Mao Lin Huang, Peter Eades and Robert F. Cohen
Department of Computer Science and Software Engineering,
University of Newcastle, NSW 2308, Australia
mhuang@cs.newcastle.edu.au,
eades@cs.newcastle.edu.au and
rfc@cs.newcastle.edu.au
The tools in the last two categories involve the use of information visualization. They usually employ one or more static visualization techniques, such as Fish-eye [6], Biform [5], and Scatterplot [4], to build a large static visualization of the Web graph at once, and then allow the user to navigate through the visualization.
While some of these static visualization techniques effectively deal with moderately large portions of the underlying Web graph, they do not handle the entire Web. The major problems are:
Since the amount of data that can be effectively displayed at one time is limited, these techniques are unable to display the whole large visualization in detail at one time. To solve this problem, some of these techniques, such as Fish-eye view and Biform view, involve a change of the view, that allowing the user to effectively view only at one time a small area of the whole visualization by changing the viewing area or focus zoom of the visualization.
On the other hand, some newly developed tools attempt to use dynamic visualization (such as a dynamic focus+context view [4] technique) to address this problem. The dynamic visualization techniques also require changing views, allowing the user to dynamically visualize a subset of the Web by updating the visualization.
The main problem with changing views is the ``mental map'' [2] problem. When the picture jumps from one view to another, there is no smooth transformation between the views. The user's mental map of the view is broken, and thus the user has to spend extra cognitive effort to re-form the mental map after each transition.
This paper introduces a new concept of exploratory navigation, and then describes a system, known as WebOFDAV, that uses this concept to help the user to navigate the Webspace and avoid the ``lost in hyperspace'' situation. It preserves the user's mental map [2] while the user dynamically visualizes the navigation by swapping the Web context.
Our essential technique adopted in WebOFDAV, known as Online Force-Directed Animated Visualization (OFDAV), provides a major departure from traditional visualization methods. It allows the user to visualize the entire Webspace that is available through the hypermedia system, but does not require the whole Web graph to be known. It assumes that the amount of data that can be effectively displayed at one time is only a tiny subset of the available Webspace. It does not predefine the geometry of the whole visualization at once (the user can navigate logically).
In WebOFDAV, the user's view is focused at any point in time on a small subset of the entire Webspace. The corresponding subgraph of this subset is called a logical viewing frame and is defined by its focus nodes. Conceptually, the focus nodes form a first-in-first-out queue with user's highest interest focus. The viewing frame is updated smoothly following the changes of the user's interest focus. We allow the user to change focus by selecting another node in the viewing frame, but we do not anticipate the user's selection. However, we do assume that we can always discover the neighbourhood of the focus node. This is analogous to following hypertext links from the Web page represented by the focus node of the current view.
We use a force-directed algorithm [1,3] to draw this subgraph and the logical neighbourhood around this subgraph. The logical neighbourhood of the focus nodes gives the user a clear idea of where they are and helps them to decide where they should go next.
We use multiple animations to guide the user between views; they make the transitions naturally and smoothly. In the user's visual sense, there is only one animated image. This greatly reduces the cognitive effort in re-forming the user's mental map after each transformation. We adopt a graphical history tail that contains a sequence of previous focus nodes. It traces the subgraphs that the user has visited and assists in backtracking through the Web graph.
The main components of WebOFDAV are:
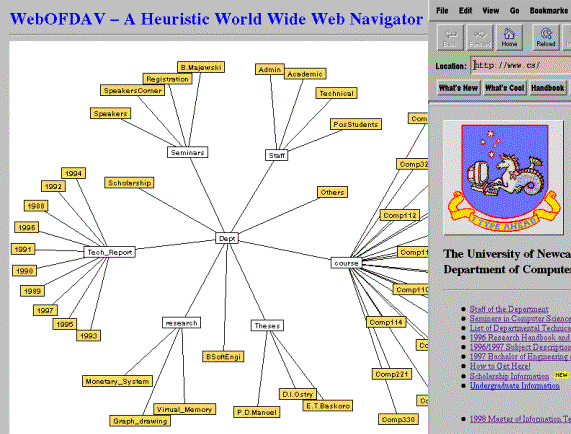
Suppose that we start to navigate the Webspace from the first initial frame, the Web context of the Department of Computer Science at the University of Newcastle (see Fig. 1). Then, we incrementally swap the context to the next frame by clicking on the node labeled PostStudents. This swapping is done smoothly through three types of animation:
Fade animation: We use shrinking/growing animation to help the user identify nodes that are disappearing or appearing to smoothly update their mental map of the view. In this instance, the focus node course is deleted from the focus queue and its immediate neighbourhood disappears smoothly from the screen, and the clicked node PostStudents becomes a new focus node and is appended to the focus queue. The immediate neighbourhood of the PostStudents node also appears smoothly to the screen.
Layout animation: Once a context transition occurs from one frame to another, the node set of the viewing frame changes with the appearing and disappearing of the nodes. We use a force-directed animation algorithm to automatically adjust the layout between viewing frames. We assume that appearing nodes can be placed anywhere close to the new focus node, since the user has not yet developed a mental map of their locations. Other nodes can move from the old equilibrium of the forces to the new according to a system of forces calculated based on their existing positions.
Camera animation: This concerns the change in the view when we move from one frame to another. We assume that the user is intending to focus their view on the new focus node, PostStudents. We allow the user to smoothly move the viewing frame to any position on the screen to reach the best viewpoint of the frame.
Fig. 1. The first viewing frame with the queue of focus nodes, {Dept, Tech_Report, Staff, Seminars, Courses, These, Research} and a set of nodes surrounding the queue with graph theoretic distant (d = 1).
Twelve frames further into the user's exploration of Webspace (see Fig. 2). We see that the current Web context has smoothly been swapped from the local department site to CNN site, and then from CNN site to Australia site.
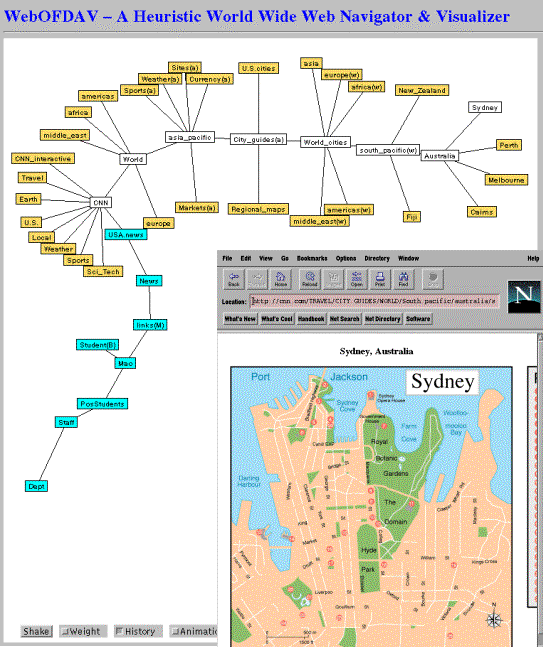
Fig. 2. Twelve frames further into the user's exploration. Note the history tail consisting of the previous focus nodes labeled Dept, Staff, PostStudents, Mao, Student(B), links, News and USA.news. Here, the queue of focus nodes is {CNN, World, asia_pacific, City_guide(a), World_cities, south_pacific(w), Australia}.
On the other hand, WebOFDAV provides a new online visualization technique allowing the user to navigate and visualize the entire Webspace of unlimited size without predefining the visualization.