![\begin{figure}\small \begin{Verbatim}[frame=single] <feed> <title>NYT Technol... ...y> <!-- more entries --> </feed>\end{Verbatim} %\vspace{-5pt} \end{figure}](fp2025-jun-img1.png) |
The advent of the web and more recently blogs introduce an unprecedented opportunity for information sharing in that anyone can write their knowledge and opinion for everyone to read. According to the BBC, one blog is created every second these days, reaching more than 14.2 million blogs [11]. Although the increased level of information flow possibly evolves our society forward, such advancement necessitates an efficient way of exchanging information.
As a response to the need of efficient information exchange, the standards such as RSS (really simple syndication or rich site summary) and later Atom have been introduced. They specify document formats that are used to contain a list of entries summarizing recent changes in a web site or a blog. These RSS or Atom feeds, referred to as news feeds throughout the paper, are used by end users as well as other web sites. Currently, most traditional mass media and personal blogs publish their articles in news feeds. However, the standards around this technology have paid little attention to an efficient delivery of news feeds. In fact, there is currently no distinction between news feeds and regular web pages from a web server's perspective. Thus, if users are to check whether new entries are published, they only have to fetch the feed documents as frequently as they want. The lack of effective notification of updates can lead to the aggressive probing, which not only wastes clients' network bandwidth but more importantly overloads the servers.
In this paper, we design and evaluate FeedEx, a news feed exchange system. Its nodes form a distribution overlay network over which news feeds are exchanged. Since this exchange allows nodes to reduce the frequency of fetching documents from servers, it can decrease the server load. In a sense, FeedEx builds an effective notification system that the current news feed technology lacks. Due to the effective notification, nodes benefit from timely delivery and high availability of feeds. We design an incentive mechanism for FeedEx so that nodes are encouraged into being collaborators rather than free riders. Since FeedEx does not require any modification of current feed servers or document formats, it can be readily deployed. Our Internet experimental results show that it achieves high availability and quick delivery time with low communication overhead, thus helping the feed servers scale well.
The rest of this paper is organized as follows. The remainder of this section gives the background on the news feed technology and points out the benefits of FeedEx. In Section 2, we present relevant statistics about news feed publishing by analyzing the data collected from 245 feeds for 10 days. Section 3 describes the design and the protocol of FeedEx. We evaluate the system and show the experimental results in Section 4. Related work is presented in Section 5, and the conclusions in Section 6.
We briefly introduce the standards and terminology about news feeds. Although several versions of news feeds specify formats that are compatible to a varying degree [33], they convey more or less the same content at a high level. A simplified sample of news feed is shown in Figure 1. A feed in Atom terminology (or channel in RSS terminology) is a place at which related entries are published and is identified by a URL from which feed documents are fetched. A feed document contains a list of entries (or items) as well as metadata about the feed itself such as the feed title and the published date. Each entry in turn contains a list of elements including the title of the entry, the link from which detailed information can be obtained, and the summary (or description) of the entry.
The news feed standards are concerned only with the document format. From a web server's perspective, fetching a feed document is the same as fetching a regular web document, using the unmodified HTTP. Thus, subscribing to a news feed does not mean that feed documents are delivered automatically upon a change. It merely means that subscribers fetch the corresponding URL repeatedly, either manually or through a client-side setup. Likewise, publishing a feed does not mean that publishers actually ``push'' documents to subscribers. It is subscribers and their applications that should ensure the timely update of news feeds. Nevertheless, these terms are used conventionally, and in this paper as well, to emphasize the dynamics of contents and the persistent behavior of readers regarding news feeds.
Starting as a means of syndicating web sites, the news feed technology has evolved so much as to be used in various ways. For example, Mozilla web browsers provide Live Bookmarks [1], which treat a feed as a folder and the contained entries as bookmarks in it, while Microsoft's new operating system, code-named ``Longhorn,'' supports this technology from a broader perspective [7]. In this paper, we focus on its primary functionality, that is, delivering news summaries. In particular, we explore the potential of sharing news feeds among peers to expedite the dissemination and reduce the server loads.
Currently, there are two ways of consuming news feeds. One way is using stand-alone applications, which look and work like traditional news readers or email clients except that posting is not possible. In fact, some email clients such as Mozilla Thunderbird support this functionality. Such applications, thus far, interact with nothing but the feed servers. Another way is using web-based services such as My Yahoo. If users register news feeds of their interests, they read them in one place provided by the web service. Allowing nodes to exchange news feeds with other nodes, FeedEx has several advantages over stand-alone and web-based aggregators:2
|
[Distribution of publishing rate. The line is
fitted between ranks 30 and 200.]rank-ecount
[Histograms about entry count. Two long bars go
up to 79 and 159, respectively.]hist
[Change of publishing rate. Each bar is one hour wide. Notice different y-axis scales.]activity [Cumulative distribution of entry lifetime. Vertical guidelines indicate days.]cdf |
As a first step towards exploring this new application, we focus this paper on the server scalability and the news entry availability.
We analyze various aspects of the current practice of news feed publishing. Understanding the current practice is not only interesting by itself but also helpful for a better design of FeedEx. Based on the popularity in Gmail's ``web clips'' and Bloglines' ``most popular feeds,'' a total of 245 news feeds are chosen for monitoring. We fetch a document from each feed every two minutes in order to continually observe the activity. Entries in a document are identified by their identifiers (e.g., the id element for Atom or guid for RSS 2.0). If no identifier is provided by the feed, we use a pair of the title and the link elements as an identifier. We find 6 different versions3 from 245 news feeds. With the data collected for 10 days, we analyze the following aspects of news feed publishing.
First, we characterize the distribution of publishing rates.
The characterization into a certain distribution is useful, for
example, to generate a synthetic model. As some feeds publish at
a high rate while many others at a low rate, we hypothesize that
the distribution follows Zipf's law, which states that the size
or frequency ![]() of an event of rank
of an event of rank
![]() is inversely proportional to
is inversely proportional to
![]() , where
, where ![]() is a positive constant, and
is a positive constant, and ![]() is an index (starting from one) into the list sorted in
the non-increasing order [8]. Many quantities on the web
seem to follow the Zipf distribution: the number of visits to a
site, the number of visits to a page [14], and the number of links to a
page [9], to name a few.
Note that since
is an index (starting from one) into the list sorted in
the non-increasing order [8]. Many quantities on the web
seem to follow the Zipf distribution: the number of visits to a
site, the number of visits to a page [14], and the number of links to a
page [9], to name a few.
Note that since ![]() , for
some constants
, for
some constants ![]() and
and ![]() , if
, if ![]() is drawn
against
is drawn
against ![]() on a log-log plot, a
straight line should be observed. Thus, putting on a log-log plot
is an easy, graphical way to see whether a distribution follows
Zipf's law.
on a log-log plot, a
straight line should be observed. Thus, putting on a log-log plot
is an easy, graphical way to see whether a distribution follows
Zipf's law.
Figure 2(a) shows the distribution of publishing rates. Feeds are ranked in the descending order of publishing rate and then put on the log-log plot. While the middle range (from rank 30 to rank 200) is well fitted on the line, both ends deviate from the line. The upper left corner (head) is crowded by such sites as Reuters, CNN, BBC, and Yahoo's Top Stories, which tend to publish news articles similar in both amount and contents. It is also due to multiple active feeds from a single site. For example, Yahoo publishes Top Stories, Entertainment, and Most Emailed Stories, all at high rates. Given that we only plot popular feeds, which are highly likely to publish at high rates, the deviation in the lower right corner (tail) will be compensated for by a huge amount of less popular feeds.
Next, we show the distributions of entry counts for the news
feeds. An entry count is referred to as the number of entries in
a document. Instead of showing 245 histograms, we use two
summarizing histograms shown in Figure 2(b). The histogram on the left shows the
distribution of the arithmetic means of entry counts, indicating
that many feeds contain 10 (in 30 feeds) or 15 (in 79 feeds)
entries in a document on average. One feed, in contrast, contains
as many as 126 entries on average. The histogram on the right
shows the distribution of the ranges of entry counts. A range is
defined as the difference between the maximum and the minimum
entry counts for a feed. The histogram indicates that 65% of
feeds have a fixed entry count, as their ranges are 0. Other
feeds use variable length presumably to cope with the bursts of
entries generated. Although not shown by a figure, there exists
little correlation between the publishing rate and the entry
count as the coefficient of determination ![]() from the linear regression is only 0.06.4 The
lack of correlation between the two variables implies that the
entries from the feeds with high publishing rates should live
shorter.
from the linear regression is only 0.06.4 The
lack of correlation between the two variables implies that the
entries from the feeds with high publishing rates should live
shorter.
Third, Figure 2(c) shows the change of publishing rate over the first week of monitoring. For a better presentation, we select four feeds that represent distinct patterns. The vertical guidelines indicate midnights in EDT (4 hours behind UTC/GMT). In most feeds publishing at high rates, represented by the Reuters graph, the publishing rate is affected by the time of day. That is, publishing is more active during day than in night. By contrast, Yahoo's Most Emailed Stories does not show such periodicity because, we suspect, the feeds are generated by the feedback of users, who live in different time zones and whose activity is more dispersed. We also find that many feeds, like Motley Fool, do not show any activity during the weekends, which fall on days [4,6) in the graph. Another observation is that feeds such as NPR update feeds only at certain times of day. Although the predictability may be a good hint for subscribers, it is likely to cause ``flash crowd'' on such servers.
Last, Figure 2(d) shows cumulative distributions of entry lifetime from four selected feeds. The vertical guidelines mark the lengths of days. Most feeds publishing at a high rate show a similar distribution to that of CNN. Fox News and some other feeds exhibit linear progression up to a certain time. Note that this means a uniform distribution (flat range in a probability density function). We believe that it occurs as a result of the publisher's policy that controls entry lifetime. For example, the publisher may assign importance to each entry so that it lives as long as its importance. With variable-size documents as in FoxNews and TechBargains, it is easier to implement such a policy about the lifetime of entries. Beta News shows an interesting distribution in which entries' lifetimes are discrete with three levels (one day, two days, and four days long), which also seems to result from some policy.
We describe the design and the operation of FeedEx, a news feed exchange system. As Figure 3 shows, a node is connected to a small number of neighbors. It occasionally, depending on the scheduler policy, fetches a document from a feed server to which it subscribes. If it finds new entries from the fetched document, it propagates them to the neighbors that are interested in them. At the same time, new entries may become available from a neighbor. In this case, it forwards new entries to other relevant neighbors.
A node is identified by a pair of IP address and port number. The IP address of a node is taken implicitly by the neighbor from the connection, HTTP and hence TCP, information while the port number is stated explicitly by the requester. The port number indicates the listening port of the XML-RPC server. The implicitly taken address (using, for example, a getpeername system call on UNIX systems) helps prevent the Sybil attack [21] as it is difficult for an adversary to establish a connection through the 3-way handshaking of TCP with its identity (i.e., IP address) spoofed. Secure binding of identity is required for reliable accountability, which in turn helps build a robust system. We do not address issues caused by network address translation or other mechanisms that hamper the network transparency [15].
A feed is identified by the URL with which it is associated. Occasionally, more than one URL maps to the same feed. Such aliases are resolved externally as it is difficult to distinguish without human intervention. An entry, as discussed in Section 2, is identified by the id or guid element along with the URL of the feed. In the absence of such an identifier, a pair of the title and the link elements determines an entry.
A node advertises a subscription set to the neighbors. The subscription set contains a list of feeds in which the node is interested. Thus, the neighbors forward only the entries whose feed is in the advertised subscription set. Since the subscription set can contain feeds that are not in its interest but in its neighbors' (explained later), each feed in the set is tagged by an integer called hop count of interest. For example, hop count 0 means that the feed is in the advertising node's direct interest, hop count 1 means that the feed is not in its interest but in at least one of its neighbors', and so forth. A subset of a subscription set that contains only the feeds of hop count 0 is referred to as direct subscription set.
In the rest of this section, we describe the detailed protocol and operation of FeedEx. The protocol uses XML-RPC [37], and we refer to the relevant functions in Table 1 as we proceed.
Bootstrapping is a procedure through which a node becomes part of the system. It proceeds in two steps. The first step of bootstrapping is to acquire a list of nodes that are currently running in the system. The list can be obtained from three sources. First, a node can contact a well-known server that provides the list (using the get_neighbors call in Table 1). This list server is similar to the host cache service in Gnutella [17] and the tracker in BitTorrent [18]. The contacting node includes its information so that it can be included later in the lists for other nodes. Second, the feed servers may append to a feed document a list of clients that have recently retrieved the same feed. This idea, similar to Pseudoserving [28] and CoopNet [31], appeals to the servers because they are able to reduce the workloads in the long run by redirecting clients. Third, if a node has participated in the system before, it may reuse some of its earlier neighbors that are available at the moment. Reconnecting to old neighbors is advantageous in that they can trust each other from the past experience (see Section 3.5 for the incentive issue).
The second step of bootstrapping is to connect to the nodes
whose locations are obtained in the first step. The
connect call, shown in Table 1,
carries the subscription set as an argument. Each element of the
subscription set is a pair of the URL of a feed and the hop count
of interest, as explained earlier. If the connected node
![]() decides to accept the
connecting node
decides to accept the
connecting node ![]() ,
, ![]() returns its subscription set
to
returns its subscription set
to ![]() . Then,
. Then, ![]() updates its subscription set including hop counts.
updates its subscription set including hop counts.
![]() 's returning set must be
computed excluding
's returning set must be
computed excluding ![]() 's
advertisement. Otherwise,
's
advertisement. Otherwise, ![]() would
falsely advertise back the feeds in which only
would
falsely advertise back the feeds in which only ![]() , and none of
, and none of ![]() 's
other neighbors, is interested. If
's
other neighbors, is interested. If ![]() decides not to accept
decides not to accept ![]() (for example,
because
(for example,
because ![]() 's neighbor capacity is
full), it returns an empty set, which is interpreted accordingly
by
's neighbor capacity is
full), it returns an empty set, which is interpreted accordingly
by ![]() . Other reasons for rejection
are discussed in Section 3.2.
. Other reasons for rejection
are discussed in Section 3.2.
As a node has its neighbors come and go, the subscription set changes over time. Thus, to update neighbors, the node advertises (using update_subset) its subscription set periodically and not immediately upon change. The immediate response to set changes may cause considerable traffic due to feedback loops. Since the direct subscription sets are always exchanged from the start and never change throughout the connection, the advertisement period can be set to a large value to reduce the overhead. Although feeds associated with large hop counts are more subject to change, they affect the overall performance to a less degree. To further reduce the overhead, the advertisement is incremental. That is, only the difference from the previous advertisement is transmitted. For the same reason as computing the returning subscription set, the advertised set must be computed for each neighbor excluding the neighbor in question. In the prototype implementation, this computation is done by a SQL query as we store the advertisements into a table of relational database. With proper indexing, the computation is efficient.
Although having more neighbors may bring more information or bring it faster, it also causes higher overhead in communication and processing. Thus, a node should restrict the number of neighbors within a sustainable level. Since a node may have more neighbor candidates than it can sustain, it needs to select ``good'' neighbors. As a primary selection metric, we use the degree of overlap in subscription sets.5
Initially, a node ![]() assigns a
weight
assigns a
weight ![]() of preference to each feed
of preference to each feed
![]() in its direct subscription
set. Periodically,
in its direct subscription
set. Periodically, ![]() assigns each
neighbor
assigns each
neighbor ![]() the degree of usefulness
the degree of usefulness
![]() :
:
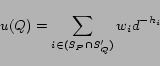
where ![]() denotes the
intersection of
denotes the
intersection of ![]() 's direct
subscription set and
's direct
subscription set and ![]() 's entire
subscription set;
's entire
subscription set; ![]() is a positive
constant; and
is a positive
constant; and ![]() is a hop count,
with respect to
is a hop count,
with respect to ![]() , for feed
, for feed
![]() . The purpose of a factor
. The purpose of a factor
![]() is to depreciate the
value of overlap in inverse proportion to the hop count because a
feed with a large hop count is more prone to disappear.
is to depreciate the
value of overlap in inverse proportion to the hop count because a
feed with a large hop count is more prone to disappear.
The assigned usefulness values are used to decide which neighbors to keep or drop. A node may need to drop some of current neighbors, for example, when it encounters shortage of network bandwidth or processing power or when a newly connecting node has a higher degree of usefulness.
If nodes do not fetch feeds frequently enough, they may obtain entries too late or even miss them. On the other hand, if fetching is too frequent, it may well waste the network bandwidth and overload the servers. Thus, it is important to balance the frequency of fetching that is appropriate for both subscribers and publishers. However, the coordination among nodes is difficult because it involves a large number of nodes that join and leave the system at a possibly high rate. Another challenge is that publishers give little explicit hint about the publishing rate or entry lifetime. Some hints may even be misleading. In our analysis, for example, some feeds fill the pubDate element with the fetching time. That is, although the actual contents remain unchanged, the element keeps changing each time a document is fetched.
We develop an adaptive algorithm that adjusts the fetching intervals without explicit coordination nor any hints from the servers. The intuition behind the algorithm is that if fetching is too frequent, a fetched document contains few new entries. On the other hand, if fetching is too infrequent, most of the entries are likely to be new. Thus, we keep track of the fraction of new entries in a fetched document and use this feedback to adapt the fetching interval.
We define a freshness rate of a fetched document as
the fraction of new entries contained in it. Each feed needs a
separate fetching interval because the publishing rate and
pattern vary greatly as shown in Figure 2. For each feed, a node assigns a value to
the target parameter ![]() for
freshness rate (
for
freshness rate (
![]() ). A value
). A value
![]() that is close to 1 means
that a node wishes new entries as early as possible. Two
parameters,
that is close to 1 means
that a node wishes new entries as early as possible. Two
parameters, ![]() and
and ![]() , denote the minimum
and maximum possible intervals, respectively. We use a simple
algorithm to adjust the fetching interval
, denote the minimum
and maximum possible intervals, respectively. We use a simple
algorithm to adjust the fetching interval ![]() of a feed. Each time a document is fetched, the
freshness rate
of a feed. Each time a document is fetched, the
freshness rate ![]() is computed as the
ratio of the new entries to the total entries in the document. If
is computed as the
ratio of the new entries to the total entries in the document. If
![]() , then
, then ![]() becomes halved or set to
becomes halved or set to ![]() , whichever is the greater. Or if
, whichever is the greater. Or if ![]() , then
, then ![]() becomes doubled or set to
becomes doubled or set to ![]() , whichever is the less.
, whichever is the less.
After a node fetches a document from a feed server, it filters and stores new entries from the document. These new entries are bundled and forwarded to the neighbors that subscribe to the corresponding feed. The entry bundle is assigned a globally unique identifier did. To assign did, we use the 20-byte SHA-1 digest [30] of a bundle. Although there is a very slight chance of collision, the cost of the collision is missing an entry bundle whose entries can be available later from other bundles. For the small cost, we can avoid coordination for a unique identifier. The entry bundle also attaches a path attribute, which keeps records of a growing list of forwarders. It is a receiver, rather than a sender, that puts the forwarder on the path list in order to reduce the chance of undesirable modification of the path. Thus, the sender, although it may alter the past path, cannot avoid appearing on the list in the absence of collusion. Even with collusion, at least one of such a forwarder must appear on the list.
Forwarding is triggered either from inside (the feed fetch scheduler in Figure 3) or from outside (the RPC server). If a node detects a loop (that is, its identifier is already included in the path attribute), the entry bundle is discarded. The bundle is forwarded to a neighbor only if the neighbor is interested in the bundle, which means that the neighbor's subscription set includes the bundle's originating URL and that the hop count for the matching feed is not greater than a system parameter max_subset_hops. Forwarded bundle may contain entries that have already been stored locally. Those old entries are removed from the bundle before it is further forwarded. Forwarding involves two remote calls that helps reduce the wasted traffic. First, using a check_did call, small enough to fit in one packet as shown in Section 4.4, the forwarding node checks whether a neighbor has already seen this entry bundle. For this purpose, nodes store the bundle identifiers did that have been seen recently (e.g., 1,000 latest dids in our prototype). While simple hashing is sufficient for searching a small amount of did cache, Bloom filter [13] may be used for a large cache [23]. Second, if the neighbor returns ``unseen,'' the entry bundle is forwarded via a put_entries call.
Due to resource constraints and the lack of centralized administration, nodes may manifest selfish behavior. For example, they may want to save the network bandwidth by only receiving the entry bundles without forwarding them. As another example, they may lie about the subscription set to become a preferred neighbor. Without proper incentive mechanisms and the detection of misbehavior, the system may become full of free riders and suffer from the ``tragedy of the commons'' [26] in the long run.
To ensure the mutual contribution, we measure the degree of
contribution from a neighbor. When a node ![]() receives a new entry from a neighbor
receives a new entry from a neighbor ![]() ,
, ![]() updates the
contribution metric
updates the
contribution metric ![]() (contribution from
(contribution from ![]() to
to ![]() ):
):
where ![]() is a system-wide
constant,
is a system-wide
constant, ![]() is the feed to which the
entry belongs,
is the feed to which the
entry belongs, ![]() is a weight of
preference for feed
is a weight of
preference for feed ![]() , and
, and
![]() is a hop count for feed
is a hop count for feed
![]() . That is, a node gives the
most credit when it receives an entry from a feed belonging to
the direct subscription set, the second most credit for an entry
from a feed of hop count 1, and so forth. Then, we define the
deficit of contribution
. That is, a node gives the
most credit when it receives an entry from a feed belonging to
the direct subscription set, the second most credit for an entry
from a feed of hop count 1, and so forth. Then, we define the
deficit of contribution ![]() of node
of node ![]() against node
against node
![]() as follows:
as follows:
Note that ![]() can maintain both
can maintain both
![]() and
and ![]() without relying on
without relying on ![]() . To prevent free riding, node
. To prevent free riding, node ![]() ensures that
ensures that ![]() does not exceed
a constant parameter
does not exceed
a constant parameter ![]() . The
effectiveness of this deficit bounding is shown in our previous
work [27]. Although it is
discussed in the context of bulk transfer, the same principles
apply to this case as well.
. The
effectiveness of this deficit bounding is shown in our previous
work [27]. Although it is
discussed in the context of bulk transfer, the same principles
apply to this case as well.
Since nodes store entries into their database, FeedEx forms a distributed archive system. If a node is to retrieve past entries that are no longer available from the feed servers, it can rely on other nodes that have those entries stored. The query_feed call serves the purpose of finding such nodes. It works similarly to the Gnutella's query and query_hit pair [17]. The requester specifies in the query what feed entries it is looking for in terms of feed titles, entry titles, published dates, and others. The query is propagated recursively rather than iteratively. That is, analogous to the recursive DNS query, once a neighbor receives a query, it propagates the query to its neighbors on behalf of the original requester. A possible drawback of recursive mode is excessive traffic caused by query flooding, which can be similarly controlled using the unique query identifier and the maximum number of hops. On the other hand, recursive queries have three advantages over iterative queries. First, the results can be aggregated along back to the original requester. Second, results can be cached, which may be useful for popular queries. Third, and most important, we can put this query relaying under the incentive mechanism discussed earlier. If iterative queries are used, nodes do not have incentive to answer the requests from non-neighbors because answering is unlikely to be rewarded.
The original requester ![]() selects a node
selects a node ![]() from the query
results for downloading the entries. Unlike the
query_feed call, because of potentially large traffic,
from the query
results for downloading the entries. Unlike the
query_feed call, because of potentially large traffic,
![]() and
and ![]() make a direct connection to retrieve entries rather than
communicating through a chain of neighbors. However,
make a direct connection to retrieve entries rather than
communicating through a chain of neighbors. However, ![]() has no incentive to upload
entries to
has no incentive to upload
entries to ![]() as it only costs
as it only costs
![]() its resources (i.e., network
bandwidth). Thus,
its resources (i.e., network
bandwidth). Thus, ![]() needs to find
either an altruistic
needs to find
either an altruistic ![]() that
unconditionally uploads to
that
unconditionally uploads to ![]() or a
circular dependency of requests. For example, if
or a
circular dependency of requests. For example, if ![]() also wants to download some other entries from
also wants to download some other entries from
![]() ,
, ![]() and
and ![]() form a circular dependency of
length 2. Or if there exists a node
form a circular dependency of
length 2. Or if there exists a node ![]() such that
such that ![]() wants to download from
wants to download from
![]() , and
, and ![]() from
from ![]() , they form a circular
dependency of length 3. If a circular dependency is found, they
are likely to agree to serving one in exchange of being served by
another. Anagnostakis and Greenwald [10] discuss how to detect
circular dependencies and perform n-way exchanges.
, they form a circular
dependency of length 3. If a circular dependency is found, they
are likely to agree to serving one in exchange of being served by
another. Anagnostakis and Greenwald [10] discuss how to detect
circular dependencies and perform n-way exchanges.
We evaluate FeedEx using various metrics in comparison with stand-alone applications. We also measure the overhead of FeedEx that is caused mainly by forwarding entry bundles.
For the proof of concept and the evaluation, we have implemented a prototype in Python [4]. As mentioned earlier, the protocol is implemented using XML-RPC for interoperability in the future as well as fast prototyping. The communication and the concurrency are due to Twisted, an event-driven networking framework [6]. The feed entries and the subscription sets are stored into tables of relational database. For this purpose, we use SQLite [5], a lightweight embedded relational database engine, which is accessed via Python's DB-API 2.0 [3]. Feed documents are parsed by Universal Feed Parser [32].
To measure the performance of news feed delivery systems, we define the following performance metrics:
In a sense, a missing entry is an entry with an infinite time lag. However, we treat two metrics separately for easy summarization because mean and variance are computable only without infinite numbers.
Measuring both time lag and missing entries requires the publishing logs from servers. Since such data are difficult to obtain, we instead run a reference node that monitors the servers' activity during the experiment. The reference node runs in stand-alone mode, fetching all monitored feeds every two minutes. Thus, in a failure-free environment, the maximum possible error in time lag is two minutes while entries that live shorter than two minutes long may even miss at the reference node. The effect of failures in the reference node is discussed in Section 4.4.
In stand-alone mode and, to a lesser degree, exchange mode, a node can reduce both time lag and missing entries by fetching documents more frequently. On the other hand, fetching document too often increases the communication cost as well as the server load. In exchange mode, the feed exchange involves controlled flooding of entry bundles, it is essential to keep the communication cost to a sustainable level. Thus, a good system should ``score high'' on these metrics in a balanced manner.
We used PlanetLab [2] for evaluation as it provides a platform for experimenting with machines distributed world-wide. Specifically, we ran our prototype on 189 PlanetLab machines for about 22 hours on a weekday. PlanetLab machines tended to shut down or reboot frequently not least because they were shared and overloaded by many users. As a result, during those 22 hours, 28 machines were shut down or rebooted, and we report the results from the remaining 161 machines that ran during the whole experiments. Nodes from the rebooted machines did not re-join the network. As a FeedEx node is able to detect neighbor failures and act accordingly (e.g., remove unreachable nodes and replenish new neighbors if there remain less than min_peers neighbors), we believe that the failed machines did not affect the results in any significant way.
The primary experimental factor is the fetching interval, which most affects all three performance metrics. We choose 6 intervals from 30 minutes up to 16 hours with each subsequent interval doubled. To factor out the effect of fetching interval, one FeedEx network consists of the nodes having the same interval. For the same reason, we do not apply adaptive fetching interval algorithm discussed in Section 3.3. We run 6 networks, each with a different interval, in parallel. That is, each machine runs 6 nodes of different intervals during the experiment. We strictly distinguish the two terms, machine and node, in this section. While different networks have no direct interaction with each other, we believe that they should not interfere much because they do not consume much processing power or network bandwidth. As the experiment runs about 22 hours long, we select 70 feeds, out of the same 245 feeds as shown in Section 2, that publish at least 5 entries per day. Out of these 70 feeds, each node puts 20 feeds independently and randomly into its direct subscription set. The direct subscription set does not change during the experiment.
For each fetching interval, two delivery modes, SLN (for stand-alone) and XCH (for exchange, representing FeedEx), are compared. The results of SLN are simulated from those of XCH. That is, no SLN nodes are actually run, but the results such as time lag and missing entries are computed from those of XCH by excluding the effects from neighbors. Note that since the feed exchange does not interfere with the document fetch, the simulated results are exactly the same as if they were run in stand-alone mode. Since the SLN and the corresponding XCH nodes have the same subscription sets (i.e., the factor, subscription set, is blocked), the results from the two modes are directly (i.e., pairwise) comparable.
Figure 4 shows how time lags change for different modes and fetching intervals. Classified by mode and interval, each group consists of 161 nodes. Each node collects some number of entries during the experiment. For each entry collected, we compute its time lag as defined in Section 4.2. Then, the average time lag of entries is computed for each node. The distributions of the node averages are shown in the figure. That is, each point in the figure is the average of the node averages while error bars indicate the 90% range of the node averages with the lower bars corresponding to the 5th percentile of node averages, and the upper bars to the 95th percentile.
The gap between SLN and XCH grows as the interval increases. The time lag of SLN is 7.0 times that of XCH for the 30-minute interval while the ratio jumps to 15.2 times for the 16-hour interval. Wide error bars in SLN indicate that it has much more variation in time lag than XCH and that the time lag variation of SLN increases as the fetching interval increases. As such an increase does not occur to XCH, it can be said that its performance is more stable.
For stand-alone mode, the expected time lag is half the fetching interval if entries are published uniformly. The expectations are close to the actual results for smaller intervals whereas they are greater for larger intervals. For example, the expected time lag of 8 hours for the 16-hour fetching interval is greater than the node average 5.7 hours. This discrepancy occurs because as the experiment period (22 hours) is not a multiple of the fetching interval (16 hours), some feeds fetched twice during the experiment lead to the time lag shorter than expected.
Figure 5 shows the percentage of entries that each group misses on average. To compute the missing entry rate, we compare, for each node, the set of entries stored in its database with that of entries stored in the reference node for the same subscription set. A group average is computed as an average of the node missing rates in the same group. As in the previous figure, each point indicates the average of the node averages for the group. As all the SLN miss groups include outliers with high missing rates (the reason is discussed shortly), for them, medians are indicated by the ``x'' marks. Error bars are drawn from the 5th percentile to the 95th percentile of the node missing rates. For each fetching interval, two ``miss'' bars grow above while two ``gain'' bars grow below, both starting from 0%. An entry that appears in the reference node but not in a XCH node accounts for XCH miss while an entry that appears in a XCH node but not in the reference node accounts for XCH gain (and similarly for SLN miss and SLN gain).
While miss rates increase along the increased fetching interval for both modes, XCH remains much lower rate than SLN. For the interval of 30 minutes, XCH nodes even manage to obtain entries that the reference node has missed (about 2% of the total number of entries collected by the reference node). Some of these entries may have lived less than two minutes, the fetching interval of the reference node, while other entries are missed because of the temporary failures in the reference node. As the failures were mostly timeouts and not temporally clustered, we believe that they were due to the servers, most likely overloaded servers, rather than the reference node. In any case, the failures in the reference node were so few and far between that they do not affect time lags and missing rates in any significant way.
There are 27 machines (hence all 162 nodes running on those machines) showing more than 80% SLN missing rate because most fetching attempts failed during the experiment. All those troubling nodes belong to the next-generation Internet. Specifically, 15 machines belong to the internet2.planet-lab.org domain (Internet2), 9 machines to canet4.nodes.planet-lab.org (CANARIE), and 3 machines to hpl.hp.com (HP Labs' Internet2 machines). At the same time, no machines that fetch documents properly belong to these domains except for some hpl.hp.com machines that are not part of Internet2. Thus, we deduce that the particular network as a whole had a problem in name resolution or routing during the experiment.6Still, since such machines were able to communicate with neighbors, the XCH miss rates on those machines were not affected as much. This event, although anecdotal, illustrates that FeedEx is more resilient to certain types of failures than stand-alone clients as it can obtain information not only from the feed servers but also from neighbors.
Figure 6 shows the rate of XML-RPC calls as a measure of communication cost of FeedEx. Out of 6 functions in Table 1, only check_did and put_entries are shown. The invocations of the other functions are so infrequent (less than a total of 50 times per node for 22 hours) that we do not include them in the figure. The check_did call, which is an HTTP request, is 344 bytes long, including the HTTP header, and the call return, which is an HTTP response, is about the same size. Since IPv4 specifies the maximum transfer unit to be at least 576 bytes (and 1,280 bytes for IPv6) except for few special cases, both the request and the response should fit in one IP packet. Thus, the overhead from the check_did is small. The rate of put_entries calls is as low as two calls per minute even when nodes fetch documents every 30 minutes. Since each call contains only 2.67 entries on average, shown in Table 3, we conclude that the communication cost is low.
Table 3 shows average bundle size by fetching interval. The bundle size is measured as the number of entries in an entry bundle. From the table, we see the average bundle size increase as fetching interval increases because it is likely to have more new entries available for the increased interval. Compared with the entry count distributions shown in Figure 2(b), entry bundles are smaller than actual feed documents because only new entries are included before forwarded.
Putting together the experimental results, we see that FeedEx has low communication overhead while achieving short time lag and low missing rates.
Web caching and content distribution network address the similar goals of relieving the server load and reducing the latency for clients to retrieve web pages. Various approaches have been researched, including recent peer-to-peer flavors [24,35]. FeedEx is different from web caching or content distribution networks in that there is no distinction between clients and proxies or content networks. That is, a peer in FeedEx plays dual roles as a consumer and as a cache. Such duality creates bidirectional service and gives an advantage to making it incentive-compatible.
FeedEx can be considered a gossip-based protocol in that a peer delivers the information it has learned to the neighbors. Gossip-based or epidemic protocols generally achieve robustness and scalability due to their distributed nature of dissemination [12,25,22]. Unlike some epidemic protocols, a FeedEx peer adheres to its neighbors, rather than changes them for each retransmission, because repeated transactions increase the chance to establish trust with the neighbors. With each pair of neighbors trying to be ``fair'' to each other, the system becomes robust to free riders.
The LOCKSS system [29] preserves digital contents by periodic voting. That is, nodes ensure the integrity of contents they own by comparing their fingerprints with those from neighbors, with possible human intervention in case of no definite voting result. Developed in the context of digital library, LOCKSS addresses copyright issue by requiring that a peer must own the contents before participating in voting. Thus, while it is not concerned with the propagation of new contents, it proposes a way of protecting integrity, which can apply to FeedEx.
Since peer-to-peer systems are prone to free riding, it is important to ensure the contribution of peers. The techniques to ensure the fairness and provide the incentives are developed in such various contexts as storage [20], bulk transfer [18,27], and data archiving [19]. As FeedEx also requires the cooperation of peers in propagating news feeds, it provides an incentive mechanism as shown in Section 3.5.
We make a case for collaborative exchange of news feeds by presenting FeedEx. By enabling nodes to exchange news feeds, it reduces the time lag and increases the entry coverage, helping the server scalability. We also emphasize that FeedEx is incentive-compatible so that cooperation is elicited. Without proper incentive mechanisms, the system becomes unsustainable due to the unwantedly induced free riders.
While we demonstrate the scalability and efficiency of FeedEx, it also has potential for other benefits such as anonymous subscription and collaborative filtering and recommendation. We plan to investigate further so as to augment FeedEx, which will help exchange information that grows increasingly unwieldy.