|
|
|
|
|
|
Tables are common in HTML documents |
|
Table understanding important |
|
Knowledge management |
|
Web mining |
|
Summarization and mobile access |
|
<table></table> tags cannot be
trusted |
|
Table detection |
|
Is a given <table> element a genuine
table? |
|
|
|
|
|
|
|
|
|
|
|
Genuine table |
|
A document entity where a two dimensional grid
structure is semantically significant in conveying the logical relations
among the cells. |
|
|
|
Non-genuine table |
|
A <table> element that does not represent
a genuine table |
|
|
|
|
|
|
|
|
Previous Work |
|
Mostly based on heuristics |
|
Limited testing |
|
Tens to hundreds of samples |
|
Domain specific (airlines, news, etc.) |
|
|
|
Our approach |
|
Machine learning based, trainable |
|
Large scale testing (over 10,000 samples) |
|
|
|
|
|
|
Novel features capturing both layout and content |
|
|
|
Collection/labeling of a large, diverse database |
|
|
|
Testing of two popular classification schemes |
|
|
|
|
|
|
|
|
HTML parsing to obtain the document tree |
|
Java swing parser, W3C HTML 3.2 DTD |
|
Extract leaf <table> elements |
|
Pseudo-rendering to obtain accurate row/column
counts |
|
Only considering <tr>, <td>,
<th> not sufficient |
|
Other tags: <rowspan>, <colspan>,
<br> |
|
|
|
|
|
|
|
|
|
Layout features |
|
|
|
Content type features |
|
|
|
Text content feature |
|
|
|
Total of 16 |
|
|
|
|
|
Average # columns and standard deviation |
|
|
|
Average # rows and standard deviation |
|
|
|
Average overall cell length |
|
|
|
Cumulative Length Consistency (CLC) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Incorporate more cases in pseudo-rendering |
|
(including non table elements?) |
|
|
|
Deeper language analysis (for both detection and
interpretation) |
|
|
|
Interpretation (title, headings, etc.) |
|
|
|
|
|
{kind=link}
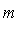{kind=link}
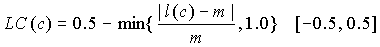{kind=link}
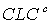{kind=link}
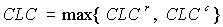{kind=link}
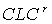{kind=link}
{kind=link}
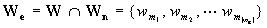{kind=link}
{kind=link}
{kind=link}