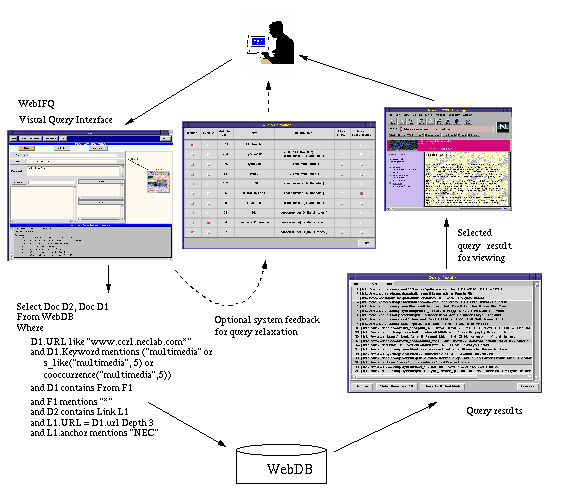
Fig. 1. Querying Web documents in WebDB.
C&C; Research Laboratories, NEC USA, Inc.,
110 Rio Robles, M/S SJ100, San Jose, CA 95134, U.S.A.
wen@ccrl.sj.nec.com and
jshim@ccrl.sj.nec.com
With all these three types of information, more complex queries can be supported. A more comprehensive query, such as "retrieve all pages, modified after 1997, which are linked from www.nba.com with depth of 10, sort the results by their URLs, and remove duplicate pages", can be supported. This query can be used as a spider to collect documents from www.nba.com and to organize the results. The query "retrieve all pages which have links to www.nba.com, group them by country of URL locations, and display the numbers of pages for each country" can be viewed as using a query to conduct a market survey for geographic locations of NBA fans.
We have developed a Web query system, WebDB, to support advanced Web search functionalities. WebDB extracts the Web structure and HTML document internal structure to allow search on Web document structures, such as forms and tables, as well as inter-document linkage information, such as links and anchors. WebDB also supports multimedia search capabilities through a multimedia database system, SEMCOG [9]. In other words, WebDB views the Web as a huge hypermedia database and provides full-fledged database-like query functionality.
In addition, WebDB provides high usability through strong emphasis on computer human interaction aspect. WebDB features a visual query interface and a query generator, WebIFQ (Web In-Frame-Query), to assist users in formulating complex Web queries. WebIFQ visualizes query criteria as query specification processes. Users have a clear overview of query criteria, including linkage and intra-document structures. WebDB supports various automated query relaxation schemes. Alternatively, users can interact WebIFQ for query refinement, relaxation, and reformulation.
We illustrate these features in Fig. 1. Here, a user wants to retrieve all Web pages containing both an HTML form and the keyword "multimedia" (or other terms related by semantic similarity or co-occurrence relationship) which have links to the NEC Web sites in www.ccrl.neclab.com within link depth of 3. The URLs of these NEC pages which are linked by these outside pages are to be projected.
Figure 1 shows that users
use a visual query interface, WebIFQ,
to specify queries, rather than using
the complex query language directly.
The data modeling in WebDB is based on the object-relational concept
and the above query can be specified using WQL
(Web Query Language), based on SQL3, as show in Fig. 1.
Note that the projected string "![]() " is for the purpose of
output presentation and mentions is a string matching
function for a set of strings, such as a keyword list.
" is for the purpose of
output presentation and mentions is a string matching
function for a set of strings, such as a keyword list.
Keywords are one of the most important and frequently used query criteria. WebDB supports two types of automated query relaxation through: s_like function for semantically related terms and cooccurrence function for terms related by co-occurrence relationship. WebDB also allows users to relax, reformulate, or refine queries through interactions with WebIFQ as shown in the centre of Fig. 1. Users can include or exclude particular terms for search or request additional related terms for these terms perpetually. The corresponding query statements are automatically generated by WebIFQ. The query statement in WQL is then processed by the WebDB query processor. The result of the above query may be as follows:
http://www.ece.nwu.edu/![]() shimjh
shimjh ![]() http://www.ccrl.neclab.com/Anecdote
http://www.ccrl.neclab.com/Anecdote
http://www.ece.nwu.edu/![]() shimjh
shimjh ![]() http://www.ccrl.neclab.com/nec_sj/
http://www.ccrl.neclab.com/nec_sj/
http://www.ece.nwu.edu/![]() acura
acura ![]() http://www.ccrl.neclab.com/forum97/
http://www.ccrl.neclab.com/forum97/
![]()
The result is presented to the user through a browser, such as Netscape Navigator. The user can click on any of the presented URLs to browse a particular page or can save these URLs as bookmarks for later use. WebDB also supports slide-show functionality, i.e. automated display of all pages or selected pages (e.g. first 10 pages).
The rest of this paper is organized as follows: We first review
related work. In Section 3, we present an overview
of the Web modeling schemes
and query language design in WebDB.
In Section 4, we present the
design and operations of WebIFQ using some example queries.
In Section
5, we present the system architecture of WebDB and
indexing schemes to support s_like and cooccurrence
functions. We give our conclusions in Section
6.
WebSQL [5] is a project at University of Toronto to develop a Web query facilitation language. It views the Web as a table of documents, in which URL, Title, Type, Last Modified Date are treated as columns. WebSQL extends standard SQL by adding information related to Web documents, such as URL and Title, as column names for queries. Some user-defined functions, such as "mentions", are supported for more fuzzy textual string matching. The query interface provided for WebSQL is form-based, as opposed to the visual query interface and query generator provided by WebDB.
WebLog [6], developed at Concordia University, is a declarative language for Web queries based on SchemaLog. It is intended to be a more complete language to support both query and result rendering formatting. No implementation of WebLog has been reported. TSIMMIS [10] is a project at Stanford University to support query heterogeneous information resources. TSIMMIS is similar to WebLog, but it implements many pre-defined queries for information retrieval so that users need not pose complex queries directly. But, this restricts searches using limited pre-defined queries.
W3QS (WWW Query System) [7] at Technion (Israel Institute of Technology) is a project to develop a high level SQL-like Web query language, W3QL, which views the Web as an ultra large database. W3QL addresses both structure and content. W3QS allows users to specify file types and file names using Perl regular expressions for search. W3QS supports queries on the Web structure by specifying a starting page, a search domain, and the depth of links. In comparison, WebDB also allows users to specify queries with arbitrary Web structures; it is not limited to one link-in or one link-out. Moreover, WebDB features a more user-friendly query interface and supports query relaxation.
HyperFile [8] is a data and query model for hypertext documents.
It introduces sophisticated modeling scheme and focuses query processing
technique. Compared with HyperFile, WebDB is a query system for
hypermedia documents on the
Web. Additionally, WebDB supports additional functionalities, such
as a visual query interface and query relaxation,
to provide higher usability.
To model the Web, we take the approach of object-relational modeling. The intra-document structures are modeled using the object-oriented model while the query language is based on SQL3 (an extension of a relational query language SQL). The Web modeling in WebDB is illustrated in Fig. 2 and is as follows:
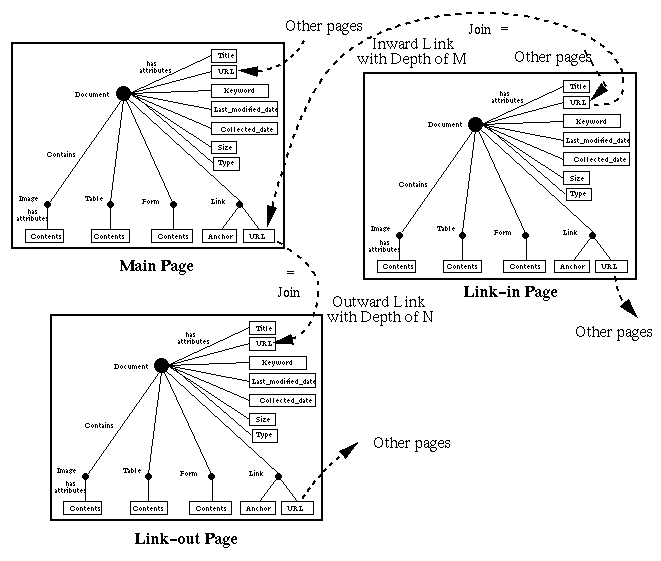
By viewing objects as entities and links as relations, we map the modeling representation in Fig. 2 to the Entity-Relational (ER) model to design the query language. Since we model Web documents as compound objects with structures, our query language is based on SQL3, an extension of the traditional SQL. In the next section, we show how to match Web queries to WebIFQ specifications. By viewing objects as entities and links as relations, we map the modeling representation in Fig. 2 to the Entity-Relational (ER) model for the WQL language design. Since we model Web documents as compound objects with structures, we extend the traditional SQL with the following functionalities:
Doc_x.Link.URL = Doc_y.URL
or
(Doc_x.Link.URL = Doc_z.URL and
Doc_z.Link.URL = Doc_y.URL)
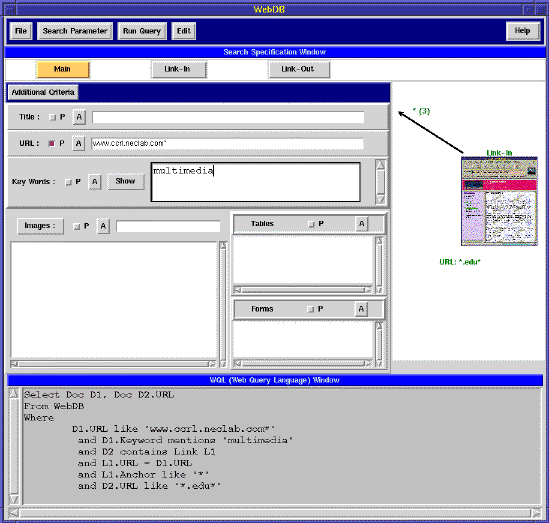
There are three types of windows, namely, main, link-in, and link-out windows. WebIFQ allows users to switch between these windows to specify query criteria associated with each window by clicking the Main, Link-in, and Link-out buttons at the top of Search Specification Window. When users specify query criteria in one window, the system shrinks other windows but display their summarized query criteria.
Figure 3 shows the query specifications from the main window view while the link-in window is shrunk: the user specifies the search criteria for URL, Keywords, and Form. After the user clicks the Link-in button, Search Specification Window switches from the main window view (Fig. 3) to the link-in window view, in which the main window is shrunk while the link-in window is in the normal size.
To specify the criteria associated with linkage, users
click on the link between the main window and link-in or link-out windows.
A window will pop up to allow the users to
specify the anchor
and depth conditions.
WebIFQ visualizes the linkage relationship
between the main window and the link-out window as well as the anchor
and depth conditions.
Multimedia or s_like("multimedia",3) or cooccurrence("multimedia",4)
the system relaxes the query criteria by automatically extending "multimedia" with other related keywords for query processing: three related terms by semantic similarity and four additional terms by cooccurrence relationship. Alternatively, WebDB also allows users to relax, reformulate, or refine queries through interactions with WebIFQ. User can click on the Show button, next to the keyword field, to see the alternative terms. In this example, the user clicks on the Show button, a window shown at the top of Fig. 3 then pops up to allow users to display terms related by s_like("multimedia",3) and cooccurrence("multimedia",4). Users can further relax these terms.
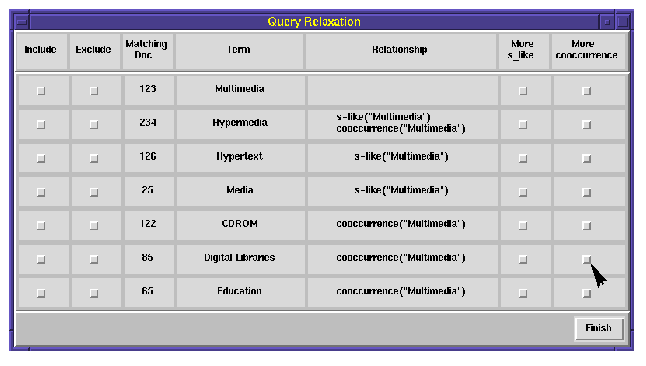
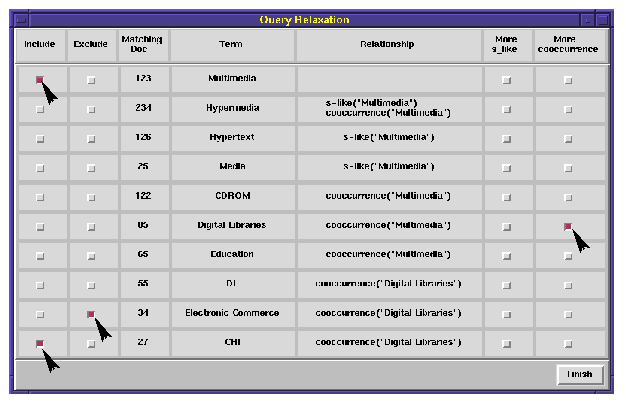
In this example, the user selects "multimedia" and requests the system to provide additional terms related to "Digital Libraries" by co-occurrence relationship (indicated with an arrow). Currently, the system is set to provide 3 additional terms each time. As a result, "DL", "Electronic Commerce", and "CHI" are presented in the bottom of Fig. 4. The user then includes "CHI" and excludes "Electronic Commerce" for search. Note that, the system also shows users the number of documents which contain a particular term. After the query relaxation and reformulation, the new keyword query criteria is as follows:
Multimedia or CHI and not("Electronic Commerce")
For the interactive mode of query reformation,
there are two types of implementation we are considering for different
network capacity.
In a network environment with a high bandwidth,
the interaction between users and the system is conducted in real time.
In a network environment with a low bandwidth,
the system sends a set of terms in advance.
In this query example, the system may send all possible terms and selectivity
for up to four levels of query relaxation interaction at once
in advance: 1,520 terms: 1 + 3 + 4 + (3 x 63) + (4 x
63) (i.e, 3 s_like terms
and 4 cooccurrence terms for 3 additional levels)
and their selectivity.
The cost of sending 1,520 terms is not expensive. This scheme can reduce
future communication setup time for further interaction between clients and
WebDB.
To perform the document gathering task, we have explored Harvest [11], Web search engines (e.g. AltaVista), and so-called spiders to gather Web pages. Currently we utilize Harvest to perform document gathering for specific domains (e.g. www.nba.com). We also use Harvest's parser to extract document level metadata, including URL, keyword, title, last modified date, type, document type, and size. To parse intra- and inter-document information, we have implemented a parser using Perl to extract this information.
Parsing has a great deal of impact on the quality of metadata extracted and query results consequently. Harvest extracts keywords based on whether or not a word is highlighted by special typeface tags, such as boldface, italic, or underlined. To improve the quality of parsing, Document Parser performs additional stemming to remove words in the forms of verb and adverb by consulting Terminology Dictionary (currently WordNet [12] is used). WordNet is a Lexical Database for English. In WordNet, English nouns, verbs, adjectives and adverbs are organized into synonym sets, each representing one underlying lexical concept.
Document Parser also transforms words in the plural form to their singular form. Additional improvements can be made by extracting "terms" rather than "keywords". For example, <b;>Michael; Jordan</b> in an HTML document is identified by Harvest/Essence extraction system as two keywords, michael and jordan. For <b;>Taxi; driver</b>, the keywords are identified as "taxi" and "driver". These two extraction results are not proper since "Jordan" may be matched with the country "Jordan" and "driver" may be matched with a golf "driver".
We are implementing and testing a new parser which further explores sentence structures and examines word forms. The following rules are being added to the parsing procedure:
By applying these rules and consulting Wordnet, the parser can extract
three terms, "Michael Jordan", "fast car", and
"golf shop", from a
highlighted sentence "Michael Jordan drives a fast car to a golf
shop".
Document Indexer is responsible for the following tasks:
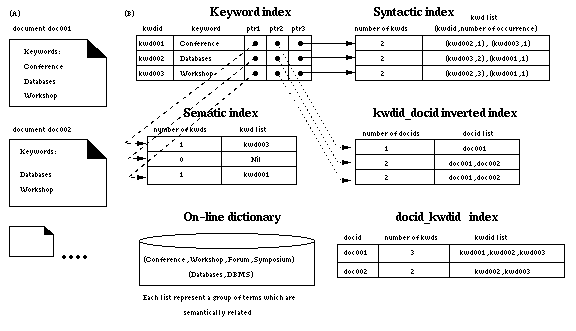
In Fig. 5, we use two documents as examples to illustrate the indexing schemes in WebDB. Each document and keyword have their own identifiers. Two documents are identified as doc001 and doc002 and the keywords "conference", "databases", and "workshop" are assigned as kwd001, kwd002, and kwd003 respectively. Based on docid_kwdid index, we can find keyword IDs for a given document. Based on Keyword index, we can find keywords for a given keyword ID. An inverted index for docid_kwdid index, kwdid_docid inverted index, is constructed to find all document IDs which contain a given keyword. Note that the values of the attribute number_of_docids are the document selectivity for keyword searches. These values are used for query optimization purposes and for showing users as system feedback as shown in Fig. 4.
One keyword may be associated with other keywords by semantics or cooccurrence relationships. In this example, the keyword "conference" is associated with "workshop", "forum", and "symposium" by semantics. Since only the term "workshop" exists in other document (i.e. doc002), an entry (1, kwd003) is inserted into Semantic index for space saving purposes. However, if a user poses a query using the keyword "forum" or "symposium" which does not exist in the collection of WebDB, the system can associate documents with the keyword "conference" or "workshop" by consulting the on-line dictionary during query processing time.
This index is used by the function cooccurrence in relaxing search based on keywords. The cooccurrence function allows users to search documents containing a keyword or other keywords often appearing with this keyword on documents. For example, a relaxed query to find documents with the keyword "Michael Jordan" using the the function cooccurrence may retrieve documents with "Michael Jordan", "NBA", "Chicago Bulls", "Scotty Pippen", etc.
The cooccurrence frequency for two terms can be viewed as the
selectivity for a query with these two terms.
The second entry of Syntactic index indicates
kwd002 and kwd003 co-occur in the same document in two
occasions and kwd002 and kwd001 co-occur in the same document in one
occasion.
Syntactic index
is used for query optimization as well as for system
feedback to show users relevant terms for query reformulation
as illustrated in Fig. 4.
The contributions of this work include the follows:
 Wen-Syan Li is currently a
research staff member at Multimedia Software Department of
Computers and Communications (C&C;) Research Laboratories, NEC USA Inc. He received
his Ph.D. in Computer Science from Northwestern University in December 1995.
He also holds an MBA degree.
His main research interests include
multimedia/hypermedia/document databases, heterogeneous
databases, object-relational database systems, and user interfaces.
Wen-Syan Li is currently a
research staff member at Multimedia Software Department of
Computers and Communications (C&C;) Research Laboratories, NEC USA Inc. He received
his Ph.D. in Computer Science from Northwestern University in December 1995.
He also holds an MBA degree.
His main research interests include
multimedia/hypermedia/document databases, heterogeneous
databases, object-relational database systems, and user interfaces.