Most of the proposals are in the signal processing domain and are mainly based in low-level feature extraction, like color and luminance investigation, motion vector analysis and image texture [2,5,6]; others use the textual (for instance the Close Caption) and/or audio information to provide a high level semantic video description [4,1,3]. Regardless of the approach, the rough idea is to use low-level information to divide the video into several video segments, so that a more precise video description can be provided.
In this work we focus on video news programs and we propose a mechanism based on low-level video features extraction and on high level audio analysis to provide a video description suitable for web indexing. The novelty of our approach is in the integration of audio and video analysis to provide a more realistic video segmentation, by finding out video editing points. In fact, in news programs, most of the editing points should be not treated as cuts (points where a video segment begins or ends), as a news is usually coupled with a video clip that contains several editing points. If only low-level information are used, all the video editing points are treated as cuts causing a single news to be split into several (meaningless) videosegments. Our idea is to consider the audio energy associated to a cut. If silence is detected, the cut is usually the beginning (or the ending) of a news, otherwise it is very likely a simple editing point.
After identifying all the cuts, and hence all the video segments, a speech detector is applied and a high-level semantic description is given in MPEG7 using the audio transcript and the timing properties. In this way, search engines can easily index the video stream.
It is worth noting that our approach differs from the one proposed by Hayashi et al. [1]; Their idea is to perform a video segmentation by analyzing the sole audio stream. Conversely, our approach considers both audio and video analysis to provide a more realistic video segmentation.
The video analysis is in charge of identifying video cuts. A
cut usually represents a camera break or an editing point and can
be detected by analyzing the low-level features of any single
frame. Different techniques are possible: histogram changes,
edges extraction, chromatic scaling. Here, for each video frame
![]() we
combine the YUV components considering that human vision is more
sensitive to brightness than to colors:
we
combine the YUV components considering that human vision is more
sensitive to brightness than to colors:
![]() . The
perceptual difference between two consecutive frames is computed
with
. The
perceptual difference between two consecutive frames is computed
with
![]() , and if this difference
is above a pre-defined threshold (here equal to 10, obtained from
analyzing several videos), a cut is detected.
, and if this difference
is above a pre-defined threshold (here equal to 10, obtained from
analyzing several videos), a cut is detected.
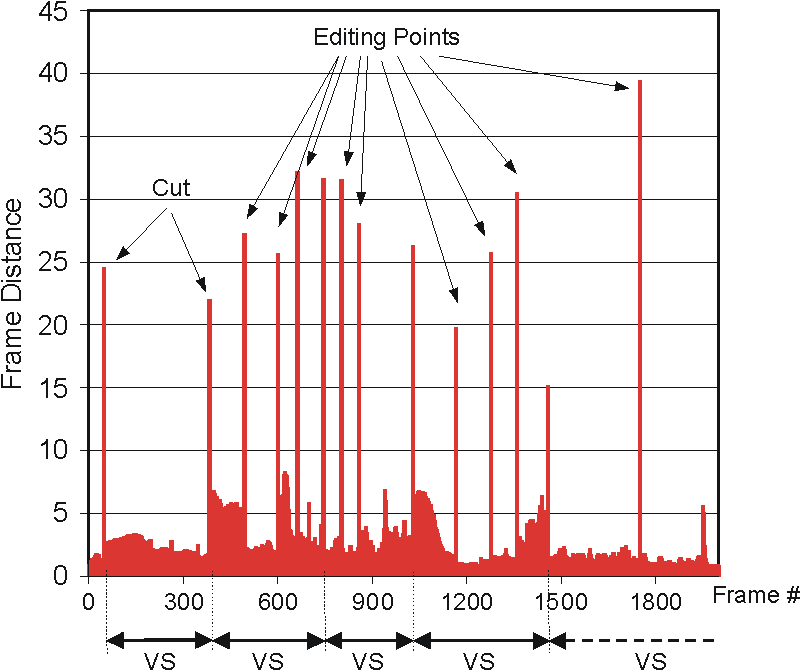
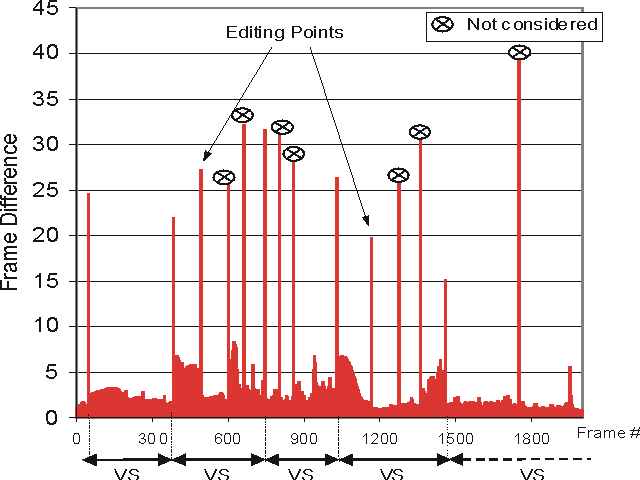
By integrating the audio analysis, it is possible to find out editing points. Figure 2 shows that our mechanism finds out seven (out of nine) editing points and only two are erroneously treated as cuts. Each video segment is then passed to the speech detector and the audio information are then transcribed using MPEG7. Table 1 is an example of the video content description.
|
Cuts detected by analyzing YUV components and audio. |
<Mpeg7> |
<Video> |
... |
<VideoSegment> |
<TextAnnotation><FreeTextAnnotation> |
GARDNER AND OTHER MILITARY ANALYST
WE |
SPOKE TO BELIEVE A CONVENTIONAL
ATTACK |
... ... ... ... ... ... ... ... ...
... |
STRIKING DISTANCE |
</FreeTextAnnotation></TextAnnotation> |
<MediaTime> |
<MediaTimePoint>0:03:17.480</MediaTimePoint> |
<MediaDuration>00:00:14.800</MediaDuration> |
</MediaTime> |
</VideoSegment> |
... |
</Video> |
</mpeg7> |
[1] Y.Hayashi et al., Speech-based and Video-Supported Indexing of Multimedia Broadcast News, Proc. of SIGIR03, July 28-August 1, 2003, Toronto, Canada.
[2] J.Zhou, X.P. Zhang, A Web-Enabled Video Indexing System, Proc. of MIR04, October, 15-16 2004 , New York, ACM
[3] M.R.Naphade, T. S. Huang, Extracting Semantics From Audiovisual Content: The Final Frontier in Multimedia Retrieval, IEEE Transaction on Neural Networks, Vol.13, No.4, July 2002.
[4] N.Babaguchi, Y. Kawai, T.Kitahashi, Event Based Indexing of Broadcasted Sports Video by Intermodal Collaboration, IEEE Transaction on Multimedia, Vol. 4, No. 1, March 2002
[5] J. Yuan, L.Y.Duan, Q.Tian, C.Xu, Fast and Robust Short Video Clip Search Using an Index Sructure, Proc. of MIR04, October 15-16 2004, New York, USA
[6] L.Y. Duan, M. Xu, Q.Tian, C.S. Xu, J.S.Jin, A Unified Framework for Semantic Shot Classification in Sports Video, IEEE Transactions of Multimedia, Vol. 7, No. 6, December 2005
[7] Sphinx Project. Carnegie Mellon University, PittsBurgh. [online]. http:/cmusphinx.sourceforge.net