Searching heterogeneous multilingual bibliographic
sources*
Ling Cao, Mun-Kew Leong, Ying Lu and Hwee-Boon Low
Kent Ridge Digital Labs,
21 Heng Mui Keng Terrace, Singapore
119597, Singapore
caoling@krdl.org.sg,
mkleong@krdl.org.sg and
hweeboon@krdl.org.sg
- Abstract
-
A crucial issue in the design of global Internet systems
is the presence of many languages for data exchange, indexing, searching,
and retrieval. It is especially significant in the library community where
there is a trend towards incorporating multilingual bibliographic collections
into regional and international databases for resource sharing through
the WWW. Such systems are distributed and heterogeneous, with libraries
using different proprietary systems and various flavours of standards such
as MARC. This paper proposes an architecture for searching distributed
heterogeneous multi-Asian language bibliographic sources, and describes
a successful pilot implementation of the system.
- Keywords
-
Distributed search; Multilingual
retrieval;
Bibliographic; Digital library; Z39.50
*This project was driven by the National Computer Board, and delivered
to the National Library Board with support from the National Science and
Technology Board.
1. Introduction
There is increasing interest in establishing a service infrastructure for
searching distributed heterogeneous multilingual (especially Asian language)
bibliographic sources regionally and worldwide [1]. Users benefit in being
able to issue a single query using a single interface and obtaining appropriate
information from multiple sources instead of repeatedly search library
after library each with their own idiosyncratic interface. Thus, issues
in multilingual cataloguing, indexing and searching, interoperability and
data exchange become more important. There are many character encoding
schemes especially for Asian character-based languages. For example, Chinese
script is variously encoded by such schemes as GB, HZX, Big5, EACC and
Unicode. Handling character sets
for multiple languages is a pervasive problem [2].
Additionally, the diversity of library sources and the variation of
data formats make resource sharing difficult. Moreover, multilingual, especially
Asian language, searching capabilities vary from system to system.
Figure 1 shows two quite different examples of
support for Chinese language and searching capabilities in bibliographic
records.
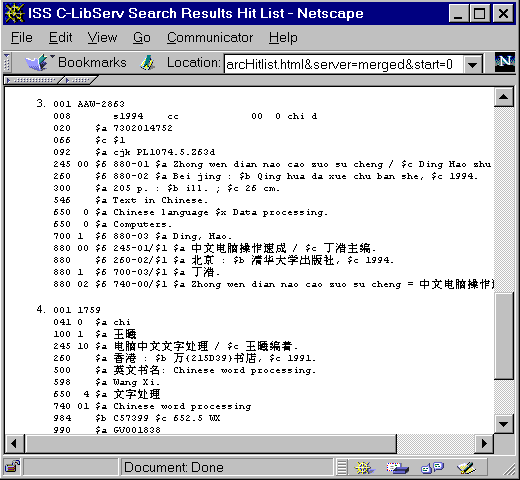 Fig. 1. MARC records with different Chinese language support.
Fig. 1. MARC records with different Chinese language support.
2. The CLib (Chinese Library) system
To demonstrate the searching of distributed heterogeneous multi-Asian language
bibliographic databases, a pilot project, the Chinese Library (CLib) system
(http://mentor.krdl.org.sg:8080),
was developed in Singapore. In the first phase, language support was for
Chinese bibliographic information, and two university libraries and one
public library were selected as test sites. These libraries each used different
library systems, different language encoding schemes, different implementations
of MARC, and support different language searching capabilities (see Figs.
1 and 2).
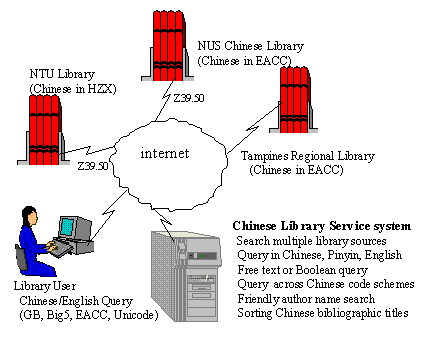 Fig. 2. The CLib system overview.
Fig. 2. The CLib system overview.
3. System architecture
An extensible 3-tier client/server architecture was designed (Fig.
3) for searching heterogeneous multilingual bibliographic sources [3].
It comprises the following high-level modules: CGI program, language server,
CLib server, Z39.50 client, CLib client and CLib multilingual search engine.
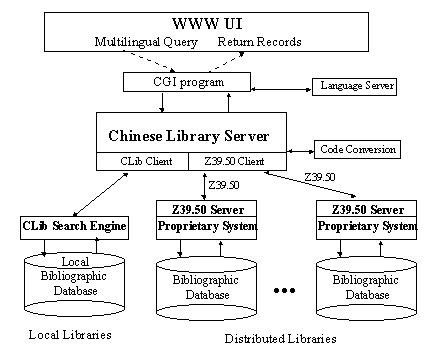 Fig. 3. The system architecture.
Accepting multilingual query
Fig. 3. The system architecture.
Accepting multilingual query
The multilingual Web interface of CLib system allows the user to select
his or her preferred encoding scheme (see Fig. 4)
and ensures that the user has selected correctly. The system provides four
fields for searching, specifically, title, author, subject and keyword
(see the query form in Fig. 5). The support
of unicode (UTF8) at the interface level provides the capability to accept
and display multiple scripts beyond English and Chinese.
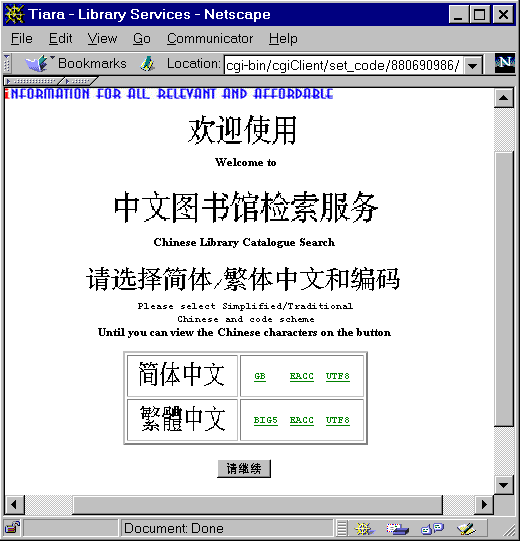 Fig. 4. Ensuring a matching encoding scheme.
Fig. 4. Ensuring a matching encoding scheme.
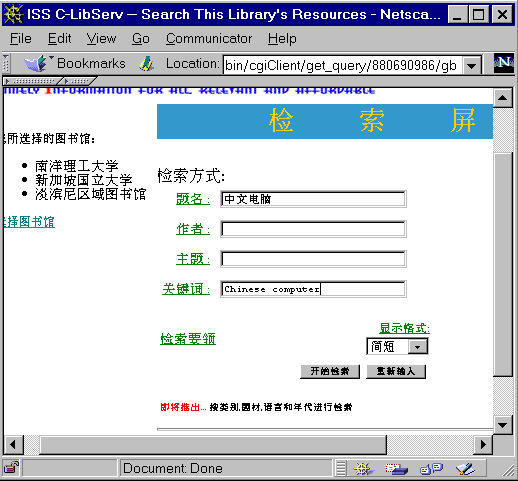 Fig. 5. The Chinese bibliography search form.
Beside receiving multilingual (including mixed language) queries from and
returning the multilingual Web pages to the HTTP server, the CGI
program calls the language server for converting the query from the incoming
encoding scheme to Unicode and converting the dynamically generated Web
pages back into the user selected encoding scheme.
Fig. 5. The Chinese bibliography search form.
Beside receiving multilingual (including mixed language) queries from and
returning the multilingual Web pages to the HTTP server, the CGI
program calls the language server for converting the query from the incoming
encoding scheme to Unicode and converting the dynamically generated Web
pages back into the user selected encoding scheme.
Meta-data repository
The meta-data repository holds the format of each bibliographic source
available to the system, i.e., the library servers. This meta-information
includes server type, language and encoding(s), searching capability, services
supported, data format, MARC mapping table and any other attributes. It
is used to distribute the user queries to the right server in the right
language and format, and also to merge the retrieved results and to extract
title information from appropriate fields in the respective MARC records.
Distributing multilingual query
When the CLib server receives the query in some language supported in
Unicode, or a mixture of any number of languages, it customizes the query,
based on the meta-information, and concurrently dispatches to the selected
library servers through the Z39.50 client or the CLib client. The CLib
client is used to communicate with the CLib multilingual bibliographic
database, running on top of an in-house Unicode-based search engine. This
database provides advanced search and retrieval features and full multilingual
searching in all bibliographic fields with the same functionality as the
other Z39.50 search servers.
Merging heterogeneous results
The Z39.50 and CLib clients' search results from the respective libraries
are received by the CLib server in the library's flavour of MARC and in
their own internal encoding scheme. CLib uses Unicode internally and as
an interlingua. The MARC records received from the various libraries are
unified into Unicode and the corresponding directory and leader information
are rebuilt. The results are then collated, merged, and if required, sorted
(by user-selectable search fields sorting orders). Lastly the results are
available in various levels of detail, e.g., Fig.
6.
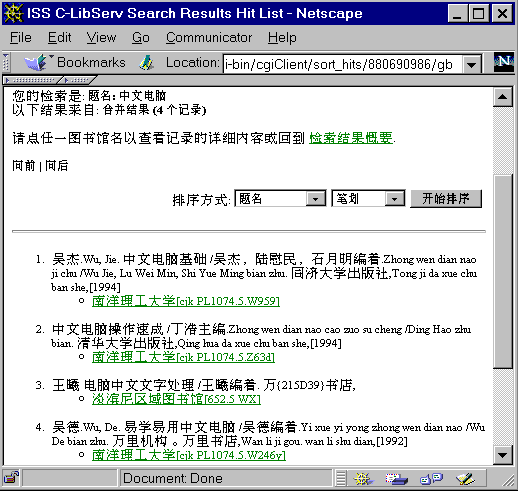 Fig. 6. Collated and sorted titles.
Fig. 6. Collated and sorted titles.
4. Conclusions
We have presented an approach to searching distributed heterogeneous multilingual
bibliographic databases. It provides the framework to distribute the multilingual
queries and merge the retrieved search results from heterogeneous multilingual
bibliographic databases. This approach makes use of the maximal multilingual
searching capabilities of each distributed server and provides alternative
mechanisms if none are available.
References
-
C.A. Lynch, Building the infrastructure of resource sharing:
union catalogs, distributed search, and cross-database linkage, Library
Trends, 45(3): 448–461 ,Winter 1997.
-
C.L. Borgman, Multi-media, multi-cultural, and multi-lingual
digital libraries, D-Lib Magazine, June 1997, http://mirrored.ukoln.ac.uk/lis-journals/dlib/dlib/dlib/june97/06borgman.html
-
L. Cao, M.K. Leong, Y. Lu and H.B. Low, Multilingual library Web
services,
Technical Report, TR98-245, Kent Ridge Digital Labs, National University
of Singapore, February 1998.