In 1996 the W3C started to work on XML as a way to enable data interoperability over the internet; today, XML is the standard for information representation, exchange and publishing over the Web. In 2003 about 3% of global network traffic was encoded in XML; this is expected to rise to 24% by 2006, and to at least 40% by 2008 [15]. XML is also seeping into many applications [1].
XML is popular because it encodes a considerable amount of metadata in its plain-text format; as a result, applications can be more savvy about the semantics of the items in the data source. This comes at a cost. At the core, the challenge in XML processing is three-fold. First, XML documents have a natural tree-structure, and many of the basic tasks that are quite easy on arrays and lists--such as indexing, searching and navigation--become more involved. Second, by design, XML documents are wordy since they nearly repeat the entire schema description for each data item. Therefore, data collections become more massive in their XML representations, and present problems of scale. As a result, XML can be ``inefficient and can burden a company's network, processor, and storage infrastructures'' [15]. Finally, XML documents have mixed elements with both text and numerical or categorical attributes. As a result, XML queries are richer than commonly used SQL queries; they, for example, include path queries on the tree structure and substring queries on contents.
In this paper we address these basic challenges. In particular, we address the problems of how to compress XML data, how to provide access to its contents, how to navigate up and down the XML tree structure (cfr. DOM tree), and how to search for simple path expressions and substrings. The crux is, we focus on doing all of these tasks while keeping the data still in its compressed form and uncompressing only a tiny fraction of the data for each operation.
Problems and the Background. As the relationships between
elements in an XML document are defined by nested structures, XML
documents are often modeled as trees whose nodes are labeled with
strings of arbitrary length drawn from a usually large alphabet
![]() . These strings are
called tag or attribute names for the internal
nodes, and content data for the leaves (shortly
PCDATA). See Fig. 1 for
an example. Managing XML documents (cfr. their DOM tree)
therefore needs efficient support of navigation and
path expression search operations over their tree
structure. With navigation operations we mean:
. These strings are
called tag or attribute names for the internal
nodes, and content data for the leaves (shortly
PCDATA). See Fig. 1 for
an example. Managing XML documents (cfr. their DOM tree)
therefore needs efficient support of navigation and
path expression search operations over their tree
structure. With navigation operations we mean:
With path expressions, we mean two basic search operations that involve structure and content of the XML document tree:
The first search operation, called SubPathSearch,
corresponds to an XPATH query having the form
/![]() , where
, where
![]() is a fully-specified
path consisting of tag/attribute names. The second search
operation, called ContentSearch, corresponds to an
XPATH query of the form /
is a fully-specified
path consisting of tag/attribute names. The second search
operation, called ContentSearch, corresponds to an
XPATH query of the form /![]() [contains(.,
[contains(.,![]() )], where
)], where
![]() is a fully-specified
path and
is a fully-specified
path and ![]() is an arbitrary
string of characters.
is an arbitrary
string of characters.
The text book solution to represent the XML document tree for
navigation--finding parents and children of nodes in the
tree--uses a mixture of pointers and hash arrays. Unfortunately,
this representation is space consuming and practical only for
small XML documents. Furthermore, while tree navigation takes
constant time per operation, SubPathSearch and
ContentSearch need the whole scan of the document tree
which is expensive. In theory, there are certain sophisticated
solutions (see [5,
14] and references therein) for tree navigation in succinct
space but they do not support the search operations above. If
SubPathSearch is a key concern, we may use any summary
index data structure [6] that represents
all paths of the tree document in an index (two famous
examples are Dataguide [16] and ![]() - or
- or ![]() -indexes [22]). This significantly
increases the space needed by the index, and yet, it does not
support ContentSearch queries efficiently. If
ContentSearch queries are the prime concern, we need to
resort more sophisticated approaches-- like XML-native search
engines, e.g. XQUEC [4], F&B-INDEX
[29], etc.; all of
these engines need space several times the size of the XML
representation.
-indexes [22]). This significantly
increases the space needed by the index, and yet, it does not
support ContentSearch queries efficiently. If
ContentSearch queries are the prime concern, we need to
resort more sophisticated approaches-- like XML-native search
engines, e.g. XQUEC [4], F&B-INDEX
[29], etc.; all of
these engines need space several times the size of the XML
representation.
At the other extreme, XML-conscious compressors such as [21,3,8]--do compress XML data into small space, but any navigation or search operation needs the decompression of the entire file. Even XML-queryable compressors like [27,23,10], that support more efficient path search operations, incur into the scan of the whole compressed XML file and need the decompression of large parts of it in the worst case. This is expensive at query time.
Recently, there has been some progress in resolving the
dichotomy of time-efficient vs space-efficient solutions
[11]. The contribution in
[11] is the XBW
transform that represents a labeled tree using two
arrays: the first contains the tree labels arranged in an
appropriate order, while the second is a binary array encoding
the structure of the tree. The XBW transform can be
computed and inverted in (optimal) linear time with respect to
the number of tree nodes, and is as succinct as the information
contained in the tree would allow. Also, [11] shows that navigation and
search operations over the labeled tree can be implemented over
the XBW transform by means of two standard query
operations on arrays: rank
![]() computes the
number of occurrences of a symbol
computes the
number of occurrences of a symbol ![]() in the array prefix
in the array prefix ![]() ; select
; select
![]() computes the
position in
computes the
position in ![]() of the
of the ![]() th occurrence of
th occurrence of
![]() . Since the
algorithmic literature offers several efficient solutions for
rank and select queries (see [5,17] and references therein), the
XBW transform is a powerful tool for compressing and
searching labeled trees.
. Since the
algorithmic literature offers several efficient solutions for
rank and select queries (see [5,17] and references therein), the
XBW transform is a powerful tool for compressing and
searching labeled trees.
Our Contribution. The result in [11] is theoretical and relies on
a number of sophisticated data structures for supporting
rank and select queries. In this paper, we show how
to adapt XBW transform to derive a compressed searching
tool for XML, and present a detailed experimental study comparing
our tools with existing ones. More precisely, our contribution is
as follows.
(1) We present an implementation of the XBW
transform as a compressor (hereafter called
XBZIP). This is an attractively simple compressor,
that relies on standard compression methods to handle the two
arrays in the XBW transform. Our experimental studies show
that this is comparable in its compression ratio to the
state-of-the-art XML-conscious compressors (which tend to be
significantly more sophisticated in employing a number of
heuristics to mine some structure from the document in order to
compress ``similar contexts''). In contrast, the XBW
transform automatically groups contexts together by a simple
sorting step involved in constructing the two arrays. In
addition, XBZIP is a principled method with
provably near-optimal compression [11].
(2) We present an implementation of the XBW
transform as a compressed index (hereafter called
XBZIPINDEX). This supports
navigation and search queries very fast uncompressing only a tiny
fraction of the document. Compared to similar tools like
XGRIND [27],
XPRESS [23] and
XQZIP [10],
the compression ratio of XBZIPINDEX
is up to 35% better, and its time performance on
SubPathSearch and ContentSearch search operations
is order of magnitudes faster: few milliseconds over hundreds of
MBs of XML files versus tens of seconds (because of the scan of
the compressed data inherent in these comparable tools). The
implementation of XBZIPINDEX is
more challenging since in addition to the XBW transform,
like in [11], we need
data structures to support rank and select
operations over the two arrays forming XBW. Departing from
[11] which uses
sophisticated methods for supporting these operations on
compressed arrays, we introduce the new approach of treating the
arrays as strings and employing a state-of-the-art string
indexing tool (the FM-index [13]) to support
structure+content search operations over the document
tree. This new approach of
XBZIPINDEX has many benefits since
string indexing is a well-understood area; in addition, we retain
the benefits of [11] in
being principled, with concrete performance bounds on the
compression ratio as well as time to support navigation and
search operations.
Both the set of results above are obtained by suitably modifying
the original definition of XBW given in [11] that works for labeled trees
to better exploit the features of XML documents. The final result
is a library of XML compression and indexing functions,
consisting of about 4000 lines of C code and running under Linux
and Windows. The library can be either included in another
software, or it can be directly used at the command-line with a
full set of options for compressing, indexing and searching XML
documents.
XBZIPINDEX has additional features and may find other applications besides compressed searching. For example, it supports tree navigation (forward and backward) in constant time, allows the random access of the tree structure in constant time, and can explore or traverse any subtree in time proportional to their size. This could be used within an XML visualizer or within native-XML search engines such as XQUEC [4] and F&B-INDEX [29]. There are more general XML queries like twig or XPath or XQuery; XBZIPINDEX can be used as a core to improve the performance of known solutions. Another such example is that of structural joins which are key in optimizing XML queries. Previous work involving summary indexes [7,19], or node-numbering such as VIST [28] or PRUFER [25] might be improved using XBZIPINDEX.
Figure 1: An XML document ![]() (left) and its
corresponding ordered labeled tree
(left) and its
corresponding ordered labeled tree ![]() (right).
(right).
<biblio>
<book id=1>
<author>J. Austin</author>
<title>Emma</title>
</book>
<book id=2>
<author>C. Bronte</author>
<title>Jane Eyre</title>
</article>
</biblio>
|
![\includegraphics[width=7cm]{jane4.eps}](6009-ferragina-img26.png) |
Given an arbitrary XML document ![]() , we now show how to build an ordered labeled tree
, we now show how to build an ordered labeled tree
![]() which is equivalent
to the DOM representation of
which is equivalent
to the DOM representation of ![]() .
Tree
.
Tree ![]() consists of four
types of nodes defined as follows:
consists of four
types of nodes defined as follows:
The structure of the tree ![]() is defined as follows (see Figure 1). An XML well-formed substring of
is defined as follows (see Figure 1). An XML well-formed substring of
![]() , say
, say ![]() <t
a
<t
a![]() ="
="![]() "
" ![]() a
a![]() ="
="![]() ">
"> ![]() </t>, generates a subtree of
</t>, generates a subtree of ![]() rooted at a node labeled <t. This
node has
rooted at a node labeled <t. This
node has ![]() children (subtrees)
originating from
children (subtrees)
originating from ![]() 's
attribute names and values (i.e. @a
's
attribute names and values (i.e. @a
![]() ), plus other
children (subtrees) originating by the recursive parsing of the
string
), plus other
children (subtrees) originating by the recursive parsing of the
string ![]() . Note that attribute
nodes and text-skip nodes have only one child. Tag nodes may have
an arbitrary number of children. Content nodes have no children
and thus form the leaves of
. Note that attribute
nodes and text-skip nodes have only one child. Tag nodes may have
an arbitrary number of children. Content nodes have no children
and thus form the leaves of ![]() .1
.1
We show how to compactly represent the tree ![]() by adapting the
XBW transform introduced in [11]. The XBW transform
uses path-sorting and grouping to linearize the labeled tree
by adapting the
XBW transform introduced in [11]. The XBW transform
uses path-sorting and grouping to linearize the labeled tree
![]() into two
arrays. As shown in [11],
this ``linearized'' representation is usually highly compressible
and efficiently supports navigation and search operations over
into two
arrays. As shown in [11],
this ``linearized'' representation is usually highly compressible
and efficiently supports navigation and search operations over
![]() . Note that we can
easily distinguish between internal-node labels vs leaf labels
because the former are prefixed by either <, or
@, or =, whereas the latter are prefixed by the
special symbol
. Note that we can
easily distinguish between internal-node labels vs leaf labels
because the former are prefixed by either <, or
@, or =, whereas the latter are prefixed by the
special symbol ![]() .
.
Let ![]() denote the number of
internal nodes of
denote the number of
internal nodes of ![]() and
let
and
let ![]() denote the number of
its leaves, so that the total size of
denote the number of
its leaves, so that the total size of ![]() is
is ![]() nodes. For each node
nodes. For each node ![]() , let
, let ![]() denote the label of
denote the label of ![]() ,
,
![]() be a
binary flag set to
be a
binary flag set to ![]() if and
only if
if and
only if ![]() is the last
(rightmost) child of its parent in
is the last
(rightmost) child of its parent in ![]() , and
, and ![]() denote the string obtained by concatenating the labels on the
upward path from
denote the string obtained by concatenating the labels on the
upward path from ![]() 's
parent to the root of
's
parent to the root of ![]() .
.
To compute the XBW transform we build a sorted
multi-set ![]() consisting
of
consisting
of ![]() triplets, one
for each tree node (see Fig. 2).
Hereafter we will use
triplets, one
for each tree node (see Fig. 2).
Hereafter we will use
![]() (resp.
(resp.
![]() ,
,
![]() ) to refer
to the
) to refer
to the
![]() (resp.
(resp.
![]() ,
, ![]() ) component of the
) component of the
![]() -th triplet of
-th triplet of ![]() . To build
. To build
![]() and compute the
XBW transform we proceed as follows:
and compute the
XBW transform we proceed as follows:
Since sibling nodes may be labeled with the same symbol,
several nodes in ![]() may
have the same
may
have the same ![]() -component (see
Fig. 1). The stability of sorting at
Step 2 is thus needed to preserve the identity
of triplets after the sorting. The sorted set
-component (see
Fig. 1). The stability of sorting at
Step 2 is thus needed to preserve the identity
of triplets after the sorting. The sorted set ![]() has the
following properties:
has the
following properties: ![]()
![]() has
has
![]() bits set to 1 (one for
each internal node), the other
bits set to 1 (one for
each internal node), the other ![]() bits are set to 0;
bits are set to 0; ![]()
![]() contains
all the labels of the nodes of
contains
all the labels of the nodes of ![]() ;
; ![]()
![]() contains all
the upward labeled paths of
contains all
the upward labeled paths of ![]() (and it will not be stored). Each path is
repeated a number of times equal to the number of its offsprings.
Thus,
(and it will not be stored). Each path is
repeated a number of times equal to the number of its offsprings.
Thus,
![]() is a
lossless linearization of the labels of
is a
lossless linearization of the labels of ![]() , whereas
, whereas
![]() provides information on the grouping of the children of
provides information on the grouping of the children of
![]() 's nodes.
's nodes.
Figure 2: The set ![]() after the
pre-order visit of
after the
pre-order visit of ![]() (left). The set
(left). The set ![]() after the stable sort (right). The
three arrays
after the stable sort (right). The
three arrays
![]() , output of the XBW transform (bottom).
, output of the XBW transform (bottom).
|
|
|
|
|---|---|---|
| 1 | <biblio | empty string |
| 0 | <book | <biblio |
| 0 | @id | <book<biblio |
| 1 | = | @id<book<biblio |
| 1 | =@id<book<biblio | |
| 0 | <author | <book<biblio |
| 1 | = | <author<book<biblio |
| 1 | =<author<book<biblio | |
| 1 | <title | <book<biblio |
| 1 | = | <title<book<biblio |
| 1 | =<title<book<biblio | |
| 1 | <book | <biblio |
| 0 | @id | <book<biblio |
| 1 | = | @id<book<biblio |
| 1 | =@id<book<biblio | |
| 0 | <author | <book<biblio |
| 1 | = | <author<book<biblio |
| 1 | =<author<book<biblio | |
| 1 | <title | <book<biblio |
| 1 | = | <title<book<biblio |
| 1 | =<title<book<biblio |
| Rk |
|
|
|
|---|---|---|---|
| 1 | 1 | <biblio | empty string |
| 2 | 1 | = | <author<book<biblio |
| 3 | 1 | = | <author<book<biblio |
| 4 | 0 | <book | <biblio |
| 5 | 1 | <book | <biblio |
| 6 | 0 | @id | <book<biblio |
| 7 | 0 | <author | <book<biblio |
| 8 | 1 | <title | <book<biblio |
| 9 | 0 | @id | <book<biblio |
| 10 | 0 | <author | <book<biblio |
| 11 | 1 | <title | <book<biblio |
| 12 | 1 | = | <title<book<biblio |
| 13 | 1 | = | <title<book<biblio |
| 14 | 1 | = | @id<book<biblio |
| 15 | 1 | = | @id<book<biblio |
| 16 | 1 | =<author<book<biblio | |
| 17 | 1 | =<author<book<biblio | |
| 18 | 1 | =<title<book<biblio | |
| 19 | 1 | =<title<book<biblio | |
| 20 | 1 | =@id<book<biblio | |
| 21 | 1 | =@id<book<biblio |

We notice that the XBW transform defined in Step
3 is slightly different from the one introduced
in [11] where XBW
is defined as the pair
![]() . The
reason is that here the tree
. The
reason is that here the tree ![]() is not arbitrary but derives from an XML document
is not arbitrary but derives from an XML document
![]() . Indeed we have that
. Indeed we have that
![]() contains the labels of the internal nodes, whereas
contains the labels of the internal nodes, whereas
![]() contains the labels of the leaves, that is, the
PCDATA. This is because if
contains the labels of the leaves, that is, the
PCDATA. This is because if ![]() is a leaf the first character of its upward path
is a leaf the first character of its upward path
![]() is = which
we assume is lexicographically larger than the characters
< and @ that prefix the upward path of
internal nodes (see again Fig. 2).
Since leaves have no children, we have that
is = which
we assume is lexicographically larger than the characters
< and @ that prefix the upward path of
internal nodes (see again Fig. 2).
Since leaves have no children, we have that
![]() for
for
![]() . Avoiding
the wasteful representation of
. Avoiding
the wasteful representation of
![]() is the reason for which in Step 3 we split
is the reason for which in Step 3 we split
![]() and
and
![]() into
into
![]() .
.
In [11] the authors
describe a linear time algorithm for retrieving ![]() given
given
![]() . Since
it is trivial to get the document
. Since
it is trivial to get the document ![]() from
from
![]() we have
that
we have
that
![]() is a
lossless encoding of the document
is a
lossless encoding of the document ![]() . It is easy to prove that
. It is easy to prove that
![]() takes
at most
takes
at most
![]() bytes in
excess to the document length (details in the full version).
However, this is an unlikely worst-case scenario since many
characters of
bytes in
excess to the document length (details in the full version).
However, this is an unlikely worst-case scenario since many
characters of ![]() are implicitly
encoded in the tree structure (i.e., spaces between the attribute
names and values, closing tags, etc). In our experiments
are implicitly
encoded in the tree structure (i.e., spaces between the attribute
names and values, closing tags, etc). In our experiments
![]() was
usually about 90% the original document size. Moreover, the
arrays
was
usually about 90% the original document size. Moreover, the
arrays
![]() ,
,
![]() ,
and
,
and
![]() are only an intermediate
representation since we will work with a compressed image of
these three arrays (see below).
are only an intermediate
representation since we will work with a compressed image of
these three arrays (see below).
Finally, we point out that it is possible to build the tree
![]() without the
text-skip nodes (the nodes with label =). However, if we
omit these nodes PCDATA will appear in
without the
text-skip nodes (the nodes with label =). However, if we
omit these nodes PCDATA will appear in
![]() intermixed
with the labels of internal nodes. Separating the tree structure
(i.e.
intermixed
with the labels of internal nodes. Separating the tree structure
(i.e.
![]() ) from the textual content of the document (i.e.
) from the textual content of the document (i.e.
![]() ) has a twofold
advantage:
) has a twofold
advantage: ![]() the two strings
the two strings
![]() and
and
![]() are strongly homogeneous
hence highly compressible (see Sect. 2.2),
are strongly homogeneous
hence highly compressible (see Sect. 2.2), ![]() search and navigation operations over
search and navigation operations over ![]() are greatly
simplified (see Sect. 2.3).
are greatly
simplified (see Sect. 2.3).
Suppose the XML fragment of Fig. 1
is a part of a large bibliographic database for which we have
computed the XBW transform. Consider the string
=<author. The properties of the XBW transform
ensure that the labels of the nodes whose upward path is prefixed
by =<author are consecutive in
![]() . In other
words, there is a substring of
. In other
words, there is a substring of
![]() consisting
of all the data (immediately) enclosed in an
<author> tag. Similarly, another section of
consisting
of all the data (immediately) enclosed in an
<author> tag. Similarly, another section of
![]() contains
the labels of all nodes whose upward path is prefixed by, say,
=@id<book and will therefore likely consists of id
numbers. This means that
contains
the labels of all nodes whose upward path is prefixed by, say,
=@id<book and will therefore likely consists of id
numbers. This means that
![]() , and
therefore
, and
therefore
![]() and
and
![]() , will likely have a
strong local homogeneity property.2
, will likely have a
strong local homogeneity property.2
We point out that most XML-conscious compressors are designed
to ``compress together'' the data enclosed in the same tag since
such data usually have similar statistics. The above discussion
shows that the XBW transform provides a simple mechanism
to take advantage of this kind of regularity. In addition, XML
compressors (e.g. XMILL, SCMPPM,
XMLPPM) usually look at only the
immediately enclosing tag since it would be too space consuming
to maintain separate statistics for each possible group of
enclosing tags. Using the XBW transform we can overcome
this difficulty since the different groups of enclosing tags are
considered sequentially rather than simultaneously. For example,
for a bibliographic database,
![]() would
contain first the labels of nodes with upward path
=<author<article, then the labels with upward path
=<author<book, and finally the labels with upward
path =<author<manuscript, and so on. Hence, we can
either compress all the author names together, or we can decide
to compress the three groups of author names separately, or adopt
any other optimization scheme.
would
contain first the labels of nodes with upward path
=<author<article, then the labels with upward path
=<author<book, and finally the labels with upward
path =<author<manuscript, and so on. Hence, we can
either compress all the author names together, or we can decide
to compress the three groups of author names separately, or adopt
any other optimization scheme.
Recall that every node of ![]() corresponds to an entry in the sorted multiset
corresponds to an entry in the sorted multiset
![]() (see Fig. 2). We (logically) assign to each tree node
a positive integer equal to its rank in
(see Fig. 2). We (logically) assign to each tree node
a positive integer equal to its rank in ![]() . This number helps
in navigation and search because of the following two properties
of the sorted multiset
. This number helps
in navigation and search because of the following two properties
of the sorted multiset ![]() .
.
For every internal node label ![]() , we define
, we define
![]() as the rank
of the first row of
as the rank
of the first row of ![]() such
that
such
that ![]() is prefixed
by
is prefixed
by ![]() . Thus, for the
example of Fig. 2 we have
. Thus, for the
example of Fig. 2 we have
![]() ,
,
![]() ,
,
![]() , and so on. Suppose that
the tree contains
, and so on. Suppose that
the tree contains ![]() internal
nodes with label
internal
nodes with label ![]() . We
can rephrase Properties 1-2
above stating that starting from position
. We
can rephrase Properties 1-2
above stating that starting from position
![]() there are
there are
![]() groups of siblings which
are the offsprings of the nodes with label
groups of siblings which
are the offsprings of the nodes with label ![]() . The end of each
group is marked by a value 1 in the array
. The end of each
group is marked by a value 1 in the array
![]() , and
the
, and
the ![]() -th group of siblings
gives the children of the node corresponding to the
-th group of siblings
gives the children of the node corresponding to the ![]() -th occurrence of the
label
-th occurrence of the
label ![]() in
in
![]() .
.
To efficiently navigate and search ![]() , in addition to
, in addition to
![]() and the
array
and the
array ![]() , we need auxiliary
data structures for the rank and select operations
over the arrays
, we need auxiliary
data structures for the rank and select operations
over the arrays
![]() and
and
![]() .
Recall that given an array
.
Recall that given an array ![]() and a symbol
and a symbol ![]() ,
,
![]() denotes the number of times the symbol
denotes the number of times the symbol ![]() appears in
appears in ![]() , and
, and
![]() denotes the position in
denotes the position in ![]() of the
of the ![]() -th occurrence of the
symbol
-th occurrence of the
symbol ![]() .
.
The pseudocode of the procedure for computing the rank of the
children of the node with rank ![]() is shown in Fig. 3 to highlight
its simplicity. We first compute the label
is shown in Fig. 3 to highlight
its simplicity. We first compute the label ![]() of node
of node ![]() by setting
by setting
![]() (Step 1). Then, we set
(Step 1). Then, we set
![]() (Step
2) and we have that
(Step
2) and we have that ![]() is the
is the ![]() -th node with label
-th node with label ![]() is
is
![]() .
Because of properties 1-2 the
children of
.
Because of properties 1-2 the
children of ![]() are the
are the
![]() -th group of siblings
starting from position
-th group of siblings
starting from position ![]() . The rank of the children is therefore easily
computed by way of rank/select operations over the
array
. The rank of the children is therefore easily
computed by way of rank/select operations over the
array
![]() (Steps 4-6). For example, in Fig.
2 for
(Steps 4-6). For example, in Fig.
2 for ![]() we have
we have
![]() and
and
![]() so we are interested
in the second group of siblings starting from
so we are interested
in the second group of siblings starting from
![]() .
.
The procedures for navigation and SubPathSearch have a similar simple structure and are straightforward adaptations of similar procedures introduced in [11].The only nontrivial operations are the rank and select queries mentioned above. Note that navigation operations require a constant number of rank/select queries, and the SubPathSearch procedure requires a number of rank/select queries proportional to the length of the searched path. In this paper we introduce the new procedure ContentSearch that combines the techniques of [11] with the FM-index data structure of [12,13] and will be discussed in Sect. 3.3.
To build the tree ![]() we
parse the input document
we
parse the input document ![]() using the Expat library by James Clark.3 Expat is a
stream oriented parser written in C. We set its handlers in order
to create the tree nodes and their labels. The time required to
build the tree
using the Expat library by James Clark.3 Expat is a
stream oriented parser written in C. We set its handlers in order
to create the tree nodes and their labels. The time required to
build the tree ![]() from one
hundred MBs of XML data is a few seconds. In [11] the authors show that given
from one
hundred MBs of XML data is a few seconds. In [11] the authors show that given
![]() we can compute
we can compute
![]() in time
linear in the number of tree nodes. In our tests we followed a
simpler approach: we represent
in time
linear in the number of tree nodes. In our tests we followed a
simpler approach: we represent ![]() as an array of pointers to
as an array of pointers to ![]() nodes and we sort
nodes and we sort
![]() operating on this
array of node pointers. Experimentally we found that the
stable-sorting of
operating on this
array of node pointers. Experimentally we found that the
stable-sorting of ![]() is the most time-consuming part of
XBW computation because of the many pointer indirections
that generate cache misses. Future work will be devoted to
implementing more efficient algorithms, by using insights from
the optimal algorithm proposed in [11].
is the most time-consuming part of
XBW computation because of the many pointer indirections
that generate cache misses. Future work will be devoted to
implementing more efficient algorithms, by using insights from
the optimal algorithm proposed in [11].
If we are only interested in a compressed (non-searchable)
representation of the XML document ![]() , we simply need to store the arrays
, we simply need to store the arrays
![]() ,
,
![]() and
and
![]() as compactly as
possible. This is done by the XBZIP tool whose
pseudocode is given in Fig. 4.
Experimentally, we found that instead of compressing
as compactly as
possible. This is done by the XBZIP tool whose
pseudocode is given in Fig. 4.
Experimentally, we found that instead of compressing
![]() and
and
![]() separately it is more convenient to merge them in a unique array
separately it is more convenient to merge them in a unique array
![]() obtained from
obtained from
![]() adding a label </ in correspondence of bits equal to
1 in
adding a label </ in correspondence of bits equal to
1 in
![]() . For example, merging the
arrays
. For example, merging the
arrays
![]() and
and
![]() of Fig. 2 yields
of Fig. 2 yields
This strategy usually offers superior performance in compression because it is able to capture repetitiveness in the tree structure.
As we observed in Sect. 2.2 the
arrays
![]() and
and
![]() are locally homogeneous
since the data descending from a certain tree path is grouped
together. Hence, we expect that
are locally homogeneous
since the data descending from a certain tree path is grouped
together. Hence, we expect that
![]() and
and
![]() are best compressed
splitting them in chucks according to the structure of the tree
are best compressed
splitting them in chucks according to the structure of the tree
![]() . For simplicity in
our tests we compress
. For simplicity in
our tests we compress
![]() and
and
![]() using the general
purpose compressor PPMDI [26]. Somewhat surprisingly this
simple strategy already yields good experimental results (see
Sect. 4.1).
using the general
purpose compressor PPMDI [26]. Somewhat surprisingly this
simple strategy already yields good experimental results (see
Sect. 4.1).
In Sect. 2.3 we observed that
for navigation and search operations, in addition to
![]() , we
need data structures that support rank and select
operations over
, we
need data structures that support rank and select
operations over
![]() and
and
![]() .
In [11] the authors use
rank/select data structures with theoretically
efficient (often optimal) worst-case asymptotic performance; in
this paper we depart from their approach and use practical
methods. In particular, we will view the array as strings, and
thus use string indexing techniques. The resulting tool is called
XBZIPINDEX and its pseudocode is
shown in Fig. 5. Some details
follow.
.
In [11] the authors use
rank/select data structures with theoretically
efficient (often optimal) worst-case asymptotic performance; in
this paper we depart from their approach and use practical
methods. In particular, we will view the array as strings, and
thus use string indexing techniques. The resulting tool is called
XBZIPINDEX and its pseudocode is
shown in Fig. 5. Some details
follow.
The array
![]() . Observe that search
and navigation procedures only need rank
. Observe that search
and navigation procedures only need rank![]() and
select
and
select![]() operations over
operations over
![]() . Thus, we use a simple
one-level bucketing storage scheme. We choose a constant
. Thus, we use a simple
one-level bucketing storage scheme. We choose a constant
![]() (default is
(default is ![]() ), and we partition
), and we partition
![]() into
variable-length blocks containing
into
variable-length blocks containing ![]() bits set to
bits set to ![]() . For each block we
store:
. For each block we
store:
It is easy to see that rank![]() and select
and select![]() operations over
operations over
![]() can be implemented by
decompressing and scanning a single block, plus a binary search
over the table of
can be implemented by
decompressing and scanning a single block, plus a binary search
over the table of ![]() -blocked
ranks.
-blocked
ranks.
The array
![]() . Recall that
. Recall that
![]() contains the labels of internal nodes of
contains the labels of internal nodes of ![]() . We represent it using again a one-level
bucketing storage scheme: we partition
. We represent it using again a one-level
bucketing storage scheme: we partition
![]() into fixed-length blocks (default is 8Kb) and for each
block we store:
into fixed-length blocks (default is 8Kb) and for each
block we store:
Since the number of distinct internal-node labels is
usually small with respect to the document size, ![]() -blocked ranks can be
stored without adopting any sophisticated solution. The
implementation of
-blocked ranks can be
stored without adopting any sophisticated solution. The
implementation of
![]() and
and
![]() derives easily from the information we have stored.
derives easily from the information we have stored.
The array
![]() . This array is
usually the largest component of
. This array is
usually the largest component of
![]() (see
the last column of Table 1 and Table
3). Recall that
(see
the last column of Table 1 and Table
3). Recall that
![]() consists of the
PCDATA items of
consists of the
PCDATA items of ![]() ,
ordered according their upward paths. Note that the procedures
for navigating and searching
,
ordered according their upward paths. Note that the procedures
for navigating and searching ![]() do not require rank/select
operations over
do not require rank/select
operations over
![]() (see Sect. 2). Hence, we use a representation of
(see Sect. 2). Hence, we use a representation of
![]() that efficiently
supports XPATH queries of the form
/
that efficiently
supports XPATH queries of the form
/![]() [contains(.,
[contains(.,![]() )], where
)], where
![]() is a fully-specified
path and
is a fully-specified
path and ![]() is an arbitrary
string of characters. To this end we use a bucketing scheme where
buckets are induced by the upward paths. Formally, let
is an arbitrary
string of characters. To this end we use a bucketing scheme where
buckets are induced by the upward paths. Formally, let
![]() be a
maximal interval of equal strings in
be a
maximal interval of equal strings in ![]() . We form one bucket of
. We form one bucket of
![]() by concatenating the
strings in
by concatenating the
strings in
![]() . In other words,
two elements of
. In other words,
two elements of
![]() are in the same bucket
if and only if the have the same upward path. Note that every
block will likely be highly compressible since it will be formed
by homogeneous strings having the same
``context''.4 For each bucket we store the
following information:
are in the same bucket
if and only if the have the same upward path. Note that every
block will likely be highly compressible since it will be formed
by homogeneous strings having the same
``context''.4 For each bucket we store the
following information:
Using this representation of
![]() , we can answer the query
/
, we can answer the query
/![]() [contains(.,
[contains(.,![]() )] as follows
(see procedure ContentSearch in Fig 6). By the procedure SubPathSearch we
identify the nodes whose upward path is prefixed by
)] as follows
(see procedure ContentSearch in Fig 6). By the procedure SubPathSearch we
identify the nodes whose upward path is prefixed by ![]() (i.e. the reversal
of
(i.e. the reversal
of ![]() ). Then, we identify
the substring
). Then, we identify
the substring
![]() containing the labels of the leaves whose upward path is
prefixed by =
containing the labels of the leaves whose upward path is
prefixed by =![]() . Note
that
. Note
that
![]() consists of an integral number of buckets, say
consists of an integral number of buckets, say ![]() . To answer the query, we
then search for
. To answer the query, we
then search for ![]() in
these
in
these ![]() buckets using their
FM-indexes, taking time proportional to
buckets using their
FM-indexes, taking time proportional to ![]() for each bucket. Since the procedure
SubPathSearch takes time proportional to
for each bucket. Since the procedure
SubPathSearch takes time proportional to ![]() , the overall
cost of the query is proportional to
, the overall
cost of the query is proportional to
![]() .
.
In addition to the above data structures, we also need two
auxiliary tables: the first one maps node labels to their
lexicographic ranks, and the second associates to each label
![]() the value
the value
![]() . Due to the
small number of distinct internal-node labels in real XML files,
these tables do not need any special storage method.
. Due to the
small number of distinct internal-node labels in real XML files,
these tables do not need any special storage method.
Figure 6: Search for the string
![]() as a substring
of the textual content of the nodes whose leading path is
as a substring
of the textual content of the nodes whose leading path is
![]() (possibly
anchored to an internal node).
(possibly
anchored to an internal node).
![\begin{figure}\hrule {\itemsep=-2pt\baselineskip=12pt\smallskip {Algorithm {\sf ... ...kets ${\cal B}[i,j]$.\end{enumerate} \vspace*{-2pt}\vskip0pt}\hrule \end{figure}](6009-ferragina-img133.png)
|
We have developed a library of XML compression and indexing tools based on the XBW transform. The library, called XBZIPLIB, consists of about 4000 lines of C code and runs under Linux and Windows (CygWin). This library can be either included in another software or it can be directly used at the command-line with a full set of options for compressing, indexing and searching XML documents. We have tested our tools on a PC running Linux with two P4 CPUs at 2.6Ghz, 512Kb cache, and 1.5Gb internal memory.
In our experiments we used nine XML files which cover a wide range of XML data formats (data centric or text centric) and structures (many/deeply nested tags, or few/almost-flat nesting). Whenever possible we have tried to use files already used in other XML experimentations. Some characteristics of the documents are shown in Table 1. The following is the complete list providing the source for each file.
Table 1: XML documents used in our
experiments. The first three files are data centric, the
others text centric. Note that columns
![]() and
and
![]() report
the byte length of these two strings.
report
the byte length of these two strings.
| DATASET | SIZE (BYTES) | TREE SIZE | #LEAVES | TREE DEPTH | #TAG/ATTR | #MATH195# | #MATH196# |
| MAX/AVG | (DISTINCT) | ||||||
| PATHWAYS | 79,054,143 | 9,338,092 | 5,044,682 | 10 / 3.6 | 4,293,410 (49) | 24,249,238 | 36,415,927 |
| XMARK | 119,504,522 | 5,762,702 | 3,714,508 | 13 / 6.2 | 2,048,194 (83) | 15,361,789 | 85,873,039 |
| DBLP | 133,856,133 | 10,804,342 | 7,067,935 | 7 / 3.4 | 3,736,407 (40) | 24,576,759 | 75,258,733 |
| SHAKESPEARE | 7,646,413 | 537,225 | 357,605 | 8 / 6.1 | 179,620 (22) | 1,083,478 | 4,940,623 |
| TREEBANK | 86,082,516 | 7,313,000 | 4,875,332 | 37 / 8.1 | 2,437,668 (251) | 9,301,193 | 60,167,538 |
| XBENCH | 108,672,761 | 7,725,246 | 4,970,866 | 9 / 7.2 | 2,754,380 (25) | 7,562,511 | 85,306,618 |
| SWISSPROT | 114,820,211 | 13,310,810 | 8,143,919 | 6 / 3.9 | 5,166,891 (99) | 30,172,233 | 51,511,521 |
| NEWS | 244,404,983 | 8,446,199 | 4,471,517 | 3 / 2.8 | 3,974,682 (9) | 28,319,613 | 176,220,422 |
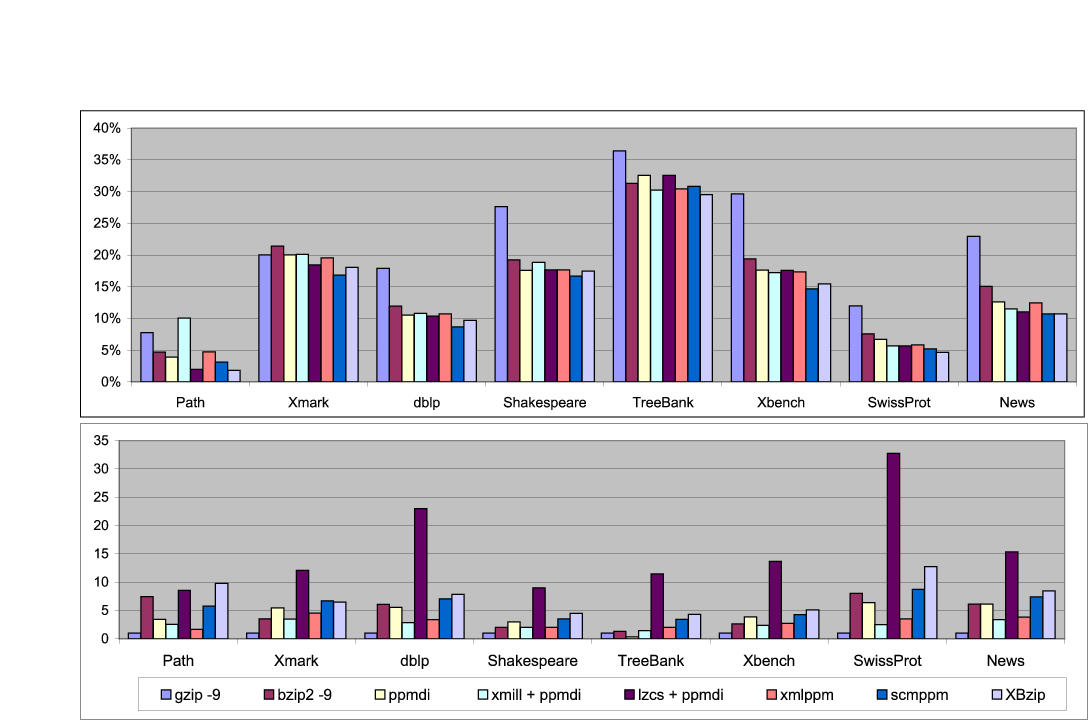
Figure 7: Comparison of XML compressors. Compression ratio (top) and compression time (bottom). Compression times are scaled with respect to GZIP compression time. Note that XMILL, XMLPPM, SCMPPM, and XBZIP all use PPMDI as their base compressor.
|
To evaluate the real advantages of XML-conscious tools we compare them with general purpose compressors. The literature offers various general purpose compressors ranging from dictionary-based (GZIP), to block-sorting (BZIP2), and PPM-based compressors (we used PPMDI [26] which is the one with the best performance). In addition, we compare XBZIP with the current state-of-the-art XML-conscious compressors:
We comment on two interesting issues arising from our experiments (see Fig. 7).
In summary, the experimental results show that XML-conscious
compressors are still far from being a clearly advantageous
alternative to general purpose compressors. However, the
experiments show also that our simple XBW-based compressor
provides the best compression for most of the files. We think
that the new compression paradigm introduced with XBW
(i.e. first linearize the tree then compress) is much interesting
in the light of the fact that we are simply applying
PPMDI without fully taking advantage of the local
homogeneity properties of the strings
![]() and
and
![]() (see Sects. 2.2 and 3.2). This will be further investigated in
a future work.
(see Sects. 2.2 and 3.2). This will be further investigated in
a future work.
The literature offers various solutions to index XML files [6]. Here we only refer to XML compression formats that support efficient query operations. In Table 2 we compare our XBZIPINDEX against the best known queriable compressors. We were not able to test XPRESS [23], XGRIND [27] and XQZIP [10], because either we could not find their software or we were unable to run it on our XML files. However, whenever possible we show in Table 2 the performance of these tools as reported in their reference papers.
Table 2: Compression ratio achieved by queriable compressors over the files in our dataset. For XPRESS and XQZIP we report results taken from [23,10] (the symbol - indicates a result not available in these papers). The comparison between the last two columns allows us to estimate the space overhead of adding navigation and search capabilities to XBZIP. Note that we can trade space usage for query time by tuning the parameters of the FM-index [12].
| DATASET | HUFFWORD | XPRESS | XQZIP | XBZIPINDEX | XBZIP |
| PATHWAYS | 33.68 | - | - | 3.62 | 1.84 |
| XMARK | 34.15 | - | 38 | 28.65 | 18.07 |
| DBLP | 44.00 | 48 | 30 | 14.13 | 9.69 |
| SHAKESPEARE | 42.08 | 47 | 40 | 21.83 | 17.46 |
| TREEBANK | 67.81 | - | 43 | 54.21 | 29.52 |
| XBENCH | 44.96 | - | - | 19.47 | 15.45 |
| SWISSPROT | 43.10 | 42 | 38 | 7.87 | 4.66 |
| NEWS | 45.15 | - | - | 13.52 | 10.61 |
From the previous comments and Table 2 we observe that
XBZIPINDEX significantly improves
the compression ratio of the known queriable compressors by
![]() to
to ![]() of the original
document size. Table 3 details
the space required by the various indexing data structures
present in XBZIPINDEX. As expected,
the indexing of
of the original
document size. Table 3 details
the space required by the various indexing data structures
present in XBZIPINDEX. As expected,
the indexing of
![]() and
and
![]() requires negligible space, thus proving again that these two
strings are highly compressible and even a simple
compressed-indexing approach, as the one we adopted in this
paper, pays off. Conversely,
requires negligible space, thus proving again that these two
strings are highly compressible and even a simple
compressed-indexing approach, as the one we adopted in this
paper, pays off. Conversely,
![]() takes most of the space
and we plan to improve compression by fine tuning the parameters
of the FM-indexes that we use for storing this array (see Sec.
3.3).
takes most of the space
and we plan to improve compression by fine tuning the parameters
of the FM-indexes that we use for storing this array (see Sec.
3.3).
Table 3: Percentage of each index part with respect to the corresponding indexed string. Auxiliary info includes all the prefix-counters mentioned in Section 3.3, and it is expressed as a percentage of the total index size. The last column gives an estimate of the avg number of bytes spent for each tree node.
| DATASET | % INDEX #MATH206# | % INDEX #MATH207# | INDEX #MATH208# | AUXILIARY | BYTES PER NODE |
| PATHWAYS | 1.7 | 0.8 | 6.0 | 9.7 | 0.31 |
| XMARK | 3.6 | 2.5 | 29.5 | 7.8 | 5.94 |
| DBLP | 4.9 | 2.3 | 32.3 | 8.1 | 1.75 |
| SHAKESPEARE | 4.6 | 3.4 | 32.3 | 9.7 | 3.11 |
| TREEBANK | 5.2 | 14.7 | 68.5 | 0.2 | 6.38 |
| XBENCH | 4.4 | 4.7 | 23.8 | 0.6 | 2.74 |
| SWISSPROT | 2.2 | 2.5 | 14.0 | 8.0 | 0.68 |
| NEWS | 1.0 | 0.5 | 18.5 | 0.6 | 3.91 |
As far as query and navigation operations are concerned, we refer to Table 4. Subpath searches are pretty much insensitive to the document size, as theoretically predicted, and indeed require few milliseconds. Navigational operations (e.g. parent, child, block of children) require less than one millisecond in our tests. As mentioned before, all the others queryable compressors--like XPRESS, XGRIND, XQZIP--need the whole scanning of the compressed file, thus requiring several seconds for a query, and use much more storage space.
Table 4: Summary of the search results for
XBZIPINDEX. These time
figures do not include the mmapping of the index
from disk to internal memory and the loading of the
auxiliary infos, which take ![]() secs on average.
Columns 2, 3, and 4 report the number of blocks accessed
during the query and their total size in bytes.
secs on average.
Columns 2, 3, and 4 report the number of blocks accessed
during the query and their total size in bytes.
| DATASET: QUERY | #MATH209# BLOCKS | #MATH210# BLOCKS | #MATH211# BLOCKS | TIME | # OCC |
| (# BYTES) | (# BYTES) | IN SECS | |||
| PATHWAYS: /entry[@id="3"] | 5 (5005) | 4 (498) | 2 | 62,414 | |
| XMARK /person/address/city[.contains="Orange"] | 8 (71324) | 6 (1599) | 2 | 41 | |
| DBLP: /article/author[contains="Kurt"] | 5 (47053) | 4 (1509) | 2 | 288 | |
| DBLP: /proceedings/booktitle[contains="Text"] | 5 (21719) | 4 (875) | 2 | 10 | |
| DBLP: /cite[@label="XML"] | 5 (5005) | 4 (473) | 134 | 7 | |
| DBLP: /article/author | 5 (47053) | 2 (967) | 0 | 221,289 | |
| SHAKESPEARE: /SCENE/STAGEDIR | 5 (14917) | 2 (1035) | 0 | 4259 | |
| SHAKESPEARE: /LINE/STAGEDIR[contains="Aside"] | 5 (21525) | 4 (1128) | 2 | 302 | |
| TREEBANK /S/NP/JJ[contains="59B"] | 8 (18436) | 6 (5965) | 697 | 2 | |
| XBENCH /et/cr[contains="E4992"] | 2 (2774) | 2 (996) | 4 | 11 | |
| SWISSPROT: /Entry/species[contains="Rattus"] | 5 (11217) | 4 (1540) | 2 | 2,154 | |
| NEWS: /description[contains="Italy"] | 2 (2002) | 2 (66) | 2 | 1,851 |
We have adopted the methods in [11] for compressing and searching
labelled trees to the XML case and produced two tools:
XBZIP, a XML (un)compressor competitive with known
XML-conscious compressors but simpler and with guarantees on its
compression ratio; XBZIPINDEX that
introduces the approach of using full-text compressed indexing
for strings and improves known methods by up to ![]() while simultaneously
improving the search operations by an order of magnitude.
while simultaneously
improving the search operations by an order of magnitude.
[1] http:/xml.coverpages.org/xml.html.
[2] J. Adiego, P. de la Fuente, and
G. Navarro.
Lempel-Ziv compression of structured text.
In
IEEE Data Compression Conference, 2004.
[3] J. Adiego, P. de la Fuente, and
G. Navarro.
Merging prediction by partial matching with structural
contexts model.
In IEEE Data Compression Conference, page
522, 2004.
[4] A. Arion, A. Bonifati, G. Costa,
S. D'Aguanno, I. Manolescu, and A. Pugliese.
XQueC: pushing queries
to compressed XML data.
In VLDB, 2003.
[5] D. Benoit, E. Demaine, I. Munro, R. Raman,
V. Raman, and S. Rao.
Representing trees of higher degree.
Algorithmica, 2005.
[6] B. Catania, A. Maddalena, and
A. Vakali.
XML document indexes: a classification.
In IEEE
Internet Computing, pages 64-71, September-October 2005.
[7] T. Chen, J. Lu, and T. W. Lin.
On boosting holism in XML twig pattern matching using
structural indexing techniques.
In ACM Sigmod, pages 455-466, 2005.
[8] J. Cheney.
Compressing XML with multiplexed hierarchical PPM models.
In IEEE Data Compression Conference, pages 163-172,
2001.
[9] J. Cheney.
An empirical evaluation of simple DTD-conscious compression
techniques.
In WebDB, 2005.
[10] J. Cheng and W. Ng.
XQzip: Querying compressed XML using structural indexing.
In International Conference on Extending Database
Technology, pages 219-236, 2004.
[11] P. Ferragina, F. Luccio, G. Manzini, and S.
Muthukrishnan.
Structuring labeled trees for optimal succinctness, and
beyond.
In IEEE Focs, pages 184-193, 2005.
[12] P. Ferragina and G. Manzini.
An experimental study of a compressed index.
Information Sciences: special issue on ``Dictionary Based
Compression'', 135:13-28, 2001.
[13] P. Ferragina and G. Manzini.
Indexing compressed text.
Journal of the ACM, 52(4):552-581, 2005.
[14] R. F. Geary, R. Raman, and V. Raman.
Succinct ordinal trees with level-ancestor queries.
In ACM-SIAM Soda, 2004.
[15] D. Geer.
Will binary XML speed network traffic?
IEEE Computer, pages 16-18, April 2005.
[16] R. Goldman and J. Widom.
Dataguides: enabling query formulation and optimization in
semistructured databases.
In VLDB, pages 436-445, 1997.
[17] A. Golinsky, I. Munro, and S. Rao.
Rank/Select operations on large alphabets: a tool for text
indexing.
In ACM-SIAM SODA, 2006.
[18] R. Kaushik, R. Krishnamurthy,
J. Naughton, and R. Ramakrishnan.
On the integration of structure
indexes and inverted lists.
In ACM Sigmod, pages 779-790,
2004.
[19] R. Kaushik, R. Krishnamurthy,
J. F. Naughton, and R. Ramakrishnan.
On the integration of structure
indexes and inverted lists.
In ACM Sigmod, 2004.
[20] W. Y. Lam, W. Ng, P. T. Wood,
and M. Levene.
XCQ: XML compression and querying system.
In WWW,
2003.
[21] H. Liefke and D. Suciu.
XMILL: An efficient compressor for XML data.
In ACM Sigmod, pages 153-164, 2000.
[22] T. Milo and D. Suciu.
Index structures for path expressions.
In ICDT, pages 277-295, 1999.
[23] Jun-Ki Min, Myung-Jae Park, and Chin-Wan
Chung.
Xpress: A queriable compression for XML data.
In
ACM Sigmod, pages 122-133, 2003.
[24] E. Moura, G. Navarro, N. Ziviani, and
R. Baeza-Yates.
Fast and flexible word searching on compressed
text.
ACM Transactions on Information Systems,
18(2):113-139, 2000.
[25] P. R. Raw and B. Moon.
PRIX: Indexing and querying XML using Prufer sequences.
In ICDE, pages 288-300, 2004.
[26] D. Shkarin.
PPM: One step to practicality.
In IEEE Data Compression Conference, pages 202-211,
2002.
[27] P. M. Tolani and J. R. Haritsa.
XGRIND: A query-friendly XML compressor.
In ICDE, pages 225-234, 2002.
[28] H. Wang, S. Park, W. Fan, and P. S. Yu.
ViST: a dynamic index methd for querying XML data by tree
structures.
In ACM Sigmod, pages 110-121, 2003.
[29] W. Wang, H. Wang, H. Lu, H. Jang, X. Lin,
and J. Li.
Efficient processing of XML path queries using the
disk-based F&B index.
In VLDB, pages 145-156, 2005.


