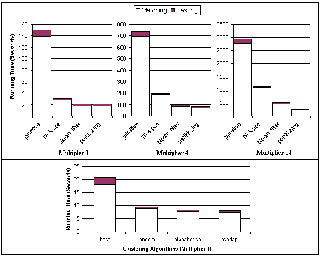
Figure 3.1: Running times of the various algorithm optimizations for different numbers of queries.
Prospective search can be performed with the help of RSS feeds. RSS (RSS 2.0: Really Simple Syndication) is an XML-based data format that allows web sites and weblogs to syndicate their content by making all new content, or at least meta data about new content, available at a specified location. Thus, a prospective search engine can find new content by periodically downloading the appropriate RSS feed.
In this paper, we study techniques for optimizing the performance
of prospective search engines. We focus on keyword queries with
particular emphasis on AND queries. However, Boolean keyword
queries can also be supported easily: We convert them to DNF,
insert each conjunction as a separate AND query, and remove
duplicate matches from the output. For more details about this
work, see [4].
Each query in our system has a unique integer query ID (QID) and each term has an integer term ID (TID). Each incoming document has a unique document ID (DID) and consists of a set of TIDs, and the output of the matching algorithm consists of a stream of (QID, DID) pairs, one for each time a document satisfies a particular query. The terms in each query are ordered by TID; thus we can refer to the first, second, etc. term in a query. Any incoming documents have already been preprocessed by parsing out all terms, translating them into TIDs, and discarding any duplicate terms or terms that do not occur in any query.
The main data structure used in all our algorithms is an inverted index, which is also used by retrospective search engines. In our case we index the queries rather than the documents, as proposed in [5]. The inverted index consists of inverted lists, one for each unique term that occurs in the queries. Each list contains one posting for each query in which the corresponding word occurs, where a posting consists of the QID and the position of the term in the query (recall that terms are ordered within each query by TID). Since (QID, position) can be stored in a single 32-bit integer, each inverted list is a simple integer array.
Exploiting Position Information and Term Frequencies: We note that the primitive algorithm creates an entry in the hash table for any query that contains at least one of the terms. This results in a larger hash table that in turn slows down the algorithm, due to additional work that is performed but also due to resulting cache misses during hash lookups. To decrease the size of the hash table, we first exploit the fact that we are focusing on AND queries. Recall that each index posting contains (QID, position) pairs. Suppose we process the terms in the incoming document in sorted order, from lowest to highest TID. This means that for a posting with non-zero position, either there already exists a hash entry for the query, or the document does not contain any of the query terms with lower TID, and thus the query does not match. So we create a hash entry whenever the position in the posting is zero, and only update existing hash entries otherwise. A further reduction is achieved by simply assigning TIDs to terms in order of frequency (we assign TID 0 to the least frequent term). So an accumulator is only created for those queries where the incoming document contains the least frequent term in the query.
Bloom Filters: As a result of previous optimizations, hash entries are only created initially, and most of the time is spent afterwards on lookups to check for existing entries. Moreover, most of these checks are negative. To speed them up, we propose to use a Bloom filter [1], which is a probabilistic space-efficient method for testing set membership.
We use a Bloom filter in addition to the hash table. In the matching phase, when hash entries are created, we also set the corresponding bits in the Bloom filter; the overhead for this is fairly low. In the testing phase, we first perform a lookup into the Bloom filter to see if there might be a hash entry for the current QID. If the answer is negative, we immediately continue with the next posting; otherwise, we perform a hash table lookup. Since the Bloom filter structure is small, this results in fewer processor cache misses.
Partitioning the Queries: We note that the hash table and Bloom filter sizes increase linearly with the number of query subscriptions, and thus eventually grow beyond the L1 or L2 cache sizes. Instead of creating a single index, we propose to partition the queries into p subsets and build an index on each subset. An incoming document is then processed by performing the matching sequentially with each of the index partitions. While this does not decrease the number of postings traversed, or the locality for index accesses, it means that hash table and Bloom filter sizes are decreased by a factor of p, assuming we clear them after each partition.
Clustering: Our next idea is to exploit
similarities between different subscriptions. In a preprocessing
step, we cluster all queries into artificial
superqueries of up to a certain size, such that every
query shares the same least frequent term with a superquery. We
employ greedy algorithms to construct superqueries. In the
algorithms we consider queries in arbitrary order (random), in
sorted order (alphabetical), or check all the candidates to
maximize an overlap ratio (overlap). In related work, Fabret et
al. [3] study how
to cluster subscriptions for improved throughput; however the
focus is on more structured queries rather than
keywords.
[1] B. Bloom, Space/time trade-offs in hash coding with allowable errors, Communications of the ACM, 13(7):422-426, 1970.
[2] A. Carzaniga and A. L. Wolf, Forwarding in a content-based network, In Proc. of ACM SIGCOMM, 2003.
[3] F. Fabret, H. A. Jacobsen, F. Llirbat, J. Pereira, K. A. Ross, and D. Shasha, Filtering algorithms and implementation for very fast publish subscribe systems. In Proc. of ACM SIGMOD Conf., 2001.
[4] U. Irmak, S. Mihaylov, T. Suel, S. Ganguly, and R. Izmailov, Efficient Query Subscription Processing for Prospective Search Engines. In Proc. of USENIX Annual Technical Conference, 2006.
[5] T. W. Yan and H. Garcia-Molina, The SIFT information dissemination system, ACM Transactions on Database Systems, 24(4):529-565, 1999.