However, mining clickthrough data is really challenging: (1) the clickthrough data contains heterogeneous objects, including users, queries, and Web pages, and the relationship among these objects are complicated; (2) since users always only click the first few pages for a query, the data is highly sparse. In order to effectively conduct clickthrough data analysis for Web search, it is a key factor to handle the sparseness problem and discover the hidden relations among the heterogeneous data objects.
In this paper, we propose a framework to overcome the above difficulties. This framework contains the following two steps. (1) The hidden cluster structures contained in the clickthrough data, as well as the probabilistic relations among them, are discovered by an unsupervised method: cube-clustering. (2) The relations among the hidden clusters are used to improve the search performance in a collaborative manner. Since we exploit the group structures of the clickthrough data and our approach is motivated by the collaborative filtering idea, we name it Collaborative Web Search (CWS). In [3], the authors also developed a collaborative search system named I-SPY. Their system is a type of meta-search engine and requires users to explicitly select a community before search activities are conducted. In our CWS framework, the clickthrough data is automatically utilized and Web users' manual efforts are not required.
We treat a cube data of the three dimensions: user, query, and
Web page, as a joint probability distribution among three
discrete random variables: ![]() .
Variables
.
Variables ![]() ,
, ![]() and
and
![]() take values from the user set
take values from the user set
![]() , query set
, query set
![]() , and page set
, and page set
![]() . Our goal is
to cluster the
. Our goal is
to cluster the ![]() users,
users, ![]() queries, and
queries, and ![]() pages
into
pages
into ![]() ,
, ![]() and
and ![]() clusters respectively:
clusters respectively:
![]() ,
,
![]() ,
,
![]() . We
use
. We
use ![]() and
and ![]() to denote the mapping functions and refer to the
triple
to denote the mapping functions and refer to the
triple
![]() as a cube
clustering.
as a cube
clustering.
Given the mapping functions
![]() ,
, ![]() ,
, ![]() , and
, and
![]() are the cluster random
variables and we denote them as
are the cluster random
variables and we denote them as ![]() ,
, ![]() ,
,
![]() respectively. Apparently,
a fixed cube clustering mapping determines the joint probability
of the cluster random variables. We judge the quality of cube
clustering by the loss in multi-information. The
multi-information is a measurement to capture the amount of
information that a set of variables contain about each other.
Naturally, a good clustering should preserve the information of
the original data as much as possible, thus minimize the loss in
multi-information:
respectively. Apparently,
a fixed cube clustering mapping determines the joint probability
of the cluster random variables. We judge the quality of cube
clustering by the loss in multi-information. The
multi-information is a measurement to capture the amount of
information that a set of variables contain about each other.
Naturally, a good clustering should preserve the information of
the original data as much as possible, thus minimize the loss in
multi-information:
![]() . This is also the
objective function that an optimal cube clustering minimizes,
subject to the constraints on the cluster numbers in each
dimension. For a cube clustering, we find the loss in
multi-information is equal to the KL divergence between
. This is also the
objective function that an optimal cube clustering minimizes,
subject to the constraints on the cluster numbers in each
dimension. For a cube clustering, we find the loss in
multi-information is equal to the KL divergence between
![]() and
and
![]() , where
, where
![]() is a
distribution of the form
is a
distribution of the form
where
![]() . That is, the
cube clustering can be approached by minimizing the KL divergence
between
. That is, the
cube clustering can be approached by minimizing the KL divergence
between ![]() and
and
![]() . We can also
prove that the loss in multi-information can be expressed as a
weighted sum of the KL-divergence between two distributions
associated with a fixed dimension. Thus the calculation of the
objective function can be solely expressed in terms of user
clustering, query clustering, or page clustering. Based on this
conclusion, we have the Cube-Clustering algorithm. We omit all
the proofs for the space reason.
. We can also
prove that the loss in multi-information can be expressed as a
weighted sum of the KL-divergence between two distributions
associated with a fixed dimension. Thus the calculation of the
objective function can be solely expressed in terms of user
clustering, query clustering, or page clustering. Based on this
conclusion, we have the Cube-Clustering algorithm. We omit all
the proofs for the space reason.
The input of the Cube-Clustering algorithm is the joint
probability ![]() . Assume
. Assume ![]() are the desired number of
clusters for each dimension. The output is the partition function
are the desired number of
clusters for each dimension. The output is the partition function
![]() . The Cube-Clustering
algorithm is described as follows:
. The Cube-Clustering
algorithm is described as follows:
Step 1: Start with some initial partition functions, thus
for each ![]() ,
, ![]() ,
,
![]() , we have its corresponding
cluster. Compute
, we have its corresponding
cluster. Compute
Step 2: (2.1) Calculate the distributions
![]() ,
,
![]() using
using
(2.2) Update user clusters: for each
![]() , find its new cluster index
as
, find its new cluster index
as
(2.3) Update the distributions listed in Eq 2.
Step 3: Process queries and pages symmetrically as in step 2.
Step 4: Iterate Step 2 and Step 3 until the change in
objective function is less than a small value, e.g., ![]() ; else go to step
2.
; else go to step
2.
After the cube-clustering step, the Web search
problem is converted to recommendation of a ranked page list
according to their relevance with the
![]() pair,
instead of depending only on
pair,
instead of depending only on ![]() . In our
CWS framework, we rank Web pages by estimating
. In our
CWS framework, we rank Web pages by estimating
![]() . Given
. Given
![]() and
and ![]() ,
,
Thus according to Eq (4), the Web pages are ranked by
![]() .
.
| Relative Improvement | |||
|---|---|---|---|
| 1 | 0.581887 | 0.632321 | 8.66% |
| 2 | 0.315347 | 0.339479 | 7.75% |
| 3 | 0.214571 | 0.232106 | 8.17% |
| 4 | 0.162961 | 0.176383 | 8.23% |
| 5 | 0.131669 | 0.141973 | 7.82% |
We use 10 days' clickthrough data for experiments, the first 5
days' data is used for estimating the cluster structures and the
rest 5 days' for testing. The search accuracy is evaluated using
the ![]() measure, that is, the
percentage of correct pages among the top
measure, that is, the
percentage of correct pages among the top ![]() pages. We compared the result of CWS and Pearson
collaborative filtering algorithm (CF) [1]. The results are given in Table
1.
pages. We compared the result of CWS and Pearson
collaborative filtering algorithm (CF) [1]. The results are given in Table
1. ![]() is varied from 1 to 5. We can see the CWS approach leads
to better search result compared with CF (around 8%
improvement).
is varied from 1 to 5. We can see the CWS approach leads
to better search result compared with CF (around 8%
improvement).
This shows the CF algorithm can not effectively exploit the clickthrough data as the data is three-way and highly sparse. However, the cluster structures can be discovered by the Cube-Clustering algorithm and the probabilistic relations among them can be utilized for improving Web search. This validates the effectiveness of our CWS approach: leveraging the clickthrough data for collaborative Web search.
[1] J. S. Breese, D. Heckerman, and C. Kadie. Empirical analysis of predictive algorithms for collaborative filtering. In UAI, pages 43-52. Morgan Kaufman, 1998.
[2] I. S. Dhillon, S. Mallela, and D. S. Modha. Information-theoretic co-clustering. In SIGKDD, pages 89-98, 2003.
[3] B. Smyth, E. Balfe, O. Boydell, K. Bradley, P. Briggs, M. Coyle, and J. Freyne. A live-user evaluation of collaborative web search. In IJCAI, pages 1419-1424, 2005.
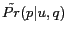
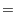
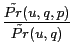
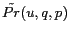
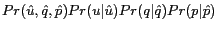
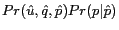 (4)
(4)