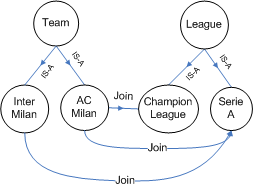
Figure 1: A partial domain ontology for the Italian soccer teams.
In the Semantic Web, domain ontology is commonly used to describe web resources. Containing semantics in the form of concepts, relations and axioms, domain ontology enables software agents to perform more sophisticated tasks automatically. Specifically, many applications have been developed for information retrieval. For instance, Guha et al. [2] used ontology to improve traditional web search by augmenting search results with related concepts in the ontology.
Although there have been many applications of domain ontology, relatively few are concerned with providing personalized information services. In this paper, we propose using an ontology based user model for representing a personalized view of the target domain to capture a user's interests and a set of statistical methods for learning the user ontology. We further incorporate the proposed user ontology model and the SAT [1] based inferencing procedure into a semantic search engine for searching academic publications.
Figure 1: A partial domain ontology for the Italian soccer teams.
Considering the sample domain ontology given in Figure 1, that represents a basic conceptualization of the Italian soccer teams. We see that ``AC Milan'' and ``Inter Milan'' are Italian soccer teams belonging to different leagues. But this domain ontology may be too general for individual's interests. For instance, I can be a big fan of the AC Milan team. Therefore, the concept ``AC Milan'' is more important to me than the concept ``Inter Milan''. Meanwhile, joining Champion League is more important to me than joining the Serie A League. The existing user modelling methods only consider the importance of the concepts for capturing user's interests. A user ontology, on the other hand, can capture all necessary semantics from a domain ontology for user modelling. Specifically, each concept and relation in the domain ontology will be given certain values for indicating user's interests. It is a personalized view of the conceptualization and is more comprehensive than the existing types of user models. An illustration of the user ontology is given in Figure 2, in which concepts and relations have been given specific values to indicate their relevance to a user.
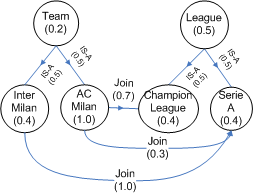
Figure 2: An illustration of the user ontology.
A user ontology can be defined formally as a structure
![]() = (C,
R,
= (C,
R,![]() ,
,![]() ,
,![]() )
consisting of
)
consisting of
Estimating the interest factor
Cx of a user on a concept is relatively
straightforward. For instance, we can record the concepts of
interests to the user and their frequencies when a user searches
information in the web. Meanwhile, we use a decay function
[1], given by
Cx(ti+1) =
Cx(ti) x 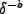 , to prevent saturation of the
interest factor Cx in the user ontology.
, to prevent saturation of the
interest factor Cx in the user ontology.
Learning relations of interests to a user is similar to learning concepts of interests. Initially, an estimated value Rxy0 is assigned to each relation rxy. Then, an empirical value is computed for each relation by analyzing the historical record. We used a Bayesian solution to compute a weighted average of the initial value and the empirical value as follows:
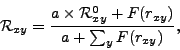 |
(1) |
where a is a constant to normalize the empirical value and the initial estimation, and F(rxy) is the frequency of the relation rxy obtained from the user's historical record.
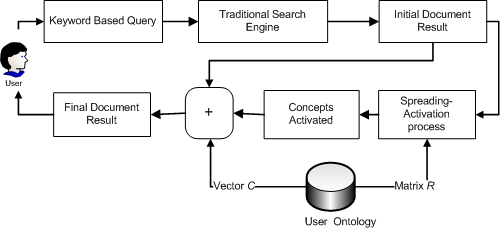
Figure 3: The procedure for exploiting user ontology in document retrieval.
We present a procedure (Figure 3) wherein a user ontology is used to re-rank the search results of a search engine below.
Similar to that of a traditional search engine, a user submits
a query consisting of keywords to the system. The search engine
then returns an initial list of documents obtained using the
classical keyword based search method. With the documents
pre-annotated with concepts, we can obtain a set of associated
concepts besides the documents retrieved. These concepts together
with their occurrence frequencies form a vector
I = [I1, I2,...,
In]T as the input for inferencing in
the user ontology, where Ix, the input to the
concept cx, is calculated by
Ix = 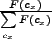 ,
where F(cx) represents the frequency of
the concept cx in the initial document
list.
,
where F(cx) represents the frequency of
the concept cx in the initial document
list.
Upon receiving the input vector I, the spreading
activation process is performed on the user ontology to infer the
concepts of relevance. Using simplified SAT in which the output
of a concept cy at time ti is
the input of the concept cy at time
ti,
Ocy(ti) =
Icy(ti), the
spreading activation process can be expressed using the following
formula:
where
![]() is the relation matrix of
the user ontology,
is the relation matrix of
the user ontology, ![]() is the decay
factor,
is the decay
factor,
![]() is an
n x n identity matrix, and
O = [O1,...,
On]T is the final output vector of
the spreading-activation process in which Ox is
the value of concept cx obtained from the
spreading-activation process.
is an
n x n identity matrix, and
O = [O1,...,
On]T is the final output vector of
the spreading-activation process in which Ox is
the value of concept cx obtained from the
spreading-activation process.
Next, the relevance factor Ox is combined
with the user's long term interest factor
![]() x to derive a
final score Sx for the concept
cx. The score strikes a balance between long
time interest and current relevance. In our application, the
score Sx is computed by
Sx = Ox +
x to derive a
final score Sx for the concept
cx. The score strikes a balance between long
time interest and current relevance. In our application, the
score Sx is computed by
Sx = Ox + ![]() x x , where
x x , where ![]() represents the time interval since the last query and b is
a real-valued constant to simulate the decay function.
represents the time interval since the last query and b is
a real-valued constant to simulate the decay function.
Finally, documents with high rankings in the initial list and annotated with concepts with high S values are moved towards the top of the list for presentation to the user.
A semantic search engine that incorporates user ontology and SAT has been developed for searching academic publication in a database. All documents collected are annotated using the ACM Computing Classification System, which also serves as the domain ontology.
5 users are involved in evaluating the user ontology's ability for providing personalized services. Each user provides two sets of queries, one for training the model and the other for testing. We experiment with the semantic search engine, first using the traditional keyword based method, then augmented with domain ontology, and finally enhanced with user ontology to provide recommendation for the test queries. The performance of the search engine, in terms of the average precision of the top 10 documents retrieved, is summarized in Figure 4. We see that the user ontology based system consistently outperforms or produces equivalent performance compared with the two methods, validating our approach of using user ontology as user models in the Semantic Web.
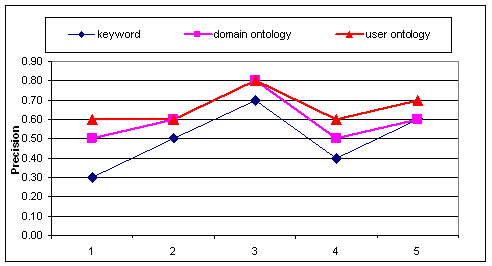
Figure 4: Average precision of the semantic search engine with and without the use of user ontology in document retrieval compared with keyword based method.
[1] R. J. Anderson. A spreading activation theory of memory. In Journal of Verbal Learning and Verbal Behavior 22, pages 261-295, 1993.
[2] R. Guha, R. McCool, and E. Miller. Semantic Search. In WWW, pages 700-709, 2003.