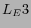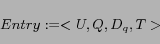
We observe that hyperlinks provide only one kind of linkages between Web pages. By properly utilizing the Web query logs, we can discover other important linkages that are just as important. In this paper, we propose to extract a new kind of links known as implicit links from the Web query logs that are accumulated by search engines. These logs record the Web users' behavior when they search for information via a search engine. Over the years, query logs have become a rich resource which contains Web users' knowledge about the World Wide Web (WWW). In order to mine the latent knowledge hidden in the query logs, much research has been conducted on the query logs [17,2]. Many applications of log analysis have been conducted in categorization and query clustering [1,4,20]. Consider the behavior of a Web user. After submitting a query, a Web user gets a long list of Web pages with snippets returned by a search engine. Then the user could look through some of the returned pages selectively. All the queries the users submit and the Web pages they click on constitute the query log. Although there may be some noise in query logs, the clicks still convey important information on the similarity between Web pages and queries in a large query log. In the context of Web page classification, an implicit type of similarity information we can use is the fact that the Web pages that are clicked by users through the same query usually belong to the same categories. It is this kind of knowledge that we make use of in order to build the implicit links between Web pages.
In this paper, we define two kinds of implicit links that can be extracted from a query log and three kinds of explicit links using the traditional hyperlink concepts. We further define two different approaches in making use of these links. The first one is to classify a target page according to the labels of the neighbors of that page. We show that using this algorithm for classification, the implicit links are more reliable in classification. The best result of using implicit links is about 20.6% higher than the best result through the explicit links in terms of the Micro-F1 measure. The second classification method we use is to construct a virtual document based on different kinds of links, and then conduct classification on the virtual documents. The experiments on the Web pages crawled from the Open Directory Project (ODP)1 and the query logs collected by MSN show that using the implicit links can achieve 10.5% improvement compared to the explicit links in terms of Macro-F1.
The main contributions of this paper could be summarized as follows:
The rest of the paper is organized as follows. In Section 2, we present the related works on query logs and Web classification through hyperlinks. We give the definition of two kinds of ''Implicit Link'' and three kinds of ''Explicit Link'' in Section 3. Section 4 gives the approaches to utilize the Links. The experimental results on the ODP dataset and query logs collected by MSN as well as some discussions are shown in Section 5. Finally, we conclude our work in Section 6.
Query logs are being accumulated rapidly with the growing popularity of search engines. It is natural for people to analyze the query logs and mine the knowledge hidden in them. Silverstein et al. made a static analysis of an AltaVista query log from six weeks in 1998 consisting of 575 million nonempty queries [17]. Beitzel et al. [2] studied a query log of hundreds of millions of queries that constitute the total query traffic for an entire week of a general purpose commercial web search service which provided valuable insight for improving retrieval effectiveness and efficiency. By analyzing and leveraging the information from query log, many applications become feasible or easier. Raghavan and Sever described an elegant method of locating stored optimized queries by comparing results from a current query to the results from the optimized query [16]. Beeferman and Berger proposed an innovative query clustering method based on query log [1]. By viewing the query log as a bipartite graph, with the vertices on one side corresponding to queries and those on the other side corresponding to URLs, they applied an agglomerative clustering algorithm to the graph's vertices to identify related queries and URLs. Wen et al. incorporated click-through data to cluster users' queries [20]. They analyzed a random subset of 20,000 queries from a single month of their approximately 1-million queries-per-week traffic. Chuang and Chien proposed a technique for categorizing Web query terms from the click-through logs into a pre-defined subject taxonomy based on their popular search interests [4]. Xue et al. proposed a novel categorization algorithm named IRC (Iterative Reinforcement Categorization algorithm) to categorize the interrelated Web objects by iteratively reinforcing individual classification results via relationships across different data types extracted from query logs [21]. However, to the best of our knowledge, no research has considered building implicit links between documents through query logs for Web page classification. In the next section, we formally introduce the concept of implicit links.
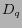 represents the returned Web pages clicked by the
user. T represents the time when such an entry occurs. In this
work, we only focus on using the query logs for Web page
classification. Thus, we omit T and consider an entry as
represents the returned Web pages clicked by the
user. T represents the time when such an entry occurs. In this
work, we only focus on using the query logs for Web page
classification. Thus, we omit T and consider an entry as
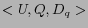 . In fact, we could further simplify
the entry as
. In fact, we could further simplify
the entry as 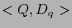 by omitting U. However, often times
when the same query is issued by two different users, it may mean
different things. Such ambiguities between users make the pages
that are constrained by Q alone to be more heterogeneous in
content than the pages that are constrained by both U and Q.
by omitting U. However, often times
when the same query is issued by two different users, it may mean
different things. Such ambiguities between users make the pages
that are constrained by Q alone to be more heterogeneous in
content than the pages that are constrained by both U and Q.
Based on a query log, we define two kinds of implicit link relations according to two different constraints:
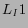 :
: 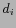 and
and 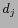 appear in the same
entries constrained by U and Q in the query log. That is
and are clicked by the same user
issuing the same query;
appear in the same
entries constrained by U and Q in the query log. That is
and are clicked by the same user
issuing the same query;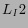 : and appear in the same
entries constrained by the query Q only. That is and
are clicked according to the same query, but the
query may be issued by different users. It is clear that the
constraint for
: and appear in the same
entries constrained by the query Q only. That is and
are clicked according to the same query, but the
query may be issued by different users. It is clear that the
constraint for 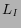 2 is not as strict as that for
. Thus, more links of can be found than
, however they may be more noisy.
2 is not as strict as that for
. Thus, more links of can be found than
, however they may be more noisy.Similar to the implicit links, we define three kinds of
explicit links based on the hyperlinks among the Web pages
according to the following three different conditions:
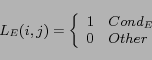
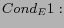 there exist hyperlinks from to
(In-Link to from );
there exist hyperlinks from to
(In-Link to from );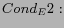 there exist hyperlinks from to
(Out-Link from to );
there exist hyperlinks from to
(Out-Link from to );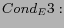 either
either 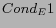 or
or 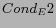 holds.
holds.We denote these three types of explicit links under the above
conditions as 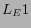 ,
, 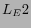 ,
, 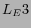 respectively.
respectively.
In the above definitions, we distinguish between the in-link and out-link because, given the target Web page, the in-link is the hyperlink created by other Web page editors who refer to the target Web page. In contrast, the out-link is created by the editor of the source Web page. They may be different when used to describe the target Web page.
Based on other considerations, it is possible for us to define other links. For example, we could define a kind of implicit link between two pages if they belong to two different entries and the intersection of the two clicked-page sets of the two entries is not empty. We could also require that the similarity between two pages be larger than a certain threshold to define a certain kind of explicit link. However, for the purpose of comparing explicit and implicit links, we will only focus on the above five different types of links.
From the above definitions, we observe that the implicit links give the relationships between Web pages from the view of Web users. However, the explicit links reflect the relationships among Web pages from the view of Web-page editors.
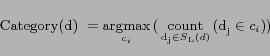
where 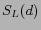 represents a kind of link;
represents a kind of link; 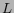 is the set of Web pages
which relate to d through ;
is the set of Web pages
which relate to d through ;
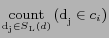 denotes the number of the neighbors which belong to the class
denotes the number of the neighbors which belong to the class
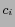 . This algorithm is similar to k-Nearst Neighbor (KNN).
However, k is not a constant as in KNN and it is decided by the
set of the neighbors of the target page.
. This algorithm is similar to k-Nearst Neighbor (KNN).
However, k is not a constant as in KNN and it is decided by the
set of the neighbors of the target page.
The CLN method classifies a Web page only based on the labels of its neighboring pages. It does not consider the content of Web pages. In this work, we enhance classification performance through the links by constructing virtual documents. Given a document, the virtual document is constructed by borrowing some extra text from its neighbors. Although originally the concept of the virtual document is pioneered by [9], we extend the notion by including different links.
To form a virtual document, we consider two cases. One is to adjust the non-zero weights of existing terms in the original keyword vector that represents the page. The other is to bring in new terms from the neighbors so that the modified vector will have additional non-zero components. The second case changes the vector more drastically. The experimental results in [14] showed that the latter method resulted in a 23.9 % decrease in F1 measure. Thus, in this paper, we adopt the former to construct virtual documents.
The plain text in Web pages, as well as the rich information marked by HTML, such as the title, meta-data and paragraph headings could be all used for Web-page classification. Some research works have studied the contribution of these elements to Web-page classification [15,8]. In order to show the contribution of different links on Web page classification, we try to find an appropriate way to represent web pages by local words and then take it as a baseline to compare with the virtual document representation. In our previous study, we find that the weighted combination of Plain text, Meta-data and Title usually achieves the best classification performance. Thus, we take these as the local representation of web pages. We give these concepts below:
 Meta
Meta and /Meta, such as
''Keywords'' and ''Description'';
and /Meta, such as
''Keywords'' and ''Description'';For the implicit links, there is no ''anchor text'' as defined
in the case of explicit links. As a consequence, in this work, we
define a corresponding concept-''anchor sentence''. Since the
implicit links among the Web pages are built through ''queries'',
we could define the ''anchor sentence'' through a query. If an
implicit link between 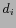 and
and 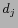 is created according to a
query Q, the set of sentences in which contain all the words in
Q are regarded as the ''anchor sentences''. We then collect the
anchor sentences to construct a virtual document. The query Q is
preprocessed as shown in section 5.1. We require the anchor
sentences include all the words in the query to guarantee that
the content of the virtual document focuses on the query.
is created according to a
query Q, the set of sentences in which contain all the words in
Q are regarded as the ''anchor sentences''. We then collect the
anchor sentences to construct a virtual document. The query Q is
preprocessed as shown in section 5.1. We require the anchor
sentences include all the words in the query to guarantee that
the content of the virtual document focuses on the query.
After constructing the virtual document through links, any traditional text classification algorithm could be employed to classify the web pages. In this paper, we take Naive Bayesian classifier and Support Vector Machine as the classifiers to compare the quality of different virtual documents.
A subset of the real MSN query log is collected as our experiment data set. The collected log contains about 44.7 million records of 29 days from Dec 6 2003 to Jan 3 2004. Some preprocessing steps are applied to queries and Web pages in the raw log. We processed the log into a predefined format as shown in Section 3. All queries are converted into lower-case, and are stemmed using the Porter algorithm.3 The stop words are removed as well. After preprocessing, the log contains 7,800,543 entries, having 2,697,187 users, 308,105 pages and 1,280,952 queries. That is, among the 1.3 million ODP Web pages, 308,105 of them clicked by users in the 29 days are studied in this paper. The average query length is about 2.1 words.
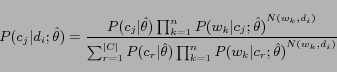
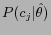 can be calculated by counting
the frequency with each category
can be calculated by counting
the frequency with each category 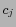 occurring in the training
data;
occurring in the training
data; 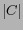 is the number of categories;
is the number of categories; 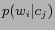 stands for the probability that word
stands for the probability that word
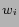 occurs in class . This last quantity may be small
in the training data. Thus, Laplace smoothing is chosen to
estimate it;
occurs in class . This last quantity may be small
in the training data. Thus, Laplace smoothing is chosen to
estimate it; 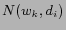 is the number of occurrences of a word
is the number of occurrences of a word
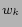 in ; n is the number of words in the training data.
in ; n is the number of words in the training data.
 software package4 due
to its popularity and high performance in text categorization.
For all the following experiments, we used a linear kernel for
comparison purposes because of its high accuracy for text
categorization [10]. The
trade-off parameter C is fixed to 1 for comparison purpose and
the one-against-all approach is used for the multi-class case
[10].
software package4 due
to its popularity and high performance in text categorization.
For all the following experiments, we used a linear kernel for
comparison purposes because of its high accuracy for text
categorization [10]. The
trade-off parameter C is fixed to 1 for comparison purpose and
the one-against-all approach is used for the multi-class case
[10].
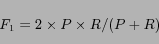
In this section, we show the statistics of different links in the data set firstly. Then the results of the two approaches of leveraging different links are presented, based on which we compare the merits of implicit links and explicit links.
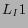 is about 23.2% higher than
is about 23.2% higher than 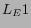 and
and 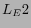 which
indicates that is more reliable for guessing the category
of a target page by the labels of its linked neighbors. One fact
for explaining this observation is that very often hyperlinks are
created not according the similarity of content between Web
pages, but for other reasons such as commercial advertisement. We
could also find that the consistency of
which
indicates that is more reliable for guessing the category
of a target page by the labels of its linked neighbors. One fact
for explaining this observation is that very often hyperlinks are
created not according the similarity of content between Web
pages, but for other reasons such as commercial advertisement. We
could also find that the consistency of 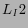 to be much lower
than , though the number of links of is far larger than
. Such an observation shows that we could get more
links by relaxing the condition, but the quality of links may
become worse.
to be much lower
than , though the number of links of is far larger than
. Such an observation shows that we could get more
links by relaxing the condition, but the quality of links may
become worse.
Table 3 supports the published facts that linked pages can be
more harmful than helpful and that links have to be used in a
careful manner [8]. In these
cases, two pages linked together by or any kind of explicit
links tend to belong to different categories with a probability
more than 0.5.
1, we collect all the pages which
are covered by implicit link of type 1 and then split them into
10 groups randomly to perform the 10-fold cross validation. The
results listed in Figure 1 are the average of the experiment
results of 10 runs. Micro-F1 and Macro-F1 represent the micro and
the macro average F1 measure from the 424 categories. From Figure
1, we could see that the two kinds of implicit links both achieve
better results than the three kinds of explicit links. The best
result achieved by implicit links is about 20.6% in terms of
Micro-F1 and 44.0% in terms of Macro-F1 higher than the best
result achieved by explicit links. We can also see that the
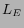 1 based classification method outperforms that based on
. The explanation of this observation is that the
average number of In-Links per page (4.38) is much larger than
the average number of Out-Links per page (3.23) which can help
remove the effect of noise.
1 based classification method outperforms that based on
. The explanation of this observation is that the
average number of In-Links per page (4.38) is much larger than
the average number of Out-Links per page (3.23) which can help
remove the effect of noise.
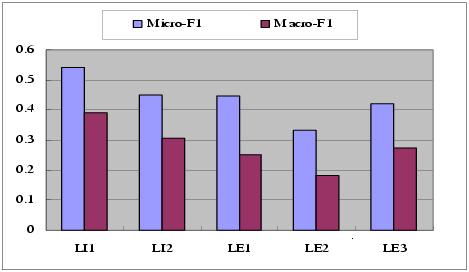
Figure 1: Results of CLN on different kinds of Links
1 and 1) to construct virtual
documents. Together we have five combinations through which to
form a virtual document, as listed in Table 4.
In this table, ELT refers to the virtual documents constructed
by combining the local text from all the pages that link to the
target Web page through 1. ILT refers to the virtual
documents constructed by combining the local text from all pages
which link to the target Web page through 1. EAT refers to
virtual documents consisting of the extended anchor text. These
are the set of rendered words occurring up to 25 words before and
after the anchor text. They also include the anchor text itself.
In order to test the impact of implicit links and explicit links,
in the following experiments, we only work on a subset of the ODP
dataset that we collected in which all the pages are covered by
both 1 and 1. The subset contains 56,129
pages. Table 5 shows the performance of classification on
different kinds of virtual documents, where Mi-F1 refers to
Micro-F1 and Ma-F1 refers to Macro-F1.
|
(1) Classification performance by SVM |
||||||
| LT | ILT | ELT | AS | EAT | AT | |
| Mi-F1 | 0.607 | 0.652 | 0.629 | 0.591 | 0.519 | 0.403 |
| Ma-F1 | 0.348 | 0.444 | 0.384 | 0.389 | 0.297 | 0.253 |
|
(2) Classification performance by NB |
||||||
| LT | ILT | ELT | AS | EAT | AT | |
| Mi-F1 | 0.551 | 0.583 | 0.515 | 0.556 | 0.464 | 0.361 |
| Ma-F1 | 0.25 | 0.336 | 0.298 | 0.296 | 0.226 | 0.163 |
To analyze the results of different kinds of virtual documents, two factors should be considered. One is the average size of the virtual documents and the other is the consistency or purity of the content of the virtual documents. The average size of each kind of virtual document is shown in Table 6.
From Table 5, we observe that although it is supposed that AS,
EAT and AT can reflect the content of the target pages correctly,
the classification performance based on them is just as good as
the baseline, or even worse than the baseline. One possible
reason may lie in the fact that the average sizes of AS, EAT and
AT are usually too small to obtain any satisfying classification
results. On the other side, though the average size of ELT is large
enough compared to the average size of LT, too much noise may be
introduced when it is constructed through 1 and the included
noise biased the classification results. We also see that ILT is
much better than ELT, with a relative increase of 12.8% in terms
of Micro-F1 through NB classifier. The reason may be that the
content of these Web pages linked by 1 may be quite different.
Thus, by combining them together, the diversity of the content
may bias the classification result. However, the content of the
Web pages linked by 1 tend to be similar to each other.
Therefore, it is more appropriate to employ the implicit links
when constructing a virtual document to improve the
classification performance.
|
(1) Results on SVM |
||||||||||
| 1:0 | 4:1 | 3:1 | 2:1 | 1:1 | 1:2 | 1:3 | 1:4 | 0:1 | Impr* | |
|
Micro-F1 |
||||||||||
| AS |
0.607 |
0.654 | 0.659 | 0.661 | 0.662 | 0.661 | 0.657 | 0.650 | 0.591 | 9.06% |
| EAT | 0.616 | 0.627 | 0.636 | 0.638 | 0.639 | 0.635 | 0.628 | 0.519 | 5.27% | |
| AT | 0.596 | 0.606 | 0.612 | 0.611 | 0.612 | 0.615 | 0.610 | 0.403 | 1.30% | |
|
Macro-F1 |
||||||||||
| AS |
0.348 |
0.423 | 0.420 | 0.432 | 0.426 | 0.431 | 0.429 | 0.422 | 0.389 | 24.14% |
| EAT | 0.370 | 0.383 | 0.391 | 0.384 | 0.386 | 0.387 | 0.376 | 0.297 | 12.37% | |
| AT | 0.355 | 0.365 | 0.365 | 0.356 | 0.356 | 0.352 | 0.352 | 0.253 | 4.83% | |
|
(2) Results on NB |
||||||||||
| 1:0 | 4:1 | 3:1 | 2:1 | 1:1 | 1:2 | 1:3 | 1:4 | 0:1 | Impr* | |
|
Micro-F1 |
||||||||||
| AS |
0.551 |
0.626 | 0.627 | 0.629 | 0.622 | 0.618 | 0.613 | 0.612 | 0.556 | 14.16% |
| EAT | 0.614 | 0.620 | 0.614 | 0.600 | 0.614 | 0.616 | 0.613 | 0.464 | 12.52% | |
| AT | 0.594 | 0.596 | 0.594 | 0.579 | 0.585 | 0.586 | 0.584 | 0.361 | 8.17% | |
|
Macro-F1 |
||||||||||
| AS |
0.250 |
0.353 | 0.352 | 0.349 | 0.337 | 0.338 | 0.338 | 0.346 | 0.296 | 41.20% |
| EAT | 0.313 | 0.306 | 0.306 | 0.281 | 0.297 | 0.304 | 0.310 | 0.226 | 25.20% | |
| AT | 0.304 | 0.296 | 0.291 | 0.275 | 0.281 | 0.287 | 0.285 | 0.163 | 21.60% | |
| Impr* = the greatest improvement in each row compared to LT (that is the column ''1:0''). | ||||||||||
Although the classification results of AT, EAT and AS shown in Table 5 are not very encouraging, there are special cases for which AT, EAT and AS can capture the meaning of the target Web page well. In the next experiment, we construct a virtual document by integrating the AT, or EAT, or AS to the target Web pages. The weight between AT, EAT, AS and the local text in the combination is changed from 4:1 to 1:4. The detailed result is given in Table 7. From Table 7 we could see that either AT, EAT or AS can improve the performance of classification to some extent with either classifier in terms of either Micro-F1 or Macro-F1. In particular, AS can provide greater improvement, especially with the NB classifier in terms of Macro-F1. The improvement is about 41.2% compared to the baseline, 12.8% compared to EAT and 16.1% compared to AT. Another observation from Table 7 is that the different weighting schemes do not make too much of a difference, especially in terms of Micro-F1.
In addition to the results reported above, we also combine the LT, EAT and AS together to test whether they complement each other. However, this combination makes a relatively very small improvement compared to the combination of LT and AS only.
1 and 1. AS can consistently
outperform AT with either NB or SVM classifier. In this part, we
test the effect of the query log's quantity. We divide the
entries in the query log into ten parts according to the time when
the entries are recorded. Each part contains about 10 percent of
the total entries. Firstly, we use the first part to construct
implicit links, and then construct AS. After that, we incorporate
these AS to the subset of ODP dataset that we used in previous
experiments (with the weighting schema as LT: AS = 2 : 1) and do
classification on the combined dataset. Then, we use the first
two parts and then the first three parts,  , until all the
parts are used. The results are shown in Figure 2. From Figure 2,
we could find that with more query logs used, the classification
performance improves steadily. Such an observation is very
encouraging since we can expect to get better results with larger
query logs. Another fact is that query log data are accumulated
rapidly with the popularity of search engines. Therefore, it is
safe to claim that the implicit link will play more and more
important roles in Web page classification.
, until all the
parts are used. The results are shown in Figure 2. From Figure 2,
we could find that with more query logs used, the classification
performance improves steadily. Such an observation is very
encouraging since we can expect to get better results with larger
query logs. Another fact is that query log data are accumulated
rapidly with the popularity of search engines. Therefore, it is
safe to claim that the implicit link will play more and more
important roles in Web page classification.
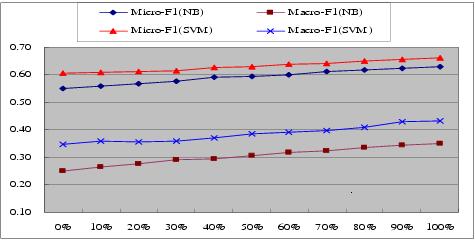
Figure 2: The effect of query log quantity
With the growing popularity of search engines, more and more query logs are being collected. We have shown here that these data can become an important resource for Web mining. In this paper, by analyzing the query log, we define a new relationship between Web pages - implicit links. In addition, we define different types of explicit links based on the existing hyperlinks. Similar to the Anchor Text used in the traditional way, we define a new approach to construct virtual documents by extracting the Anchor Sentences. Through the two different classification approaches, the ink-based method and the content-based method, we compared the contribution of the implicit links and the explicit links for Web page classification. The experimental results show that implicit links can improve the classification performance obviously as compared to the baseline method or to the explicit links based methods.
In the future, we will also test whether the implicit links will help Web page clustering and summarization. In addition, we wish to explore other types of explicit and implicit links by introducing other constraints, and compare them with the links given in this paper. Besides furthering the research following the framework of this paper, we will try to exploit more knowledge from the query logs. For example, when dealing with query logs, most researchers only consider the clicked pages and assume that there exist some ''similarity'' relationships among these pages. They neglect the ''dissimilarity'' relationships among the ''clicked Web pages'' and ''unclicked Web pages''. In our future work, we will study the possibility of constructing ''dissimilarity'' relationships to help Web page classification and clustering.
 martin/PorterStemmer/ind-ex.html
martin/PorterStemmer/ind-ex.html