The vision of reusable digital learning resources or objects, made accessible through coordinated repository architectures and metadata technologies, has gained considerable attention within education and training communities. However, the pivotal role of metadata in this vision --and in more general conceptions of the semantic Web-- raises important and longstanding issues about classification, description and meaning. These issues are of special importance in indexing educational resources, where questions of application and relevance to particular learning contexts often supersede more conventional forms of access such as author, title or date. This paper will survey the controlled vocabularies defined in a number of educational metadata specifications (in particular, the set of values such as "quiz", "simulation", and "exercise" used to identify a "learning resource type"). Understanding these vocabularies in terms of their potential harmonization or rationalization in the CanCore Profile, this paper will illustrate the problems inherent in specifying educational and subject contexts and types. It will propose that the specification of these and other elements can best be approached not through further formalization and abstraction, but via careful study of their use, currency and relevance among existing communities of practice. It will conclude by emphasizing that a similar acknowledgement of the importance of community and practice will also be significant for further developments in XML and the semantic Web.
Metadata, Interoperability, Communities of Practice, Learning Objects, XML, RDF, Application Profiles, IMS, Learning Resource Type, Semiotics, Semantics, Z39.50
7990
In Understanding Media, McLuhan suggests that the content of any new medium, at least initially, is provided by the medium that it is in the process of supplanting (1964): the content of early writing, as in Homer's Odyssey, is the spoken word; and the content of early silent film was often theatre or vaudeville. Developments in Web technology and the use of this technology in education also seem to follow this pattern. Exclusive concern with document appearance and presentation --characteristics inherited from the print world-- are gradually giving way on the Web to multimedia formats and distributed organizational mechanisms. Similarly, in education, the Web initially took as its content the lectures, overheads, discussions and other aspects of the traditional classroom. Many of these aspects --down to the closed classroom door, the obligatory teaching assistant and the classroom whiteboard-- have been faithfully transferred onto the Web via password-protected course management systems like WebCT and Blackboard. However, attempts to replicate the face to face classroom may be giving way to distributed systems of "learning objects" that exploit the intrinsically decentralized and modular nature of Web-based content.
These learning objects --or granular, digital educational resources-- are made accessible and reusable through distributed repository or database architectures and through the use of systematic indexing or metadata. Learning objects are designed to be re-combinable to serve the needs of different instructors or students, and to be adaptable to a range of educational contexts, including distance and self-paced learning and training. Understood in the most general terms, a learning object could conceivably take the form of any of a number of digital media. These media can include Java applets, Flash animations, and audio and video clips; but they can also take the form of more exclusively "informational" materials like Web pages, Web sites, PDF documents, or PowerPoint presentations. These learning objects are made accessible or "discoverable" through exchangeable metadata records that describe their content, their educational application(s) and their technical and other characteristics. The function and limitations of this metadata --or "data about data"-- will form the focus of this paper.
Access or discoverability of Web-based resources has typically been facilitated through the use of search services or engines such as AltaVista or Hotbot. In the simplest terms, these services make Webpages and Websites discoverable by finding matches between the character-combinations or "strings" entered by the searcher, and those occurring somewhere in the textual contents of Web documents themselves. The problems that this technology presents to users in general and educators in particular are both familiar and manifold: tens or hundreds of thousands of "matching documents" are retrieved in response to almost any search string; educationally appropriate resources are difficult to find and evaluate; and multimedia or interactive content is not directly searchable. The inadequacy of this search technique springs, in part, from the fact that it works only with mere character combinations, matching those typed as searches against those occurring in Web pages. These search services have no real way of understanding or registering the significance of these character combinations or the potential purpose or value of the resources. In other words, these services only recognize the formal properties or the appearance of words, seeing them simply as "formal squiggles" (Dreyfus, 2001).
What has been widely suggested as a solution to these problems is to direct attention to the actual meanings of the words in Web documents, and to focus on the purpose or significance of the pages or resources themselves. Attempts to capture these meanings have become the raison d'être of Web-based descriptive metadata. "If there is a solution to the problem of resource discovery on the Web," as one metadata introduction explains, "it must surely be based on a distributed metadata catalog model" (Gill, 2001; p.7).
In this sense, metadata would function in a manner similar to a card or record in a library catalogue, providing controlled and structured descriptions of resources through searchable "access points" such as title, author, date, location, description and subject. But unlike library catalogue records, these metadata records are expected to provide interpretive information on the potential education application of resources. In further contradistinction to the card catalog example, a metadata record could either be located separately from the resource it describes, or be embedded or packaged with it. Also, many visualize this metadata as being distributed across the Web, rather than collected in a single catalog. Others extend this vision even further to include a number of other distributed mechanisms that involve logically rigorous ways of describing the relations between these resources. (This more ambitious vision of the "semantic Web" will be given further consideration below).
In apparent recognition of the importance of this change in approach, these visions of the future of the Web are characterized variously as "the next-generation Web," and the "intelligent," "content aware" or "semantic Web" (Bosak, Bray, 1998; Chislenko, 1997). Naeve, Nilsson and Palmér go so far as to proclaim the historical moment that this vision promises to usher in as "the semantic age," and they lay out the steps requisite for e-learning to play a leading role in this new era (2001). In an early article in this area, one author uses the language of established Web technologies and protocols to characterize this potential:
I expect that the next generation of information services will do for Web semantics what HTML and HTTP have done for its communication layer, that is to build a foundation for a global, intelligent, reactive knowledge exchange system. (Chislenko, 1997; my emphasis)
What is rarely if ever acknowledged in these sweeping characterizations is the fact that this shift in approach and emphasis --for both educational objects and visions of the semantic Web-- will entail an attendant sea-change in the conceptions and practices of those both designing and using Web contents.
For the use of metadata in these contexts needs to be seen as inserting a layer of human intervention and interpretation into the Web-based search and retrieval process. This layer of interpretation is one in which words are emphatically not just understood as "formal squiggles" that match other formal character strings, but as actual bearers of meaning and significance. When searching metadata --whether it is distributed across the Web or collected in a conventional library catalogue-- documents and other resources are seen as relevant to a given search not because of the letter or word combinations they contain. Instead, their value and purpose is assessed only according to the way they are represented and interpreted in the metadata that describes them. In this new vision of the Web, resources would be determined as relevant to a specific subject or category not as a direct result of their contents, but because of how a metadata creator or indexer has understood their relevance.
The shift in emphasis implied in this application of metadata can be understood in terms of a shift from data manipulation and processing to the creation, interpretation and assessment of information or knowledge. Data, information and knowledge are often conceived of as forming a hierarchy, where each successive layer is differentiated from the last through a process of interpretation and mediation. Merriam-Webster defines data as "information in numerical form that can be digitally transmitted or processed" (2001) --in other words, as pure, un-interpreted fact, perception, signal or message. Information, as characterized by management guru Peter Drucker, is data that is "endowed with relevance or purpose" (1988; p. 4). Information, in other words, can be said to form the contents of the data signal or message. Knowledge, finally, is defined in terms that associate it even more closely with human understanding, intention and purpose: As 1) "the fact or condition of knowing something with familiarity gained through experience or association," 2) "acquaintance with or understanding of a science, art, or technique," or 3) "the fact or condition of being aware of something" (Merriam-Webster, 2001).
In this context, to characterize an interpretation of the meaning or purpose of a digital resource as "metadata" seems misleading. For in order to be "about" something --or to deserve the prefix "meta"-- data needs to be endowed with purpose and relevance. On their own, the 1's and O's of a digital description (or any other digital resource) are not about anything in particular. To acquire relevance or "aboutness," this raw data needs to be transformed into interpreted information or knowledge. In this sense, metadata as data that has significance or is "about something" is a contradiction in terms. Only by clearly indicating and understanding how metadata is to function as a complex description of meanings, purposes and contexts will it be possible to realize the potential of specifications, profiles and technologies developed for metadata.
Many specialists in the established fields of classification and indexing also recognize the importance of this difference between the search and retrieval of data on the one hand, and the discoverability of "information" or "documents" on the other. Writing in an article appearing long before the advent of the Web and of many other information technologies, M. E. Maron articulates this differentiation as follows:
It has become more or less standard to divide the access problem into two parts: access to data, and access to documents. Systems that provide access to data are called "data retrieval" or "question-answering" systems.... Document retrieval systems, on the other hand, are one linguistic level removed from the storing and processing of factual data; they answer questions about documents (books, journals, reports and writings of all sorts) (Maron, 1977; p. 38).
In terms of the above discussion of the Web and metadata, "data retrieval," of course, corresponds to string matches occurring on the level of textual strings, or HTML files. "Document retrieval" conceives of these same files as Web documents, made discoverable exclusively through records describing their author, title, content, and other aspects.
In Language and Representation in Information Retrieval, Blair reiterates this distinction between data and document, and draws an important conclusion that will also be taken up here: namely, that in order to understand the processes of interpretation and description, it is necessary to carefully consider linguistics and language themselves:
The process of representing documents for retrieval is fundamentally a linguistic process, and the problem of describing documents for retrieval is, first and foremost, a problem of how language is used. Thus any theory of indexing or document representation presupposes a theory of language and meaning (122).
Blair also indicates that the understanding of language that is most often implied in discussions of information retrieval is one that is broadly semiotic in nature. Semiotic linguistic theory understands language as a system of signs, with each sign being comprised of two parts: 1) the signifier, the "material sound-image;" and 2) the signified, the "concept" to which the signifier corresponds (de Saussure, 1972; p. 63). The signifier, on the one hand, can be understood as a purely "material" entity, whose physical form is completely conventional and arbitrary. The signified, on the other hand, is a distinct idea, concept or "mental image," a purely psychological, "mentalistic" phenomenon (de Saussure, 1972; pp. 70-71; Blair, 1990; pp. 127-137).
This distinct separation between physical sign and mental signification is often reinforced and deepened in the way computers process human languages and texts. As mentioned above, Web-based search services and many other forms of computerized text-manipulation deal with language only on the level of the signifier --as formal, arbitrary patterns or "squiggles." These signifiers or tokens are understood as being related to their conceptual, mentalistic counterparts in an entirely contingent, arbitrary manner. A computer, as Varela, Thompson and Rosch explain, operates "only on the physical form of the symbols it computes" --having "no access to their semantic value" or meaning (Varela, Thompson and Rosch, 1992; p. 41). The relation between signifier and signified, token and meaning, is typically seen as being established through explicit definition, a process that often occurs in abstraction from the sign's physical, material characteristics or the quotidian contexts of its use. Meanings in both semiotics and computer processing are associated with signifiers only through arbitrary, definitional connections. John Haugeland contrasts the arbitrary and derivative nature of these definitional connections with what he calls "genuine understanding:"
[a computer's] tokens only have meaning because we give it to them; their intentionality, like that of smoke signals and writing, is essentially borrowed, hence derivative. To put it bluntly: computers themselves don't mean anything by their tokens (any more than books do) --they only mean what we say they do. Genuine understanding, on the other hand, is intentional "in its own right" and not derived from something else. (Haugeland, 1981; pp. 32-33, emphasis in original)
A further point of emphasis shared by semiotics and computerized language processing is a particular privileging of syntax. Defined as "the way in which linguistic elements (as words) are put together to form constituents (as phrases or clauses)" (Merriam-Webster, 2002), syntax is understood in both semiotics and computer processing as an important structuring principle of language. Both see syntax as something that can be understood in relative isolation from the other aspects of language. Computer language processing and Web-based search services rely on syntactic rules and regularities in language to parse sentences and search queries grammatically. (Examples of this syntactically-based text manipulation in search engines includes the automatic truncation of standard suffixes, the insertion of Boolean operators between tokens, and the removal of common conjunctions and prepositions. [Notess, 2001])
In both semiotic theory and computer programming, this emphasis on syntax is often combined in a significant way with exclusively definitional conceptions of meaning. The result of this combination is the formulation of definitional statements of an almost mathematical quality. In the case of semiotics, these definitions are produced through "componential analysis"; and in the case of a technology proposed as a part of the semantic Web, such defnitions take the form of take the form of "ontological" statements. In each case, these statements look something like the following (respectively):
stool = [+sitting] [+legs] [-back] [-arms] [+single person] (Norrick, N. R. 1998)
class-def defined herbivore subclass-of animal slot constraint eats, value-type plant (Fensel, D. et. al. 2000)
In the first formulation, "stool" is defined in terms of the presence and absence of particular attributes, such as legs, arms, a backrest, and utility for sitting. The second, part of semantic structures designed to enable artificially-intelligent processing of Web data, defines "herbivore" as a sub-type of the class "animal" which is further specified as eating only plants.
At this point, following the linguistic understandings of semiotic and language processing theory, it would seem that to identify meaning, relevance and purpose through the interpretive act of metadata creation would largely be a question of clear and unambiguous definition. And the issue of semantics itself would seem to be reducible to a question of clearly associating a word, sign or token with a definition.
One might infer that these were some of the tacit assumptions informing the development of "IMS Learning Resource Meta-data Information Model," the leading specification for the creation of structured metadata records for the description and exchange of learning objects. This metadata specification ambitiously defines about 80 separate aspects or "elements" for the description and management of learning resources. These elements include generic informational items such as title, author, description, and keywords, but also include exclusively educational aspects like "typical learning time" or "educational context." In keeping with linguistic understandings implied in semiotics and computer processing, this IMS metadata specification provides semantic definition of these elements separately from the syntax (or the XML "binding") that is to structure each record.
However, as the IMS itself admits, their metadata specification has proven to be too complex to be implementable or put to direct use: "Many vendors [have] expressed little or no interest in developing products that [are] required to support a set of meta-data with over 80 elements" (IMS, 2000). In addition, many of the elements in the IMS specification are not defined and described in sufficient detail to allow for consistent implementation. For example, the element "semantic density" is characterized confusingly in the IMS documentation as a "subjective measure of the learning object's usefulness as compared to its size or duration", and the element labeled "Catalog Entry" is described only as the "designation given to the resource." (IMS 2001).
In order to build on the IMS specification and to take advantage of the educational elements associated with it, the "Canadian Core Learning Object Metadata Application Profile" (CanCore) provides a simplified, explicated and interpreted version of this specification. CanCore gives precise definition to 36 elements as a workable sub-set of the numerous IMS elements that have been identified as being of greatest utility to indexers, users, and learning object management in general. CanCore forms what is known as an "application profile" for IMS metadata, recommending specific understandings for each element, and (in some cases) the use of particular taxonomies or controlled vocabularies. The purpose of providing these interpretations and recommendations is to ensure that metadata records created by any number of Canadian and other repositories are constructed as consistently and systematically as possible. This will serve not only to enhance the effectiveness of these metadata records as means for discovery, description and administration, but will make it possible to share and exchange them between projects and jurisdictions. This capacity to share resources efficiently and effectively across systems and jurisdictions is known as "interoperability:" "the ability of a system or product to work with other systems or products" (Miller, P. 2000).
The vocabulary or taxonomy for the element labeled "learning resource type" will form the focus of this brief case study. The learning resource type element is defined in IMS only with the words: "Specific kind of resource, most dominant kind first." As an additional note, the specification also states: "This element corresponds with the Dublin Core element 'Resource Type'. The vocabulary is adapted for the specific purpose of learning objects." (Dublin Core is a general-purpose metadata specification "created to provide a core set of elements that could be shared across disciplines" [Dublin Core, 2001]). And this particular resource type vocabulary, as it is provided in Dublin Core documentation, consists of the following values: "Collection, Dataset, Event, Image, Interactive Resource, Service, Software, Sound, Text" (Dublin Core, 1999). As the Dublin Core documentation itself states, these terms are meant to describe "the nature or genre of the content of the resource." The Dublin Core documentation also comments that "to describe the physical or digital manifestation of the resource, the 'format' element" should be used."
So it would seem clear that the vocabulary used for this element in the IMS specification should identify the genres or general types of content that can constitute an educational resource in isolation from its digital manifestation. Such a vocabulary might include specific values or terms like "demonstration," "exercise," and "assessment," "quiz" or "test." Indeed, the IMS provides a recommended vocabulary for this element in which a number of these values are included. This vocabulary is as follows: "Exercise, Simulation, Questionnaire, Diagram, Figure, Graph, Index, Slide, Table, Narrative Text, Exam, Experiment, Problem Statement, Self Assessment."
However, closer examination of these terms reveals a number of problems. First, this recommended vocabulary includes terms whose apparent meanings are difficult to differentiate. For example, values such as diagram, figure and slide, and perhaps to a lesser extent, exercise, simulation, and experiment could be used with a greater or lesser degree of interchangeability. Moreover, no definitions are provided to clarify and individuate the meanings of these terms. In addition, this listing seems to mix or conflate two different sorts of categorization: on the one hand, it includes terms that describe the formal properties of a resource --terms like slide, table, or narrative text. On the other hand, it also includes terms that speak to the pedagogical application of a resource --as is the case with values like exercise, self assessment or exam. It would be easy to conceive of a table or narrative text making up a significant part of an exercise or exam, or serving an entirely different pedagogical purpose. In other words, this vocabulary or taxonomy confuses the description of two aspects of a learning resource that would be best kept separate and mutually independent.
Difficulties in interpreting the "learning resource type" element and in devising an effective vocabulary for this element can be further illustrated by looking briefly at taxonomies or vocabularies suggested for this element --or for elements similar in definition or purpose. The table below provides four examples of vocabularies that have been developed more or less independently for this element or for elements defined in very similar terms. In most cases, these vocabularies have been devised in the contexts of other learning object repository projects or content management technologies. The first of these vocabularies has been developed for the "Gateway to Educational Materials" or "GEM," a "consortium effort to provide educators with quick and easy access to [Web-based] educational resources" (GEM, 2001; GEM, 2000). This vocabulary presents a more extensive version of the IMS recommended vocabulary, also mixing terms that refer both to formal properties (image set, form, serial, for example), and to potential educational applications (activity, curriculum support). The second vocabulary is developed by EdNA Online, "a service that aims to support and promote the benefits of the Internet for learning, education and training in Australia" (EdNA, 2001; EdNA, 2000). This taxonomy deals with the ambiguity between resource format and potential educational application by explicitly differentiating between these two categories --using the terms "document values" and "curriculum values," respectively, as broad equivalents. However, this approach still results in the use of one element to describe two separate aspects of a learning object, and leaves the exact purpose or significance of some values --such as manuscript or online project-- unclear. The third taxonomy listed has been developed for WebCT (short for "Web Course Tools"), a course development and delivery platform (Friesen, 2000). The WebCT vocabulary for learning resource type simply enumerates the different components or tools in WebCT in an undifferentiated and unedited form (Voltero, 2001). As illustrated by terms like Student, Compile, or Language, this taxonomy makes sense only in the context of the WebCT product itself. Indeed, it would seem counterproductive to use it for any other purpose. Finally, ARIADNE --a research and technology development project of the European Union-- understands resource type in terms of what it calls "document type" (ARIADNE, 1999). It suggests only two values of active and expositive to characterize these documents: "Expositive documents include essays, video clips, all kinds of graphical material and hypertext documents. Active documents include simulations, questionnaires and exercises" (ARIADNE, 1999). Through its simplicity, this taxonomy seems to avoid the categorical ambiguities that plague the other vocabularies; but at the same time, it fails to differentiate between a number of common types of educational resources, such as student evaluations, a record of an instructor's presentation, or a simulation.
| GEM Resource Type | EdNA | WebCT | ARIADNE 3.2 |
|
Activity |
document values |
Assignments Calendar Cdrom Chat Compile Content Module Course Discussions Glossary Image Database Index Language My Grades My Progress Navigation Organizer Page Password Student Presentation Individual Quizzes Quiz Resume Course Self Test Course Map Student Homepages Syllabus Student Tips Whiteboard |
Active document Expositive document |
It would seem that none of the vocabularies listed and described here meet the goal of clear, unambiguous definition mentioned above. Nor do they hold the promise of facilitating any kind of effective interoperability between the systems in which they would be implemented: there does not seem to be any obvious way to realize any commensurability between these taxonomies; they do not lend themselves to any mutually compatible harmonization. Ultimately, no one of these vocabularies seem to be successful in the task of linking together signifier and signified in a way that is consistent, in such a way that a particular aspect of a number of learning objects can be consistently and logically described.
The failure of any one of these vocabularies to deal adequately with the apparently straightforward notion of learning resource type seems indicative of some of the larger problems that have long plagued resource description and classification. The magnitude of these problems can be easily illustrated through reference to research carried out in the area of classification and resource description. As an example, studies of "inter-indexer consistency," the likelihood of two indexers describing the same resource with the same index terms, suggest that "substantial inconsistency is the rule rather than the exception" --with measures of consistency often in the area of 60% (Todd, 1992, p. 101; Song, et. al. p. 1). Meanwhile, the chance of any two people spontaneously entering a search query using the same subject term is almost infinitesimally small: "In every case two people favored the same term with probability <0.02," as one study concludes (Furnas, et. al. 1987). The general effectiveness of subject classification in libraries has been a matter of dispute in the literature of library science for some time. Unfortunately, studies and information similar to those available for library classification are not yet available in the case metadata in general or learning object classification and description in particular. However, as a starting point one can predict that they would at best be consistent with results in long-established indexing and cataloguing practices.
Despite the absence of studies in metadata creation, it is possible to gain further understanding of how descriptive metadata might facilitate resource discovery and interoperability by looking at related examples of information creation and management, and to give further consideration to the linguistic understandings that they presuppose. To begin, it may be useful to recall that the words and taxonomies being used in any metadata specification are not simply raw data. Contrary to what the word "metadata" might imply, the use of terms to describe a learning resource type --or any other aspect of a document or object-- is a reflection of the knowledge, interpretation and judgment of the indexer. Peter Drucker's earlier explanation of the term "information," quoted here at greater length, further indicates that this interpretation and judgment does not occur in isolation:
Information is data endowed with relevance and purpose. Converting data into information thus requires knowledge. And knowledge, by definition, is specialized. (In fact, truly knowledgeable people tend toward overspecialization, whatever their field, precisely because there is always so much to know) (Drucker, 1988; p. 4).
It is significant that Drucker mentions specialization or expertise as being constitutive of knowledge: for it is specialization or expertise that locate the individual knower in a particular context, and often, in specific, concrete practices, commitments and communities. One could extend this argument even further by saying that the conversion of data to information or knowledge that happens in the interpretive process of metadata creation implies a number of common-place social and human realities: It entails personal involvement in and commitment to specific practices, and most often, participation in a community of those with similar or complimentary understandings.
All of this would heighten the surmise that the significance of words and descriptions in metadata may not be so much a matter of clear and unambiguous definition, but of doing, acting, and belonging. Establishing the meaning of words may not be so much a question of defining the relationship between signifier and signified, however rigorously this relationship is analyzed and formulated. Meaning, in other words, is perhaps not a matter of definitional or analytical rigour, but of doing and of using words. In fact, this is a position frequently articulated by experts in the emergent field of organizational ethnography. For example, in his book Communities of Practice: Learning, Meaning and Identity, Wenger emphasizes that meanings arise through practice and engagement with everyday concerns:
This focus on meaningfulness is therefore not primarily on the technicalities of "meaning." It is not on meaning as it sits locked up in dictionaries. It is not just on meaning as a relation between a sign and a reference [or signifier].... Practice is about meaning as an experience of everyday life (emphasis in original; Wenger,1999; pp. 51-52).
Wenger further emphasizes that everyday life is above all social and participatory. He describes this "social participation" as follows:
[It] refers not just to local events of engagement in certain activities with certain people, but to a more encompassing process of being active participants in the practices of social communities and constructing identities in relation to these communities.... Such participation shapes not only what we do, but also who we are and how we interpret what we do (1999; pp. 4).
The meaning of any set of terms, and the significance and utility of any taxonomy, according to Wenger's thinking, can be evaluated only in the context of a community whose members are involved in similar activities and share similar values. Wenger calls this process the "negotiation of meaning:" the production of meanings "that extend, redirect, dismiss, reinterpret, modify or confirm... the histories of meanings of which they are a part" (Wenger, 1999; p. 53).
One example of a technically-oriented specification that bears some resemblance to the complexities of the IMS learning object metadata specification, and that also provides an important object lesson in "negotiation of meaning" goes by the name of Z39.50. This particular protocol defines query and retrieval functionality for searching across multiple databases from a single interface or point of access. Z39.50 has been under development for more than 20 years; however, its history has been plagued by controversy, misconceptions and disagreements. As Clifford Lynch explains, this protocol has been developed and extended in response to "an ever-growing set of new communities and requirements" (1997). However, as a result "it has become ever less clear what the appropriate scope and boundaries of the protocol should be" (Lynch, 1997). Understanding interoperability as having both semantic and formally technical dimensions, Lynch emphasizes the value of the lessons provided by Z39.50 development:
Z39.50 is one of the few examples we have to date of a protocol that actually goes beyond codifying mechanism and moves into the area of standardizing shared semantic knowledge. ...the insights gained by the Z39.50 community into the complex interactions among various definitions of semantics and interoperability are particularly relevant (Lynch, 1997).
One of the solutions that has emerged to the problems posed by Z39.50 implementation has been the development of "application profiles" --"customizations of the [Z39.50] standard to particular communities of implementers with common applications requirements" (Lynch, 1997). (As indicated earlier, CanCore represents just such a customization intended for the community constituted by those implementing learning object metadata in Canada.)
The development of application profiles for Z39.50 has led to very specific thinking about the communities involved, and about the ability of Z39.50 to work within and across these communities. Emphasizing that interoperability is a matter of degree, rather than an all or nothing proposition, Moen (co-author of the "Bath" Profile for Z39.50) suggests that interoperability varies with the degree of commonality between communities: "We suggest... that the degree of interoperability between information systems may be dependent on the distance between communities whose information systems attempt to interact" (Moen, 2001). Moen goes on to explain that
Within a community or domain, relative homogeneity reduces interoperability challenges. Heterogeneity increases as one moves outside of a focal community/domain, and interoperability is likely [to be] more costly and difficult to achieve (Moen, 2001).
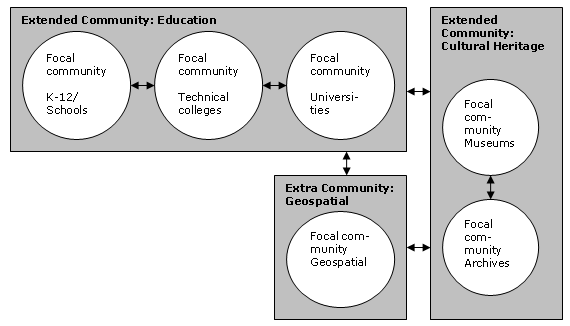
He also outlines a number of levels of community commonality or homogeneity, as well as a variety of relationships that can exist between communities. Following the example of a diagram provided by Moen, those communities sharing and using learning object communities might be schematized in the following way:
The communities and relationships schematized here include "focal communities," drawn as circles. Relationships formed within or relationships constitutive of these communities are known here as intra-community relationships. These focal communities generally have a high degree of internal homogeneity, with clearly defined interests, memberships and common understandings. If two or more of these focal communities are able to identify common interests and values, they can establish an inter-community relationship. Together, these related communities would constitute what Moen identifies as an "extended community." This is a type of community that possesses less homogeneity than a focal community, but still shares some ways of understanding and defining meaning. It is possible for two extended communities to enter into their own inter-community relationship --once they have negotiated common interests and understandings. As an additional variation in Moen's model, when an individual community is brought into relation with an extended community, this individual community is known as an "extra community."
As the above diagram indicates, the focal communities constituted by schools, technical colleges and universities together would together form an extended educational community. As such, this extended community would be able to form relationship with the extended "cultural heritage" community (constituted, in turn, by the related focal communities of museums and archives). Either of these extended communities would be able to form relationships with the "extra community" constituted by the geospatial focal group.
Intra-community relationships that constitute focal communities and inter-community relationships that can be formed between communities are quite different in nature. Both types of relationship are formed through different processes, and entail the use of different technologies, as well as the realization of varying levels of interoperability.
Relationships that constitute a focal community in and of itself can be formed through relatively direct agreement on semantics and other forms of interoperability. Using the syntactic framework provided by XML for the exchange of customized documents, members in these communities can rely on an existing set of shared meanings and can make use of established community mechanisms (governing bodies, conferences, and special interest groups, for example) to further define the semantics for information interchange. The key technological form that helps define these semantics is the DTD (Document Type Definition) or more recently, a more flexible means of document type definition known as a "schema." In the simplest terms, these technologies define the specific XML tags or terms that will be used to label the information to be exchanged within the community. (An example of one such schema document is provided as a part of the IMS learning object metadata specification.) As a very simple example of a community schema or DTD, the archives community might want to identify "location", "version", "title" and "accession number" as the semantics for the internal interchange of collection information within their focal community. These particular elements would be formalized in the syntax of a DTD. In instances of documents created with this document type definition, these elements would be assigned particular values; and each document would describe a particular artifact. In reality, such a DTD (containing, of course, a much more extensive and complex semantics) already exists for the archives community, and goes by the name "Encoded Archival Description" (EAD). Similar document type definitions have also been created in business and other communities for the exchange of inventory, sales, and many other types of information (see, for example XML.com, 2001).
In an early policy document focusing specifically on document type definitions, the interchange mechanism of the DTD is characterized as "a guardian of common interests," or as an "exchange agreement" (National Defense, 2001). This document goes on to explain that DTDs serve as agreements that well-defined groups of people or organizations can use to exchange information in a reliable and interoperable manner (National Defense, 2001): The "DTD is really an agreement between people exchanging documents on how they will use SGML [or XML] to describe a common document architecture" (National Defense, 2001). The process of negotiating such an agreement would seem to fit quite directly with Wenger's notion of the "negotiation of meaning:" Within the archives community, for example, it would be possible to build a consensus around the very particular meaning of terms, for example, like "location" and "version" for archival practice. (Indeed, common understandings of the meanings of these terms would likely have already been established within this community through shared practices and processes.)
However, in other communities, the significance of such apparently obvious terms might be quite different, their meaning being negotiated in the context of very different practices. For example, in communities dealing with digital rather than physical artifacts, the term "location" would refer not to storage place of a physical item, but to the networked access location of one or more digital versions of the same item. Also, the word "version" itself would take on different meanings in the context of digital artifacts, since copies of digital entities are made easily and routinely, and because variations in copies can be introduced algorithmically (Manovich, 2001). In addition, linking between focal communities possessing different understandings would be made more difficult because of the frequent absence of any established inter-community organizational mechanisms that span these communities.
The semantics or meanings of the terms encoded in DTD or schema technologies used for exchange within communities add to this difficulty. As Heflin and Hendler point out, these semantics are not encoded in an explicit manner that would allow for interoperable interchange between focal communities:
the semantics of a DTD are implicit. That is, the meaning of an element in a DTD is either inferred by a human due to the name assigned to it [e.g. "location" or "version"]. Humans can then build these semantics into tools that are used to interpret or translate the XML documents, but software tools cannot acquire these semantics independently (Heflin, J. Hendler, J. 2001; p. 112).
The solution that Heflin and Hendler bring to this problem of inter-community relationship is to define the terms occurring in XML documents in a thoroughly explicit and formalized manner. This solution goes by the name "ontology," a concept that has come up earlier in this paper, and that can be defined simply as "a document of file that formally defines the relations among terms." (Berners-Lee, Hendler, Lassila, 2001). Advocates of the semantic Web see ontologies as being able to create relations between terms --between terms that are used in different ways by heterogeneous communities. These relations, moreover, are understood as being thoroughly formalized or machine readable, and as enabling the algorithmic generation of even further relations or ontologies:
Machine-readable explicit representation of diverse semantic information should provide [semantic Web] systems with a lot of "food for thought" that would help develop knowledge acquisition and processing algorithms, and also will prove instrumental in further acquiring and processing knowledge from less structured sources (Chislenko A. 1997).
Berners-Lee, the inventor of the World Wide Web, explains further how this structure and formalization will enable the second generation, semantic Web:
For the semantic web to function, computers must have access to structured collections of information and sets of inference rules that they can use to conduct automated reasoning.... The challenge of the Semantic Web, therefore, is to provide a language that expresses both data and rules for reasoning about the data and that allows rules from any existing knowledge-representation system to be exported onto the Web (Berners-Lee, Hendler, Lassila, 2001).
What these advocates suggest as a solution to the problem of intra-community interoperability, in short, is to again understand complex, human-negotiated semantics in terms of computer-processable formal "squiggles," physical signifiers or raw data.
Unfortunately, this vision ambitiously overlooks decades of empirical evidence from in the fields of document description, cataloguing and indexing (to say nothing of the failures of symbolic artificial intelligence [Dreyfus, 1992]). Techniques of formalized interrelation and definition that seem so important for the semantic Web have proven to be of clearly limited use in classification and indexing practices and technologies. Evidence from document description practices indicates that semantic ambiguities arising from cross-community relationships cannot be simply be reduced to a matter of formalized, rule-bound data processing. Moreover, notions of "degrees" of interoperability or community homogeneity --conceptions that have proven so important to the success of Z39.50-- seem to find no mention in the literature of the semantic Web. And as this paper shows, even the more familiar issues of intra-community consensus (in the case of learning type vocabularies) can give rise to serious barriers to realizing even a modicum of semantic interoperability.
The goal of increased interoperability between communities will not be achieved through further formalization and abstraction. What will bring this goal closer, however, is increased negotiation within, but especially between communities. Techniques of accomplishing this, such as "domain analysis" (Nielsen, 2001) and the identification of "boundary objects" (Bowker, Star, 1999; p. 196-198) have already been developed and used with some success in other fields. If interoperability is to be established between communities or across a semantic Web of disparate resources, it seems likely that organizational and descriptive rather than technical supports are the key ingredient that is currently lacking. CanCore hopes to provide such supports within the educational community, and is seeking also to establish relationships of mutual benefit with other communities possessing similar interoperability concerns.
Norm Friesen has been working in the area of instructional Web development at the University of Alberta since 1997. His work has included programming, instructional design, layout and graphical artwork, and collaborative website development. Since the winter of 2000, he has been working on the CAREO Project (Campus of Alberta Repository of Educational Objects). This project has as its goal the creation of a searchable online collection of postsecondary educational resources, and requires a focus on issues like peer review, repository and gateway architecture, and resource modularity and discoverability. Mr. Friesen's work has recently focused on the last of these, the development of descriptive data or metadata that will make these resources easy to find and use. This has led him to collaborate in the development of the CanCore Profile, a standard way of describing educational resources that will be used in a number of educational repository projects across the country. His academic credentials include a Master's degree in Library and Information Studies from the University of Alberta and a Masters in German Literature from the Johns Hopkins University. He is currently completing his Ph.D. in Education at the University of Alberta.
ARIADNE Alliance of Remote Instructional Authoring and Distribution Networks of Europe (1999). ARIADNE Educational Metadata Recommendation. [Web Page]. URL http://ariadne.unil.ch/Metadata/
Berners-Lee, T. Hendler, J. and Lassila. The Semantic Web. Scientific American. May 2001. [Web Page]. URL http://www.sciam.com/2001/0501issue/0501berners-lee.html.
Blair, D.C. (1990). Language and Representation in Information Retrieval. Amsterdam: Elsevier.
Bowker, G.C. and Star, S. L. (1999). Sorting Things Out. Cambridge, Mass: MIT Press.
de Saussure, F. (1972). Course in General Linguistics. The Structuralists from Marx to Lévi-Strauss. pp. 59-79.
Dreyfus, H. (2001). On the Internet. London: Routledge.
Dreyfus, H. (1992). What Computers still can't do. Cambridge, MA: MIT Press.
Drucker, P. F. (1988). The Coming of the New Organization. Harvard Business Review. January-February. pp. 4-11.
Dublin Core (1999). Dublin Core Metadata Element Set, Version 1.1: Reference Description. [Web Page]. URL http://www.dublincore.org/documents/dces/
Dublin Core. (2001). DCMI Frequently Asked Questions (FAQ). [Web Page]. URL http://www.dublincore.org/resources/faq/
EdNA Education Network Australia. (2000). EdNA Metadata Elements. [Web Page]. URL http://standards.edna.edu.au/metadata/elements.html
EdNA Education Network Australia. (2001). About Us. [Web Page]. URL http://www.edna.edu.au/aboutus/aboutsite.html
Fensel, et. al. (2000). OIL in a Nutshell. [Web Page]. URL http://www.cs.vu.nl/~ontoknow/oil/downl/oilnutshell.pdf
Friesen, N. (2000). Guide to WebCT 3 for Instructors: Design, Development and Delivery. Whitby, ON: McGraw-Hill Ryerson.
Furnas G, T.K. Landauer, L.M. Gomez, S.T. Dumais. (1987). The vocabulary problem in human-system communication. Communications of the ACM. (30). pp. 964-71.
GEM Gateway to Educational Materials. (2000). GEM Resource Type Controlled Vocabulary. [Web Page]. URL http://www.geminfo.org/Workbench/Metadata/Vocab_Type.html
GEM Gateway to Educational Materials. (2001). About GEM. [Web Page]. URL http://www.geminfo.org/networker.html
Geoffrey C. Bowker and Susan Leigh Star. Sorting Things Out: Classification and Its Consequences. Cambridge, MA: MIT Press, 1999.
Gill, T. (2001). Metadata and the World Wide Web. [Web Page]. URL http://www.getty.edu/research/institute/standards/intrometadata/pdf/gill.pdf
Heflin, J. and Hendler, J. (2000). Semantic Interoperability on the Web. In: Proceedings of Extreme Markup Languages 2000. Graphic Communications Association, Alexandria, VA. Pp. 111-120. [Web Page] URL http://www.cs.umd.edu/projects/plus/SHOE/pubs/extreme2000.pdf.
Haugeland, J. (1981) Semantic Engines: An Introduction to Mind Design. In: Haugeland, J. (ed.) Mind Design Philosophy Psychology Artificial Intelligence. Cambridge, MA: MIT Press.
Haugeland, J. (1989) Artificial Intelligence. Cambridge, Mass: MIT Press.
IMS Global Learning Consortium. (2000) IMS Learning Resource Meta-data Best Practices and Implementation Guide. [Web Page]. URL http://www.imsproject.com/metadata/mdbestv1p1.html
IMS Global Learning Consortium. (2001) IMS Learning Resource Meta-data Information Model. [Web Page]. URL http://www.imsproject.org/metadata/ims_md_infov1p2.html
Lynch, C. A. (1997). The Z39.50 Information Retrieval Standard. Part I: A Strategic View of Its Past, Present and Future. D-Lib Magazine. April. [Web Page]. URL http://www.dlib.org/dlib/april97/04lynch.html
Manovich, Lev. (2001). The Language of New Media. Cambridge, MA: MIT Press.
Maron, M.E. (1977). On Indexing, Retrieval and the Meaning of About. Journal of the American Society for Information Science. January.
McLuhan, M. (1964). Understanding Media: the Extensions of Man. New York: McGraw-Hill.
Miller, P. (2000). Interoperability What is it and Why should I want it? ARIADNE 24. June 2000. [Web Page]. URL http://www.ariadne.ac.uk/issue24/interoperability/
Moen, W.E. (2001). Mapping the interoperability landscape for networked information retrieval. In Proceedings of First ACM/IEEE-CS Joint Conference on Digital Libraries, Roanoke, VA, June 24-28, 2001. pp. 50-52. [Web Page]. URL http://www.unt.edu/wmoen/publications/MapInteropJCDLFinal.pdf
National Defense. (2001). The DTD: A Guardian of Common Interests. [Web Page]. URL http://cals.debbs.ndhq.dnd.ca/cals/english/issue02/cals-e16.jsp
Norrick, N.R. (1998). Lecture Semantics. [Web Page]. URL http://www.uni-saarland.de/fak4/norrick/lectsem.htm
Notess, G.R. Search Engines by Search Features. [Web Page]. URL http://www.searchengineshowdown.com/features/byfeature.shtml
Palmér, M., Naeve, A., Nilsson, M. (2001), E-learning in the Semantic Age, In Proceedings of the 2nd European Web-based Learning Environments Conference (WBLE 2001), Lund, Sweden. [Web Page]. URL http://kmr.nada.kth.se/papers/SemanticWeb/e-Learning-in-The-SA.doc
Song, D.W. Wong, K.F. Bruza, P.D. Cheng, C.H. Towards a Commonsense Aboutness Theory for Information Retrieval Modelling. [Web Page]. URL http://www.dstc.edu.au/Research/Projects/Infoeco/publications/aboutness-sci00.pdf
Todd, R. J. (1992). Academic Indexing: What's it all About? The Indexer. 18 (2). pp. 101-104.
Varela, F., Thompson, E., & Rosch, E. (1991). The Embodied Mind; Cognitive Science and Human Experience. Cambridge, Mass: MIT Press.
Voltero, K. (2001). WebCT's Content Migration Utility. [Web Page]. URL http://www.imsproject.org/membersexchange/ME_WebCTContentMigration.pdf
XML.com (2001). DTD Repositories. [Web Page]. URL http://www.xml.com/pub/rg/DTD_Repositories