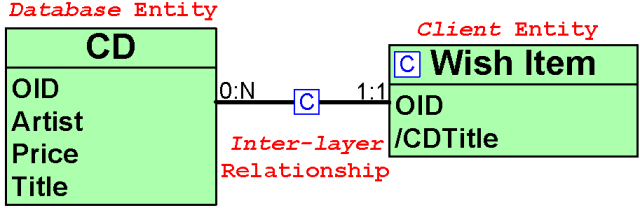
Figure 1: Example of RIA Data model
Data model. While in traditional data-intensive Web applications content resides solely at the server-side (in the form of database tuples or as user session-related main memory objects), in RIAs content can also reside in the client, as main memory objects with the same visibility and duration of the client application, or, in some technologies, as persistent client-side objects. Data are therefore characterized by two different dimensions: the architectural tier of existence, which can be the server or the client, and the level of persistence, which can be permanent or temporary. In WebML, where the data model is represented by Entity-Relationship diagrams, we stereotype entities and relationships with their persistence level. Figure 1 depicts a well-formed data schema. For example, we stereotype as database the data permanently stored in a server-side data management system (e.g., a relational or XML database); as client the data that are temporarily stored at the client side, for the duration of the application run. A data schema extended with these two persistence levels is well-formed if the following constraint holds: relationships with database persistence connect entities with database persistence only(i.e. persistent relationships cannot connect temporary entities).
Hypertext model in the large. Hypertext modeling in the
large specifies the general structure of the front-end: it
organizes the hypertext taking into account the different classes
of users, and structures it into pages, possibly clustered into
areas having a specific purpose, and possibly organized in a
hierarchy composed of nested pages. From the technological
standpoint RIAs have a different physical structure than
traditional data-intensive Web applications: the former typically
consist of a single application "shell" (e.g., a Java applet or a
FLASH movie), which loads different data and components based on
the user's interaction. The latter consist of multiple
independent templates, processed by the server and simply
rendered by the client. However, the hypertext modeling metaphor
remains a good description of the dynamics of the interface also
for RIAs, especially in the case of hybrid applications, which
comprise a mix of traditional page templates and RIA
components.
To cope with the specificity of RIAs, where pages, or fragments
thereof, can be executed either at the server-side or at the
client-side, the notion of page in WebML has been extended, by
stereotyping it as: 1) Server page: it represents a
traditional Web page; content and presentation are calculated by
the server, whereas rendering and event detection are handled by
the client. Events triggering some business logic (not bound to
the presentation layer) are processed at server-side. 2)
Client page: it represents a page incorporating content or
logics managed (at least in part) by the client. Its content can
be computed at the server or client side, whereas presentation,
rendering and event handling occur at the client side. Events can
be processed locally at the client or dispatched to the
server.
Hypertext model in the small. Hypertext modeling in the
small refines the coarse model of the application with details
about the content of pages, the links for user's
interaction, and the operations triggered by the
user.
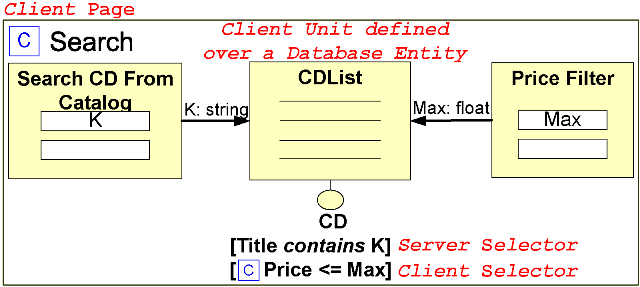
The content of pages in WebML is represented with a visual
notation as a graph of content units connected by links.
Figure 2 depict an example of a
RIA hypertext model. Links express both parameter passing, needed
for computing the data of parametric units, and user interaction,
needed for triggering page (re)computation. In traditional Web
applications, content unit processing occurs on the server: data
is extracted from a database entity, logical conditions
(called selector conditions in WebML) can be specified to
filter the entity instances, and ordering clauses specify
how they have to be sorted. In RIAs, computation is
distributed between the server and the client, according to
the page type: units contained in a server page are computed by
the server (server units), like in traditional Web
applications, and units contained in a client page are managed by
the client (client units). The WebML content unit is
extended with the possibility of specifying the source entity,
the selector conditions and ordering clauses either on the server
or on the client. A unit is well-formed if the following
constraints hold: a) server units cannot be specified on a client
entity and cannot comprise client-side selectors and ordering
clauses; b) a client unit that draws content from a client
entity, cannot contain server-side selector conditions or
ordering clauses. These constraints ensure that all the
computations performed by the server rely only on data and
operations computable at the server-side and thus cope with the
asymmetric nature of the Web, where the client calls the server
and not vice versa.
WebML operations model arbitrary business logic and
predefined content updates (creating, deleting or modifying
entities, connecting or disconnecting pairs of entity instances
belonging to a relation). In the RIA context, operations can be
executed by the client or by the server, as captured by the
following definitions: 1) server operation: a piece of
business logic or data update executed by the server; 2)
client operation: a piece of business logic executed by
the client or an update on a client-side entity or relationship;
3) operation chain: a sequence of operations, possibly
mixing client and server operations.
In order to fit the RIA paradigm, operation composition
constraints and a new semantic of page computation have also been
defined.
[1] Joshua Duhl
White paper: Rich Internet Applications.
IDC, 2003
[2]S. Ceri and P. Fraternali and M. Brambilla and A. Bongio
and S. Comai and M. Matera.
Designing Data-Intensive Web Applications.
Morgan Kaufmann, 2002
IDC, 2003
[3]P.Fraternali.
Tools and Approaches for Developing Data-Intensive Web
Applications: A Survey.
ACM Comput. Surv., Pages 227-263, Volume 31, 1999