This paper addresses the interoperability problem consequence of the proliferation of online learning systems, mainly in Internet environments, which is being considered by key standardization
institutions and the most relevant educational software consumers worldwide. Up to this date, proposals are available for the standardization of information models, such as educational metadata or
course structures.
Our main objective is to contribute to this standardization process with an original proposal for a service architecture to build standard-driven distributed and interoperable learning systems. This
contribution is based on the definition of open software interfaces for each subsystem in the architecture, avoiding any dependency from specific information models.
To materialize our proposal, we have selected CORBA as the technological supporting infrastructure, defining a domain facility for e-learning. It provides the mechanisms whereby heterogeneous online
learning systems are able to interoperate and exchange learning objects at runtime. Our architecture includes learning object repositories, packaging management, cataloguing and searching
environments, learner administration and, of course, runtime environments for e-learning.
Standardization, Open Architectures, Interoperability, Learning Objects, CORBA
Advances in Information and Communication technologies, and specifically in Multimedia, Networking, and Software Engineering have promoted the apparition of a huge amount of learning resources. During the last years, thousands of electronic texts, images, movies, or Java applets have been developed for learning purposes in Internet environments.
To take advantage of this situation, new services were developed, and the search, classification, organization, and peer-to-peer exchange of learning resources by learners, instructors, and course developers are becoming commonplace. Metadata helps to carry out these tasks, and several specifications for learning objects were produced. Related to them, specialized search engines and indexing tools for learning were also made available.
However, to find the appropriate learning resource is not enough. The learning objects developed for a particular system may not be reusable in others. Formats for animations, videos, simulations, educational games, and multimedia are standards or well-known specifications, but to offer them to learners, these elements should be organized in a structured way, because they usually need to be processed by software tools prior to delivery. Additionally, information related to the interaction of learners with these contents should also be generated. Content structure formats maintain the static and dynamic structure of learning object aggregations. There are also specifications available for course packaging, to facilitate the transfer of courses among systems. In a similar way, it is necessary to manage information about learners, and their interaction with courses. All these elements have been considered by several international projects and most relevant standardization bodies. We have reviewed them, and a summary of this survey is included in section 2.
Also, the increasing use of the Internet and its technological capabilities, in addition to the huge amount of learning resources, allowed a high number of technology-based learning platforms to show up. As they are usually developed ad-hoc, to meet the requirements of a particular institution, heterogeneous systems appear with no interoperability mechanism among them. When these systems are reviewed, our conclusion is that they provide very similar functionalities: content delivery, learner tracking, learner management and administration, questionnaires evaluation, communication and collaboration facilities, search tools, etc. Therefore, we can state that most online learning systems share some common functionality, usually implemented from the scratch by each one of them. In this sense, software reuse would be a must to reduce the time-to-market factor.
On the other side, there is a lack of interoperability mechanisms among heterogeneous platforms. Such mechanisms would allow, for instance, that a particular online learning system would provide its own content delivery module, which uses a common learner administration system provided by an external institution and, maybe, developed by a different vendor.
The identification of a common architecture, composed of basic software components that provide open interfaces, would contribute to both reuse and interoperability. Standardization would be reflected here through the definition of agreed interfaces for these components.
Our work is mainly focused on this area. The second part of this paper, section 3, is devoted to the presentation of CORBAlearn, a proposal for a service architecture supporting the development of distributed, interoperable and standards-driven e-learning systems. As final products, within these learning applications we can distinguish two clearly separate aspects. On the one hand, we can identify the common services provided by CORBAlearn. On the other, we can recognize specific elements that the final application programmer must implement to provide the user interface and the particular functionalities (i.e. value-added services) of each concrete learning application. Section 4 discusses some examples of final applications that can be developed using the services provided by CORBAlearn. We will finish this paper with some conclusions in section 5.
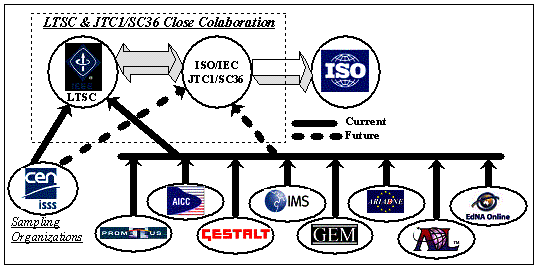
The e-learning standardization process is an active, continuously evolving process that will last for years to come, until a clear, precise, and generally accepted set of standards for educational-related systems is developed. Among the main contributors to this effort let us mention the IEEE's Learning Technology Standardization Committee (LTSC) [1], the IMS Global Learning Consortium [2], the Aviation Industry CBT Committee (AICC) [3], the US Department of Defense's Advanced Distributed Learning (ADL) initiative [4], and projects Alliance of Remote Instructional Authoring and Distribution Networks for Europe (ARIADNE) [5], Getting Educational Systems Talking Across Leading Edge Technologies (GESTALT) [6], PROmoting Multimedia access to Education and Training in EUropean Society (PROMETEUS) [7], European Committee for Standardization, Information Society Standardization System, Learning Technologies Workshop (CEN/ISSS/LT) [8], Gateway to Educational Materials (GEM) [9], and Education Network Australia (EdNA) [10]. The IEEE's LTSC is the institution that is actually gathering recommendations and proposals from other learning standardization institutions and projects (c.f. Figure 1). Specifications that have been approved by the IEEE go through a more rigorous process to become ANSI or ISO standards. In fact, an ISO/IEC JTC1 Standards Committee for Learning Technologies, SC36 [11], was approved in November 1999.
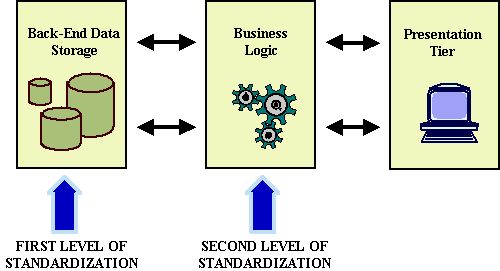
The outcomes of these standardization efforts can be identified into two levels:
Many Internet programmers develop their applications following a three-tier architectural style [12]. Persistent data is stored in the first level of this architecture, the back-end tier. The second level is the business logic tier. This one is responsible for managing data according to the expected functionality. Finally, the front-end or presentation tier supports the user interface. In terms of this architectural style, the first level of standardization presented above would provide standards for the back-end tier, while the second level of standardization deals with the business logic tier (c.f. Figure 2). There are also some recommendations for the presentation tier (e.g. user interface recommended icons by AICC [13]) although results here are less relevant. Main results from the first level are summarized in section 2.1. Outcomes from the second level are discussed in section 2.2. Section 2.3 discusses these works from the perspective of our proposal.
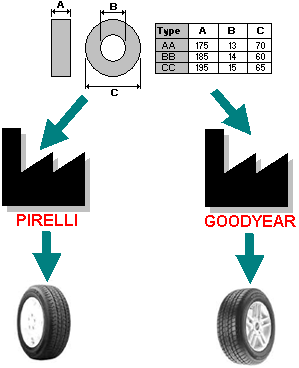
The more mature results correspond to this first level. In most cases, XML [14] is used to define supporting information models enabling interoperability in WWW settings. Standards at this level can be seen as common specifications that must be used by different vendors to produce learning objects. Figure 3 illustrates this concept using an example from the car manufacturing environment. In that setting, common specifications define standards to make, for example, tires for car wheels. As shown in the figure, the standard allows different vendors to produce tires that can be used by different cars. In the same way, common specifications for learning objects would allow their use by different educational software tools.
Relevant specifications at this level address:
A comprehensive survey on the e-learning standardization process can be found in [24].
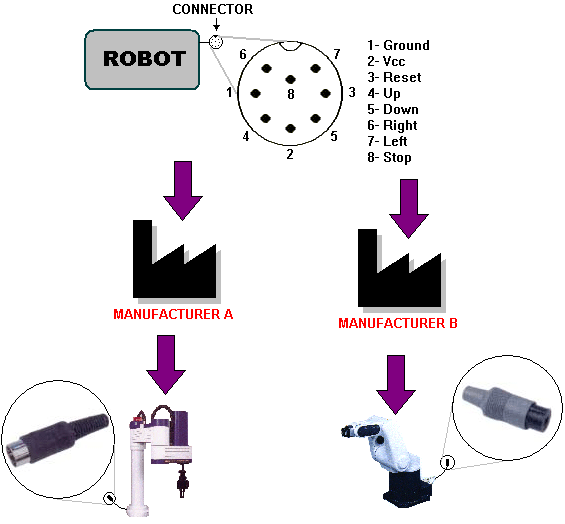
At this level, standards define the expected behavior of software components responsible for managing learning objects in online environments. Revisiting the car manufacturing example above, second level standards would specify the interface for the robots that assemble tires in a production line. These specifications let different manufacturers to produce robots with the same behavior (c.f. Figure 4). Performance may vary but the expected behavior as defined by the specification (top of the figure) must be implemented by different manufacturers' robots (bottom of the figure). Therefore, a production line could be composed of robots developed by different manufacturers provided they are compliant with the defined specification to support interoperability. In the same way, software interfaces for educational components would allow us to build new online learning systems avoiding their development from scratch, and also to provide interoperability among heterogeneous systems at runtime.
Up to this date, only some institutions have developed architectures that contain common components for a generic learning environment. With respect to management and administration, we can identify three major categories of systems:
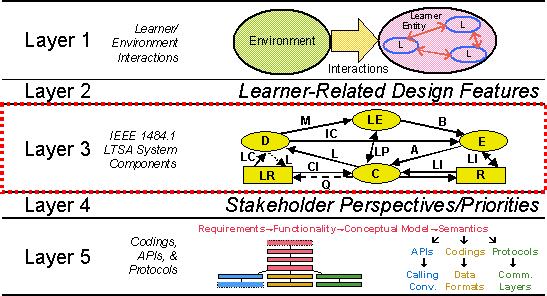
At this level of standardization, proposals to define such systems range from the specification of conceptual models to concrete interfaces for CMIs. The IEEE LTSC's Architecture and Reference Model working group delivered in November 2001 the 9th draft of the Learning Technology Systems Architecture (LTSA) [32]. The LTSA specification corresponds to a conceptual model applicable to a broad range of learning scenarios. It is pedagogically, content, culturally and platform neutral. Although five refinement layers are specified (c.f. Figure 5) only layer 3 is mandatory. This layer identifies the architecture components, comprising four processes, Deliverer (D), Learning Entity (LE), Evaluation (E) and Coach (C); and two stores, Learning Resources (LR) and Learner Records (R).
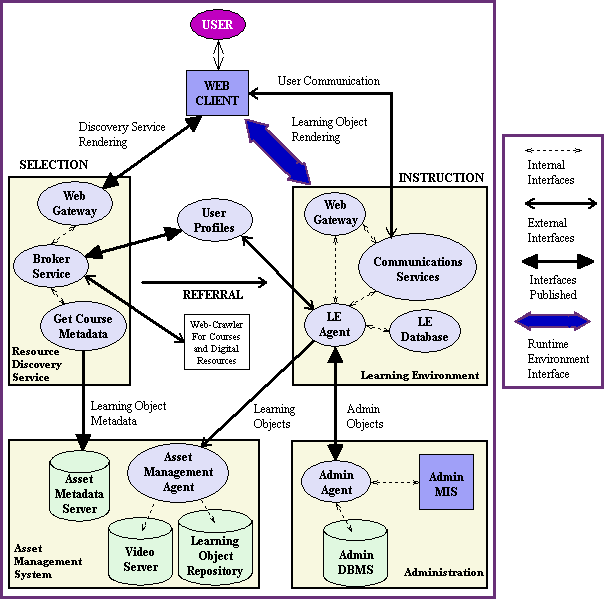
There are two main proposals for concrete software architectures and components in a distributed e-learning system. The more elaborated one comes from the GESTALT project [33], which identifies a system architecture for online learning platforms based on a functional architecture and a reference business model. The GESTALT proposal is based on and integrates components from previous ACTS projects [34] GAIA, Renaissance and Prospect. The system architecture comprises a learning environment, an administration system, an asset management system, a service for user profiles, and a resource discovery service. Business objects comprising the interfaces among the various software components within the GESTALT architecture are also identified.
In the US, the IMS project started in 1997 defining a system model and architecture for learning environments. They abandoned this work very soon, as they considered of prior interest the development of data and information models to be managed by such architectures. In fact, although its work in architectures has not been resumed at the time of writing this paper, the IMS project has been a very active member at the first level of the e-learning standardization process (c.f. section 2.1).
A critical component inside a learning system is the runtime environment, responsible for delivering learning objects to students and tracking their progress. In the past, authoring systems made the customer a captive of his own delivery system. Many times, it was very difficult or even impossible to transfer learning objects created for a particular delivery platform to another one. To avoid this dependency, there should be provided a common way to initiate contents and to communicate them to the delivery and management system through a standardized data model. The US Department of Defense's ADL initiative has defined a Runtime Environment [21] directly based on the "AICC CMI Guidelines for Interoperability" specification [20] as part of its SCORM model. The ADL Run Time Environment includes a specific launch protocol to initiate learning objects, an Application Programming Interface (API), and a data model defining the communication at run-time between a learning object and its management software component.
The projects introduced above are directly related to the work proposed as the main contribution of this paper. However, they do not cover the stated objectives at the second level of the e-learning standardization:
From the previous section we can conclude that the first level of standardization has already produced mature specifications, and some proposals are considered de-facto standards (e.g. LOM metadata specification). However, results at the second level have been scarce so far. There is still a lot of work to be done to provide suitable standards for the business logic tier.
Our purpose is to contribute to this second level of standardization by the identification of common services for e-learning that will be supported by a Reference Architecture. This architecture will be composed of reusable software components with open and clearly identified interfaces. All interfaces in the architecture define their externally visible properties to facilitate the development of distributed, interoperable, and standards-driven online learning environments.
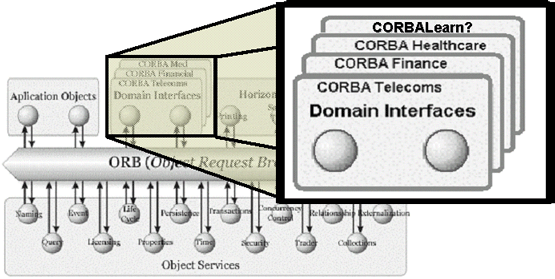
As a part of our contribution, we propose a concrete instance of the Reference Architecture for a particular implementation. The selected technology is CORBA [35], an object-based distributed architecture that allows distributed and heterogeneous applications to interoperate on a network. CORBA is a standard defined by more than 800 institutions that form the Object Management Group (OMG) [36]. Over a software bus, the Object Request Broker (ORB), CORBA objects interact with each other via standard contracts written in the Interface Definition Language (IDL). The OMG has also defined the interfaces for 17 basic services for distributed computing [37]. Nowadays, one of the key activities is the definition of higher level services, clearly oriented to a particular business domain: domain CORBA facilities. Already available domain facilities [38] are targeted to domains like Telecommunications, Manufacturing, Finance or Healthcare (c.f. Figure 7). They identify the objects needed, and their interfaces, in those domains to cover the needs of a wide range of requirements. Different vendors may change the implementation, but the offered functionality is basically the same thanks to the agreed interfaces.
Thus, CORBA domain facilities contribute to the interoperability among systems. At the time of this writing there is no domain facility for e-learning. In addition, the OMG is an open consortium with no ties to particular software platforms or programming languages. Eventually, CORBA objects can communicate through Internet using the IIOP protocol. For all these reasons, we chose CORBA as our middleware framework among other available options (e.g. DCOM or Java RMI). Our Reference Architecture will be put into practice through the proposal of a new domain CORBA facility for e-learning: CORBAlearn.
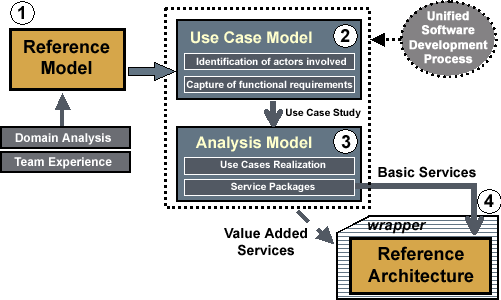
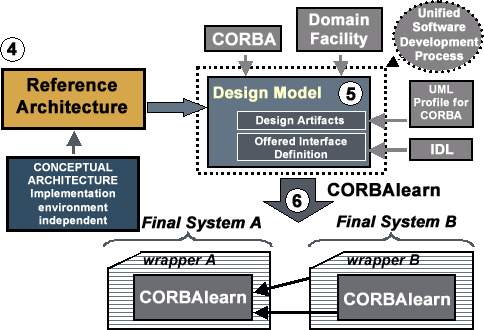
Services supported by the Reference Architecture and eventually provided by CORBAlearn are the consequence of the application of an appropriate design methodology. This methodology, which can be seen as a side contribution of this paper, is devoted to the definition of service architectures starting from user requirements. It is based on the Unified Software Development Process [39] together with the recommendations by other authors [12]. The Unified Process' aim is to obtain a final product. On the other side, our aim is to define a service architecture to build final applications upon it. For this, we adapted the Unified Process to serve our needs. We included a Reference Model as an initial stage and defined a Reference Architecture as an intermediate stage. The overall process is illustrated in Figures 8 and 9. Modeling was made using the Unified Modeling Language (UML) [40] and its profile for CORBA [41].
The Unified Software Development Process is an iterative and incremental process, based on the architecture and driven by use cases. Basically, its foundation is an identification of the functionalities that must be provided to the users. Then, analysis and design models are developed to provide the functionality required.
First, we identified a business model for the e-learning domain. This model corresponds to the Reference Model presented by Bass [12] and describes the key agents participating in the e-learning process (section 3.2) identifying the data flows among them (step 1). The Reference Model is derived from an analysis of the e-learning domain [42][43], a survey of the main proposals made by the institutions involved in the e-learning standardization process [24], and previous authors' experiences [44][45][46][47].
Once we have obtained a Reference Model, we proceed to functional requirements capture using artifacts from the Unified Process (step 2). This task is performed from use cases, considering the most common functional aspects in e-learning systems. Note that the eventually defined software services should be as general as possible, and therefore suitable for most learning tools. From the domain analysis, we concluded that different e-learning systems define different sets of actors, although some actors appear in practically all relevant systems (e.g. learner, tutor). Additionally, some contributions to the e-learning standardization process address the identification of relevant actors and their responsibilities within e-learning systems. After a thorough analysis, we decided to use for functional requirements capture the actors defined by the ERILE [48] specification. In other words, for each of the elements in the Reference Model we extracted the relevant requirements assuming the actors in ERILE were the target users.
The Use Case Model reflects requirements capture from the actors' perspective. Along a next analysis phase (step 3) we will study and further investigate these requirements from the perspective of the designers and developers responsible for building compliant systems. This lets us further understand system requirements as a first step towards a stable architecture. Responsibilities are assigned to analysis objects to assure that all user requirements are fulfilled by collaborations among analysis objects. The analysis model will serve as the basis to define a Reference Architecture [12]. For this, those analysis classes that have been assigned fundamental responsibilities to build final systems or to encapsulate information models from the first level of standardization are assigned to service packages.
Service packages are the foundation of a Reference Architecture for standards-driven e-learning systems (step 4). The Reference Architecture is a decomposition of the Reference Model into a set of components that provide the functionality identified along previous stages (steps 2 and 3). Note that, in a general sense, our objective is the definition of a set of services to facilitate and speed up the development of standardized, distributed and interoperable e-learning systems. Thus, we will only include in the service packages determining our architecture those analysis classes offering basic, common services. Additionally, the selected classes should be reusable and independent from specific learning domains or specific value-added services. Specific subsystems in the architecture should be implemented in an integral manner. In fact, these subsystems model class groupings that typically evolve together. Those analysis classes that are too application-dependent or represent value-added services will be assigned to the wrapper. Final applications demanded and used by the actors in the use case model will be composed by the defined service packages and analysis classes external to them. As in other standardized fields, external components (i.e. external analysis classes) will provide specific features and value-added services that characterize individual, may be competing learning systems. In other words, this external wrapping will provide a differentiation among proposals from distinct developers and institutions.
As the Reference Architecture includes only classes from the analysis model, it is implementation independent and purely conceptual. In the design stage (step 5, see Figure 9) we state our implementation environment. Here, each design artifact was elaborated taking in mind that CORBA was our selected implementation technology. Models at this step use the UML profile for CORBA. Also, as our final objective is to propose a domain facility, we focused on the design and definition of those interfaces provided by the design subsystems. Interface definition was made using IDL, and was thoroughly documented, as it is the core for any business logic-centered specification (c.f. Figure 2 and 4).
Thus, this proposal is materialized as a CORBA domain facility for e-learning: CORBAlearn (step 6). CORBAlearn is a specification, as it is the LOM specification for metadata; where CORBA was chosen as the implementation/deployment environment, as XML provides a concrete representation for LOM. Services offered by CORBAlearn are used by developers of final e-learning platforms, who would add a wrapper that makes use of them and adds application-specific value-added services to differentiate systems from different vendors (see bottom of Figure 9). Also, the core provided by CORBAlearn, whose specifications would be published in the framework offered by the OMG and its domain facilities, would support interoperability among heterogeneous platforms.
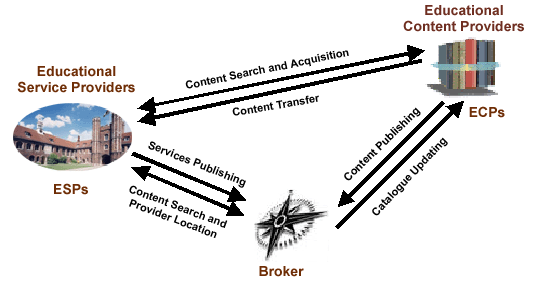
As discussed above, the Reference Model is obtained from an analysis of the domain and previous authors' experiences. We have identified three elements in a Reference Model for e-learning (c.f. Figure 10). Educational Content Providers (ECPs) are responsible for developing learning objects. They are equivalent to publishers in conventional education. Educational Service Providers (ESPs) are the schools, universities, or academic institutions in these virtual environments. They are responsible for offering high-quality online learning environments. ESPs use ECPs to access, maybe under payment, online courses to be offered at their institutions. This could be done directly or indirectly, using a Broker, which is the third party involved. Brokers are responsible for helping both learners and ESPs to find suitable learning resources: learners will use Broker services to find and locate those institutions (ESPs) that offer courses they are interested in; ESPs will use Broker services to find learning resources offered by the ECPs to enrich their catalogues. To offer these services, Brokers must maintain metadata information about courses offered by associated ESPs and ECPs.
The Reference Architecture is a decomposition of the Reference Model, reflecting all components implementing the functionality identified in steps 2 and 3 of the proposed methodology (c.f. section 3.1), together with the corresponding data flows. Basic functional requirements are fulfilled by the Reference Architecture, whereas others, qualified as "value-added services", are assigned to the wrapper (c.f. Figure 8). The Reference Architecture is obtained from a detailed analysis of the functional requirements, and includes further specific requirements identified along this analysis process. Elements in the Reference Architecture are identified from loosely coupled service analysis class packages, which in turn are composed by tightly coupled objects. The proposed Reference Architecture [12] is a service architecture enabling component reuse. This is the main reason to adopt as the building blocks of the Reference Architecture the service packages identified along the process described in section 3.1. A further insight into the methodological approach to obtain this architecture can be found in [49].
Figure 11 outlines the proposed Reference Architecture, including the Reference Model decomposition into Reference Architecture elements and the analysis package each service package belongs to. We will briefly introduce its aims along the next paragraphs.
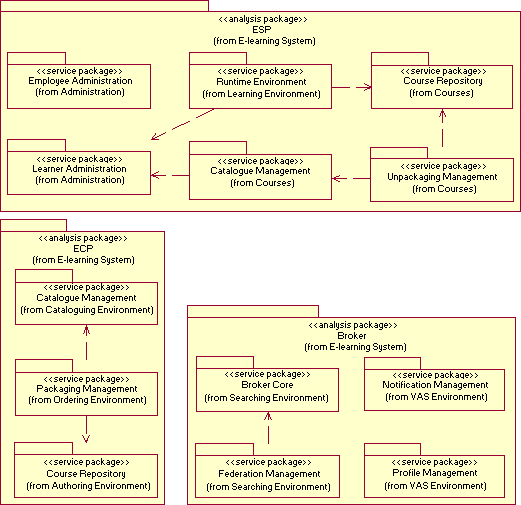
We identified six subsystems for the ESP Reference Architecture:
In our model, ECPs are built from three different subsystems:
Brokers that intermediate between ECPs and ESPs or between ESPs and Learners are developed from basic services offered by four subsystems:
The basic properties of this Reference Architecture are:
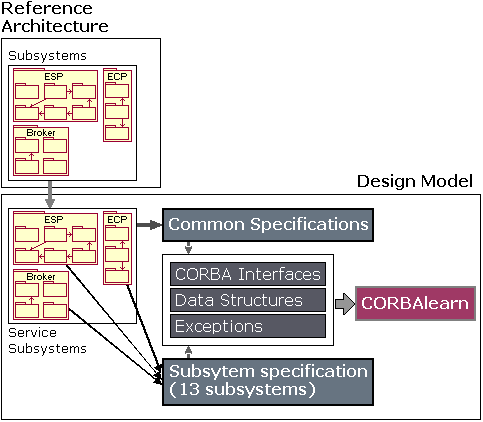
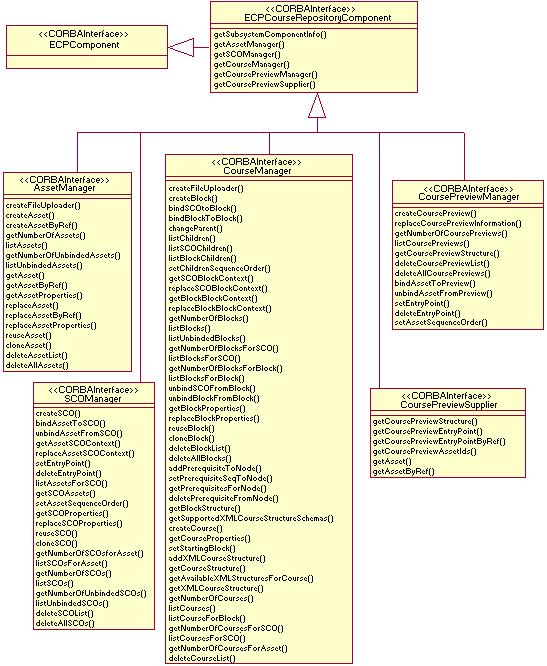
The elements defined in the design model are the design counterparts of the more conceptual elements defined in the analysis model, in the sense that the former are adapted to the implementation environment, whereas the latter (analysis) elements are not. In other words, the design model is implementation-oriented in nature, whereas the analysis model is more conceptual. From the Reference Architecture elements we derive a set of design service subsystems (c.f. Figure 12). Reference Architecture subsystems have been assigned with specific responsibilities. Along design, service subsystems will materialize these responsibilities in a concrete programming language or, as in our case, interface definition language. At this stage, we selected CORBA and the framework provided by the CORBA domain facilities as the implementation environment. Each service subsystem is defined using a separate specification where service interfaces, data structures and exceptions are included. There is also a set of common specifications, horizontal to the whole domain facility. Together, they form our proposal for a new CORBA domain facility for e-learning: CORBAlearn. The whole set of specifications (for the three elements in the Reference Model) includes 69 service interfaces and a total of 888 method definitions. Let us recall here that, as our aim is to propose a domain facility, we focused on interface definition. Products from different vendors may provide different performances, but their functionality must be the same if they claim to be compliant with the interface.
CORBAlearn covers all aspects in a distributed e-learning system identified by the Reference Architecture. Each of them is supported by a different specification of the CORBAlearn domain facility. For the sake of brevity, we just present here part of the static and dynamic view of the software architecture and its object IDL interfaces. We encourage the reader to request the whole set of specifications [52] to the authors.
Common specifications include the definition of data structures and service interfaces useful in several subsystems. Among others, we have specified a set of generic IDL structures (c.f. Figure 13) to encapsulate information models following a tree-like structure (e.g. like XML or DOM documents). Therefore, we provide a straightforward mechanism to use those proposals from the first level of standardization, as most of them use XML as the data definition format. On the other side, there are no bindings to particular proposals for information models. These structures are generic enough to encapsulate different alternatives.
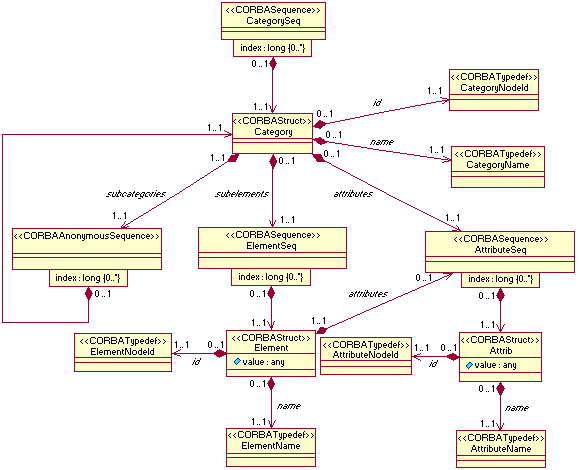
Figure 14 shows some of the interfaces included in the CORBAlearn Runtime Environment subsystem. Note that the figure only presents method definitions but not the parameters for each of them. The purpose of these interfaces is to support interoperability for runtime environments. As a result, developers of final e-learning systems are freed from common design tasks, like learning object delivery, student tracking or evaluation. Service interfaces presented in the figure are:
Other available service interfaces in this subsystem deal with storage and management of runtime data models, and support the development of supervision and tracking tools for tutors and teachers responsible for monitoring students.
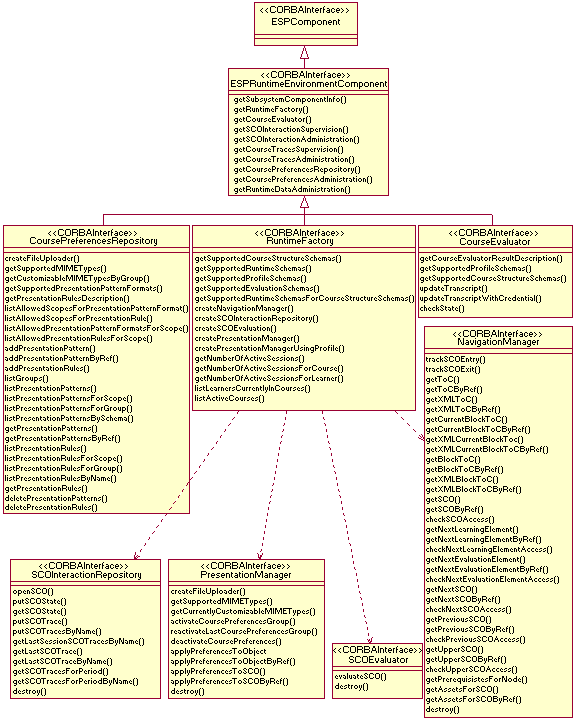
For this paper, we have selected the CourseRepository subsystem interfaces as the representative for the ECP specifications. The overall purpose of these interfaces is to facilitate the development, management and storage of learning objects in different aggregation levels: assets, learning objects as its most basic form (text, images, Java applets, sound files, etc.); SCOs, a set of assets that forms the smallest indivisible learning object that can be delivered to a student (e.g. an Web page containing an HTML file, several images, sound files and movies); and courses as the structured collection of SCOs with an associated dynamic behavior (course structure). We have defined five service interfaces (c.f. Figure 15):
>From the services provided by products compliant with these interfaces, less effort would be required to develop a final Web-based authoring tool. Most of the work would be to develop an appropriate user interface (which would belong to the wrapper), as management and learning object organization is dealt by the CORBAlearn facility.
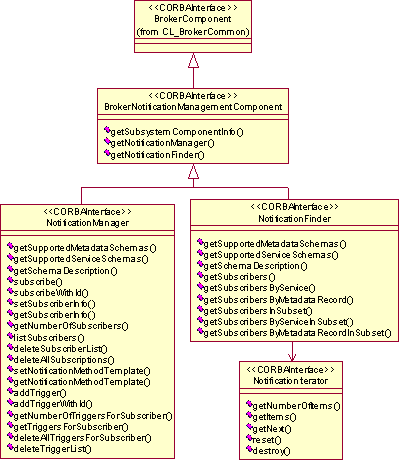
As example for the Broker, Figure 16 shows the interfaces that describe the CORBAlearn Notification Management specification. The main interfaces are Notification Manager and Notification Finder. Both of them provide introspection methods to discover the formats for resource description (i.e. metadata), and service descriptions supported by the implementation of each one of them.
Along the previous section we discussed the development of the CORBAlearn domain facility. Specifications provided as IDL interfaces contribute to the e-learning standardization at the business logic tier. Different vendors claiming compliance with this specification would offer products that provide the services defined in these interfaces. Over these basic services, developers of final applications build the wrapper, (c.f. Figure 9) where user interfaces are embedded and additional value-added services may be included.
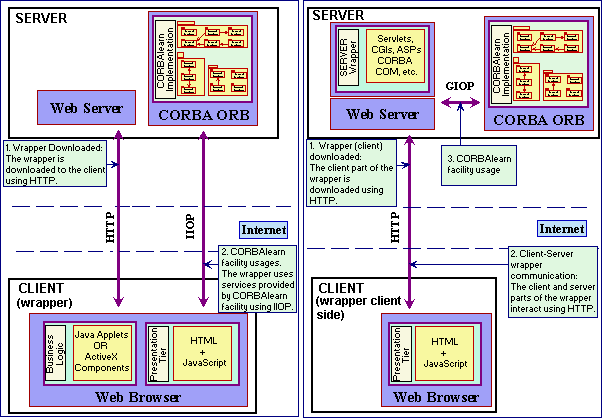
There is no restriction in terms of wrapper technology. The only assumption is that it is able to use CORBAlearn services through a CORBA software bus, which may be accessed from most WWW browsers. Also, the wrapper may be distributed among the server and client, or may be totally embedded in the client. Figure 17 shows two different scenarios for a final system implemented in a WWW setting using CORBAlearn facilities.
On the right side of the figure, we assume that the wrapper is distributed between server and client. The client side of the wrapper provides the presentation tier (i.e. user interfaces) from where commands are sent to the server side of the wrapper. The latter uses CORBAlearn facilities to implement basic commands and, probably, it also may encapsulate some other additional features.
On the left side of the figure, the whole wrapper is downloaded to the client, both the presentation tier and the business logic implemented by the wrapper. HTTP is used for downloading, while Internet Inter ORB Protocol (IIOP) is used to access CORBA objects for subsequent accesses to CORBAlearn services.
At the time of this writing, the whole set of CORBAlearn specifications have been implemented and tested from a Web-based wrapper following the approach shown in the right side of Figure 17. As an example of the CORBAlearn usability, we briefly describe along the next paragraphs how a product compliant with the RuntimeEnvironment specification can provide (CORBAlearn-compliant) WWW-based content delivery and tracking tools.
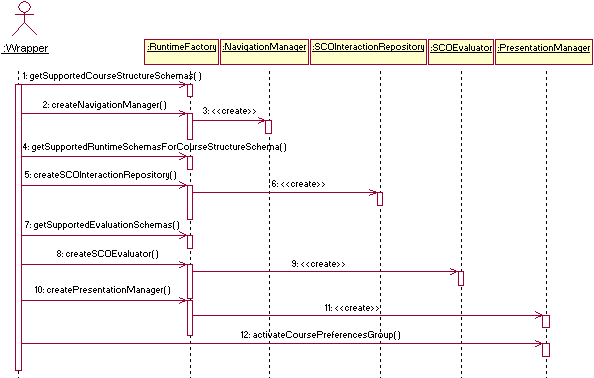
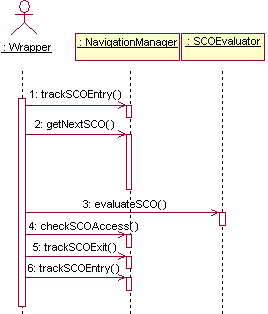
First, developers take advantage of the different services needed for each active learning session using objects created by the Runtime Factory. Figure 18 shows a sequence diagram with the steps the wrapper must follow to activate all needed objects. Steps 1, 4 and 7 represent calls to the introspection methods used to discover the actual information models coming from the first level of standardization that this particular implementation of CORBAlearn is able to deal with.
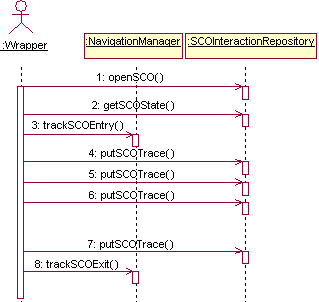
Among the features this subsystem offers to the wrapper we can mention:
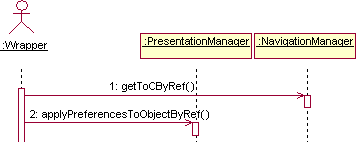
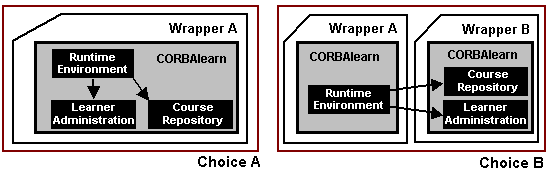
As identified by the Reference Architecture, c.f. section 3.3, the RuntimeEnvironment subsystem depends on the services provided by other fundamental subsystems in the ESP, namely CourseRepository and LearnerAdministration (c.f. Figure 24). The first one is needed to access the learning objects that must be sent to the learners, and to access static structure and dynamic behavior for those contents. The second one is needed for accessing Learner preferences and forupdating Learner transcripts when he or she masters the contents. These subsystems can be part of the same ESP as the RuntimeEnvironment (left side of Figure 24) or may be distributed in different, and possibly developed by different vendors, heterogeneous e-learning systems (ESPs). As for the car manufacturing example (c.f. Figure 4), interoperability is guaranteed as these subsystems provide the same interface regardless the vendor that developed them: CORBAlearn interfaces.
The first part of this paper discusses the current state of the e-learning standardization process. While the first level of standardization, which deals with specifications for information models, is mature enough with some de-facto standards available, the second level, which deals with definition of architectures and software interfaces, is still in its infancy and there is a lot of work to do.
In this line, this paper contributes to the e-learning standardization at the second level, defining a Reference Architecture and particular interface specifications for the business logic tier of a distributed online education environment.
The Reference Architecture proposed is conceptual and implementation independent, and may be instantiated for different technological infrastructures. It is composed of a set of reusable subsystems that provide fundamental services to build final applications. Defined services are the consequence of the strict application of a systematic methodology to obtain service architectures. Components defined can be easily identified by those agents involved in the e-learning standardization process, as they encapsulate different standardized information models in separate subsystems. This property, together with the separation of functional requirements, makes our architecture oriented to local changes, and able to support the development of new systems in a scalable way.
It can be argued that this approach is too business process oriented, and results may be manifestly different if the process where based on a learner-centric approach. However, the foundation of the methodological process leading to CORBAlearn is based on use cases from relevant actors, the learner being one of them, perhaps the most important as the eventual objective of any learning initiative. This approach guarantees that the learner’s perspective is taken into account along the process in an integral manner, taking into account other actors’ needs.
Additionally, there are other relevant proposals that are more pedagogically driven, which in this aspect complement the stance supported in this paper. In [53], the Open Knowledge Initiative from Stanford University proposes an API-based infrastructure for educational application development and support that is learner-centered in conception. As another example, the approach from the Learning Systems Architecture Lab in Carnegie Mellon [54] advocates for an architecture for user-centric learning management systems, aimed to a virtual university.
Concrete software interfaces are defined as a proposal for a new domain CORBA facility for e-learning: CORBAlearn. CORBAlearn includes the definition of data structures to encapsulate outcomes from the first level of standardization, exceptions and service interfaces, which are distributed among 13 different specifications that cover the whole spectrum of functionalities included in full-fledged e-learning environments. Open publication of these interfaces within the OMG framework will assure interoperability among products developed by different vendors, provided they are built over CORBAlearn-compliant products. Also, software reuse is promoted as new systems can be built over components offering the basic and fundamental services defined by the CORBAlearn specifications. CORBAlearn specifications are compatible with current available standards for the first level of standardization. Information models defined by standards at that level are properly managed and transferred using CORBAlearn-compliant products, with no tie to any specific proposal. Therefore, this contribution to the second level in the e-learning standardization process supports both reuse and interoperability, not only at the back end, but also at the business logic tier.
Luis E. Anido-Rifón received the Telecommunication Engineering (1997) degree from the University of Vigo with Honors by the Spanish Department of Science and Education and by the Galician Regional Government. He has been also awarded by the Galician Royal Academy of Sciences. He joined the Telecommunication Engineering faculty of the University of Vigo where he is working towards his PhD. His main interests are in the field of New Information Technologies applied to distance learning and in the area of Object-oriented distributed systems. Actually, he participates in two CEN Workshops devoted to LOM internationalization and to the definition of learn-related vocabularies and taxonomies, respectively.
Juan M. Santos-Gago is a Telecommunication Engineer (1998). He has been involved in several projects related to distance learning and e-commerce. Now, he is Assistant Professor at the University of Vigo.
Judith S. Ródríguez-Estévez received her Telecommunication Engineering (1999) degree from the University of Vigo. In addition to teaching, her main interests are in the Educational Metadata and Information Retrieval.
Manuel Caeiro-Rodríguez received the Telecommunication Engineering (1999) degree from the University of Vigo. Currently, he teaches Computer Architecture and Software Engineering at the Telecommunication School where he is working towards his PhD.
Manuel J. Fernández-Iglesias graduated from the University of Santiago de Compostela, Spain, with a Telecommunication Engineering degree in 1990, and from University of Vigo with a Doctor in Telecommunication degree in 1997. He is actively involved in researching in the area of multimedia applications, Computer Based Training and Formal Description Techniques.
Martín Llamas-Nistal received the Telecommunication Engineering (1986) and Doctor in Telecommunications (1994) degrees from the Technical University of Madrid, Spain. He is the head of the GIST research group and New Technologies Division at the University of Vigo.