative model [21]. In the mixture generative model, each document is generated by a mixture of several multinomial word distributions. These word distributions correspond with the latent themes among all documents and can be estimated by the Expectation-Maximization (EM) algorithm [4]. At the same time, the EM algorithm can also give us the mixing weights of each document to the themes (i.e., word distributions). The document clusters are then formed by assigning each document to the most salient theme to which it has the largest weight.
Formally, assume there are ![]() hidden themes in a given document collection
hidden themes in a given document collection
![]() :
:
![]() ,
and one background model
,
and one background model ![]() which has high probability to generate the
common English words such as ``the'' and ``a''. A document
which has high probability to generate the
common English words such as ``the'' and ``a''. A document
![]() is regarded as a sample
of the following mixture model:
is regarded as a sample
of the following mixture model: ![\begin{equation*} P(w\vert\theta_d) = (1-\lambda_B)\sum_{j=1}^{k}{[\pi_{d,j}P(w\vert\theta_j)]}+\lambda_B P(w\vert\theta_B) \end{equation*}](/www2006/3020-sun-img47.png) where
where ![]() is a word,
is a word,
![]() is the document
mixing weight associated with the
is the document
mixing weight associated with the ![]() -th theme and
-th theme and
![]() ,
and
,
and ![]() is the mixing
weight for the background model. To estimate the parameters
is the mixing
weight for the background model. To estimate the parameters
![]() , the log-likelihood of the collection is defined:
, the log-likelihood of the collection is defined:
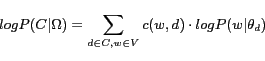 where
where ![]() is the
vocabulary,
is the
vocabulary, ![]() is
the count of word
is
the count of word ![]() in document
in document ![]() . The
purpose is to find good parameters to maximize the
log-likelihood and it can be achieved by a standard EM
algorithm. More details about the EM algorithm can be found
in [21]. After the
document
. The
purpose is to find good parameters to maximize the
log-likelihood and it can be achieved by a standard EM
algorithm. More details about the EM algorithm can be found
in [21]. After the
document ![]() 's mixing weights
to each theme model are achieved,
's mixing weights
to each theme model are achieved, ![]() can be assigned to the cluster by
can be assigned to the cluster by ![]() From the estimated word distribution
From the estimated word distribution ![]() , the most
important words for the
, the most
important words for the ![]() -th theme can be selected by incorporating their
probabilities in
-th theme can be selected by incorporating their
probabilities in ![]() .
These words are representative of the
.
These words are representative of the ![]() -th theme and will be
displayed in our CWS system for the
-th theme and will be
displayed in our CWS system for the ![]() -th cluster. In our
system, the clusters are ranked based on their salience
scores
-th cluster. In our
system, the clusters are ranked based on their salience
scores
![]() .
.
4.3 Extracting Keyphrases for Comparative Clusters
After the page pairs are clustered, we extract keyphrases from each cluster in order to facilitate users' comparisons. As each cluster consists of pages corresponding with two queries, we extract the phrases reflecting the common theme of all these pages in one cluster, as well as those specific to each query. As discussed in Section 4.2, the important words estimated by the clustering algorithm will be used as common keyphrases for each cluster. In this section, we first describe our approach to extracting keyphrases for each page. Then we discuss our entropy based method to select keyphrases specific to each query from the phrases generated in the previous step.
4.3.1 Keyphrase Extraction Algorithm
We use a phrase extraction package, KEX,
implemented in our group to extract keyphrases for each
result page [3]. KEX
is based on a supervised approach. The training examples of
our package are created by three human annotators who
manually extract keyphrases from a collection of Web pages.
For each candidate phrase in a Web page, a 4-dimensional
feature vector
![]() is
constructed. These phrases are used to train a linear
regression model:
is
constructed. These phrases are used to train a linear
regression model:
 (3)
(3)
If a phrase is keyphrase, ![]() ; otherwise,
; otherwise, ![]() . The phrase features include:
. The phrase features include:
(1) PF: phrase frequency. This feature is calculated
in the traditional meaning of term frequency (TF).
Intuitively, frequent phrases are more likely to be better
candidates of keyphrases.
(2) ATF, average frequency of all terms in the
phrase. Sometimes, a keyphrase may have low PF but contain
keyterms with high TF. The ATF feature can be used
to discover this kind of keyphrases.
(3) AIDF, average inverse document frequency
(IDF) of all terms contained in the phrase.
Intuitively, if a phrase contains many terms with low IDF,
it is less informative.
(4) OKA, modified Okapi weighting score. Okapi is a
highly effective document weighting model in information
retrieval [5]. The
formula is:
In our system, we adopt this parameter
setting: ![]() ,
,
![]() ,
, ![]() and
and ![]() . We use
log(OKA) score as a feature.
. We use
log(OKA) score as a feature.
After the feature vectors are constructed for all the
candidate phrases, we train a linear regression model as
described in Equation (3),
where ![]() =PF,
=PF,
![]() =ATF,
=ATF,
![]() =AIDF and
=AIDF and
![]() =log(OKA).
Then we apply this model on every page in each cluster
=log(OKA).
Then we apply this model on every page in each cluster
![]() to rank all
candidate phrases. Those ranked at top are selected as
keyphrases. In our system, all the candidate phrases are
extracted from the title and snippet text returned by
to rank all
candidate phrases. Those ranked at top are selected as
keyphrases. In our system, all the candidate phrases are
extracted from the title and snippet text returned by
![]() . We do not use the
HTML contents to guarantee the efficiency of our
CWS system, as downloading these pages and parsing
them are quite time-consuming.
. We do not use the
HTML contents to guarantee the efficiency of our
CWS system, as downloading these pages and parsing
them are quite time-consuming.
4.3.2 Keyphrase Selection for Clusters
As the query specific keyphrases
summarize the contents contained in sub-clusters
![]() and
and ![]() respectively. We
propose to use the entropy measure to help select
them.
respectively. We
propose to use the entropy measure to help select
them.
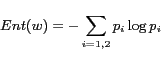
where ![]() (i=1,2)
measures the probability that phrase
(i=1,2)
measures the probability that phrase ![]() occurs in sub-cluster
occurs in sub-cluster
![]() . For each
sub-cluster, all the keyphrases contained in it are
ranked by
. For each
sub-cluster, all the keyphrases contained in it are
ranked by ![]() and
those with low entropies are regarded as query specific
phrases. Intuitively, if a phrase frequently occurs in
one sub-cluster and seldom occurs in the other, it has
low entropy value and will be regarded as a keyphrase
specific to the current sub-cluster.
and
those with low entropies are regarded as query specific
phrases. Intuitively, if a phrase frequently occurs in
one sub-cluster and seldom occurs in the other, it has
low entropy value and will be regarded as a keyphrase
specific to the current sub-cluster.
5 EXPERIMENTS
In this section, we investigate whether our CWS system can help to satisfy Web users' comparison needs. Both the pair-view and the cluster-view modes are used for experiments. Twenty pairs of comparative queries listed in Table 1 are used. We intentionally select the query pairs broadly which reflect different comparison needs: cameras, companies, diseases, and humans, etc.
For evaluation purpose, three human subjects are
requested to annotate all the 20 query pairs. For each
query pair, we submit them to MSN search engine and
retrieve at most the top 50 pages for each query. Each
subject is asked to navigate through the snippet texts of
the 100 pages and manually match the comparative page
pairs. If two pages satisfy the below 3 conditions, they
will be labeled by a subject as a comparative page
pair:
1) The first page is relevant with the first query.
2) The second page is relevant with the second
query.
3) The contents of both pages can help users make
comparisons. The labeling results of all three subjects
are used to evaluate our CWS system.
| 1 | xbox | playstation | 11 | sars | bird flu |
| 2 | Sony dv | Samsung dv | 12 | McDonalds | KFC |
| 3 | Canon sure shot 130u | Olympus stylus epic | 13 | Nike | Adidas |
| 4 | lancome | clinique | 14 | Iraq war | Afghanistan war |
| 5 | Ford Escape | Jeep Liberty | 15 | virtual earth | Google map |
| 6 | PSP | GBA | 16 | Chengxiang Zhai | Jiawei Han |
| 7 | Maradona | Pele | 17 | Sony Camera | Canon camera |
| 8 | Nokia cell phone | Motorola cell phone | 18 | windows | linux |
| 9 | MIT | CMU | 19 | MSN messenger | Google talk |
| 10 | Microsoft | 20 | Bush | Clinton |
5.1 Results of the Comparative Page Pair Ranking
Approach
In this experiment, we evaluate the
effectiveness of the comparative page pairs returned by
CWS in the pair-view mode. As discussed in Section
4.1, we need to compute
![]() and
and ![]() to rank the page pairs
by
to rank the page pairs
by ![]() . In this
experiment, as we use a search engine to retrieve Web
pages, the search engine does not return the relevance
score between a query and a page. We have only the rank
order of the result pages. A straightforward approach to
estimate the relevance between a query
. In this
experiment, as we use a search engine to retrieve Web
pages, the search engine does not return the relevance
score between a query and a page. We have only the rank
order of the result pages. A straightforward approach to
estimate the relevance between a query ![]() and a page
and a page ![]() is:
is:
![]() ,
,
![]() is the rank of the
page in the corresponding search results returned by
is the rank of the
page in the corresponding search results returned by
![]() . The cosine
similarity is used to compute the function
. The cosine
similarity is used to compute the function ![]() in Equation (2) [2].
in Equation (2) [2].
5.1.1 Results Measured by Precision
Based on the
annotated results, we can calculate the precision
measures ![]() of the
comparative pair ranking results. For each page pair,
of the
comparative pair ranking results. For each page pair,
![]() is defined as the
number of comparative page pairs in the top
is defined as the
number of comparative page pairs in the top ![]() pair results divided by
pair results divided by
![]() . In our experiment,
. In our experiment,
![]() take values 1, 5
and 10.
take values 1, 5
and 10.
In Equation (1), the
parameters ![]() ,
,
![]() and
and ![]() may influence
both the construction of page pairs and their ranks in
the result. In order to give equal weights to both
queries, we set
may influence
both the construction of page pairs and their ranks in
the result. In order to give equal weights to both
queries, we set ![]() and require
and require
![]() . Since both
. Since both
![]() and
and ![]() functions take values
from 0 to 1, we vary all possible values of the
parameters
functions take values
from 0 to 1, we vary all possible values of the
parameters ![]() ,
,
![]() ,
, ![]() and
and ![]() and report the
best result achieved by our system. In our experiments,
the values of the above parameters are varied from 0 to 1
with step 0.1.
and report the
best result achieved by our system. In our experiments,
the values of the above parameters are varied from 0 to 1
with step 0.1.
As given in Equation (2), the
comparative information of two pages is calculated
using their snippet texts and URLs. In order to compare
their effectiveness, we also report the results when only
one kind of information is used. As given in Figure
3, ``URL'' corresponds with
![]() in Equation
(2), ``Snippet'' corresponds with
in Equation
(2), ``Snippet'' corresponds with
![]() and
``URL&Snippet'' denotes both kinds of information are
used. In all our experiments, the snippet text of a page
is the combined strings of its title and the snippet
returned by the search engine. In the three cases, all
possible parameters are varied and the best pair ranking
result is reported in Figure 3. For each setting, the evaluation
results of P@1, P@5 and P@10 are all given. All the
precision measures are averaged over the annotation
results of the three subjects.
and
``URL&Snippet'' denotes both kinds of information are
used. In all our experiments, the snippet text of a page
is the combined strings of its title and the snippet
returned by the search engine. In the three cases, all
possible parameters are varied and the best pair ranking
result is reported in Figure 3. For each setting, the evaluation
results of P@1, P@5 and P@10 are all given. All the
precision measures are averaged over the annotation
results of the three subjects.

Figure 3: Precision measures of comparative page pair results
From Figure 3, we can find both the URL and the snippet information are useful when calculating the comparative information of two Web pages. When only one kind of information is used, ``URL'' is better than ``Snippet''. The combination of them leads to better comparative ranking results. The conclusions are consistent when the results are evaluated by P@1, P@5 and P@10 respectively. The best P@10 (in ``URL&Snippet'' setting) precision is 0.57, which indicates 57% page pairs in the top 10 results returned by our CWS system are meaningful comparative page pairs.
5.1.2 Case Studies
In Section 5.1.1, the effectiveness of comparative page pairs are evaluated using precision measure. Here, we also study two cases in order to give intuitive results of our CWS system.
In Table 2, we give the results of two query pairs. The first pair contains two product queries: `Canon Sure Shot 130u' and `Olympus Stylus Epic'. The second consists of query `Afghanistan War' and `Iraq War'. The titles and URLs of each page pair are given side by side but the snippets are omitted for the limit of space.
The two product queries refer to two types of cameras manufactured by Cannon and Sony, respectively. Web users may submit these two queries in order to make comparisons between the two cameras. From the annotation results, we find that all the three subjects annotate the 10 results as comparative page pairs. As listed in Table 2, for the first 9 page pairs, both pages of each pair come from a same website. Take the first pair as an example: DealTime (http://www.dealtime.com/) is an online shopping Web site and the two pages in this pair come from this website. Both pages contain the price information of several shops selling the corresponding cameras. The two pages are automatically discovered by our system and form a comparative pair. As for the second page pair, PhotographReview (http://www.photographyreview.com/) is a site providing information like digital camera and photo equipment reviews. The pages returned by our system are exactly the two containing the customer reviews about the two cameras queried by the user. The next 7 pages are also comparative page pairs of other Web sites. That is, our CWS system can integrate the comparative pages of various Web sites together and present them to end users, which will greatly facilitate Web users' comparison needs. As for the 10th pair returned by our system, the two pages come from Shopping.com and DealTime, respectively, and are put together to form a comparative page pair. This indicates the pages from different Web sites can also be identified to form a comparative page pair.

Figure 4: A comparative page returned for query pair: `Afghanistan war' and `Iraq war'.
Table 2 also gives the results for
the query pair: `Afghanistan war' and `Iraq war'. Web
users may submit the two queries in order to make
comparisons between the two recent wars. We can find
that the 5th page pair consists of only one page.
This page should contain comparative contents
relevant with both wars. This is verified after we
check this page. It is a war report page which
archives articles about the two wars. All the
articles are listed side by side, the left
corresponding with the Iraq war and the right
corresponding with the Afghanistan war. Partial
contents of this page are displayed in Figure
4.
Table 2: Results Returned by CWS in Pair-view Mode
|
q1=`Canon Sure Shot 130u', q2=`Olympus Stylus Epic' |
||
|---|---|---|
| 1. | Canon Sure Shot
130U 35mm Film Camera - Find, Compare, and Buy
at ... http://www.dealtime.com/xPC-Canon Sure Shot 130U |
Olympus Stylus
Epic QD 35mm Film Camera - Find, Compare, and
Buy ... http://www.dealtime.com/xPC-Olympus Stylus Epic QD |
| 2. | Canon Sure Shot 130u
Reviews http://www.photographyreview.com/cat/cameras/film-cameras/point-and-... |
Olympus Stylus Epic
Reviews http://www.photographyreview.com/PRD 84048 3108crx.aspx |
| 3. | Canon Sure Shot
130u - Point & Shoot / Zoom camera -
35mmprices ... http://shopper.cnet.com/Canon Sure Shot 130u Point Shoot Zoom |
Olympus Stylus
Epic QD - Point & Shoot camera - 35mmprices
- CNET ... http://shopper.cnet.com/4014-6503 9-30231950.html?pbrpt=4583 |
| 4. | Canon Sure Shot 130U -
Reviews, Best Prices and Product ... http://www.bizrate.com/marketplace/product info/overview/index... |
Olympus Stylus Epic - Reviews,
Best Prices and Product Information ... http://www.bizrate.com/marketplace/product info/overview/index cat id... |
| 5. | Compare Prices and Read
Reviews on Canon Sure Shot 130U 35mm Film
... http://www.epinions.com/pr-Film Cameras Canon Sure Shot 130u Ca... |
Compare Prices and Read
Reviews on Olympus Stylus Epic Zoom 170 QD
... http://www.epinions.com/pr-Film Cameras Olympus Stylus Epic Zoom 170... |
| 6. | Canon Sure Shot 130u II 35mm
Camera Kit @ Unverse http://www.unverse.com/id-Canon+Sure+Shot+130u+II+35mm+Came... |
Olympus Stylus Epic Zoom 170
QD Date 35mm Camera @ Unverse http://www.unverse.com/id-Olympus+Stylus+Epic+Zoom+170+QD+Da.... |
| 7. | Compare Prices and Read
Reviews on Canon Sure Shot 130U 35mm Film
... http://www.epinions.com/pr-film cameras canon sure shot 130u caption 35mm p... |
Compare Prices and Read
Reviews on Olympus Stylus Epic DLX 35mm
... http://www.epinions.com/elec Cameras-Point And Shoot OlympusStyluss-... |
| 8. | Canon Sure Shot 130u - Point
& Shoot / Zoom camera - 35mm - SLR
... http://www.mysimon.com/Canon Sure Shot 130u Point Shoot Zoom cam... |
Olympus Stylus Epic QD - Point
& Shoot camera - 35mm - SLR ... http://www.mysimon.com/Olympus Stylus Epic QD Point Shoot camera ... |
| 9. | Canon Sure Shot 130u 35mm
Camera w/ Zoom @ Unverse http://www.unverse.com/id-Canon+Sure+Shot+130u+35mm+Camera+w+Zoom-B00006K154 |
Olympus Stylus Epic QD CG Date
35mm Camera @ Unverse http://www.unverse.com/id-Olympus+Stylus+Epic+QD+CG+Date+35mm... |
| 10. | Canon Sure Shot 130U 35mm Film
Camera - Find, Compare, and Buy at ... http://www.shopping.com/xPC-Canon Sure Shot 130U |
Olympus Stylus Epic Zoom 170
QD 35mm Film Camera - Find, Compare ... http://www.dealtime.com/xPC-Olympus Stylus Epic Zoom 170 QD |
|
q1=`Afghanistan War', q2=`Iraq War' |
||
|---|---|---|
| 1. | Afghanistan War .
The Columbia Encyclopedia, Sixth Edition.
2001-05 http://www.bartleby.com/65/af/AfghanWar.html |
Iran- Iraq War .
The Columbia Encyclopedia, Sixth Edition.
2001-05 http://www.bartleby.com/65/ir/IranIraq.html |
| 2. | The Observer--Special
reports--War in Afghanistan http://observer.guardian.co.uk/afghanistan/0,1501,573451,00.html |
Muslims, Islam, and Iraq http://www.uga.edu/islam/iraq.html |
| 3. | Afghanistan
Timeline, 21st Century http://www.mapreport.com/countries/afghanistan.html |
Iraq War
Timeline http://www.infoplease.com/ipa/A0908792.html |
| 4. | Articles about September 11
2001 attacks on USA and subsquent ... http://people.pwf.cam.ac.uk/nwm20/usa afghanistan.htm |
Iraq War http://webhost.bridgew.edu/jhayesboh/iraq.html |
| 5. | War Report - Iraq
War and Afghan Aftermath - compiled by the
... http://www.comw.org/warreport/ |
|
| 6. | Independent Online Edition
> World Politics: http://news.independent.co.uk/world/politics/article313450.ece |
Informed Comment http://www.juancole.com/2004/07/preoccupation-with-iraq-slowed-us- uk.html |
| 7. | Government Resources http://library.louisville.edu/government/subjects/war/afgwar/afgwar.html |
VAIW :: Veterans Against The
Iraq War http://www.vaiw.org/vet/index.php |
| 8. | events 19691979 crises
recovery eec world renewal tensions cartoon
... http://www.ena.lu/europe/crisis-recovery/cartoon-murschetz-afghanistan-war.htm |
Iraq War Cartoons http://www.cartoonistgroup.com/bysubject/theiraqcartoons.php |
| 9. | Amazon.com: The Lessons of
Afghanistan : War Fighting, Intelligence
... http://www.amazon.com/exec/obidos/tg/detail/-/089206417X?v=glance |
Amazon.com: The Iraq War :
Books http://www.amazon.com/exec/obidos/tg/detail/-/1400041996?v=glance |
| 10. | Afghanistan : War Without
End? http://www.pbs.org/newshour/bb/asia/afghanistan/afghan 12-27-85.html |
UNCOVERED: The War on
Iraq http://www.truthuncovered.com/ |
5.2 Results of Comparative Page Clustering and
Keyphrase Extraction
Traditional document clustering relies on the category information as ground truth for evaluation [15]. However there is no such information for all the pages we clustered. Instead, we evaluate the clustering results by investigating the accuracy of the extracted keyphrases.
The KEX package is used to extract keyphrases for each result page [3]. The linear regression model is trained on a set of 300 Web pages which have been manually annotated by three human subjects. This model can achieve a top 10 precision and recall of 0.303 and 0.297 respectively. This result is not bad, because when we evaluate the annotation result of one subject on those of the other two, the average precision at 10 and the recall at 10 is 0.44 and 0.388 respectively. These values indicate that keyphrase extraction is quite subjective and not an easy task. This conclusion is also drawn in previous research works [17]. In this paper, we do not present the evaluation details of our keyphrase extraction algorithm.
| Common Keyphrases | |||
|---|---|---|---|
| 1. | illinois, urbana, champaign (44) | university, filtering, collaborative | mellon university, list, pakdd-2001 tutorials |
| 2. | research, system, database (44) | beespace, automated, news-gazette online | mining, participation, concepts |
| 3. | author, title, resource (44) | annual, information retrieval, embedding | data mining, data, anhai |
| 4. | author, track, kdd (24) | information retrieval, research, anhai | mining, conference, data |
| 5. | usa, tao, award (26) | papers, zhai cs hong, zhang fa | diff, delete, business intelligence |
| Common Keyphrases | |||
|---|---|---|---|
| 1. | date, compact, kit (122) | canon 35mm, ebay canon, canon rebel | film cameras, science stuff, dlx |
| 2. | point, shoot, available (42) | compare, canon buy, compact | zoom, resnick, rambling |
| 3. | read, compare, epinion (26) | cameras, shot 130u caption, canon 8036a006 | dlx, electronic equipment, glorianas court |
| 4. | price, bizrat, online (40) | photo, shot 130u 35mm camera, photo canon | digital, save, day |
| 5. | compare, find, shopper (8) | 35mm film, shot 130u 35mm film camera, cameras | camera-mint, camera, compare |
| 6. | review, consumer, internet (28) | film camera, watch, digital video | equipment used, rooks archives, cg |
| 7. | reviews, 35mm, shoot listings (12) | shoot, reviews canon, 35mm compact | excite partner, photograph, ou |
Table 3
presents the phrases extracted for query pair:
`ChengXiang Zhai' and `Jiawei Han'. Table 4 corresponds the result
of query pair: `Canon Sure Shot 130u' & `Olympus
Stylus Epic'. For each cluster, the top 3 common
keyphrases as well as the top 3 keyphrases specific
to each query are given. As we extract the query
specific keyphrases, those which are sub phrases of
the query are omitted as they do not provide
additional information.
The result given in Table 3 is very interesting. As both the professors are from University of Illinois at Urbana-Champaign, from the three common phrases we can find that the first cluster corresponds with the pages introducing the two professors. The second cluster corresponds with their research works and the third is about their publications. Most query specific phrases also make sense. For example, in the third and fourth clusters, phrases like ``information retrieval'' are extracted for the query ``ChengXiang Zhai'' and phrases such as ``data mining'' are extracted for the query ``Jiawei Han''. This exactly reflects the different research interests between Professor ChengXiang Zhai and Professor Jiawei Han.
As for the results of the two camera queries, the results are also interesting. For the first cluster, the words `date', `compact' and `kit' are extracted as common keyphrases. This is because both the cameras are compact. The two terms `date' and `kit' also frequently appear in all the result pages corresponding with the two queries. According to the common phrases, we can also find that clusters 3, 6 and 7 contain pages on consumer reviews and cluster 4 is about price comparisons.
5.3 Discussions
Based on the above experiments and case studies, we find our CWS system is effective. In the pair-view mode, the percentage of meaningful comparative page pairs in the top 1, 5, 10 results is 80%, 69% and 57% respectively. We can also find the combination of URL and snippet contents is effective in measuring the comparative information of two pages. The case studies also show our comparative page ranking function is able to find those pages which contain comparison information relevant with both input queries.
As Equation (1) indicates,
both the comparative and relevance information help
decide whether two pages form a meaningful
comparative pair. We also did experiments to study
which kind of information is more promising. In this
experiment, the parameter ![]() is fixed and
is fixed and ![]() ,
, ![]() and
and ![]() are varied.
The conclusion is: with the increase of
are varied.
The conclusion is: with the increase of ![]() , the precison
of the pair matching grows steadily. This shows the
relevance information between queries and pages has
no impact on the pair matching result. The reason is:
when the three subjects annotated the 20 queries,
they only identified which two pages form a
comparative pair. They did not rank the pairs
according to their relevance scores with the input
queries. When
, the precison
of the pair matching grows steadily. This shows the
relevance information between queries and pages has
no impact on the pair matching result. The reason is:
when the three subjects annotated the 20 queries,
they only identified which two pages form a
comparative pair. They did not rank the pairs
according to their relevance scores with the input
queries. When ![]() is small, even if those comparative
page pairs which are very relevant with the input
queries can be identified, they do not make extra
contribution to the precison evaluation. At the
beginning of the labeling process, we also asked the
subjects to rank the comparative page pairs. However,
we found ranking them is much more difficult than
just identifying whether two pages form a comparative
pair or not. Thus we need other approaches to
evaluate the ranking order of the comparative page
pairs.
is small, even if those comparative
page pairs which are very relevant with the input
queries can be identified, they do not make extra
contribution to the precison evaluation. At the
beginning of the labeling process, we also asked the
subjects to rank the comparative page pairs. However,
we found ranking them is much more difficult than
just identifying whether two pages form a comparative
pair or not. Thus we need other approaches to
evaluate the ranking order of the comparative page
pairs.
In the cluster-view mode, our CWS system can automatically cluster the comparative information into different themes. The keyphrases are also extracted to summarize the commonness and differences of each theme. The examples given in Section 5.2 show the comparative information produced by CWS are helpful for making comparisons. However, it is hard to quantitively evaluate the clustering results as well as the extracted keyphrases.
6 CONCLUSION AND FUTURE WORK
In this paper, we proposed and studied a novel search problem, Comparative Web Search. We developed a CWS system to help users seek comparative information from the Web. Human evaluations and some case studies show that our system is quite effective to facilitate users' comparative information needs.
In the future, we plan to investigate the following issues:
(1) The evaluation of the comparative Web search system is challenging and labor intensive. In this paper, our evaluation result of the CWS system is based on a relatively small query sets. It is interesting to adopt other approaches to evaluate the effectiveness of comparative search system.
(2) The queries input to the CWS system represent the topics which the users will compare. How to automatically distinguish comparative query pairs is also an interesting problem.
(3) In this paper, we combine the contents and the ranking information of Web pages to construct comparative page pairs. We also plan to incorporate the link structure information to our system.
(4) Our approaches to the comparative Web search problem are still preliminary and our CWS system only provides very basic comparison functionalities. More advanced functions can be added by leveraging other relevant techniques.
In conclusion, the CWS system is challenging but very helpful to satisfy users' comparison needs. We expect to conduct more research work on this direction.
7 Acknowledgments
We thank Dr. ChengXiang Zhai for insightful discussions and Liu Xin for his help on organizing the labeling work and implementing the CWS system. We also thank the reviewers for their valuable suggestions on this work.