Knowledge Construction With Visual Representations Of Distributed Information
Daniel A. Kauwell, James Levin, Young Jin Lee , Hwan Jo Yu
University of Illinois at Urbana-Champaign, USA
{kauwell@uiuc.edu, j-levin@uiuc.edu, ylee12@uiuc.edu, hwanjoyu@uiuc.edu}
"The difficulty seems to be, not so much that we publish unduly in view of the extent and variety of present day interests, but rather that publication has been extended far beyond our present ability to make real use of the record. The summation of human experience is being expanded at a prodigious rate, and the means we use for threading through the consequent maze to the momentarily important item is the same as was used in the days of square-rigged ships." Vannevar Bush, 1945 [ 1]
Vannevar Bush's visionary words are more poignant today than they were in 1945. Since he penned these words the explosion of information has been unprecedented in human history and, the Internet has fanned the flames of the ensuing fire. There is too much information available for individuals to keep up with, leading to ever narrowing job specialization. This makes it more difficult for individuals to keep up with related information that may be useful to them. It is difficult to locate needed information and once found, to make sense of it all and archive it in ways that make it accessible over time. Once information is found, analyzed, and archived, we need better ways of sharing it with others.
Bush was concerned with the problem of "keeping up" with all of the research pertinent to one's field, in a time when journals and presentations were the main source of scientific information dissemination. Not only has that problem grown with the increased number of journals, conferences and symposia but also, we now have increased venues of information. Those who often have little or no training in search techniques conduct Internet searches amidst this engulfing volume of data, news and lore. Research on information retrieval shows that most well formulated queries involve multiple search terms and relatively sophisticated query logic [ 2, 3] yet most Internet searchers employee simplistic one or two word queries [4 ]. Furthermore, even well trained searchers are limited by the inadequacies of search engines, and can formulate search queries that may return thousands or even hundreds of thousands of 'hits' [5]. Unfortunately, this problem seems to be growing. Recent research indicates that there are in excess of one billion pages on the Internet [6 ] and that at best, any one search engine may cover only 16% of the Internet [7].
Generally speaking there are several methodologies that dominate attempts to better catalog, search, and deliver information found on the Internet. These methodologies include the development of better algorithms for the indexing and categorization of pages but, these attempts often boil down to attempts to better understand and process natural language. Others seek to bring order to the Web through implementation of mark up languages but, this is dependent on all who have put information or will put information on the Web adhering to standards and conventions yet to be developed. Some are implementing innovative new search algorithms which utilize the "structural nature of the web" (http://www.google.com/). However, just because many people link to a site (i.e., amazon.com or microsoft.com) does not necessarily mean it is the best or most authoritative on a given subject and since the overwhelming majority of sites are ".com" sites, it is likely that over time they may dominate these types of algorithms.
Even if improved search techniques can be developed, the presentation of search results is problematic [4, 8]. Search results appear as lengthy lists of text and links, in a traditional linear format. Often, the development of search engines and their interfaces are technology driven and lack user centered design to enhance our ability to process information [4, 5, 9, 10 ]. Linear displays of information and list-based archives do not map well onto the user's representations or mental models of the Web [8]. Users have many different representations of the Web [11] and most views of the Web usually have a spatial quality (highway, spider web, etc.) not well represented by the lists returned from search engines and indexes. Furthermore, linear displays do not provide cognitive assistance, since they contain few perceptual clues to help in the process of finding information [9 ], nor do they assist in navigation.
To begin to address the problems listed above, we have developed a tool that applies visualization techniques to Internet-based information (VisIT). Instead of lengthy lists of search results, VisIT (Visualization of Information Tool) presents the user with a graphical, spatial representation of the search space where each Web site is represented and all of the hits returned are clustered within that site representation. Now the user can "see" the hits returned by the search engine and other pages at the site and when any of the pages are clicked on the appropriate page is displayed in the browser window (Figure 1). Searchers query multiple search engines simultaneously to construct a search space and heuristic based rules augment search engine relevancy rankings. Upon placing the cursor over any page, a pop-up box appears with search engine comments (if any) and the first 'n' characters of text found on the page (Figure 2). Users can scan text from the page in this manner and they can make a more informed decision as to which pages to explore further by clicking on them. This interface allows users too not only quickly scan hundred of hits at once but numerous perceptual cues are added to convey more information as well. Arrows are drawn that show which pages in the search space are referencing other pages, the color intensity of pages indicate relevancy weighting, visited pages are marked to enhance navigation, etc.
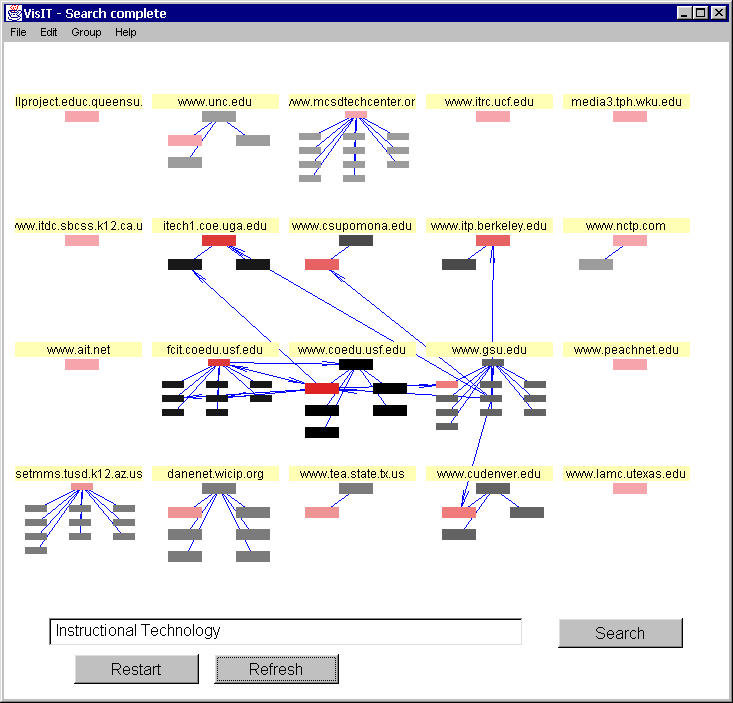
Figure 1. Initial Search Space in VisIT
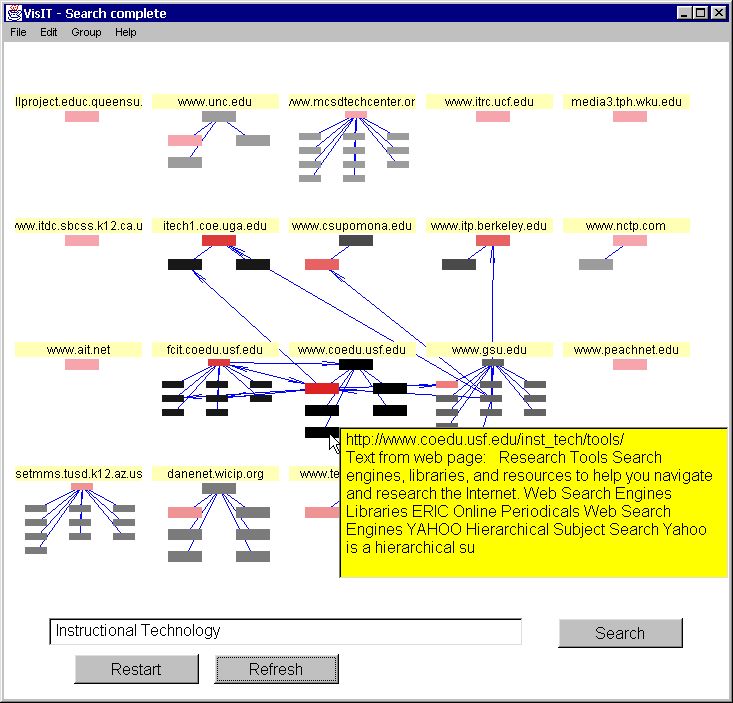
Figure 2. Pop-Up Box With Text From Page
Once information is found we need better ways to assimilate it into our existing knowledge structures and as mentioned above, graphical representations can help with this process. To facilitate, VisIT's graphical displays can be saved, and reopened later. Users can edit the search space by deleting sites, grouping sites, making annotations on pages, labeling sites and more (Figure 3). In this manner users can begin to construct a "knowledge space" from their search space, one in which they have taken information from various sources and constructed meaningful external representation or cognitive artifacts [12]. VisIT is written entirely in Java, utilizes a client server architecture and will be demonstrated during this poster session. We will also be discussing collaborative versions of VisIT in which search spaces can be shared between users or groups of users.
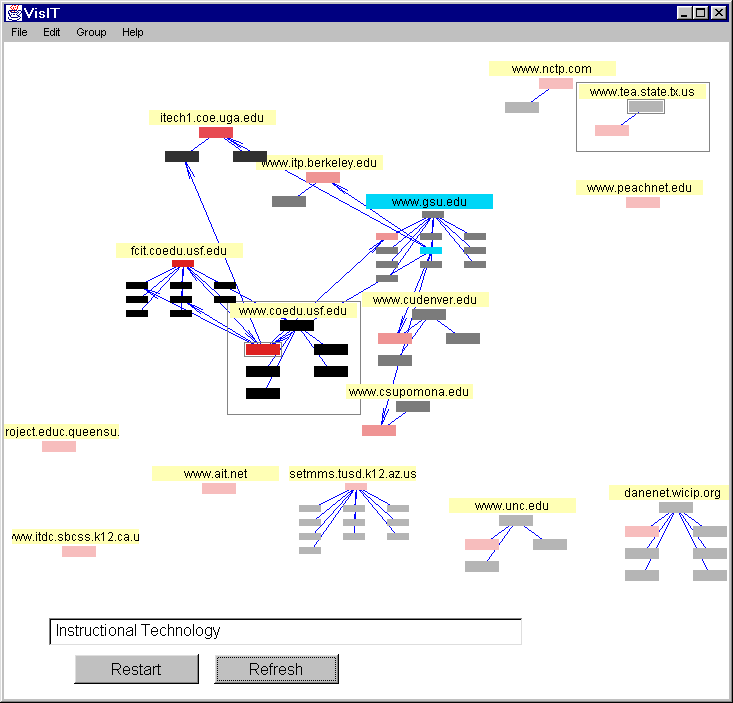
Figure 3. Search Space After User Modification
For more information on VisIT see http://visit1.vp.uiuc.edu/
This research has been funded by a grant from Yamaha Motor Co. LTD
References
- V. Bush, "As We May Think," The Atlantic Monthly, vol. 176, pp. 101-108, 1945.
- R. Korfhage, Information Storage and Retrieval: Wiley, 1997.
- C. Meadow, Text Retrieval Information Systems: Academic Press, 1992.
- A. Spink, J. Bateman, and B. J. Jansen, "Searching the Web: a survey of EXCITE users," Internet Research, vol. 9, pp.117-128, 1999.
- A. Spink, J. Bateman, and B. J. Jansen, "Searching heterogeneous collections on the Web: behavior of Excite users.," Information Research, vol. 4, 1998.
- Inktomi and I. NEC Research Institute, "Inktomi WebMap," http://www.inktomi.com/webmap/, 2000.
- S. Lawrence and C. L. Giles, "Accessibility of information on the web," Nature, vol. 400, pp. 107-109, 1999.
- J. Nielsen, "User interface directions for the Web," Communications of the ACM, vol. 42, pp. 65-72, 1999.
- X. Lin, "Map displays for information retrieval," Journal of the American Society For Information Science, vol. 48, pp.40-54, 1997.
- G. Marchionini and A. Komlodi, "Design of interfaces for information seeking," ANNUAL REVIEW OF INFORMATION SCIENCE AND TECHNOLOGY, vol. v33, pp. 89-130, 1998.
- J. A. Levin, M. J. Stuve, and M. J. Jacobson, "Teachers' conceptions of the Internet and the World Wide Web: A Representational Toolkit as a model of expertise," Journal of Educational Computing Research, vol. 21, pp. 1-23, 1999.
- D. A. Norman, "Cognitive Artifacts," in Designing interaction: Psychology of the human-computer Interface, vol. 4, Cambridge series on human-computer interaction,, J. M. Carroll, Ed. Cambridge, England UK: Cambridge University, 1991, pp. 17-38.