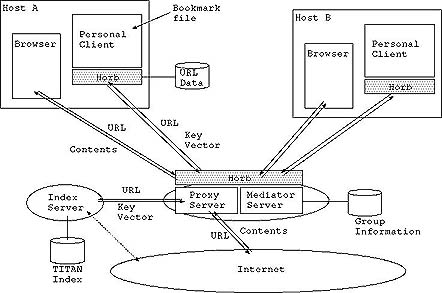
Fig. 1. System architecture.
NTT Information and Communication Systems Labs.,
1-1 Hikarinooka Yokosuka-Shi Kanagawa, 239-0847, Japan
First, it constructs a personal client (hereafter, simply client) that displays user interests; that is, it analyzes information users stores in their browsers' bookmark. We regard the information in the bookmark as user interests. If users classify the URLs (Uniform Resource Locators) to make use of folders in their bookmark, the system regards information in the same folder as the same interest group. The group is named using label of the folders in the users' bookmark. After getting this initial information, it extracts feature terms according to frequency of appearance from each URL, which are important words other than stop-words, and it calculates similarities between URLs by the measure `tf*idf'[3]. Inverted document frequency (idf) is calculated approximately using the `Index Server' which stores many URLs that gathered by the Internet-Robot. Finally, it arranges these URLs in the client according to the similarity.
If the user accesses a new URL on the Internet through the proxy server, the system judges whether it should be put into the client or not. This judgement is carried out on the basis of the length of time which the user refers to the information [6]. As for leading the URL to the client, the system extracts terms which are featured in the URL, calculates the similarity between URLs already existing in the client, and then rearranges this information according to the similarity. Users can reorganize these URLs in the client by direct operation; that is, they can add or delete a target URL, and move the group of URLs closer together or farther apart to classify this information using several mouse operations.
The system also calculates similarities between users. Each user is characterized according to the feature terms extracted from URLs in their bookmark and viewed information. The server lets each client send and receive these features, then it calculates the users' similarity. This prototype is written in HORB [2] which is equipped with the ORB mechanism, facilitating easy communication to remote objects.
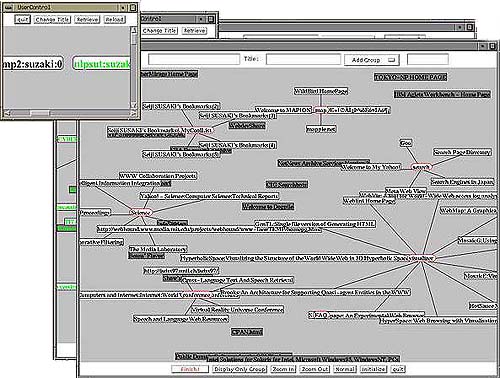
Figure 2 is a snapshot while operating. There are several windows in this figure. The small window at upper-left is user management window, and the windows on the right are user client windows. Square nodes, displayed like the spokes of a wheel, specify URLs stored in users' bookmark list, oval nodes with a red border specify group names, and the distance between nodes indicates the similarity among URLs. The groups are regarded as fields in which a user is interested. If a new URL is similar to an existing one, the system displays the new one, and it puts it near other groups which are judged similar. The users can rearrange these nodes and groups by clicking and dragging the mouse in order to add, delete, and classify the URLs and groups. For example, users can click on the mouse to delete a URL, or classify the target group to bring it closer or farther away from another group.
The user is able to refer to another user's personal information by clicking the mouse button that indicates the user in the user management window. Then, the system transfers the URLs in which the specified user is interested and displays them in the client. In the nature of things, it rearranges them totally using the feature terms in the URLs. They can access information kept by other users having similar interests, so it is useful for extracting proper information from the WWW.
[2] HORB, http://ring.etl.go.jp/openlab/horb/
[3] G. Salton, Automatic Text Processing, Addison-Wesley, 1989.
[4] U. Shadanand et al., Social filtering: algorithms for automating
`Word of Mouth', in: Proc. CHI'95, 1995, pp. 210–217.
[5] S. Susaki et al., Navigation interface in cross-lingual WWW search engine TITAN, in:
Proc. AUUG&WWW;'96,
1996, pp. 352–356.
[6] S. Susaki et al., Automatic interests extraction chasing the browsing and event history,
in: Proc. WebNet'97,
1997, pp. 562–567.