1 Introduction
Sometimes a user's search query may be an imperfect description of their information need. Even when the information need is well described, a search engine or information retrieval system may not be able to retrieve documents matching the query as stated. For example, a user issues the query ``cat cancer'', but all documents in the collection use the expression ``feline cancer''. Our setting is sponsored search, in which we attempt to match enormous numbers of queries to a much smaller corpus of advertiser listings. Here recall is crucial, as conjunctive search often leads to no matching results.Existing solutions to this type of problem include relevance feedback and pseudo-relevance feedback, query term deletion [#!jonesFainSIGIR2003!#], substituting query terms with related terms from retrieved documents [#!terra04:Scoring!#], and Latent Semantic Indexing (LSI) [#!deerwester90indexing!#]. Pseudo-relevance feedback involves submitting a query for an initial retrieval, processing the resulting documents, modifying the query by expanding it with additional terms from the documents retrieved and then performing a second retrieval with the modified query. Pseudo-relevance feedback has limitations in effectiveness [#!ruthven2003!#]. It may lead to query drift, as unrelated terms are added to the query. It is also computationally expensive. Substituting query terms with related terms from retrieved documents also relies on an initial retrieval. Query relaxation or deleting query terms leads to a loss of specificity from the original query. LSI is also computationally expensive. In an alternative to automatic query modification or expansion, one could allow the user to select the appropriate related terms [#!AnickSIGIR2003!#]. This allows for user-aided disambiguation, though also at the cost of an extra iteration and cognitive load.
We propose query modification based on pre-computed query and phrase similarity, combined with a ranking of the proposed queries. Our similar queries and phrases are derived from user query sessions, while our learned models used for reranking are based on the similarity of the new query to the original query as well as other indicators. We are able to generate suggestions for over half of all web search queries, even after eliminating sensitive queries such as those containing adult terms. A random sample of query pairs are labeled for training the models, and we find that the proportion of good suggestions is significant in the sample (even without any training): 55% of the suggestions in the sample are labeled as highly relevant. When we apply machine learning, we improve performance over the baseline significantly, improving the detection accuracy for highly relevant pairs to 79%. We describe the application of our methods to sponsored search, discuss coverage, and examine the types of useful suggestions and mistakes that our techniques make.
Others using user query sessions as a source of information to improve retrieval include Furnas furnasCHI1985, who explicitly asked users whether their reformulations should be used for indexing, and Radlinski and Joachims radlinskiJoachims who use query chains followed by clicks as a source of relevance ordering information. Cucerzan and Brill cucerzan_brill04:spelling user query logs for spelling correction, but do not take advantage of user query reformulations.
Our contributions are: (1) identification of a new source of data for identifying similar queries and phrases, which is specific to user search data (2) the definition of a scheme for scoring query suggestions, which can be used for other evaluations (3) an algorithm for combining query and phrase suggestions which finds highly relevant phrases and queries 55% of the time, and broadly relevant phrases and queries 87.5% of the time and (4) identification of features which are predictive of highly relevant query suggestions, which allow us to trade-off between precision and recall.
In Section ![]() we define
the problem, describe our four types of suggestion quality, and
discuss possible query rewriting tasks and the sponsored search
application. In Section
we define
the problem, describe our four types of suggestion quality, and
discuss possible query rewriting tasks and the sponsored search
application. In Section ![]() we
describe our technique for identifying related phrases
(substitutables) based on user query-rewrite sessions,
and the basic process for generation of candidate query
substitutions. In Section
we
describe our technique for identifying related phrases
(substitutables) based on user query-rewrite sessions,
and the basic process for generation of candidate query
substitutions. In Section ![]() we
describe a basic rewriting system, combining whole-query and
phrase-substitutions based on user-session analysis. We then
describe experiments using machine learning to improve the
selection of query rewriting suggestions. In Section
we
describe a basic rewriting system, combining whole-query and
phrase-substitutions based on user-session analysis. We then
describe experiments using machine learning to improve the
selection of query rewriting suggestions. In Section ![]() we show
that using machine-learned models improves the quality of the
top-ranked suggestion, leading to high quality query
substitutions, as measured though human evaluation. In Section
we show
that using machine-learned models improves the quality of the
top-ranked suggestion, leading to high quality query
substitutions, as measured though human evaluation. In Section
![]() we show that we are able to assign a reliable confidence score to
the query-suggestion pairs, which allows us to set thresholds and
predict the performance of query suggestions when deployed.
we show that we are able to assign a reliable confidence score to
the query-suggestion pairs, which allows us to set thresholds and
predict the performance of query suggestions when deployed.
2 Problem Statement
Given a query There are many ways in which the new query ![]() could be related to the original query
could be related to the original query ![]() . Some may be improvements
to the original query, others may be neutral, while others may
result in a loss of the original meaning:
. Some may be improvements
to the original query, others may be neutral, while others may
result in a loss of the original meaning:
- same meaning, different way of expressing it
- spelling change
- synonym substitution (for example colloquial versus medical terminology)
- change in meaning
- generalization (loss of specificity of original meaning)
- specification (increase of specificity relative to original meaning)
- related term
To accommodate and allow quantification of these and other
changes, we define four types of query substitutions. We place
these on a scale of 1 to 4, with the most related suggestions
assigned a score of 1, and the least related assigned a score of
4. Examples of these are shown in Table ![]() , and we
define these classes below.
, and we
define these classes below.
1 Classes of Suggestion Relevance
- Precise rewriting: the rewritten form of the query
matches the user's intent; it preserves the core meaning of the
original query while allowing for extremely minor variations in
connotation or scope. Although the two forms may differ
syntactically, in most cases, the rewriting process should be
completely transparent to the user.
E.g.: automobile insurance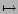 automotive insurance
automotive insurance - Approximate rewriting: the rewritten form of the
query has a direct close relationship to the topic described by
the initial query, but the scope has narrowed or broadened or
there has been a slight shift to a closely related topic.
E.g.: apple music player ipod shuffle - Possible rewriting: the rewritten form either has
some categorical relationship to the initial query (i.e. the
two are in the same broad category of products or services,
including close substitutes and alternative brands) or
describes a complementary product, but is otherwise distinct
from the original user intent.
E.g.: eye-glasses contact lenses,
orlando bloom johnny
depp - Clear Mismatch: the rewritten form has no clear
relationship to the intent of the original query, or is
nonsensical. E.g.: jaguar xj6 os x jaguar
2 Tasks
Depending on the task, different classes of rewriting
may be acceptable.
- Specific Rewriting (1+2) If the goal is to have a closely related query, in order to retrieve new highly relevant results, only the 1s and 2s are acceptable. Here we will measure performance in terms of the proportion of {1,2}. We will refer to this as ``specific rewriting'' or ``1+2''.
- Broad Rewriting (1+2+3) If the goal is to perform re-ranking of results retrieved with the initial query, (akin to relevance feedback), rewritings from classes 1, 2 and 3 may all be useful. Similarly all three classes may be useful if we wish to perform query expansion using the rewritten query. In addition, if the task is to find results relevant to the interests of the user, with the query as our indication of user interests, class 3 may be of interest too. Under all these conditions, we will measure our performance in terms of the proportion of query suggestions in classes {1,2,3}. We will refer to this as ``broad rewriting'' or ``1+2+3''.
3 Query rewriting for sponsored search
In sponsored
search [#!fain2005!#], paid advertisements relevant to a
user's search query are shown above or along-side algorithmic
search results. The placement of these advertisements is
generally related to some function of the relevance to the query
and the advertiser's bid.
While in general web search there are often many documents containing all of the user's search terms, this is not always true for sponsored search. The set of advertiser results is much smaller than the set of all possible web pages. For this reason, we can think of sponsored search as information retrieval over a small corpus, where in many cases a conjunctive match on all query terms will not give a result. In this setting, the ability to modify a user's query (which may have no sponsored results) to a closely related query (which does have results) has extremely high utility.
Sponsored search has a few interesting constraints that we
briefly touch on. The primary constraint is that we have a finite
set of possible rewritings: the set of phrases for which we can
return an advertisement. On one hand, this increases the
difficulty of the task in terms of coverage, because even if we
find a good rewriting for the initial query, it won't necessarily
be found in an advertiser's listing. On the other hand, the
constraint acts as a basic (language model) filter. If the
rewritten form of the query is available for sponsored search, it
is more likely to be meaningful. Thus this constraint can help
filter out nonsensical rewritings (E.g.: air jordan iv retro
![]() jordan intravenous
50s). Another constraint relates to the classes of queries
we can modify. For example, we avoid generating suggestions for
sensitive queries such as those containing adult terms.
jordan intravenous
50s). Another constraint relates to the classes of queries
we can modify. For example, we avoid generating suggestions for
sensitive queries such as those containing adult terms.
We expect that the work we present here is relevant to other applications of query rewriting, such as for general web retrieval.
3 Substitutables
Given an initial search query 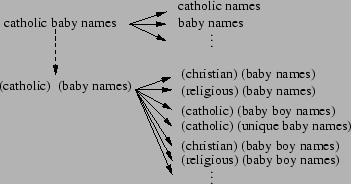 |
Thus we would like to have a source of similar queries, and similar phrases. While we could use static sources such as WordNet [#!fellbaum98wordnet!#] to identify similar phrases, in general this will not allow us to generate suggestions for new concepts such as products, movies and current affairs that arise in query streams. Another possibility is to use within-document cooccurrence statistics to find related phrases, as these have been found useful for finding query-relevant terms [#!terra04:Scoring!#]. One could also use anchor text, which has been found useful for generating query refinements [#!kraftAnchorText!#]. For using data as close as possible to our target task, however, we chose to work with user-sessions from search query logs. Previous work has shown these sessions to contain around 50% reformulations [#!jonesFainSIGIR2003!#,#!spink00:use!#]. In these query-session reformulations, a user modifies a query to another closely related query, through word insertions, deletions and substitutions, as well as re-phrasing of the original query.
1 Definition of Query Pair
The data used comes from logs of user web accesses. This data contains web searches annotated with user ID and timestamp. A candidate reformulation is a pair of successive queries issued by a single user on a single day. Candidate reformulations will also be referred to as query pairs.We collapse repeated searches for the same terms, as well as query pair sequences repeated by the same user on the same day. We then aggregate over users, so the data for a single day consists of all candidate reformulations for all users for that day.
2 Phrase Substitutions
Whole queries tend to consist of several concepts together, for example ``(new york) (maps)'' or ``(britney spears) (mp3s)''. Using phrases identified by high point-wise mutual information, we segment queries into phrases (where a single word can be a phrase), and find query pairs in which only one segment has changed. For example, the query pair : (britney spears) (mp3s)Note that the point-wise mutual information measure we use to identify phrases looks for adjacent terms whose mutual information is above a threshold:
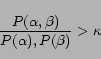
where we set the threshold ![]() to be 8. We also experimented with the connexity
approach to identifying phrases [#!fastwww03!#], and found that
our methods are not sensitive to the approach used to identify
phrases.
to be 8. We also experimented with the connexity
approach to identifying phrases [#!fastwww03!#], and found that
our methods are not sensitive to the approach used to identify
phrases.
3 Identifying Significant Query Pairs and Phrase Pairs
In order to distinguish related query and phrase pairs from candidate pairs that are unrelated, we use the pair independence hypothesis likelihood ratio. This metric tests the hypothesis that the probability of termThe likelihood score is
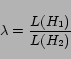
The test statistic
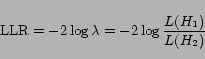
A high value for the likelihood ratio suggests that there is a strong dependence between term
Because of the ![]() distribution of
distribution of ![]() , a
score of 3.84 for LLR gives us a 95% confidence that we can
reject the null hypthesis, and two phrases are statistically
significantly related. However, this will give us 1 in 20
spurious relationships. As we are dealing with millions of
phrases, we set the threshold on LLR much higher, generally to
above 100, based on observation of the substitutable pairs.
, a
score of 3.84 for LLR gives us a 95% confidence that we can
reject the null hypthesis, and two phrases are statistically
significantly related. However, this will give us 1 in 20
spurious relationships. As we are dealing with millions of
phrases, we set the threshold on LLR much higher, generally to
above 100, based on observation of the substitutable pairs.
|
4 Generating Candidates
We seek to generate statistically significant related queries for arbitrary input queries. For frequent queries, we have dozens of such related queries. But for less frequent queries, we may not have seen sufficiently many instances of them to have any statistically significant related queries. We can't ignore infrequent queries: infrequent: the power-law (Zipf) distribution of query terms leads to a large proportion of rare queries.
In the same way as we generated the phrase-substitutables, we
can break up the input query into segments, and replace one or
several segments by statistically significant related segments.
This will help cover the infrequent queries. Figure ![]() shows a
schematic of the approach we take:
shows a
schematic of the approach we take:
- generate
 candidate
whole-query substitutions
candidate
whole-query substitutions
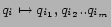
- segment query into phrases
- for each phrase
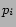
- generate
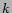 phrase-substitutions
phrase-substitutions
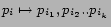
- generate new query from a combination of original
phrases and new phrases:
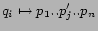
- generate
This gives us a set of query-substitution candidates which we
will denote ![]() .
.
As an example, consider the query ``catholic baby names''. We
can find whole-query substitutions from our query substitutables,
such as ``catholic names''. We can also segment the query into
the two phrases ``catholic'' and ``baby names'', and find
substitutions for these phrases (see Figure ![]() ).
).
4 Experimental Method
We will compare a variety of methods for generating query substitutions. Our evaluation will consider only the query suggestion, i.e., given a randomly sampled queryFor each evaluation, we use a random sample of 1000 initial
queries ![]() sampled from query logs
from a disjoint time period to our substitutables query data, and
generate a single suggestion
sampled from query logs
from a disjoint time period to our substitutables query data, and
generate a single suggestion ![]() for
each. We will evaluate the accuracy of approaches to choosing the
suggestion to generate, by reporting the proportion of
suggestions falling into the classes precise (class 1+2)
and broad (class 3+4).
for
each. We will evaluate the accuracy of approaches to choosing the
suggestion to generate, by reporting the proportion of
suggestions falling into the classes precise (class 1+2)
and broad (class 3+4).
To assess whether there are properties of the suggestions
which are predictive of good quality, we will train a
machine-learned classifier on the labeled
![]() pairs. We will then
evaluate our ability to produce suggestions of higher quality for
fewer queries, by plotting precision-recall curves.
pairs. We will then
evaluate our ability to produce suggestions of higher quality for
fewer queries, by plotting precision-recall curves.
5 Automatic Assessment of Substitution Quality
Whole query
substitutions and many of the possible combinations of
substituted phrase segments yield hundreds of candidates for
common queries. Only a few are good, and we need to assess and
predict quality as well as rank.
We first describe two simple methods for ranking candidates.
In order to develop a more sophisticated ranking scheme, we take
the top suggestion from one of these ranking schemes and use
machine learning and human judgements to learn a model of high
quality suggestions. We describe how we use the learned
classifier to learn a more accurate re-ranking of candidate
suggestions in Section ![]() .
.
1 Basic Query Substitution Ranking Algorithms
1 Random Ranking Algorithm
Our baseline candidate selection
method is randomRank:
- Set the maximum number of whole query alternatives
to 10
- Segment the query, and assign number of alternatives per
phrase, , as a function of the
number of constituent phrases
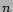 :
:
- if (
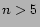 )
= 5
)
= 5 - else = 10
- if (
For randomRank we require all whole query and phrase suggestions to have an LLR score of at least 50. We set the threshold lower than the value of 100 we have empirically observed to be a useful setting, in order to assess the performance of suggestions over a range of LLR scores.
We sample one query uniformly at random from this sample. Note
that we are much more likely to select a phrase-substitution than
a whole query substitution: for a query with two phrases, there
are up to
![]() new
queries generated by phrase substitution, and only 10 generated
by whole-query substitution.
new
queries generated by phrase substitution, and only 10 generated
by whole-query substitution.
2 Substitution Type and Log-likelihood Ratio Score
We designed our next method, LLRNumSubst, using the following intuitions, based on our experience with samples of the generated candidates:
- First try whole-query suggestions ranked by LLR score
- then try suggestions which change a single phrase, ranked by the phrase substitution LLR score
- then try suggestions which change two phrases, ordered by the LLR scores of the two phrases
- ...
|
2 Query Substitution with Machine Learning
Rather than making assumptions about what makes a good
substitution, we can treat our problem as a machine learning
problem. The target to learn is the quality of the substitution,
and we provide features that we expect to be reasonably
efficiently computable. We tried both linear regression and
binary classification approaches. For classification, we learn a
binary classifier over query pairs:
| (1) |
We evaluate on two binary classification tasks, as specified
in Section ![]() :
:
- broad (classes 1+2+3) for which the negative class will be rewritings labeled 4
- specific (classes 1+2) for which the negative class will be rewritings labeled 3+4.
1 Labeled Data
Our training data was a sample comprised of the top-ranked suggestion for each of 1000 queries, where the top-ranked suggestion was generated using the LLRNumSubst ranking scheme described Section2 Features
We generated 37 features for each initial and rewritten query pair- Characteristics of original and substituted query in isolation: length, number of segments, proportion of alphabetic characters.
- Syntactic substitution characteristics: Levenshtein edit
distance, number of segments substituted, number of tokens in
common, number of tokens specific to
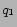 , to
, to 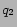 , size of
prefix overlapping, stemming relationship.
, size of
prefix overlapping, stemming relationship. - Substitution statistics: LLR, frequency,
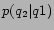 , mutual
information. Where multiple phrases were substituted in a
single query, these features were computed for the both the
minimum and the maximum.
, mutual
information. Where multiple phrases were substituted in a
single query, these features were computed for the both the
minimum and the maximum.
|
3 Linear Regression
We used the original labels {1, 2, 3, 4} and performed standard linear regression. The forward-backward stepwise process reduced the number of features from 37 to 20. We kept only the features with p-value smaller than plus number of substitutions and experimented with different combinations. The simplest best fit was obtained with the following features:- Word distance: prefer suggestions with more words in common with the initial query
- Normalized edit distance: prefer suggestions with more letters in common with the initial query
- Number of substitutions: prefer whole query suggestions over phrase suggesions, prefer fewer phrases changed.
It is interesting to note that none of the features relating
to the substitution statistics appeared in the best models. This
may be due to the fact that the training query suggestions were
selected using the LLRNumSubst method which takes LLR score into
account. The ranking function we learn is shown in Equation
![]() .
.
We can interpret this model as saying that, given that a suggestion is among the top ranked suggestions according to the LLRNumSubst ranking, we should prefer query substitutions with small edit distance (perhaps spelling and morphological changes) and with small word edit distances (perhaps word insertions or deletions). We should prefer whole-query suggestions, and if we substitute at the phrase segment level, the fewer the substitutions the better.
4 Classification Algorithms
We experimented with a variety of machine learning algorithms to assess performance achievable and the utility of the overall feature set. We experimented with linear support vector machines (SVMs) [#!chang-libsvm!#] allowing the classifier to choose its own regularization parameter from a fixed set (using portion of training data only), and decision trees (DTs). For the SVM, we normalized features by dividing by the maximum magnitude of the feature, so all features were in the range [-1,1]. For tree induction, no pruning was performed, and each feature was treated as numeric. Bags of 100s of decision trees performed best, under a number of performance measures. On the task of distinguishing {1+2} from {3+4} (baseline of 66% positive using data generated with LLRNumSubst described in Section
If (number of tokens in common is nonZero )
then {1+2}
else if (prefix overlap is nonZero)
then {1+2}
else
{3+4}
end
end
We can interpret this model as saying that a suggestion
should ideally contain some words from the initial query,
otherwise, the modifications should not be made at the beginning of
the query.
6 Results
For all learning algorithms we report on, we
performed 100 random 90-10 train-test splits on the labeled data
set, and accumulated the scores and true labels on the hold-out
instances. We plot the precision-recall curve to examine the
trade-off between precision and recall. The 1 Results of Regression and Classification
Figure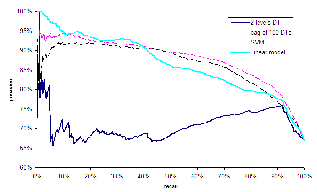
We would like to apply one of these models for selecting the suggestion for an initial query from the pool of possible candidates, Q'. For our subsequent experiments we experimented with the linear regression model for its execution time efficiency, as it only requires three easy to compute features.
2 Precision of Top-ranked Suggestion
We will now turn our
attention from the binary classification of pre-selected query
pairs, to the ranking of multiple candidate suggestions Q' for a
single input query. We have the two ranking schemes (1)
randomRank and (2) LLRNumSubst described in
Sections We can now compare the precision of the top-ranked suggestion
of these three ranking schemes. Note that each was used to
generate suggestions for a distinct sample of 1,000 queries. In
Table ![]() we see
that the substitutables are an excellent source of related terms:
the baseline random ranking achieved precision of 55% on the
specific rewriting task of identifying highly relevant
suggestions for queries. The LLRNumSubst algorithm
improved the performance to 66%, while NumSubstEdit's
re-ranking of a separate sample of LLRNumSubst candidates
increased precision of the top suggestion to 74%.
we see
that the substitutables are an excellent source of related terms:
the baseline random ranking achieved precision of 55% on the
specific rewriting task of identifying highly relevant
suggestions for queries. The LLRNumSubst algorithm
improved the performance to 66%, while NumSubstEdit's
re-ranking of a separate sample of LLRNumSubst candidates
increased precision of the top suggestion to 74%.
|
For generating a suggestion for broad rewriting, which allows suggestions from each of classes {1,2,3} LLRNumSubst generates an appropriate top-ranked suggestion for 87.5% of a sample of 1000 queries. Our source of data, the substitutables, is by construction a source of terms that web searchers substitute for one another, leading to a large proportion of broadly related suggestions. Re-ranking LLRNumSubst's candidate suggestions with NumSubstEdit does not result in increased precision of the top-ranked candidate for broad rewriting.
3 Coverage
We are not able to generate suggestions for all
queries for several reasons:
- Data sparseness: for many queries, we have seen too few instances to have statistically significant whole query or phrase substitution instances.
- Sponsored search setting: we are constrained to generating suggestions for which we have an advertiser.
- Risk averse algorithm design: we eschew generating suggestions for adult queries (around 5% of the input query sample), and for other sensitive terms.
- Novelty constraint: we reject suggestions which are deemed to be identical to the original query by a baseline normalization procedure.
Under these constraints, our methods (e.g., Random
Selection of Section ![]() ) yield at
least one suggestion for about 50% of queries.
) yield at
least one suggestion for about 50% of queries.
When we break down the coverage by query decile we see that
the coverage varies by decile. Decile 1 contains the queries
constituting the top 10% of query volume, while decile 10
contains the most infrequent queries, most of which have a search
frequency of only 1 in the sampled time-period. The histogram
shown in Figure ![]() was
generated by using the NumSubstEdit method to select a
candidate. We see that our method allows generation of
suggestions for both frequent and infrequent queries.
was
generated by using the NumSubstEdit method to select a
candidate. We see that our method allows generation of
suggestions for both frequent and infrequent queries.
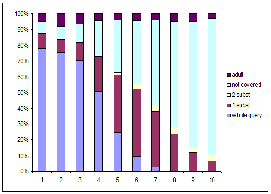
We generate a suggestion for more than 10% of queries from decile 10, many of which would typically have no sponsored search result. This incremental coverage is primarily due to phrase substitution: for the frequent queries, we were able to find whole query substitutions, but for the less frequent ones, only breaking the query into phrase segments allowed us to generate a result.
Examples of queries with a low monthly query frequency for which we changed 1 or 2 units:
new testament passages ![]() bible quotes
bible quotes
cheap motels manhattan, ny ![]() cheap hotels manhattan, ny
cheap hotels manhattan, ny
7 Confidence Model
For each query suggestion generated by our
algorithm, we would like to associate a probability of
correctness (confidence score). For example, for the query pair
1943 nickel 1 Evaluating Confidence Models
We evaluate our confidence models by comparing them to the true binary (0,1) label. If a query pair was labeled 1 or 2 by our human labelers, the ideal confidence model would say the pair is correct with probability 1. In this case we will say the true probability of correctnessWe evaluate our confidence models using root-mean squared
error (RMSE):

where
2 Baseline Confidence Models
Our uniform model assumes the probability is the same for all suggestions: the overall precision of the model (0.73). Shift and scale (SS) is the simple monotonic transformation which maps the score onto a [0,1] scale by subtracting the minimum score and dividing by [max - min].3 Comparison of Confidence Estimation Techniques
We experimented with several well known techniques for transforming a score into a probability, and evaluated their RMSE and Log-Loss on 100 80-20 train-test splits. Results are shown in TableIsotonic regression [#!lutz2000!#] (Iso) performs well, but
tends to overfit1. Fitting an asymmetric distribution
[#!bennett2003!#] (ADist) is a promising technique in general,
but for our task no true distribution could model well the
![]() class and thus the
performance was not as good as with the other techniques. The
best results were obtained with a sigmoid [#!platt1999!#] (SS).
The sigmoid also has the advantage of being a simple model to
implement.
class and thus the
performance was not as good as with the other techniques. The
best results were obtained with a sigmoid [#!platt1999!#] (SS).
The sigmoid also has the advantage of being a simple model to
implement.
Consequently, we used the sigmoid to model the probability
function: 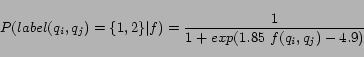
4 Threshold Model
For different applications of our
query-suggestion algorithm, we may want to ensure that the
average precision will be higher than a given threshold. This
differs from the confidence model, in that we consider a set of
We could directly rely on the observed data, and for each
value of the threshold, count how many times suggestions with a
score higher than this threshold were correct. A drawback of this
approach is that for high thresholds, we will have very little
data with which to estimate the precision. This can be observed
on the graph of the estimated precision for given thresholds in
Figure ![]() . The
confidence interval increases with the threshold, and with a high
threshold, we are not able to give a reliable estimate.
. The
confidence interval increases with the threshold, and with a high
threshold, we are not able to give a reliable estimate.
We have a probability model, and we can take advantage of it
using the following integration. For a set of query
transformations ![]() , if we
accept only those with a probability of correctness
, if we
accept only those with a probability of correctness ![]() greater than
greater than ![]() , the average precision will
be:
, the average precision will
be:
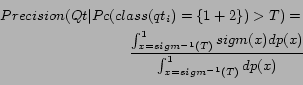
where
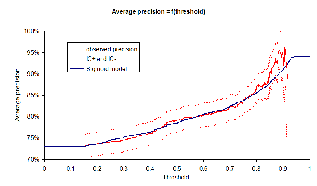 |
Still it is odd that we have an under-confident estimate. This is due to the fact that the true model of the probability is not sigmoid-shaped for high scores. When we replace the flattening part of the sigmoid with a line ramping up faster than the sigmoid, we have better results as measured with RMSE. Nevertheless, since we have few datapoints with high scores, it is safer to assume that the probability for high scores is flattening. We can integrate to get the associated confidence threshold. For instance, if we want to ensure an average precision of 75%, we need to reject any rewriting with a confidence lower than 17%. If we want to ensure an average precision of 85%, we need to refuse any rewriting with a confidence lower than 76%.
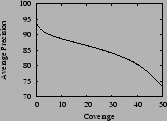
In Section ![]() we looked
at precision-recall curves. We now take into account both the
incomplete coverage, the continuous score of the linear model and
the threshold model transformation. This allows us to tune for
more or less coverage and predict the expected average precision.
As we can see in Figure
we looked
at precision-recall curves. We now take into account both the
incomplete coverage, the continuous score of the linear model and
the threshold model transformation. This allows us to tune for
more or less coverage and predict the expected average precision.
As we can see in Figure ![]() , we
can have, for example:
, we
can have, for example:
- precision: 90% coverage 7%
- precision: 80% coverage 42%
- precision: 75% coverage 49%
5 Examples of Estimated Relevance Scores
Using the NumSubstEdit linear model with sigmoid normalization, we have observed that substitution types in order of decreasing confidence tend to be spelling variants, then query expansion and relaxation, then synonyms and related terms, and finally approximate matching with every word changed. In Table
|
8 Discussion
The NumSubstEdit algorithm prefers suggestions with small edit distance and few words changed. This is often effective for identifying specific (1+2) suggestions, as we showed in Section
|
One of the causes of the broader suggestions is our approach
to identifying possible phrase substitutions. Very general
contexts can lead to broad types of substitutions: (britney
spears) (mp3s) ![]() (christina
aguilera) (lyrics) gives us the phrase pair: britney
spears
(christina
aguilera) (lyrics) gives us the phrase pair: britney
spears ![]() christina
aguilera. We are investigating methods for detecting very
broad changes, such as considering the entropy of the rewrites
found in a given context.
christina
aguilera. We are investigating methods for detecting very
broad changes, such as considering the entropy of the rewrites
found in a given context.
While we showed in Section ![]() that
coverage varies across deciles, the precision of suggestions is
generally constant across deciles. However, there are still
differences between the suggestions we generate for frequent and
infrequent queries. We tend to generate more spelling variants
for the infrequent queries: we see 0% spelling change for initial
queries in decile 1, and 14% for decile 10. The reason may simply
be that infrequent queries are much more likely to contain
misspellings, and spelling corrections are the easiest
suggestions to generate.
that
coverage varies across deciles, the precision of suggestions is
generally constant across deciles. However, there are still
differences between the suggestions we generate for frequent and
infrequent queries. We tend to generate more spelling variants
for the infrequent queries: we see 0% spelling change for initial
queries in decile 1, and 14% for decile 10. The reason may simply
be that infrequent queries are much more likely to contain
misspellings, and spelling corrections are the easiest
suggestions to generate.
Even with an excellent source of related terms such as the substitutables, we occasionally generate poor suggestions. We have observed that these errors are frequently produced because of polysemy: some terms are good substitutes for each other in one context, but not in another. For instance, while software is related to system in the context of computer science, it is not in the context of the term ``aerobic''. We generated the poor suggestion:
Both are popular queries, certainly likely issued often in the
same sessions, but it is unlikely that a user's specific search
need when searching for one is satisfied by serving results for
the other.
Overall our query substitution technique is extremely efficient, especially in comparison to retrieval-based techniques such as pseudo-relevance feedback, and matrix multiplication methods such as LSI. For whole-query suggestions, we are able to precompute the query substitutions and their scores offline, and so at run-time we require just a look-up. For phrase substitutions, we precompute edit distance between phrases offline, so when we look-up substitutions for each phrase at run-time, we require linear normalization of the edit-distance score, as well as computing the linear score with multiplications and additions.
9 Conclusions and Future Work
We have shown that we are able to generate highly relevant query substitutions. Further work includes building a semantic classifier, to predict the semantic class of the rewriting. With such a classifier we would be able to focus on the targeted subtypes of rewriting, such as spelling variants, synonyms, or topically related terms.To improve our algorithm, we can also take inspiration from machine translation techniques. Query rewriting can be viewed as a machine translation problem, where the source language is the language of user search queries, and the target language is the language of the application (for instance advertiser language in the case of sponsored search).
In order to generalize our work to any application, we also need to work on introducing a language model, so that in the absence of filtering with the list of sponsored queries, we avoid producing nonsensical queries. In addition, with the algorithm in operation we could learn a new ranking function using click information for labels.
10 Acknowledgements
Thanks to Tina Krueger and Charity Rieck for work on the evaluation, to Paul Bennett for helpful discussions, and to the anonymous reviewers for helpful comments.No References!
Footnotes
- ... overfit1
- The variance of the RMSE across different cross validation runs was much higher than for other techniques.