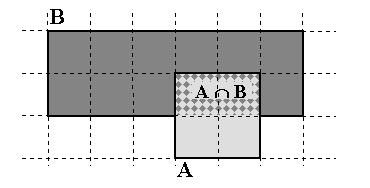
Fig. 1. Computing size ratios from overlap estimates.
DIGITAL,
Systems Research Center,
130 Lytton Avenue,
Palo Alto, CA 94301, U.S.A.
bharat@pa.dec.com and
broder@pa.dec.com
Clearly no search engine can index the entire Web. (A good discussion of this issue appears in [1].) An often debated topic is how much coverage they provide. Typical questions are "Which one has the largest coverage?", "Do they all cover the same pages and differ only in their ranking, or do they have low overlap?", "How many pages are out there and how many are indexed?". These questions are of scientific and public interest but few objective direct evaluation methodologies have been proposed.
The most straightforward way to get answers would be to obtain the list of URLs within each engine's index, and compute the sizes and intersections of these lists. Given the intense competition among commercial search services, and the fact that such a list is highly prized proprietary information, this certainly will not happen. Furthermore even if the services were to supply a third party with a list of URLs there is no guarantee that they represent legitimate URLs and/or that the corresponding pages were actually fetched and still in the index.
Some published approaches to estimating coverage are based on the number of hits for certain queries as reported by the services themselves. A better variation, used by Melee's Indexing Coverage Analysis (MICA) is based on the reported count of pages within a particular domain. (MICA uses other refinements, but is still ultimately dependent on the accuracy of the reported numbers.) Unfortunately self-reported counts are not necessarily reliable or comparable. Even assuming no deliberate over-estimation there is no guarantee that the reported counts do not include duplicate documents, aliased URLs, or documents no longer in existence. Furthermore this method does not allow any determination of overlap.
A different approach, used for example by the Search Engine Watch for their Search Engine EKG, is to observe the access logs of selected sites and determine how much of these sites is visited by various search engine robots. Again there is no guarantee that if an engine has fetched a page, the page will eventually be indexed. Search engines tend to employ various filtering policies to build an effective index.
In an attempt to resolve the questions above we have developed a standardized, statistical way of measuring search engine coverage and overlap through random queries. Our technique does not require privileged access to any database, and can be implemented by independent third-party evaluators with fairly modest computational resources. (For four engines, we could determine their relative size and and the relative size of their intersection within a few days. Most of the time is spent waiting for pages to be fetched.) Our method is subject to certain statistical biases that we discuss, but since they tend to favour content-rich pages, this can be viewed as an asset rather than a flaw.
We implemented our measurement technique as described in this paper and did two sets of experiments involving over 10,000 queries each. These show that as of mid 1997, the approximate sizes of HotBot, AltaVista, Excite, and Infoseek, expressed relative to their joint total coverage at that time, were respectively 47%, 39%, 32%, and 18%; and as of November 1997, they were 48%, 62%, 20%, and 17%. Our method does not provide absolute values. However using data from other sources we estimate that as of November the number of pages indexed by HotBot, AltaVista, Excite, and Infoseek were respectively roughly 77 million, 100 million, 32 million, and 17 million and the joint total coverage was 160 million pages. We further conjecture that the size of the static, public Web as of November was about 200 million pages. The most startling finding is that the overlap was very small: less than 1.4% of the total coverage, or about 2.2 million pages appeared to be indexed by all four engines.
In the next section we overview our estimation algorithm. Its detailed implementation is described in Section 3. In Section 4 we discuss sources of bias in our technique and suggest how they may be overcome or even exploited. Section 5 describes in detail the two sets of experiments that we did to estimate the sizes and overlaps of AltaVista, Excite, Hotbot and Infoseek. Finally Section 6 presents some conclusions.
The idea behind our approach is simple: Consider sets A and B of size 4 and 12 units respectively. Let the size of their intersection A & B be 2 (see Fig. 1). Let us suppose that we do not know any of these sizes but can sample uniformly from any set and check membership in any set. If we sample uniformly from A and we will find that about 1/2 of the samples are in B as well. Hence the size of A is approximately 2 times the size of the intersection, A & B. Similarly we will find that the size of B is approximately 6 times the size of A & B. This will lead us to believe that B is about 6/2 = 3 times the size of A.
Fig. 1. Computing size ratios from overlap estimates.
More formally, let Pr(A) represent the probability that an element belongs to the set A and let Pr(A & B|A) represent the conditional probability that an element belongs to both sets given that it belongs to A. Then, Pr(A & B|A) = Size(A & B)/Size(A) and similarly, Pr(A & B|B) = Size(A & B)/Size(B), and therefore Size(A)/Size(B) = Pr(A & B|B) / Pr(A & B|A).
To implement this idea we need two procedures:
Fraction of URLs sampled from E1 found in E2.
Fraction of URLs sampled from E2 found in E1 -------------------------------------------- Fraction of URLs sampled from E1 found in E2
However in principle sampling can proceed along different lines. For instance, if we had a way to select a page on the Web uniformly at random, we could choose a large set of random pages and for each page test if it is indexed by each of the search engines. This would allow us to estimate the relative sizes and overlaps of the search engines under consideration and also their sizes relative to the entire Web.
Unfortunately choosing pages uniformly at random from the entire Web is practically infeasible: it would require either collecting all valid URLs on the Web, which requires constructing a better Web crawler than any existing one, or the use of sampling methods that do not explore the entire Web. Such methods, based on random walks, have been studied theoretically in other contexts (see e.g. [3] and references therein). They are not easily applicable to the Web, since the Web is a directed graph with highly non-uniform degrees and has many small cuts. Precious little is known about the graph structure of the Web. Hence the length of the random walks required to generate a distribution close to the uniform may be extremely large.
Since sampling at random from the Web directly is not easy, we could use the search engines themselves to generate page samples. It is tempting to use one engine, say E1 as a random source of URLs to estimate the sizes of two other search engines, say E2 and E3. For a random page from E1 we could check whether it belongs to E2 and whether it belongs to E3. Given enough samples we could infer the relative sizes of E2 and E3. However such a strategy could work only if the search engine indices are truly independent, and built from random samples of the Web. This is not true in practice. Two engines may well have started at the same starting points, or have taken URL submissions from the same parties, or may use the same policy for prioritizing links and indexing pages. If engine E1 were used as a source and there is a positive correlation between E1's index and E2's index, then E2 will unfairly appear to be bigger than the others. Hence we employ the strategy described in Section 2.1.
For our experiments we used a broad crawl of roughly 300,000 documents in the Yahoo! hierarchy to build a lexicon of about 400,000 words. Extremely low frequency words (which may have been typographic errors) were not included in the lexicon. We conjecture that all search engines must use Yahoo! as one of their starting points and hence the lexicon would be fair to all. Whether indeed the composition and word distribution in our lexicon reflects that of the whole Web is unclear.
In general the choice of a particular lexicon induces a certain bias, as we further discuss below. For instance, such a lexicon may be heavily biased towards English. In principle it is possible to choose a corpus of Web pages in another language and construct the lexicon accordingly. In addition we can impose additional constraints, such as a restriction on the hostname (e.g., *.com) to obtain statistics on a particular section of the Web.
We experimented with both disjunctive (OR) queries and conjunctive (AND) queries. All queries tend to introduce a query bias towards large, content rich pages (see Section 4). For conjunctive queries one can try to pick keywords such that fewer than 100 results are returned, thus eliminating the ranking bias. Unfortunately this increases the query bias.
Disjunctive (OR) queries are made out of random sets of keywords drawn from the lexicon. We used sets of four. To reduce the query and ranking bias the words need to be chosen so that their frequencies are roughly the same, since some search engines prefer infrequent keywords to rank results.
To compute conjunctive (AND) queries, pairs of random keywords are used (sets of 3 will often result in 0 hits). Keywords are paired carefully to return a small but non-empty set of results. This is done as follows: The list of available keywords is sorted by frequency. A lower and an upper threshold are picked iteratively so that keywords equidistant from the thresholds tend to give between 1 and 100 results in a conjunctive query. Then the keywords contained between the thresholds are randomly sampled. The resulting set of keywords is sorted by frequency, and keywords equidistant from the ends of the list are paired to form queries.
Given a random query in one of the two schemes, a URL is obtained from a designated search engine by selecting a random result page from the top 100 result pages returned by the search engine for the query.
This query based sampling approach is subject to various biases, that is some pages tend to have a higher probability of being selected as a sample. This gives them a higher "weight". Eventually what we end up estimating is the ratio of the total weight of the pages indexed by one engine to the total weight of the pages indexed by another. However the bias introduced seems reasonable or even favourable, in the sense that we tend to give a higher weight to "interesting" pages — namely pages rich in content in our language of choice. This is further discussed in Section 5.
The strong query is constructed as follows. The page is fetched from the Web and we analyse the contents to compute a conjunctive query composed of the k (say 8) most significant terms in the page. Significance is taken to be inversely proportional to frequency in the lexicon. Words not found in the lexicon are ignored since they may be typographical errors (which tend to be transient) or words that might not have any discriminative value (e.g., common words in a foreign language.) The strong query is sent to each of the search engines in turn and the results are examined. If one of the result URLs matches the query URL then the query URL is noted as being present in the engine's database.
The matching has three aspects:
(a) Normalization. All URLs are translated to lowercase and optional filenames such as index.htm[l], home.htm[l] are eliminated. Relative references of the form "#..." and port numbers are removed as well. Hostnames are translated to IP addresses when one of the URLs involves an IP address.
(b) Actual matching. This is done in several ways depending on how strict the matching requirement is:
(c) Filtering out dynamic and low-content pages. Pages that are detected by none of the search engines (including the source) may be regarded as dynamic Web pages and filtered out of the statistics on the assumption that they contain changing content. Similarly, some pages actually have very little textual content which results in an ineffective strong query. (That is, the strong query returns a large number of matches from either the source or the engine being tested.) Ignoring such pages allows us to focus on content rich pages with relatively static content.
The checking step introduces a checking bias that we discuss further below. Again our estimates weight in the favour of pages that are content rich and relatively static. Although this is not representative of the entire Web, it reflects the part of the Web that most users tend to query, and is hence more meaningful as a measure of a search engine's utility. As already explained, query based sampling is inherently biased towards pages rich in text content. Hence, this effect seems inevitable regardless of the checking method used.
We classify the biases as follows:
Some of these biases can be alleviated, but usually there are trade-offs. To remove the ranking bias we could frame conjunctive queries that return less than, say, 200 documents, although this is hard to guarantee, and retrieve all the documents. Clearly this increases the query bias.
Removing the query bias is more difficult. One could in principle compute Pincl(u), the probability of inclusion of URL u given our process for generating URLs. This depends on the probability of generation of various queries and the probability of u being matched by each of the queries. If Pincl were the same for all URLs then we could select all URLs with equal probability. Since this is not the case (due to the query bias) we can compensate by selecting u with a selection probability of P0/Pincl(u), where P0 is the minimum value for Pincl(u) on the Web. These quantities are very hard to estimate in practice, and since in most cases the selection probability will be very low, this process will take a large number of trials to generate the needed set of URLs.
With privileged access to a search engine it is trivial to generate random URLs from the set indexed by that engine, thus eliminating both ranking and sampling bias. This should show a decrease in overlap, since one would expect that high-content pages which are favoured by both ranking and query bias are likely to be cross-indexed. Preliminary experiments done using privileged access to the AltaVista index confirm this.
Statistics were computed for various inclusion criteria (all pages, static pages only) and matching criteria (full URL match, hostname match, any URL). When considering static pages only, the matching criterion determined how many tests were applicable, since, by our definition, at least one search engine needed to contain the page for the test to be applicable. We consistently found that about 10% of the pages sampled were dynamic and another 10% failed to produce a small result set with a strong query. Hence only 80% of the tests were actually considered for the static pages measurements.
The leftmost column lists the source engine for the random pages (Engine A). The second column lists the engine being tested for containing these pages (Engine B). For each trial we list the percentage random pages from A found in B (overlap), and the inferred ratio of sizes: Size(A)/Size(B). To compute the ratio we use the method explained in Section 2.1.
Some variation between the trials in a set is to be expected. A variation in an overlap value will cause a variation in the corresponding size ratio. In most cases the overlap variation appears to be statistically insignificant. The only significant variation in the first set of trials is an apparent increase in Excite's coverage from trial 1 to trial 2. This is probably due to different biases in effect with disjunctive and conjunctive queries. With conjunctive queries there is a query bias towards large, content-rich pages. This might indicate that Excite was selectively indexing content-rich pages at that point in time. The other explanation might be that Excite installed a larger index in the interval between the trials (about 15 days). We observe two mildly significant variations in the second set of trials (i.e., trials 3 and 4): (1) Infoseek indexed more of AltaVista pages accessed with conjunctive queries than disjunctive queries, and (2) Infoseek and AltaVista indexed more of HotBot with disjunctive queries. As before, the first variation might arise because Infoseek selectively indexed content rich pages. The second observation may be due to a ranking bias on HotBot's part towards more "popular" pages by some metric (e.g., content length, in-degree). Such a bias could be more visible with respect to pages fetched with disjunctive queries which generally return large sets. In general, the interplay between ranking biases and page indexing policies of search engines has the potential to produce isolated variations in overlap that are hard to explain. However the overall results seem fairly consistent.
As mentioned previously 10% of the pages were observed to be dynamic. Hence the overlaps when considering static pages alone were about 10% larger than when all pages were considered. This did not affect size estimates. Quite surprisingly size ratios seemed unaffected by the matching criterion as well. As we weakened the URL matching criterion, the overlap fractions grew correspondingly. Strong queries often list large files such as dictionaries in their result set. Hence, taking a non-zero result set to be a match seems overly generous. While hostname matching may compensate in some cases for URL naming differences due to aliases, we believe full URL matching to be a more dependable scheme, even though it tends to underestimate overlap a little.
To reconcile the various pair-wise size ratios and get a full picture we computed best likelihood estimates for engine sizes. Specifically, we computed estimates for the engine sizes so that the sum of squared differences between the resulting estimates for the pairwise overlap (using the experimental ratios) was minimized. Using these estimates for sizes, we then averaged the estimates for the intersections given by the experimental ratios. Finally we normalized our data so that the total coverage of all search engines together equals 100%. The final numbers are presented in Fig. 2.
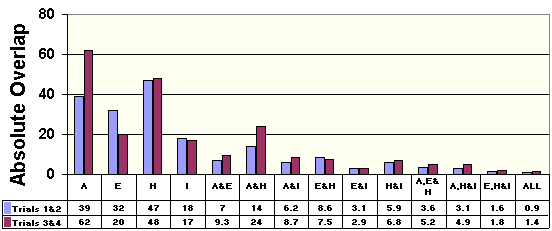
Fig. 2. Normalized estimates for all intersections (expressed as a percentage of total joint coverage).
We can see from Fig. 2 that in November 1997, only 1.4% of all URLs indexed by the search engines were estimated to be common to all of them. The maximum coverage by any search engine was by AltaVista, which had indexed an estimated 62% of the combined set of URLs. In July 1997, HotBot was the largest, with 47% of the combined set of URLs, and the four engine intersection was only 0.9%.
The ratios we obtained seem consistent with other estimates of the sizes of these search engines at the time. Search Engine Watch reported the following search engine sizes (as of November 5, 1997): AltaVista = 100 million pages, HotBot = 80 million, Excite = 55 million, and Infoseek = 30 million pages. The October 14, 1997 press release from AltaVista also states a 100 million page database. Hence if the size of AltaVista was 100 million pages, then the total coverage of all the search engines should have been about 100 million/0.62, or roughly 160 million pages in November 1997 (see Fig. 3). Similarly, the estimate that the four-engine intersection was 1.4% leads us to estimate that only roughly 2.25 million pages were common to all search engines in November 1997.
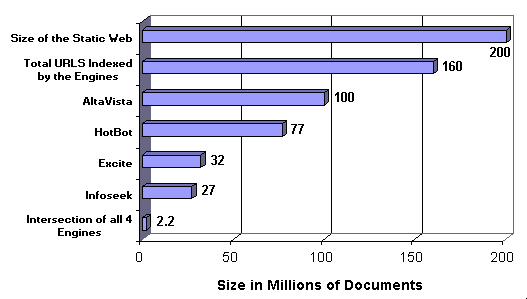
Fig. 3. Absolute size estimates for November 1997.
Further, we observe that each search engine seems to have indexed roughly a constant fraction of every other search engine. For example, from trials 3 and 4, it would seem that AltaVista indexed 50% of every search engine, and Infoseek indexed 15%, and so forth. This seems to suggest that the indices were constructed independently, and that these fractions are in general representative of each engine's coverage of the Web at large. On this assumption, if AltaVista had indexed 50% of the Web in November 1997, then the static portion of the Web could be estimated to be at least 200 million pages. Note that all engines have a bias towards well-connected, content-rich pages. The probability that AltaVista indexed an arbitrary page on the Web is likely to have been less that 0.5. Hence, the true size of the static Web was probably larger than 200 million documents in November 1997. This is in the same range as the estimate by Z. Smith, which was based on a crawl done by Alexa that found 80 million public pages in January 1997 and a predicted annual doubling rate [4].
In this paper we describe the first attempt to measure the coverage and overlap of public Web search engines using a statistically sound sampling technique. Our estimation scheme works on the basis of individual URL containment and thus we can estimate intersections between engines as well. Our measurements taken in November 1997 provided size ratios that were consistent with third party measurements reported in the press. We found AltaVista to be the largest search engine at that point in time with a 62% share of the combined set of URLs indexed by the four major engines, and a consistent 50% coverage of each of the three other search engines. Based on estimates that AltaVista's size was approximately 100 million documents, we conjecture that the size of the static public Web as of November 1997 was at least 200 million documents.
Our approach for search engine comparison has a clear statistical objective basis. Although it gives a higher weight to long, content rich pages in the language of the the lexicon, this bias is well understood and it is in principle computable for every page on the Web. Thus we have a method that can be used by any interested party to estimate the coverage of publicly available engines. Further, by modifying the lexicon suitably the method can be biased towards estimating coverage of a particular language or even a (broad) topic.
We are exploring the possibility of transferring this technology to a third party interested in providing a periodic evaluation of search engine coverage.
| [1] | D. Brake, Lost in Cyberspace, New Scientist, June 28, 1997, http://www.newscientist.com/keysites/networld/lost.html |
| [2] | D. Brake, A. Broder, S. Glassman, M. Manasse, and G. Zweig, Syntactic clustering of the Web, in: Proc. of the 6th International World Wide Web Conference, April 1997, pp. 391–404, http://www6.nttlabs.com/papers/PAPER205/PAPER205.html. |
| [3] | A. Sinclair, Algorithms for Random Generation and Counting: A Markov Chain Approach. Birkhauser, 1993. |
| [4] | Z. Smith, The truth about the Web; crawling towards eternity, Web Techniques Magazine, May 1997, http://www.webtechniques.com/features/1997/05/burner/burner.shtml |
 Krishna Bharat is a member of the research staff at Digital Equipment
Corporation's Systems Research Center. His current research interests include
Web content discovery and retrieval, user interface issues in automating
tasks on the Web, and speech interaction with hand-held devices. He received
his Ph.D. in Computer Science from Georgia Institute of Technology in 1996,
where he worked on tool and infrastructure support for building distributed
user interface applications.
Krishna Bharat is a member of the research staff at Digital Equipment
Corporation's Systems Research Center. His current research interests include
Web content discovery and retrieval, user interface issues in automating
tasks on the Web, and speech interaction with hand-held devices. He received
his Ph.D. in Computer Science from Georgia Institute of Technology in 1996,
where he worked on tool and infrastructure support for building distributed
user interface applications. |
 Andrei Broder has a B.Sc. from Technion, Israel Institute of Technology
and a M.Sc. and Ph.D. in Computer Science from Stanford University.
He is a member of the research staff at Digital Equipment Corporation's
Systems Research Center in Palo Alto, California. His main interests
are the design, analysis, and implementation of probabilistic algorithms
and supporting data structures, in particular in the context of Web-scale
applications.
Andrei Broder has a B.Sc. from Technion, Israel Institute of Technology
and a M.Sc. and Ph.D. in Computer Science from Stanford University.
He is a member of the research staff at Digital Equipment Corporation's
Systems Research Center in Palo Alto, California. His main interests
are the design, analysis, and implementation of probabilistic algorithms
and supporting data structures, in particular in the context of Web-scale
applications. |