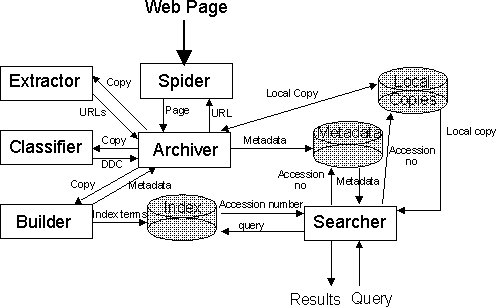
Fig. 1. Overview of the new WWLib architecture.
School of Computing & IT,
University of Wolverhampton
Wulfruna Street,
Wolverhampton,
WV1 1SB,
UK
The evolution of automated World Wide Web search engines from manually maintained classified lists and directories has further demonstrated the strengths and weaknesses of these two approaches. The tendency of automated search engines to inundate users with irrelevant results has prompted reconsideration of the merits of classification. The combination of automation and classification has the potential to provide an accurate, intuitive, comprehensive classified search engine. This is the aim of WWLib.
The original version of WWLib relied to a large degree on manual maintenance and as such can best be described as a classified directory that was organised according to DDC. The use of DDC to organise WWLib evolved from the notion that Library Science has a lot to offer the chaotic task of information resource discovery on the Web. The classified nature of WWLib was beneficial in that it clustered documents according to subject matter and enabled users to browse through documents that shared the same DDC classmark as those that appeared in the results of a query.
It was soon evident, however, that WWLib required a much higher degree of automation. A robot for resource discovery and an automatic indexer were required but the automated WWLib would preserve its classified nature by employing an automatic classifier. An outline design of the new automated WWLib, shown in Fig. 1, identifies the automated components and their responsibilities:
There are six automated components:
One of the reasons for deciding on such a componentised architecture was to allow for components to be distributed over a network if necessary.
Many automated search engines have deployed traditional IR indexing strategies and retrieval mechanisms but very few have experimented with automatic classification. Previous experimentation with automatic classification was carried out during the development of the original WWlib. This original classifier[2] compared text in each document with entries in a DDC thesaurus file. The thesaurus entries consisted of the DDC classmark and accompanying header text eg:
641.568 Cooking for special occasions Including Christmas
The original classifier achieved approximately 40 percent accuracy. For the new version of the classifier, it was decided that a much more detailed thesaurus with a long list of keywords and synonyms for each classmark was required. These lists are referred to as class representatives. It was also decided that more use would be made of the hierarchical nature of DDC. The classifier would begin by matching documents against very broad class representatives representing each of the ten DDC classes at the top of the hierarchy — 000 Generalities, 100 Philosophy paranormal phenomena and psychology, 200 Religion, 300 Social Sciences, 400 Language, 500 Natural sciences and mathematics, 600 Technology, 700 The arts, 800 Literature and rhetoric, 900 Geography, history, and auxiliary disciplines.
The matching process would then proceed recursively down through the subclasses of those DDC classes that were found to have a significant measure of similarity with the document. A filtering effect is achieved using customised class representatives at each node. Ambiguous terms are concealed within lower nodes of the classification hierarchy enabling them to be considered in context.
The classifier has two main processes; firstly the document is indexed; secondly the document is classified. The indexing process results in the formation of a document object. The document object comprises a number of keyword objects, each one representing a word found within the document. Keywords have a weight — assigned according to where the word was found — and a position associated with them.
The classification process uses a classify object which takes the newly formed document object and compares it with a number of DDC objects. DDC objects inherit their structure and behaviour from an abstract class Dewey. They too are made up of a series of weighted keyword objects that together make up the class representative. Each DDC object has a classmark object specifying its dewey decimal classmark, and can have up to ten subclasses which are in themselves DDC objects representing the next layer of the hierarchy. The classify object begins by comparing the document object with the ten DDC objects representing the top of the DDC hierarchy. If the document matches significantly with a DDC object, instances of that DDC object's subclasses are created and the document is compared with those. This process continues recursively down the hierarchy until a significant match is found with a leaf node (a DDC object with no subclasses). In this event the classmark object belonging to the DDC objec is copied into the document object. Measures of similarity are calculated using the Dice Coefficient[3]. The indexing and classification processes are co-ordinated by the Ace (Automatic classification engine) object.
The classifier has been implemented in Java. This has enabled easy networking, multithreading and memory management.
The new classifier is in the early stages of evaluation. It appears, however, that use of a hierarchical classifier results in context sensitive classifications. The use of manually defined class representatives, that perform context sensitive filtering, encourage accuracy. To increase the accuracy of the classifier further a more comprehensive set of DDC class representatives are required. When sufficient DDC classes have been defined, formal testing will be required to prove that the new classifier is achieving a higher rate of accurate classifications than the original one. There is a working paper that describes the design and implementation of the classifier in more detail.