| Soumen Chakrabarti1 | Mukul M. Joshi | Kunal Punera | David M. Pennock | |||
| IIT Bombay | IIT Bombay | IIT Bombay | NEC Research Institute |
Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
Categories and subject descriptors:
H.5.4 [Information interfaces and presentation]:
Hypertext/hypermedia;
H.5.3 [Information interfaces and presentation]:
Group and Organization Interfaces, Theory and models;
H.1.0 [Information systems]: Models and principles.
General terms: Measurements, experimentation.
Keywords: Social network analysis, Web bibliometry.
(Note: The HTML version of this paper is best viewed using Microsoft Internet Explorer. To view the HTML version using Netscape, add the following line to your ~/.Xdefaults or ~/.Xresources file:
Netscape*documentFonts.charset*adobe-fontspecific: iso-8859-1
For printing use the PDF version, as browsers may not print the mathematics properly.)
The Web is an actively evolving social network which brings together myriad topics into a uniform hypertextual medium. Superficially, it looks like a giant graph where nodes are hypertext pages and edges are hyperlinks. A closer look reveals fascinating detail: the textual matter, tag structure, site identity and organization, and (link) affinity to prominent topic directories such as Yahoo! and the Open Directory (DMoz), to name just a few. The best strategies for browsing, searching and foraging for Web information are clearly predicated on our understanding of the social processes which shape the Web. Naturally, the structure and evolution of the Web has been under intensive measurements and modeling in recent years.
With a few notable exceptions, most studies conducted on the Web have focused on its graph-theoretic aspects.
Barabási and Albert [3] proposed a local model for social network evolution based on preferential attachment: nodes with large degree are proportionately more likely to become incident to new links. They applied it to the Web graph, and the model predicted the power-law degree distribution quite accurately, except for underestimating the density of low-degree nodes. This discrepancy was later removed by Pennock et al. [30] by using a linear combination of preferential and random attachment.
Random graph models materialize edges independently with a fixed probability. If the Web were a random graph, large densely connected components and bipartite cores would be extremely unlikely. The Web is not random, and such subgraphs abound on the Web. A small bipartite core is often an indicator of an emerging topic. Kumar et al. [21] mine tens of thousands of such bipartite cores and empirically observed that a large fraction are in fact topically coherent, but the definition of a `topic' was left informal.
Dense bipartite subgraphs are an important indicator of community formation, but they may not be the only one. Flake et al. [17] propose a general definition of a community as a subgraph whose internal link density exceeds the density of connection to nodes outside it by some margin. They use this definition to drive a crawler, starting from exemplary members of a community, and verify that a coherent community graph is collected.
Bröder et al. [7] exposed the large-scale structure of the Web graph as having a central, strongly connected core (SCC); a subgraph with directed paths leading into the SCC, a component leading away from the SCC, and relatively isolated tendrils attached to one of the three large subgraphs. These four regions were each about a fourth the size of the Web, which led the authors to call this the ``bow-tie'' model of the Web. They also measured interesting properties like the average path lengths between connected nodes and the distribution of in- and out-degree. Follow-up work by Dill et al. [15] showed that subgraphs selected from the Web as per specific criteria (domain restriction, occurrence of keyword, etc.) also appear to often be bow-tie-like, although the ratio of component sizes vary somewhat. Content-based criteria used keywords, not topics, and the interaction between topics, or the radius of topical clusters, were not addressed.
A few studies have concentrated on textual content.
Davison pioneered a study [13] over about 100,000 pages sampled from the repository of a research search engine called DISCOWEB. He collected the following kinds of pairs of Web pages:
A single starting page u0 may be a noisy indicator of semantic similarity with pages later on in the walk, because it may have a limited vocabulary. The pages on a short walk (u0,u1,�,ui) may all be clearly about a given broad topic c, but each page may use a negligible fraction of the vocabulary of c. Thus, it is possible that u0·ui is small, whereas �cPr(c)Pr(u0|c)Pr(ui|c) (the probability that they are both relevant to the same topic, see §2.2) is quite large.
It is also more informative to estimate the distance at which topical memory is lost, rather than only measure the rate of relevance decay for some fixed starting topics, because there is no reference for how dissimilar u0 and ui need to be before we agree that memory of u0 has been lost.
We also go beyond the studies of Davison and Menczer in that we analyze the relation between different topics rather than only model similarity between pages in a small neighborhood.
We bring together two existing experimental techniques to launch a thorough study of topic-based properties of the Web: the ability to classify a Web page into predefined topics using a high-speed automatic classifier, and the ability to draw near-uniform samples from the Web graph using random walks. We use a 482-class topic taxonomy from DMoz (http://dmoz.org/) and a sampling and classifying technique that we will describe in §2. By obtaining evidence that our samples are faithful, we avoid processing large Web crawls, although even our sampling experiments have fetched almost 16 million pages.
Our study reveals the following properties about communities of broad topics in the Web graph.
Convergence of topic distribution on undirected random walks: Algorithms for sampling Web pages uar have been evaluated on structural properties such as degree distributions [2,32]. Extending these techniques, we design a certain undirected random walk (i.e., assuming hyperlinks are bidirectional) to estimate the distribution of Web pages w.r.t. the Dmoz topics (§3). We start from drastically different topics, and as we strike out longer and longer random paths, the topic distribution of pages collected from these paths start to converge (§3.1). This gives us strong circumstantial evidence that the Web has a well-defined background topic distribution, even though we cannot directly measure the fidelity of our distribution w.r.t. the `whole' Web.
Degree distribution restricted to topics: Once we have some confidence in collecting samples which are faithful to the Web's topic distribution, we can measure the degree distribution of pages belonging to each topic-based community. We observe (§3.4) that the degree distribution for many topics follow the power law, just like the global distribution reported by Bröder and others. We offer a heuristic explanation for this observation.
How topic-biased are breadth-first crawls? Several production crawlers follow an approximate breadth-first strategy. A breadth-first crawler was used to build the Connectivity Server [5,7] at Alta Vista. Najork and Weiner [27] report that a breadth-first crawl visits pages with high PageRank early, a valuable property for a search engine. A crawl of over 80 million pages at the NEC Research Institute broadly follows a breadth-first policy. However, can we be sure that a breadth-first crawl is faithful to the Web's topic distribution? We observe that any bias in the seed URLs persists up to a few links away, but the fidelity does get slowly better (§3.2).
Representation of topics in Web directories: Although we use Web directories to derive our system of topics, they need not have fair representation of topics on the Web. By studying the difference between the directory and background distributions (§3.3), we can spot Web topics and communities that have an unexpectedly low (or high) representation on the directory, and try to understand why.
Topic convergence on directed walks: We also study (§4) page samples collected from ordinary random walks that only follow hyperlinks in the forward direction [18]. We discover that these ordinary walks do not lose the starting topic memory as quickly as undirected walks, and they do not approach the background distribution either. Different communities lose the topic memory at different rates. These phenomena give us valuable insight into the success of focused crawlers [11,14,31] and the effect of topical clusters on Google's PageRank algorithm [6,28].
Link-based vs. content-based Web communities: We extend the above measurements to construct a topic citation matrix in which entry (i,j) represents the probability that a page about topic i cites a page about topic j (§5). The topic citation matrix has many uses that we will discuss later. Typically, if the topics are chosen well and if there is topical clustering on the Web, we expect to see heavy diagonals in the matrix and small off-diagonal probabilities. Prominent off-diagonal entries signify human judgment that two topics adjudged different by the taxonomy builders are found to have connections endorsed by Web content writers. Such observations may guide the taxonomy builders to improve the structure of their taxonomies.
A fixed taxonomy with coarse-grained topics has no hope of capturing all possible information needs of Web users, and new topics emerge on the Web all the time. Another concern is the potentially low accuracy of a state-of-the-art text classifier on even such broad topics. Despite these limitations, we believe that data collected using a fixed classification system and an imperfect classifier can still be valuable.
We argue that new topics and communities, while numerous, are almost always extensions and specializations of existing broad classes. Topics at and near the top levels of Yahoo! and Dmoz change very rarely, if at all.
As long as the automatic classifier gives us a significant boost in accuracy beyond random choice, we need not be overly concerned about the absolute accuracy (although larger accuracy is obviously better). By using a held-out data set, we can estimate which topics are frequently confused by our classifier, and suitably discount such errors when interpreting collected data.
Recent hypertext classification algorithms [8] may reduce the error by using hyperlink features, but this may produce misleading numbers: first the classifier uses link structure to estimate classes, then we correlate the class with link structure-the results are likely to show artificial coupling between text and link features.
A classifier also acts as a dimensionality reduction device and makes the collected data more dense. Since we use a few hundred classes but Web documents collectively use millions of term features, estimating class distributions is easier than estimating term distributions.
Sampling approximately uniformly at random (uar) is a key enabling technology that we use in this work, and we review sampling techniques in some detail here. The Web graph is practically infinite, because URLs can embed CGI queries and servers can map static-looking URLs to dynamic content. We can discuss sample quality only in the context of a finite, static graph. A small set of strict rules often suffices to make the Web graph effectively finite, even if unspeakably large. E.g.,
PageRank-based random walk: Henzinger et al. [18] proposed an early approach to this problem using PageRank [6,28]. The PageRank prestige p(u) of a node u in G is defined as the relative rate of returning to node u during an infinite random walk on G, where each step from a node v is taken as follows: with probability d (0 < d < 1) we jump to a random node in G, and with probability 1-d we follow an outlink from v uar. The steady state distribution p of this walk is called the PageRank. Henzinger et al. first performed a PageRank-style walk for some steps, and then corrected the bias by sampling the visited nodes with probability inversely proportion to their p scores. Rusmevichientong et al. [32] have enhanced this algorithm and proved that uniform sampling is achieved asymptotically.
The Bar-Yossef random walk: An alternative to the biased walk followed by the correction is to modify the graph so that the walk itself becomes unbiased. Bar-Yossef et al. [2] achieve this by turning the Web graph into an undirected, regular2 graph, for which the PageRank vector is known to have identical values for all nodes. The links are made undirected by using the link:... backlink query facility given by search engines. This strategy parasites on other people having crawled large sections of the Web to find the backlinks, and is not guaranteed to find all backlinks. This will introduce some initial bias in the sample towards pages close to the starting point of the walk. Unfortunately, there is no easy way around this bias until and unless hyperlinks become bidirectional entities on the Web [9]. However we can assess the quality of the samples through other means. The graph is made regular by adding sufficient numbers of self-loops at each node; see §3.
We use a variant of Bar-Yossef's walk, with random jumps thrown in with a small probability, which in our empirical experience gave us faster convergence. We call this the SAMPLING walk, whereas the PageRank walk with d = 0 is called the WANDER walk.
We downloaded from the Open Directory (http://dmoz.org) an RDF file with over 271,954 topics arranged in a tree hierarchy with depth at least 6, containing a total of about 1,697,266 sample URLs. Since the set of topics was very large and many topics had scarce training data, we pruned the Dmoz tree to a manageable frontier as described in §3.1 of our companion paper in these proceedings [10]. The pruned taxonomy had 482 leaf nodes and a total of 144,859 sample URLs. Out of these we could successfully fetch about 120,000 URLs.
For the classifier we used the public domain BOW toolkit and the Rainbow naive Bayes (NB) classifier created by McCallum and others [23]. Bow and Rainbow are very fast C implementations which let us classify pages in real time as they were being crawled. Rainbow's naive Bayes learner is given a set of training documents, each labeled with one of a finite set of classes/topics. A document d is modeled as a multiset or bag of words, {�t, n(d,t)�} where t is a term/word/token/feature. The prior probability Pr(c) is the fraction of training documents labeled with class c. The NB model is parameterized by a set of numbers qc,t which is roughly the rate of occurrence of term t in class c, more exactly, (1+�d � Dcn(d,t))/(|T|+�d,tn(d,t)), where Dc is the set of documents labeled with c and T is the entire vocabulary. The NB learner assumes independence between features, and estimates
| ||||||||||||||||
In this section we seek to characterize and estimate the distribution of topics on the Web, i.e., the fractions of Web pages relevant to a set of given topics which we assume to cover all Web content.
We will use only SAMPLING walks here; WANDER walks will be used in §4. Bar-Yossef et al.'s random walk has a few limitations. Apart from the usual bias towards high indegree node and nodes close to the starting point, it may find convergence elusive in practice if snared in densely linked clusters with a sparse egress. One example of such a graph is the ``lollipop graph'' which is a completely-connected k-clique with a `stick' of length k dangling from one node belonging to the clique. It is easy to see that a walk starting on the stick is doomed to enter the clique with high probability, whereas getting out from the clique to the stick will take a long, long time [26].
Unfortunately, lollipops and near-lollipops are not hard to find on the Web: http://www.amazon.com/, http://www.stadions.dk/ and http://www.chipcenter.com/ are some prominent examples. Hence we add a PageRank-style random jump parameter to the original Bar-Yossef algorithm [2], set to 0.01-0.05 throughout our experiments, i.e., with this probability at every step, we jump uar to a node visited earlier in the SAMPLING walk. Berg confirms [4] that this improves the stability and convergence of the SAMPLING walks.
Bar-Yossef et al. showed that the samples collected by a SAMPLING walk have degree distributions that converge quickly (within a few hundred distinct page fetches) to the ``global'' degree distribution (obtained from the Internet Archive). It would be interesting to see if and how convergence properties generalize to other page attributes, such as topics.
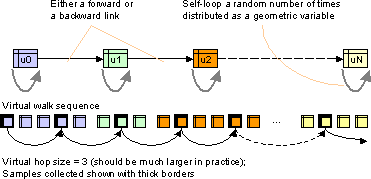
Our basic experimental setup starts with two URLs u0 and v0, generally about very different topics. We now execute the following steps:
In our first experiment, we pick some 20 topics from our 482-topic Dmoz collection and one representative URL from each topic as a starting point for a SAMPLING walk. Each page visited in a walk is classified using Rainbow and its class histogram as well as in- and out-neighbors stored in a relational database. Then we consider pairs of walks, turn them into virtual walks and sample at a given stride on the fly.
Suppose we have thus collected two sets of documents D1 and D2. Each document d has a class probability vector p(d) = (Pr(c|d)"c), where �cPr(c|d) = 1. E.g., if we have only two topics /Arts and /Sports, a document may be represented by the vector (0.9,0.1). The topic distribution of D1 (likewise, D2) is simply the average.
| ||||||||||
We characterize the difference between p(D1) and p(D2) as the L1 difference between the two vectors, �c|pc(D1)-pc(D2)|. This difference ranges between 0 and 2 for any two probability vectors over the classes. We had to avoid the use of the more well-known Kullback-Leibler (KL) divergence
| ||||||||||
Bar-Yossef et al. found that an undirected random walk touching about 300 physically distinct pages was adequate to collect a URL sufficiently unbiased to yield a good degree distribution estimate. We use this number as a guideline to set the virtual hop size so that at least this number of physical pages will be skipped from one sample to the next.
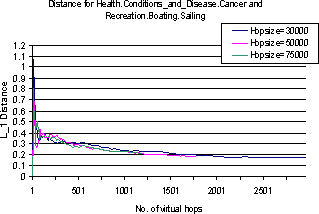
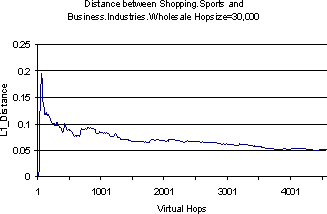
Figure 2 shows pairwise class distribution differences starting from a few pairs of very dissimilar topics; the x-axis plots the number of samples drawn from the respective virtual walks, and different curves are plotted for different virtual hop sizes. We never seem to get complete convergence (distance zero) but the distance does rapidly reduce from a high of over 1 to a low of about 0.19 within 1000-1500 virtual hops, which typically includes about 300-400 distinct physical pages. A larger virtual stride size leads to a slightly faster rate of convergence, but curiously, all pairs converge within the same ballpark number of virtual strides.
Convergence of this nature is a stronger property than just a decay in the similarity between u0 and ui on a walk (u0,u1,�) as i increases. It indicates that there is a well-defined background topic distribution and we are being able to approach it with suitably long SAMPLING walks.
 |
 |
|
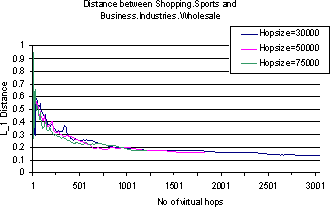
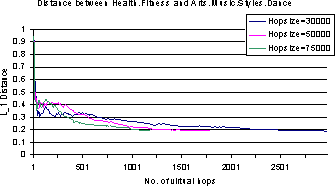
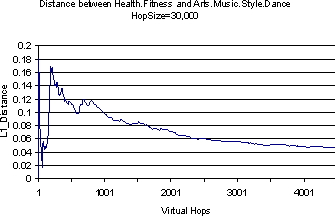
Obviously, the rate at which the topic probability vectors converge depends on the granularity of the topic specification, if only because it will take a larger number of documents to fill up a larger number of topic buckets adequately to make a reliable reading. We repeat the above experiment with a coarser version of Dmoz which is obtained by lifting all the 482 leaf classes of our Dmoz topic set to their immediate parents. Figure 3 shows the results. Because topic bins are populated more easily now, the distance is already small to start with, about 0.2, and this decreases to 0.05. But the number of virtual hops required is surprisingly resilient, again within the 1000-1500 range.
 |
|
There are some anomalous drops in distance at a small number of virtual hops in the graphs mentioned above. This is because we did not preserve the page contents during the walks but re-fetched them later for pages classification. Some page fetches at small hop count timed out, leading to the instability. For larger hop counts the fraction of timeouts was very small and the result became more stable.
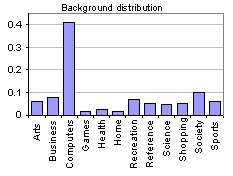
In Figure 4, we show an estimate of the background distribution of Web pages into the 12 top-level topics in our taxonomy. Computer-related topics lead the show. This is completely understandable (if only because of rampant mirroring of software manuals).
Many production crawlers follow an approximate breadth-first link exploration strategy which gives them some basic robustness against overloading a small set of servers or going depth-first into a bottomless ``spider pit''. The crawler which populates Alta Vista's Connectivity Servers follows largely a breadth-first strategy [5,7]. Najork and Weiner [27] have demonstrated that a breadth-first crawler also tends to visit nodes with large PageRank early (because good authorities tend to be connected from many places by short paths). A crawler of substantial scale deployed in NEC Research uses breadth-first scheduling as well.
| Level | Sampled | Unique | Fetched |
| 0 | 50000 | 49274 | 23276 |
| 1 | 500000 | 491893 | 45839 |
| 2 | 5000000 | 4857239 | 109544 |
The NEC crawl was started from URLs taken from Dmoz. These URLs were placed in level zero. We collected URL samples from levels 0, 1 and 2. Details are shown in Figure 5. Figure 6(a) shows the pairwise distance between the three levels of the NEC crawl. The distances are fairly small, which indicates that the aggregate class distribution drifts quite slowly as one strikes out from the seed set. Therefore any significant bias in the seed set will persist for quite a few levels, until the frontier size approaches a sizable fraction of the reachable Web.
| (a) |
| ||||||||||||
| (b) |
|
Figure 6(b) shows the distance of the NEC collections at the three levels and our approximation to the background topic distribution. We see some significant distance between NEC collections and the background distribution, again suggesting that the NEC topic distributions carry some bias from the seed set. The bias drops visibly from level 0 to level 1 and then rises very slightly in level 2. It would be of interest to conduct larger experiments with more levels.
| Topics OVER-represented in Dmoz |
| compared to the background |
| Games.Video_Games.Genres |
| Society.People |
| Arts.Celebrities |
| Reference.Education.Colleges_and_Universities.North_America... |
| Recreation.Travel.Reservations.Lodging |
| Society.Religion_and_Spirituality.Christianity.Others |
| Arts.Music.Others |
| Reference.Others |
| Topics UNDER-represented in Dmoz |
| compared to the background |
| Computers.Data_Formats.Markup_Languages |
| Computers.Internet.WWW.Searching_the_Web.Directories |
| Sports.Hockey.Others |
| Society.Philosophy.Philosophers |
| Shopping.Entertainment.Recordings |
| Reference.Education.K_through_12.Others |
| Recreation.Outdoors.Camping |
Many Web users implicitly expect topic directories to be a microcosm of the Web itself, in that pages of all topics are expected to be represented in a fair manner. Reality is more complex, and commercial interests play an important role in biasing the distribution of content cited from a topic directory. Armed with our sampling and classification system, we can easily make judgments about the biases in topic directories, and locate topics which are represented out of proportion, one way or another.
The L1 distance between the Dmoz collection and the background topic distribution is quite high, 1.43, which seems to indicate that the Dmoz sample is highly topic biased. Where are the biases? We show some of the largest deviations in Figure 7. In continuing work we are testing which among these are statistically significant. This is not a direct statement about DMoz, because our sample of DMoz differs from its original topic composition. Over-representation could be caused by our sampling, but the under-represented topics are probably likewise under-represented in DMoz. In any case, it is clear that comparisons with the background distribution gives us a handle on measuring the representativeness of topic directories.
Several researchers have corroborated that the distribution of degrees of nodes in the Web graph (and many social networks in general [16,34]) asymptotically follow a power law distribution [1,7,21]: the probability that a randomly picked node has degree i is proportional to 1/ix, for some constant `power' x > 1. The powers x for in- and out-degrees were estimated in 1999 to be about 2.1 and 2.7, respectively, though the fit breaks down at small i, especially for out-degrees [7]. Barabási and Albert [3] gave an early generative model called ``preferential attachment'' and an analysis for why millions of autonomous hyperlinking decisions distributed all over the Web could lead to a power-law distribution. Dill et al. [15] showed that subgraphs selected from the Web as per specific criteria (domain restriction, occurrence of a given keyword, etc.) also appear to satisfy power-law degree distributions. Pennock et al. [30] found that certain topic-specific subsets of the web diverge markedly from power-law behavior at small i, though still converge to a power law for large i; the authors explain these observed distributions using an extension of Barabási's model.
 |
|
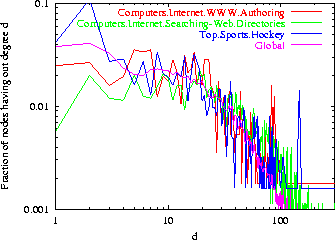
We conduct more general tests for power law behavior across a broad array of topics: if we fix a topic and measure the degree of nodes relevant to that topic, will the resulting degree distribution also follow a power law? We can use the same soft-counting technique to answer this question. Using a SAMPLING walk, we derive a sample D of pages. If a page d has degree Dd and class vector p(d), it contributes a degree of Dd pc(d) to class c. Note that Dd includes all links incident on d.
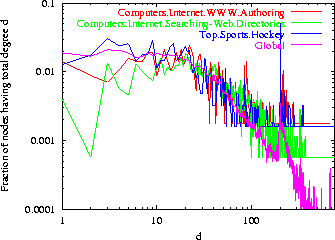
Figure 8 shows that topic-specific degree distributions also follow the power law over many orders of magnitude. We cannot explain this by claiming that ``social networking within a topic mimics social networking on the Web at large'', because Dd includes off-topic links, for which there is no known analysis of social networking processes.
Log-log plots of degree distributions for various topic look strikingly similar at first glance, but a closer examination shows that, for example, pages about Web directories generally have larger degree than pages about hockey, which matches our knowledge of the Web. We observe that the degree distribution restricted to members of a specific topic have a power law tail, but with a significant divergence from power law at small numbers of links, in agreement with the Pennock et al. findings [30], and in contrast to the global in-degree distribution which is nearly a pure power law [7].
An empirical result of Palmer and Steffan [29] may help explain why we would expect to see the power law upheld by pages on specific topics. They showed through experiments that the following simple ``80-20'' random graph generator fits power-law degree distributions quite well:
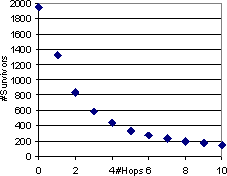
In this section we use the WANDER walk to see how fast the memory of the topic of a starting page fades as we take random forward steps along HREFs. (No backlinks or self-loops are permitted.) It is actually quite difficult in practice to sustain forward walks. Figure 9 shows that if we start a large set of WANDER walks, very few survive with each additional hop, owing to no outlink, broken outlinks, or server timeout. Note that this experiment is different from the study of the NEC crawler, because here, only one random outlink is explored from each page, whereas the NEC crawler tried to fetch as many outlinks in every subsequent level as possible.
 |  |
 | 
|
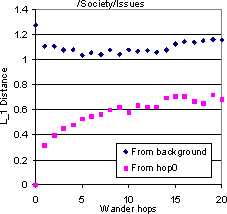
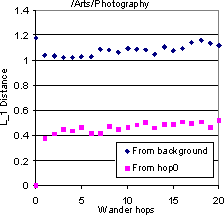
At this point we have a reference background topic distribution. We consider several classes in DMoz. Because forward walks die fast, we picked some Dmoz classes which were very well-populated, say with more than 10000 URLs. We start one WANDER walk from each URL. The starting pages are at distance 0. For each topic, we collect all the pages Di found at distance i, i � 0, and find the soft class histogram p(Di) as before. Next we find the distance between p(Di) and our precomputed baseline, as well as the distance between p(Di) and p(D0) to monitor the drift rate.
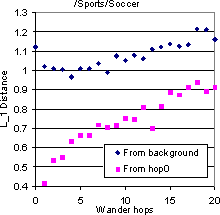
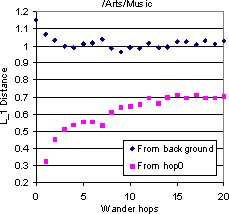
Figure 10 shows the results for four topics as starting points. Because all the starting points in each group were taken from a specific topic, the topic histogram at distance 0 is quite dissimilar from the background. Even 20 hops seem inadequate to bring the distribution closer to the background. But this is not because the walks stay perfectly on-topic. They clearly do start drifting away, but not too badly within the first 5-10 hops. Thus it is clear that a sampling-type walk is critical to topic convergence. The rate of drift away from the starting topic also varies from topic to topic: `Soccer' seems to be very drift-prone whereas `Photography' drifts much less. Such prior estimates would be valuable to a focused crawler, and explain in part why focused crawling along forward links is already quite successful [11]. We also confirm our intuition that our estimate of drift w.r.t. broad topics seems generally lower than what Davison and Menczer have characterized in terms of cosine similarity with the starting point.
Two families of popularity-based ranking of Web pages have been very successful in recent years. Google (http://google.com) uses as a subroutine the PageRank algorithm [6,28], which we have already reviewed in §2.1. Kleinberg proposed the HITS algorithm [20] which has many variants.
Unlike PageRank, HITS does not analyze the whole Web graph, but collects a subgraph Gq = (Vq,Eq) of the Web graph G in response to a specific query q. It uses a keyword search engine to collect a root set Rq, includes Rq in Gq and then further includes in Gq any node linked from or linking to some node in Rq (a radius-one link expansion). In matrix terms, we can reuse Eq to denote the node adjacency matrix: Eq(i,j) = 1 if i links to j, and 0 otherwise. HITS assigns two scores a(v) and h(v) with each node, reflecting its authority and its hubness (the property of compiling a number of links to good authorities), and solves the following mutually recursive equations iteratively, scaling a and h to unit norm every step:
| ||||||
It has been known that the radius-one expansion improves recall; good hubs and authorities which do not have keyword matches with the query may be drawn into Gq this way. Some irrelevant pages will be included as well, but our experiments confirm that at radius one the loss of precision is not devastating. Davison and Menczer [13,25] have proposed that topical locality is what saves Gq from drifting too much, but they did not use a reference set of topics to make that judgment.
Unlike HITS, PageRank is a global computation on the Web graph, which means it assigns a query-independent prestige score to each node. This is faster than collecting and analyzing query-specific graphs, but researchers have hinted that the query-specific subgraphs should lead to more faithful scores of authority [20].
PageRank has a random jump parameter d, which is empirically set to about 0.15-0.2. This means that typically, every sixth to eighth step, the random surfer jumps rather than walks to an out-neighbor, i.e., the surfer traces a path of typical length 6-8 before abandoning the path and starting afresh. The key observation is this: if topic drift is small on such short directed random paths, as Figure 10 seems to indicate, the global nature of the PageRank computation does not hurt, because endorsement to any node (apart from jumping to it uar, which treats all nodes equally) comes from a small neighborhood which is topically homogeneous anyway!
All this may explain why PageRank is an acceptable measure of prestige w.r.t. any query, in spite of being a global measure. Confirming this intuition will not be easy. Perhaps one can build synthetic graphs, or extract large graphs from the Web which span multiple topic communities, and tweak the jump probability d so that the average interval between jumps ranges from much less than directed mixing radius to much more that mixing radius, and see if the largest components of the PageRank vector leaves a variety of topic communities to concentrate in some dominant communities featuring ``universal authorities'' such as http://www.yahoo.com/, http://www.netscape.com/, http://www.microsoft.com/windows/ie/, or http://www.adobe.com/prodindex/acrobat/readstep.html.
According to the ordinary graph model for Web pages, a link or edge connects two nodes which have only graph-theoretic properties such as degree. Given our interest in the content of pages, it is natural to extend our view of a link as connecting two topics. The topic of a potential link target page v is clearly the single most important reason why the author of another page u may be motivated to link from u to v.
This view is clearly missing from preferential attachment theory, where the author picks targets with probability proportional to their current indegree, regardless of content or topic. It would be very interesting to see a general, more realistic theory that folds some form topic affinity with preferential attachment and matches our observations.
We model topic affinity using a topic citation matrix, which is constructed using soft-counting as follows:
 | 
|
| (a) Raw citation | (b) Confusion-adjusted |
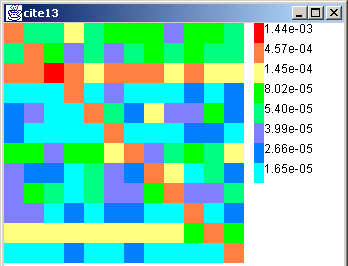
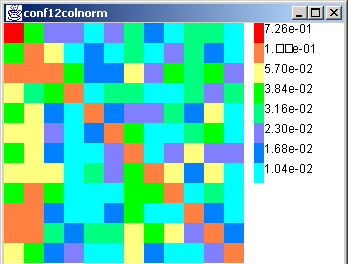
We experimented with our 482-leaf taxonomy at two levels of detail: the top level with 12 topics and the third level with 191 topics. This is partly because data at the 482×482 level was very sparse. In Figure 11(a), we show the 12-class top-level citation matrix. Dark colors (in the HTML version, hot colors) show higher probabilities. The diagonal is clearly dominant, which means that there is a great deal of self-citation among topics. This natural social phenomenon explains the success of systems like HITS and focused crawlers. It is also worthwhile to note that the matrix is markedly asymmetric, meaning that communities do not reciprocate in cross-linking behavior.
Apart from the prominent diagonal, there are two horizontal bands corresponding to /Computers and /Society, which means that pages relevant to a large variety of topics link to pages about these two topics and their subtopics. Given that these are the two most dominant top-level topics on the Web (Figure 4), it is conceivable that preferential attachment will lead to such behavior.
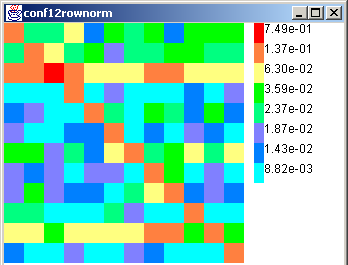 | 
|
| True-normalized | Guess-normalized |
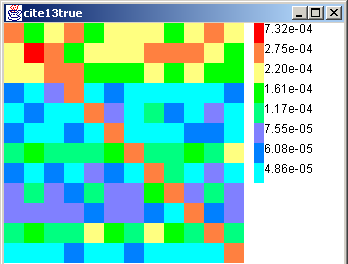
However, these inferences may be specious if it turns out that our classifier is biased in favor of /Computers and /Society when it guesses the class of test documents. To avoid this problem, we use a held-out labeled data set from DMoz to calibrate the classifier. The result is a confusion matrix E where E(i,j) is the number of documents in class i labeled with class j by the classifier. Depending on the application, we can scale either the row (true class) or the column (guessed class) of E to 1. In either case, an ideal classifier's confusion matrix will be the identity matrix. We show both scaled versions Et and Eg in Figure 12. Although the color scales were designed for maximum contrast, we note that the diagonal elements are generally large, hinting that the classifier is doing well.
The entries corresponding to guessed class j in the ``guess-normalized'' version Eg may be regarded as the empirical Pr(true = i|guess = j) for all i. Information from Eg can be folded into the soft counting process as follows. After we fetch and classify u and v, getting class probability row vectors p(u) and p(v), we find the corrected probability vector p*(u) (similarly, p*(v)) by computing the corrected probability that u `truly' belongs to class i as
| ||||||||
Returning to the citation matrix, we present the corrected citation matrix in Figure 11(b). Generally speaking, the correction smears out the probability mass slightly, but the corrected data continues to show a higher than average rate of linkage to documents about /Computers and /Society.
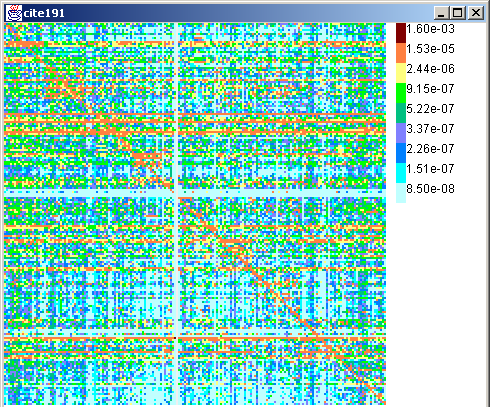
We can now extend the experiments to more detailed levels in the taxonomy. Figure 13 shows the citation matrix at the third level of our DMoz sample, with 191 topics. This diagram is a drill-down into the earlier 12-class citation diagram, and we see a telltale block-diagonals and other block-structure in the larger matrix, which align with the broad 12-topic boundaries. (They are not all equally wide, because the top-level topics have different numbers of descendants.)
The diagonal remains dominant, which is good news for topic communities and focused crawling. Finer horizontal lines emerge, showing us the most popular subtopics under the popular broad topics. Zooming down into /Arts, we find the most prominent bands are at /Arts/Music, /Arts/Literature and /Arts/Movies. Within /Computers, we find a deep, sharp line about a fourth of the way down, at /Computers/DataFormats. This is partly an artifact of badly written HTML which confounded our libxml2 HTML parser, making HTML tags part of the classified text. Other, more meaningful target bands are found at /Computers/Security, /Recreation/Outdoors, and /Society/Issues. We found many meaningful isolated hot-spots, such as from /Arts/Music to /Shopping/Music and /Shopping/Entertainment/Recordings.
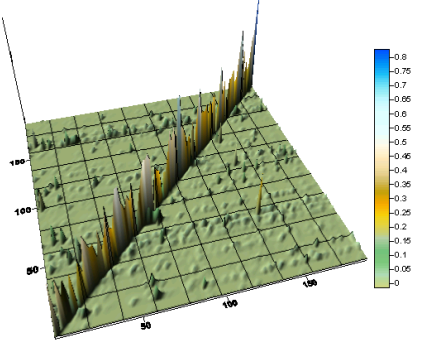
Because the `height' at various pixels is not very clear from a 2d rendering, we also show a 3d contour-plot of the 191×191 citation matrix in Figure 14. Although the excessive smoothing and the slope introduced between adjacent pixels is artificial, the contour-plot does reveal how strongly self-citing the topics are, even at the third level of DMoz.
The topic citation matrix, similar in spirit to a spectrogram, is fascinating in its own right in showing the strongest (single-link) inter-topic connections on the Web, but it also has a variety of practical applications. We touch upon a few here.
Improved hypertext classification: Standard Bayesian text classifiers build a class-conditional estimate of document probability, Pr(d|c), in terms of the textual tokens appearing in d. Pages on the Web are not isolated entities, and the (estimated) topics of the neighbors N(u) of page u may lend valuable evidence to estimate the topic of u [8,19]. Thus we need to estimate a joint distribution for Pr(c(u),c(N(u))), which is a direct application of the topic citation matrix.
Enhanced focused crawling: A focused crawler is given a topic taxonomy, a trained topic classifier, and sample URLs from a specific topic. The goal is to augment this set of relevant URLs while crawling as few irrelevant pages as possible. Currently, focused crawlers use the following policies:
Reorganizing topic directories: We had to discard the /Regional and /News subtrees, not only because of severe classification error, but also because of overwhelming interlinkage between these and other topics. /News is almost always about some other topic, such as /Sports or /Science. The structure within the /Regional or even the /Shopping subtree mirrors many broad topics outside. E.g., mountain biking fits under recreation and sports, but to buy biking gear, one must move up and then descend down the /Shopping path. A tree is a rather inadequate structure to connect areas of human endeavor and thought, and such artificial structures have compelled Yahoo! to include a number of ``soft links'' connecting arbitrary points in their topic `tree'.
The limitations of a tree representation are responsible for many long-range off-diagonal elements in the topic citation matrix, and arguably makes directory browsing less intuitive. It may also make focused crawling and automatic cataloging more difficult. We claim that such phenomena warrant careful consideration of taxonomy inversion and better metadata annotation. E.g., let commercial interests related to biking be contained in the subtree dedicated to biking, rather than collect diverse commercial interests together. We can envisage advanced user interfaces through which taxonomy editors can point and click on a topic citation map or a confusion matrix to reorganize and improve the design of a taxonomy.
The geography of the Web, delineating communities and their boundaries in a state of continual flux, is a fascinating source of data for social network analysis (see, e.g., http://www.cybergeography.org/). In this paper we have initiated an exploration of the terrain of broad topics in the Web graph, and characterized some important notions of topical locality on the Web. Specifically, we have shown how to estimate the background distribution of broad topics on the Web, how pages relevant to these topics cite each other, and how soon a random path starting from a given topic `loses' itself into the background distribution.
We believe this work barely scratches the surface w.r.t. a new, content-rich characterization of the Web, and opens up many questions, some of which we list below.
PageRank jump parameter: How should one set the jump probability in PageRank? Is it useful to set topic-specific jump probabilities? Does an understanding of mixing radius help us set better jump probabilities? Is there a useful middle ground between PageRank's precomputed scores and HITS's runtime graph collection?
Topical stability of distillation algorithms: How can we propose models of HITS and stochastic variants that are content-cognizant? Can content-guided random walks be used to define what a focused crawler should visit and/or collect? Can we validate this definition (or proposal) on synthetic graphs? Can such a theory, coupled with our measurements of topic linkage, predict and help avoid topic drift in distillation algorithms?
Better crawling algorithms: Given that we can measure mixing distances and inter-topic linkage, can we develop smarter federations of crawlers in which each concentrates on a collection of tightly knit topics? Can this lead to better and fresher coverage of small communities? Can we exploit the fact that degrees follow power laws both globally and locally within topic contexts to derive better, less topic-biased samples of URLs from the Web?
Acknowledgments: Thanks to Alice Zheng and David Lewis for helpful discussions, to Kim Patch for bringing Menczer's recent measurements to our notice, to Gary W. Flake for providing the NEC crawl data, and for his help with our code. We also thank the referees for helpful comments.
1Contact author, email soumen@cse.iitb.ac.in
2All
nodes have equal degree in a regular graph.