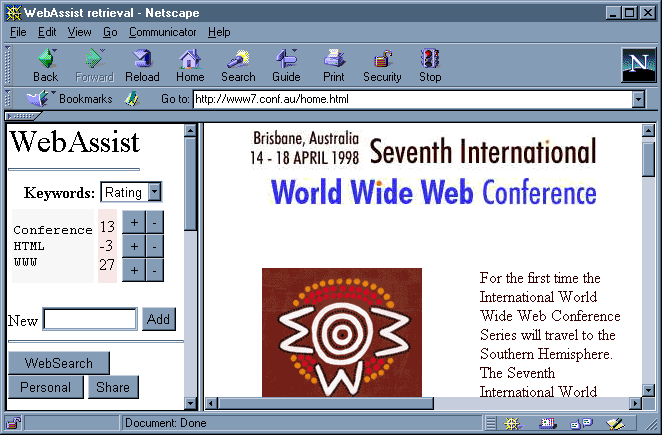
Fig. 1. Screenshot of a WebAssist classified page.
University of Erlangen, Erlangen, Germany
cnkurzke@cip.informatik.uni-erlangen.de,
endc01@rrze.uni-erlangen.de and
mdbathel@cip.informatik.uni-erlangen.de
The focus of the WebAssist project is to pre-classify and filter information based on user profiles database which is automatically created by tracing user activities when browsing the Web.
When a user joins the WebAssist system by using the WebAssist proxy, the keywords (determined from META statements within the HTML code) of all Web pages read are collected within the database. Other information about Web documents like request or keyword frequencies, time of last visit and modification time are also stored in the database as they are evaluated over time.
After startup time, a huge set of keywords and URLs has been collected and can assist the user in information retrieval. In this phase, the user can also benefit from profiles of other users working on the same project. The resulting URLs will be classified, compared to the user profiles and added to the database.
Besides supporting the user in information retrieval tasks, the WebAssist also helps to maintain personal and group wide hotlists of relevant URLs. New URLs can be made available to all users dependent on the assigned permissions. This greatly simplifies the communication between project members.
Based on this database, automatic tasks like checking for modification can be done periodically, depending on flags associated with the URL.
It is also possible to think of completely automatic information retrieval using the system, based on the set of acquired keywords. These database updates can be accomplished after business hours or during idle times.
Another aproach to increase the accuracy of the database would be using sophisticated mechanisms to generate new relevant keywords, not only from meta statements, but to extract them from the document text as proven to be possible in other studies.
A very close look has to be taken concerning data protection and user privacy. Since WebAssist scans the whole traffic of a user surfing the Internet, the databases offer a deep insight in the user's interest profiles.
Here a way has to be found to secure their privacy, even from the system administrator. This could be achieved by encrypting the database entries.
Still, with the current concept, WebAssist can increase the productivity of working groups, collaborating on projects.