Internet Scrapbook:
automating Web browsing tasks by programming-by-demonstration
Atsushi Sugiura and Yoshiyuki Koseki
C&C; Media Research Laboratories, NEC Corporation,
4-1-1 Miyazaki, Miyamae-ku, Kawasaki 216, Japan
sugiura@ccm.cl.nec.co.jp and
koseki@ccm.cl.nec.co.jp
- Abstract
-
This paper describes an intelligent Web browsing system, called
Internet Scrapbook, which allows users with little programming skill
to automate their repetitive browsing tasks using a
programming-by-demonstration technique. With the system, the user can
create a personal page by clipping only the necessary portions from
multiple Web pages. Once the personal page is created, the system
updates it on behalf of the user by extracting the specified parts
from the latest Web pages.
- Keywords
-
Web browsing; Programming by demonstration
1. Introduction
WWW (World Wide Web) browsers, such as Microsoft Internet Explorer and
Netscape Navigator, allow users to easily access Internet information
resources. However, users need to spend much time and care in the
daily access to their desired Web information for two reasons.
- Usually, the information that users need is distributed across
several different pages. The users have to access all the necessary
pages by repeatedly specifying URLs (Uniform Resource Locators) or
selecting them from a bookmark.
- Users often need to browse only a portion of a Web page. They are
required to search the page for their desired information either by
eyes, or using the string search capability provided by the browser.
If users' target pages are frequently modified, it is a heavy burden
to keep up with the latest information by repeating these Web browsing
operations. Our goal is to reduce the operational cost of the browsing
tasks.
2. Internet Scrapbook
2.1. Overview
We have developed an intelligent Web browsing system, called Internet
Scrapbook, which allows users to automate their daily browsing tasks
using a programming-by-demonstration (PBD) [1] technique. PBD is a
method to convert user demonstrations on example data into programs
that perform repetitive tasks on behalf of the user.
In Scrapbook, users can demonstrate which portions of Web pages they
are interested in by creating a personal page, that is, selecting data
on a Web browser (Fig. 1a) and copying it to the single personal
page (Fig. 1b). Web data is copied directly from Netscape Navigator
3.0 and later, and Microsoft Internet Explorer 3.0 and later, using
APIs of those browsers. Once the personal page is created, the system
automatically updates it by extracting the user-specified portions
from the latest Web pages (Fig. 1c). Thus, the user can browse only
the necessary information on a single page and avoid repetitive access
to multiple Web pages.
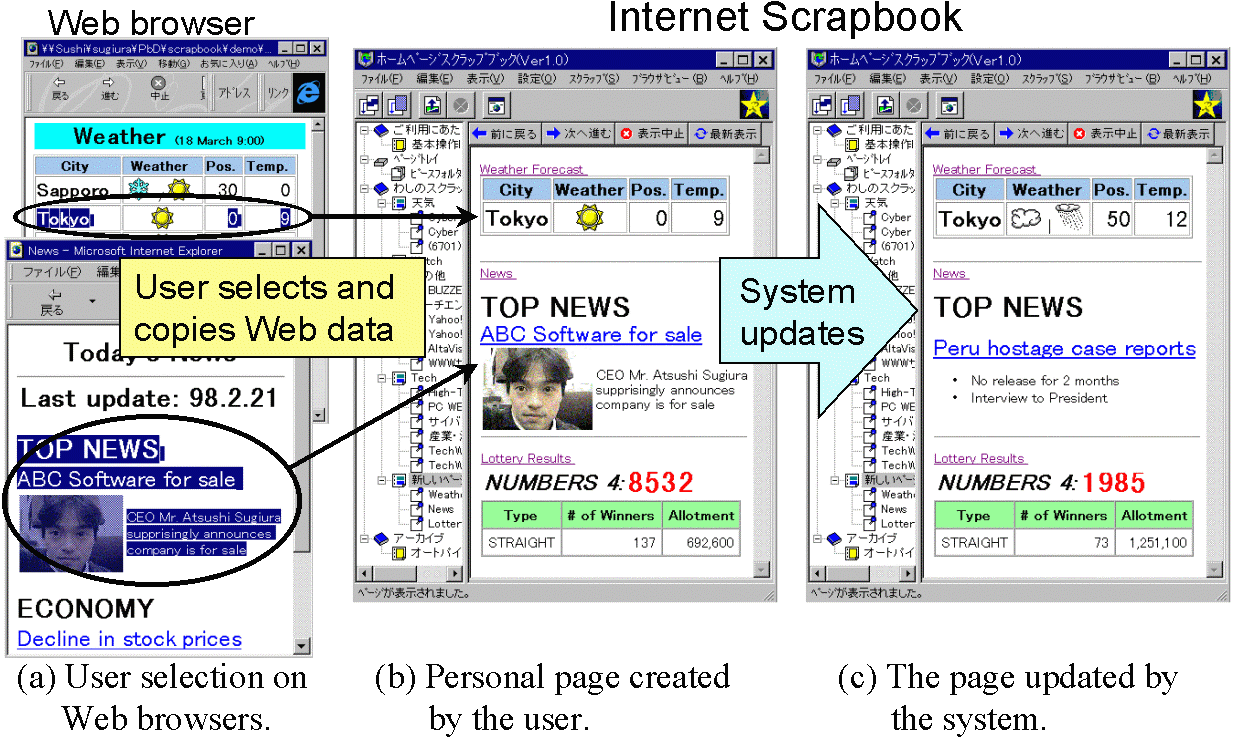
Fig. 1. Overview of Internet Scrapbook.
2.2. Generating matching patterns
Every time the user selects and copies Web data from a Web browser,
the system generates a matching pattern, used to extract the latest
data from the future Web page. Therefore, the pattern should contain
information that is expected to remain constant even after the source
page has been modified.
According to our observations of frequently modified Web pages, two
kinds of information are available as such permanent information:
the heading of an article and the position of an
article. In the news page of Fig. 1a, for example, the headings,
"Top News" and "Economy", are preserved while the articles following
these headings keep changing, and the positions of articles also
remain unchanged. We speculate that the headings and positions remain
unchanged for two reasons. First, changing the structure of Web pages
is costly for Web sites. Second, Web sites must ensure the readability
of their Web pages for readers, by preserving the document structure.
Based on such consideration, Scrapbook uses two kinds of descriptions
to define matching patterns: a heading pattern and a tag
pattern.
The heading pattern consists of texts that the system regards as a
heading of the user-selected article (data). Actually, Scrapbook
simply infers that the headings are likely to be in the
previous/first/next lines of the user selection. This is because users
tend to select the whole article from the beginning to the end, not
starting from the middle of the article, and the articles are often
surrounded by the permanent headings. For example, if the user selects
the data as shown in Fig. 1a, "Last update: 98.2.21", "Top News" and
"Economy", which are the previous line, the first line and the next
line respectively, are used as heading patterns.
The tag pattern represents the position of the selected data in the
Web page. It consists of both HTML elements that mark up the selected
data and their appearance order in the page. Therefore, the tag
pattern gives an interpretation, such that a user selects a region
from the first H2 to the second H2.
2.3. Updating a personal page
To update the personal page, the system downloads the latest Web page
from a Web site and extracts a portion specified by a user, using a
matching pattern. During the extraction, Scrapbook first tries to find
a portion that completely matches the pattern. However, such a portion
can not necessarily be found in the latest Web page. In the news page
shown in Fig. 1a, for example, it is expected that the date
information, "Last update: 98.2.21", described in the pattern would be
changed in the latest Web page.
In such cases, Scrapbook performs partial matching. Since there are
usually multiple portions extracted by the partial matching, the
system chooses the most plausible one by applying heuristics.
Basically, the system prefers portions identified by a heading pattern
to those found by a tag pattern. This is because the headings are
expected to reflect the user intent in the selection and explain the
contents of articles more clearly than the article position.
In some cases, however, portions found by tag patterns are preferred
over those resulting from heading patterns. Let us consider a Web page
shown in Fig. 2 where the newest information is added to the head.
If a user selects the data in the dash line (Fig. 2a), the generated
heading pattern contains texts "98.4.14" (the first line of the
selection) and "98.4.13" (the next line). Since those headings remain
in the page even after the information for "98.4.15" is added, the
heading pattern would extract the same data from the latest page in
Fig. 2b. In order to compensate for these cases, the system prefers
the region extracted using the tag pattern, whenever the extracted
information using the heading pattern is the same as the one before
the update. Consequently, the region from the first list item to the
second one, extracted by matching the tag pattern, is chosen in Fig.
2b.
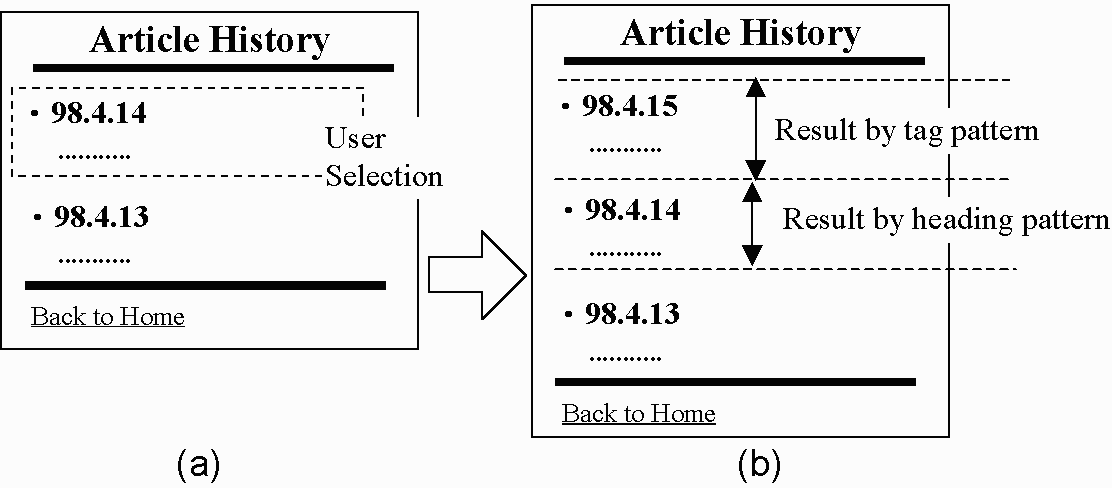
Fig. 2. A Web page where the newest information is added to the head.
3. Evaluation
We did an experiment in order to evaluate the accuracy of the data
extraction method in updating the personal page. We first created a
Scrapbook page by selecting 430 portions from 193 Web pages and
updated it seven days later. The 193 pages were randomly chosen from
categories in Yahoo! [3] and Yahoo! Japan [4], which were news,
sports, magazines, stocks, weather, etc.
The system was enable to appropriately update 88.4% of the selected
portions. Another 8.1% could be revised, combining with an
interactive learning method [2] that learn the correct priority in
candidate portions to be extracted from the user. Totally, 96.5% could
be extracted correctly.
4. Conclusion
This paper describes a Web browsing system with a demonstrational user
interface, called Internet Scrapbook.
We are planning to incorporate push technology into Scrapbook so that
information extracted by Scrapbook could be sent to a push-style
viewer. This configuration would enable users to create their own
information delivery system that can use the whole Web as the
information source.
References
- Cypher, A. (Ed.), Watch What I Do: Programming by
Demonstration, MIT Press, 1993.
- Sugiura, A. and Koseki, Y., Internet Scrapbook: Web browsing by programming-by-demonstration (in Japanese),
in: Proceedings of WISS'97, 1997, pp. 190–198.
- Yahoo!, http://www.yahoo.com/
- Yahoo! Japan, http://www.yahoo.co.jp/