The Web Structure of E-Government -
Developing a Methodology for Quantitative Evaluation
Table 2. Sizes of audit offices' websites.
|
Country |
|
Yahoo! |
MSN |
Crawl |
doc |
|
dynamic |
|
CA |
139,000 |
13,800 |
30,913 |
12,730 |
2 |
725 |
596 |
|
CZ |
739 |
632 |
1,059 |
926 |
11 |
464 |
356 |
|
NZ |
558 |
1,230 |
1,115 |
836 |
1 |
352 |
0 |
|
UK |
32,200 |
6,980 |
10,325 |
4,027 |
78 |
1,411 |
144 |
|
US |
433,000 |
64,400 |
72,010 |
19,625 |
0 |
4,897 |
4,140 |
Table 2 enumerates the size of the crawl for each website, together with the estimated size of these sites as provided by Google, Yahoo! and MSN. It can be seen that Google's estimates are usually larger than MSN's, which are usually larger than Yahoo's. The source of this discrepancy is unknown but is probably connected to the size of the underlying index as well as the associated estimation technique.[5] Reliable figures for the actual size of e-government websites are difficult to obtain. We are unaware of any government figures pertaining to this. While the number of pages we crawled is on the low side, personal correspondence with contacts at the UK audit office suggests that (at least for the UK) our crawl was exhaustive.
4. EXPERIMENTAL RESULTS
We analyzed the five datasets (CA, CZ, NZ, UK, US) for the audit offices of Canada, the Czech Republic, New Zealand, the UK, the USA, respectively. We examined both the internal structure and the external connectivity. Section 4.1 summarizes the internal structure, which is related to navigability, and Section 4.2 summarizes external connectivity, which we interpret as a measure of an institution's nodality.
4.1 Internal Structure
The internal structure of a website can have a significant effect on its navigability when users only use the hyperlinks to navigate the site. For the five datasets, we examined (i) the size of the connected components, (ii) the average distance between randomly selected pairs of nodes and their distribution, and (iii) the distribution of links within a site. These three properties can clearly affect navigability and are discussed in detail below.
4.1.1 Connected Components
Major advantage of hyperlinked environments is that they permit the user to navigate from one document to another and reach related documents. Which documents a user can reach on a website is primarily determined by the links that are included in each Web page. The drawback of not having any links from a page becomes obvious when we realize that a substantial proportion of users arrive via a search engine and therefore cannot use the back button to continue exploring the site. This seems to be supported by preliminary results of our user studies that show users starting navigation not from the top page but from deep inside a site (after arriving from a search engine) and then performing non-trivial navigation.
Since a user can enter a site at an arbitrary location provided by a search engine, a very simple assumption is that a good website should provide the possibility to navigate to any other page on the site via its hyperlinks, in other words that there is a path between any two pages. In fact, Broder et al [27] established that for the Web a path exists only for 25% of all pairs of nodes, i.e. in 75% of cases it is no possible to navigate between two random pages.
Broder et al also described the structure of the Web graph. At the centre is a strongly connected component (SCC) with a path between every pair of nodes. The IN component contains nodes that have a path to nodes in the SCC but not from the SCC. In the same way, nodes that are only reachable via a path from nodes in SCC but not conversely form the OUT component.
Table 3. Percentage of pages in strongly connected (SCC) and in OUT component, for both entire site as well as "navigable" site (i.e. without .pdf, .doc and image files) and percentage of documents removed by this filtering operation.
|
|
Whole Site |
Filtered site |
%age of pdf+doc |
||
|
Country |
SCC |
OUT |
SCC |
OUT |
|
|
CA |
47 |
53 |
50 |
50 |
6 |
|
CZ |
35 |
65 |
71 |
29 |
51 |
|
NZ |
48 |
90 |
10 |
42 |
|
|
UK |
34 |
66 |
54 |
46 |
37 |
|
US |
52 |
48 |
70 |
30 |
25 |
In terms of a user navigating a site via its links, any node contained in the SCC is reachable from any other node in the SCC, although the path from one node to another may be long (see Section 4.1.2). In contrast, nodes in the OUT component "trap" a user since it is not possible to reach the nodes in the SCC from there. None of our datasets contain an IN component because the crawls started at the top page of the site that is part of the SCC. Table 3 summarizes the sizes of the SCC and OUT components in our datasets. Since our crawler does not parse .pdf and .doc files for hyperlinks, these documents are always in the OUT component. Thus, websites that provide many reports in pdf or doc format may appear to have a small SCC. We therefore repeated our analysis of the datasets without pdf, doc and image pages so that only navigable pages were included in the analysis.
We expect that sites with a large SCC will be easier to navigate than sites with a small strongly connected component because a user will not get trapped on a page that does not provide any link back to the central core of the site. Our analysis of the entire site reveals that approximately 50% of the US, NZ and CA sites are strongly connected compared with only 34% for the UK and CZ..
When only navigable content is considered, the SCC increases according to the number of pdf and Word documents on the site. New Zealand's ranking improves dramatically, with almost 90% of its site forming part of the SCC. The good performance of the US is especially noteworthy as it is the largest site of all.
There are several potential drawbacks to comparing these numbers. One open question is whether some documents that could not be parsed for links by our crawler (for example pdf and
Table 4. Navigability related properties of audit offices' websites.
|
Country |
Directed Diameter |
Average Directed Distance |
Median Directed Distance |
Normalized |
%age of Unreachable Pairs |
|||
|
Directed Diameter |
Average Directed Distance |
Median Distance |
Whole Site |
Navigable Content |
||||
|
CA |
12 |
4.7 |
5 |
2.92 |
1.14 |
1.22 |
53% |
50% |
|
CZ |
6 |
3.8 |
4 |
2.02 |
1.28 |
1.35 |
65% |
29% |
|
NZ |
8 |
3.3 |
3 |
2.74 |
1.13 |
1.03 |
48% |
10% |
|
UK |
22 |
5.4 |
5 |
6.10 |
1.50 |
1.39 |
66% |
46% |
|
US |
23 |
5 |
5 |
5.36 |
1.16 |
1.16 |
48% |
30% |
doc files) should be excluded because these are by definition in the OUT component. Another question is how strongly the size of a website influences the size of the SCC. For smaller sites, it is relatively easy to ensure a SCC of 100%, which may explain why CZ and NZ have such large SCC's after filtering. In contrast, this is much bigger challenge for a site like the audit office of the US with almost 20,000 pages. It seems clear that some normalization is needed to account for the size of a website. However, we are uncertain what form this normalization should take.
4.1.2 Distance
While the strongly connected component indicates what percentage of the site can be accessed by navigating the link structure, it does not reveal the number of clicks needed to move from one node to another. It is therefore interesting to measure the distance, in number of hyperlinks followed, in order to navigate between two randomly selected nodes of a website.
For the following calculations we establish the longest shortest path between a random node and all other nodes. This is the longest path a user would have to follow to get from one node to another.
A worst case measure of distance is the directed diameter of the site, which is defined as the longest of all calculated shortest paths. Perhaps a more useful measure is the average distance, which is defined as the average over all the longest shortest paths of each node. We also quote the median as this measure is less susceptible to extreme outliers. Table 4 enumerates these values for each dataset. The path length does not change significantly when calculated for the whole site and only for the navigable content. This is because unreachable paths are ignored in these calculations. However, obviously the percentage of unreachable pairs can shrink dramatically. It is interesting to observe that the percentage of unreachable pairs is almost equal to the percentage of the OUT component. This indicates that there are almost no paths between pairs of nodes in the OUT component, i.e. the number of reachable pairs consists almost entirely of nodes in SCC. This implies that once a user enters the OUT component, there is not only no way back, but there is very little chance of navigating to another page.
The average directed distances of the websites in our sample are much lower than the ones that Albert et al [35] calculated for the Internet, indicating that indeed there is a higher degree of connectivity within a managed website than for the Internet as a whole. However, as with the SCC, it is clear that a small website will tend to have a smaller diameter and an average distance than a large website. Therefore in order to meaningfully compare the values, they should be normalized. We decided to apply a normalization factor equal to the logarithm of the size of the website. This is based on the models of [35] and [39] where the diameter grows linearly with logarithm of the size of the network.
Looking at Table 4, we observe that the normalized average distance for CA and US is now comparable with NZ. The normalized average distance for CZ has worsened, while the UK's normalized average distance remains the worst.
The average distance does not reveal the distribution of longest shortest paths. Figure 1 shows the cumulative distribution of path lengths for each data set. The asymptotic value of each curve has been normalized to reflect the different percentage of nodes that are unreachable for each dataset.
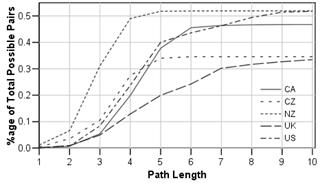
Figure 1. Cumulative sum of number of pairs of pages that have a path between them of less than a certain length. The x-axis represents the path length. The y-axis represents the fraction of all possible pairs of pages in the website that are connect by a path of length less than x.
Figure 1 shows that for those nodes that are reachable, the majority can be reached by six or less hyperlinks. While this value might seem rather small, Huberman et al [23-25] found that an average user follows only 4 links within a site. For a path length of four or less, we see that (i) for NZ, most of the reachable nodes are accessible, (ii) for CZ, over 50% of reachable nodes are accessible, (iii) for CA and US, somewhat over a third of reachable nodes are accessible, and (iv) for the UK, about a third of reachable nodes are accessible. This is particularly poor for the UK, since not only does it have the lowest accessibility for path lengths of four or less, but this is compounded by the fact that the percentage of reachable nodes is also the lowest.
4.1.3 Average Degree, Degree Distribution and Centralization
The previously discussed measures all rely on the existence of links between documents. One could argue that the more links exist, the more likely it is that there exists a path between two randomly selected pages. In order to measure how densely connected a network is we can measure the average degree of a node, that is the average number of links pointing to or from a node in a network. The higher the average degree, the more links exist in a network. As we use the average, this measure can be compared across networks of different size. In the same way, we can measure the indegree and outdegree distributions. However, as we analyze a website and its internal links only, every link going out from one page is received by another page within our graph. Therefore, the average indegree equals the average outdegree. In accordance with our earlier findings, the values in Table 5 underline that sites with a smaller normalized average distance tend to have more links.
Table 5. Average degree per page (sum of incoming and outgoing links), standard deviation from average and median of degree. Degree closeness centralization Cd(G) both for the whole site crawled and for navigable content only.
|
|
Degree |
Degree Closeness Centralization |
||
|
Country |
Average (std. dev.) |
Median |
Whole Site |
Navigable Content |
|
CA |
20.0 (105.0) |
3 |
0.341 |
0.341 |
|
CZ |
7.7 (18.5) |
2 |
0.427 |
0.507 |
|
NZ |
19.9 (47.6) |
14 |
0.607 |
0.789 |
|
UK |
13.3 (57.3) |
2 |
0.288 |
0.229 |
|
US |
23.8 (277.9) |
10 |
0.509 |
0.515 |
Many links do not necessarily guarantee a small average distance. Although the Web is a sparsely connected graph, it has been shown that it exhibits the characteristic of a small world [35][27][37], i.e. that most nodes can be reached from a random node by a comparatively small number of clicks. This is possible because links are unevenly distributed across nodes: there is a small number of nodes with a very high number of links while at the same time there is a large number of nodes with only a few links. The distribution of links follows a power law. For the Internet Albert et al [35] calculated a Zipf-exponent of 2.1 for the indegree distribution and of 2.72 for the outdegree distribution.
Figure 2 plots the distribution of indegree and outdegree for the websites in our sample. In the log-log plot, a straight line from the upper left corner to the lower right corner indicates a power law distribution. The distribution is stronger for larger sites, but even for the small sites, the indegree distribution roughly follows a power law. This is not the case for the outdegree distribution.
It is important to note that we only consider the distribution of links that are internal to the site, that is link source and link target are pages within the website of the audit office. In order to meaningful compare our distribution with distributions found for the Web as a whole, we would have to consider the external links as well.
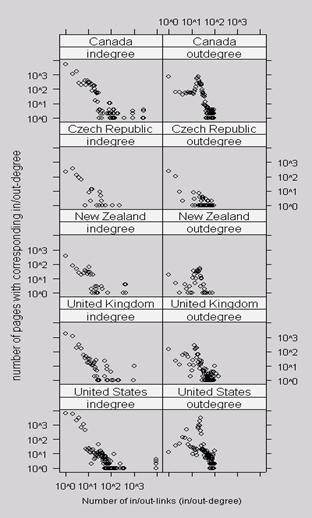
Figure 2. Distribution of in and outdegree for internal links in audit office websites as seen on a double logarithmic scale.
Although there is considerable variation, for inlinks, the five sites follow the general model of the Web, with a few nodes acting as internal authorities. While a few sites receive the majority of links, the websites differ in the amount to which they are centralized in their organization.
We use the closeness centralization coefficient denoted Cd(G) [17] to compare centralization of sites. Let G be an undirected graph with n nodes representing our dataset where V(G) and E(G) are sets of vertexes/pages and edges/links respectively. Let d(v,i) be the distance from node v to node i and Sn* a star-network of n nodes. The closeness centrality of a node v denoted cd(v) is defined as:
![]()
For the closeness centralization of a whole network we first calculate the overall variation in closeness centrality scores for all nodes, denoted vd(G):
Table 6. Inlink analysis of audit offices' websites.
|
|
Number of External Inlinks |
% of Pages Receiving Links |
% of Links to Top Page |
Number of Hosts |
% of Government Hosts |
Number of Different |
|||
|
Total |
Normalized |
Total |
Normalized |
Governments |
Audit Offices |
||||
|
CA |
647 |
32.4 |
0.9% |
47% |
212 |
10.6 |
25% |
15 |
11 |
|
CZ |
89 |
18.5 |
1% |
90% |
55 |
11.5 |
20% |
10 |
8 |
|
NZ |
39 |
12.2 |
0.1% |
100% |
34 |
10.6 |
44% |
10 |
7 |
|
UK |
2515 |
66.9 |
7.6% |
57% |
456 |
12.1 |
18% |
25 |
20 |
|
US |
8594 |
46.5 |
13.5% |
9% |
1905 |
10.3 |
12% |
7 |
2 |
![]()
This variation is then set into relation to the variation in a network of the same size with maximum centralization, that is a star-network:
![]()
From the definition the coefficient Cd takes values between 0 and 1 with one for a most centralized star-network.
The centralization measure can assist in the interpretation of our earlier measure of the datasets' diameter and average distance. This is because there are basically two ways to achieve a low distance between pages as well as a large strongly connected component - either a website can be built by simply linking all pages directly to a hub page, or by linking every page to different relevant pages on the site. While both methods will reduce the average distance between pages, the former results in a highly centralized network, while the latter creates a much more distributed network. We note that New Zealand is the most centralized network. However, further analysis is needed to determine the nature of this centralization.
4.2 External Connectivity
The previous sections analyzed the internal structure of the websites in our sample. It is hoped that analysis of the internal structure can provide a quantitative measure of the navigability of the websites. However, such an analysis does not relate to the "nodality" of political science, a concept that is akin to the hubness and authoritativeness of a site. To do so, requires broadening the analysis beyond the website itself, by establishing what are the links between the websites in our sample and other websites. Note that in the following analysis, inlinks and outlinks refer to links that come from or go to a node that is not part of the website under study.
4.2.1 Inlink Analysis
Following the common interpretation of a link as an endorsement, we look at number and type of links a website receives. The total number of inlinks, as reported in Table 6, can be interpreted as an indicator of a site's visibility or authority. We observe that the number of inlinks is very high for the UK and US.
However, the total number of inlinks does not reflect the fact that some countries have a very much smaller population than others. We therefore believe that it is appropriate to normalize the number of inlinks to a website by the estimated size of the internet population of the associated country. Consider the audit offices of large countries such as the United States, which have very high Internet penetration, and those audit offices that operate in smaller countries where less people have access to the Internet. Therefore we normalized the total number of incoming links to a website by the number, in millions, of Internet users in the country [34]. It is worth noting that this normalization is particular to governments online, in contrast to company websites for example. Although everyone can link to a national audit office's website, regardless of whether they are a citizen of that particular country, the very function of these institutions is primarily of interest to citizens of that country. This is supported by the finding that the majority of external inlinks originate from websites within the same country domain (see Figure 3). After normalization, we observe that the UK is ranked highest, i.e. is most authoritative, followed by the US and CA.
A site that offers a variety of useful information is more likely to receive links to many of its pages, not just to its home page. We therefore measure the proportion of pages on a website receiving external links. We argue that the higher this value is, the more useful information is likely to be offered by the site. Additionally, we determined the proportion of external links pointing to the home page. We believe that a low proportion of links to a home page is better, as this probably indicates that external sites are pointing to specific, useful information on the site rather than pointing to an audit office as an institution. By this measure, we observe that all pointers to NZ are generic, while only about 9% of inlinks to the US point to the home page.
The total number of inlinks does not reveal their distribution. For example, all inlinks might originate from a single external site. We believe it is better if the inlinks come from a variety of external sources. We report the number of different hosts pointing to each site. Again, we normalize this measure by millions of Internet users in country. Interestingly, although the US exhibits by far the largest number of hosts the normalized measure suggests that both the UK and even CZ are in fact linked to by more different websites than the North American audit offices.
As we are interested in e-government, the links between different national governments are of interest as well as the external links within the national government of the country. These are tabulated in Table 6 and graphically illustrated in Figure 3. We see in Figure 3 that the websites in the sample differ in the proportion of inlinks originating from other government domains. Still, it can clearly be seen that the majority of websites pointing to an audit office is non-governmental, indicating that the relevance of these institution extends beyond the institutionalized political system. In fact, as one would hope, business interest is strong - about a third of inlink sources are commercial. Furthermore, national audit offices really seem to be 'national'
Table 7. Outlink analysis of the audit offices' websites.
|
|
Number of External Outlinks |
Number of External Pages Linked to |
% of Pages Containing External Link |
Number of Hosts |
% of Government Hosts |
Number of Different |
|||
|
Total |
Normalized |
Total |
Normalized |
Governments |
Audit Offices |
||||
|
CA |
5516 |
0.43 |
267 |
39% |
98 |
0.0077 |
67% |
4 |
1 |
|
CZ |
21 |
0.02 |
8 |
1% |
8 |
0.0086 |
50% |
4 |
3 |
|
NZ |
526 |
0.63 |
96 |
50% |
79 |
0.0945 |
52% |
16 |
13 |
|
UK |
886 |
0.22 |
568 |
4% |
308 |
0.0765 |
44% |
48 |
43 |
|
US |
243 |
0.01 |
190 |
<1% |
123 |
0.0064 |
35% |
1 |
1 |
institutions - at least half of all websites pointing to an audit office are located in the same country. This adds relevance to the normalization by national Internet population that we applied earlier.
4.2.2 Outlink Analysis
The number of outlinks from a site is related to its 'hubness' [30]. In political science terms, hubness could be seen as a measure of the extent to which a organization 'collects' information from the outside world, by providing users with links to other sources of information.
Governments tend to perceive themselves as the ultimate authority on information. Therefore we assume it is less likely for government websites to function as hubs and to point to other sources of information, except perhaps to other governments.
Table 7 provides a comparison of outlink statistics for our five datasets. There are substantial differences in the number of external outlinks across sites. While it was felt appropriate to normalize the external inlinks of each site by the respective sizes of their internet populations, such normalization does not seem appropriate for outlinks as the creation of an outlink is not performed by individual users. Instead, we propose to normalize by the size of each site, to provide the number of outlinks per page. Surprisingly, after normalization, we see that NZ exhibits the highest number of outlinks per page (63%). This may be misleading, since it is quite common to link to generic sites such as "Adobe Acrobat Reader". This is confirmed when we consider column 4 of Table 7, the number of unique external pages pointed to. Here, we see that while the total number of outlinks for NZ is 526, the total number of different outlink targets is only 96.
A similar change can be observed for Canada if one considers the number of hosts pointed to instead the total number of outlinks. Although Canada links heavily outside, it does not point to many different websites. In fact, a closer examination of Canada's outlinks revealed that the majority of these links have one single target - the website of the Canadian government. In contrast, the National Audit Office of the United Kingdom is heavily interlinked with foreign governments, unlike Canada and the United States. While a considerable share of the outlinks point to government websites, audit office link also to other sources.
We can distinguish the websites linked to by the audit office's according to their top-level domain. The North American countries are primarily inward looking with few links to websites in foreign countries. Here clearly the UK takes the lead. Another interesting result is that most audit offices are obviously not afraid of linking to commercial sites.
5. DISCUSSION
We have performed a preliminary comparative study of government audit offices on Canada, the Czech Republic, New Zealand, the UK and the USA. This study was based on an examination of the structural characteristics of these websites. Website properties based on usage statistics were not considered due to the difficulty of acquiring such data. Despite this lack of usage information, it appears that structural information is informative as to the quality of the websites.
The structural characteristics examined form two categories, internal structure that is indicative of the navigability of a site, and external structure that is indicative of the nodality (hubness and authority) of a site. A further subdivision may be made with respect to nodality. We use the distinction between hubs and authorities to distinguish between nodality in terms of collecting information (hubness) and nodality in terms of disseminating information (authoritativeness).
A variety of properties were examined - diameter of the site, average distance between nodes, largest strongly connected component, and the number of external inlinks and outlinks. These properties have been well studied within computer science, the Web and the social sciences. Nevertheless, our comparative analysis revealed some shortcomings of these properties, due to the diversity of the websites and countries under investigation. It is clear that in many cases, these properties need to be normalized to account for the size of a website and/or the size of the national Web. In the latter case, this was approximated by normalizing for the internet penetration in each country. Other normalizations are possible and future work will consider such issues as the variation in gross domestic product of each nation. Furthermore, a simple count of the number of external inlinks and outlinks can be misleading. At the very least, it is necessary to adjust the results to only consider unique source or target pages/hosts. The US and Canada emerge as the most internally connected and navigable sites in relation to their size, with the UK scoring the lowest on this dimension. The smallest sites, the Czech Republic and New Zealand, score highest in absolute terms, having the largest strongly connected component, the lowest average and median directed diameter, the lowest percentage of unreachable pairs and the highest degree of centralization (taking only navigable content into account, as we believe should be the case). For the larger sites, the US and Canada score generally better for navigability than the UK across the same measures, in spite of being far larger than the UK site. When we take size into account (by normalizing for the number of pages), the UK's position as a laggard becomes most marked, with the highest directed diameter, directed distance and percentage of unreachable pairs of all the sites, including the Czech Republic and New Zealand. To summarize the results with respect to navigability, internal structural characteristics reveal that the US and CA rank highly with regard to these navigability measures, while the UK is seen to be lagging.
In contrast, with respect to nodality, the UK and the US emerged as the clear leaders. In terms of incoming nodality (or authority), the UK scored most highly with respect to the normalized number of external inlinks, and was beaten only by the US with respect to the proportion of pages receiving links. These two were considerably more authoritative in this sense than Canada, which in turn eclipsed the two smaller sites. The US and the UK received links from a greater number of hosts than the other sites, with a smaller proportion of governmental hosts. The UK had far more links from different governments (probably reflecting the NAO's hosting of a site for an international association of audit offices); the US was lowest here with only 7, perhaps highlighting the somewhat insular nature of US public administration. When it comes to outgoing nodality (hubness), which is a measure of the 'willingness' of a site to link to information in other domains, we found considerable variation, with Canada having by far the greatest number of outlinks. New Zealand and then the UK have a significantly higher number of external outlinks when normalized by the size of the website. Although Canada linked heavily outside, the majority of links are within the Canadian government and it was the UK that emerged as linking to the highest number of hosts (over twice as many as its nearest rival, the US), the highest number of different governments (four times as many as its nearest rival, New Zealand) and by far the highest number of audit offices. The US and the UK appear to be the most 'authoritative' sites, i.e. the most effective disseminators of information. The UK and New Zealand seemed to be the most effective collectors of information (hubness) from the outside world. Overall, therefore, we might deem the UK the most 'nodal' of our audit offices online.
Our comparative study affirms previous qualitative studies, for example in their findings of the superiority of Northern American sites. However, we have done so by using quantitative measures instead of qualitative assessment. Our study has also yielded novel results. By distinguishing between internal and external connectivity, we have broadened our analysis beyond the website itself and have established a first quantification of nodality and therefore how an institution's website relates to its surroundings.
We believe these metrics offer the possibility to provide a more sophisticated and meaningful evaluation of the web structures of government than any of the existing studies outlined in the first section. When applied at the 'whole government' or policy sector level, they offer the possibility to rigorously assess the accessibility of government information along two key dimensions: navigability and nodality. This study represents, as far as we know, the first attempts to quantitatively measure either of these dimensions and the first attempt to apply these techniques systematically to the web structure of government. Because these measures are non-obtrusive, data can be collected relatively cheaply (more so, at least, than any user metrics) without transgressing ethical boundaries or seeking multiple permissions although a web crawler has to be configured in a way that puts no irresponsible pressure onto the bandwidth and availability of information providers [40]. Our aim now is to move beyond the relatively modest research subject of audit offices to larger departments (such as finance ministries or foreign offices) and then to governmental domains.
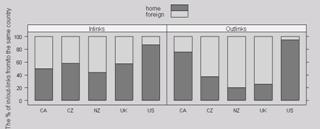
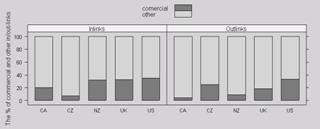
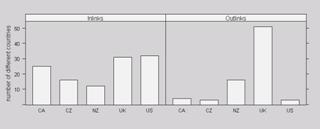
Figure 3. A comparison of the audit offices according to (i) percentage of hosts from the home country, (ii) percentage of commercial hosts and (iii) number of different countries appearing in the list of hosts.
The next stage for future research will be to compare our structural measures against results of our lab based user study that we just finished and also against user metrics, collected via mystery shopping exercises, opinion surveys and usage statistics, in order to verify that sites or communities which emerge as 'healthy' in terms of navigability and nodality also score well when experienced by users.
ACKNOWLEDGMENTS
Thanks to the National Audit Office of the UK and the Web manager of the School of Public Policy, Aaron Crompton, for providing us with data to verify our crawls. We also want to express our gratitude to Vladimir Batagelj and Andrej Mrvar for developing Pajek, their excellent program for large scale network analysis. We would like to thank the Cambridge-MIT Institute for financial support. This work was supported in part by the National programme of research (Information society project 1ET100300419).
REFERENCES
[1] Accenture ' Leadership in Customer Service: New Expectations, New Experiences' , The Government Executive Series, April 2005
[3] A. Caldas 'On the Web Structure and Digital Knowledge Bases', 2004.
[4] Cap Gemini, 'Online Availability of Public Services: How is EuropeProgressing? Web-based survey on electronic public services, Report of the fifth measurement', European Commission Directorate General for Information Society and Media, 2004.
[6] C. C. Demchak, C. Friis, T.M. La Porte, 'Webbing governance: National differences in constructing the public face', in G. D. Garson (ed.) Handbook of Public Information Systems (New York: Marcel Dekker Publishers), 2000.
[7] N. Eiron,, K. S. Mccurley 'Locality, Hierarchy, and Bidirectionality in the Web', Workshop on Web Algorithms and Models, 2003.
[8] W. H. Dutton, C. di Genarro, A. Millwood, 'The Internet in Britain: The Oxford Internet Survey (OxIS), Hargrave, May 2005,
[9] I. Graafland-Essers, E. Ettedgui, 'Benchmarking E-Government in Europeand the U.S', Rand Research, 2003.
[11] C. Hood, 'The Tools of Government', Macmillan, 1983.
[12] C. Hood, H. Margetts, 'The Tools of Government in the Digital Age' (London: Palgrave), 2006.
[15] United Nations, 'World Public Sector Report 2003: E-Government at the Crossroad',s Department of Economics and Social Affairs (New York: United Nations), 2003.
[16] D. West, 'Digital Government: Technology and Public Sector Performance', (Princeton University Press), 2005.
[17] W. Nooy, A. Mrvar, V. Batagelj, 'Exploratory Social Network Analysis with Pajek', Cambridge University Press, 2005.
[20] L. Page, S. Brin, R. Motwani, T. Winograd 'The PageRank Citation Ranking: Bringing Order to the Web', Tech. Rep., Stanford Digital Library Technologies Project, 1998.
[22] X. He, H. Zha, C. Ding, H. Simon 'Web document clustering using hyperlink structures', CS&DA 41:19-45, 2001.
[23] B. A. Huberman,, P. Pirolli, J. E. Pitkow, R. M. Lukose, 'Strong Regularities in World Wide Web Surfing'. Science, 280, pp 95-97, 1998.
[24] L. Adamic, B. Huberman 'The Web's hidden order', Communications of the ACM, vol. 44, no. 9, 2001.
[25] B. Huberman, L. Adamic, 'Growth dynamics of the World-Wide Web', Nature, vol. 399 pp. 130, 1999.
[28] S. Chakrabarti, B. Dom, D. Gibson, J. Kleinberg, P. Raghavan, S. Rajagopalan, 'Automatic resource list compilation by analyzing hyperlink structure and associated text', in Proceedings of the 7th International World Wide Web Conference, 1998.
[29] S. Chakrabarti, B. E. Dom, S. R. Kumar, P. Raghavan, S. Rajagopalan, A. Tomkins, D. Gibson, J. Kleinberg, 'Mining the Web's Link Structure', Computer, vol. 32, no. 8, pp. 60-67, 1999.
[30] D. Gibson, J. M. Kleinberg, P. Raghavan, 'Inferring Web Communities from Link Topology', in UK Conference on Hypertext, pp. 225-234, 1998.
[31] J. M. Kleinberg, 'Authoritative sources in a hyperlinked environment', Journal of the ACM, vol. 46, no.5, 604-632, 1999.
[33] G. W. Flake, S. Lawrence, C. L. Giles, F. Coetzee, 'Self-Organization of the Web and Identification of Communities', IEEE Computer, vol. 35 no. 3 pp. 66-71, 2002.
[38] P. Ingversen, 'The calculation of Web impact factors', Journal of Documentation, 4(2), pp 236-243, 1998.
[39] L. Lu. 'The Diameter of Random Massive Graphs',in Proceedings of the Twelfth Annual ACM-SIAM Symposium on Discrete Algorithms,2000.
[40] M. Thelwall, D. Stuart, ' Web crawling ethics revisited: Cost, privacy and denial of service', to appear in Journal of the American Society for Information Science and Technology.
[1] For example the following institutions at University College London (http:/www.ucl.ac.uk) use different form of URL: http:/www.cs.ucl.ac.uk/ (Department of Computer Science) http:/www.ucl.ac.uk/spp/ (School of Public Policy)
[2] http:/lucene.apache.org/nutch/
[3] The non default parameters being a 5s delay between requests to the same host, and 10,000 attempts to retrieve pages that failed with a soft error. Our crawler followed http links to files, skipping unparseable content.
[4]http:/blog.searchenginewatch.com/blog/050128-134939
[5] http:/blog.searchenginewatch.com/blog/050128-134939