Memory-based architecture for distributed WWW caching proxy
Norifumi Nishikawaa,
Takafumi Hosokawaa,
Yasuhide Morib,
Kenichi Yoshidab, and
Hiroshi Tsujia
aHitachi, Ltd., Systems Development Laboratory
Kansai Bldg. 8-3-45 Nankouhigashi, Suminoe,
Osaka, 559 Japan
Tel: +81-6-616-1106, Fax:+81-6-616-1109
nisikawa@sdl.hitachi.co.jp,
hosokawa@sdl.hitachi.co.jp and
tsuji@sdl.hitachi.co.jp
bHitachi, Ltd., Advanced Research Laboratory
Hatoyama, Saitama, 350-03, Japan
Tel:+81-492-96-6111, Fax:+81-492-96-5999
mori@harl.hitachi.co.jp and
yoshida@harl.hitachi.co.jp
- Abstract
-
In networks with heavy WWW traffic, the disk I/O performance
can become a bottleneck for caching proxies. To solve this problem, we
propose a memory-based architecture for WWW caching proxies. The features
of the proposed architecture are (1) a cache contents control that retrieves
only frequently accessed WWW pages, and (2) an automatic distribution mechanism
that enables efficient cache space sharing among multiple caching proxies.
A statistical analysis shows that our approach reduces the required cache
space. It consumes only 1/10 the cache space of current typical proxies
while retaining the same cache hit rate. The reduced cache space enables
the use of fast DRAMs in the caching proxies, and solves the disk I/O problem.
- Keywords
-
Cache; Proxy; Memory-based; Frequency; Distribution
1. Introduction
The World Wide Web (WWW) has recently become a widely used network. It
symbolizes the benefits of a networked society. The rapid growth in the
demand to get logged on, however, has caused heavy network overloads at
times, and has resulted in slow network responses, spoiling benefits of
the Internet. For example, WWW traffic, which had not appeared in the network
traffic statistics a few years ago, has increased and has become the main
network traffic of today [1]. Even though network bandwidths are widened,
WWW traffic continues to grow and consume all of the increases immediately.
To alleviate this situation, WWW caching proxies try to reduce network
traffic by omitting duplicated WWW traffic. Caching technologies such as
hierarchical caching [2] and distributed caching [3] have also been proposed.
These major caching proxies [2,4,5] use a time-to-live (TTL) based cache
replacement strategy. In these proxies, the value of the expire date
field is used as the TTL value of the page. According to this approach,
when the cache storage is full, the cached pages whose TTL values have
expired are replaced with new WWW pages.
In the design of our caching strategy, consideration is important on
the characteristics of WWW traffic. It has been reported [7] that WWW access
patterns follow Zipf's law. That is, the ith frequently accessed
WWW page will be accessed C/i times. Here, parameter C characterizes
the total number of WWW pages. The important consequences of this are
(1)
WWW accesses are localized on a few particular WWW pages, and (2) the remaining
of WWW pages, which will probably not be accessed again, make the conventional
TTL based caching strategy inefficient due to the excessive disk I/O operations.
In this study, we carefully reanalyze WWW traffic and design a caching
strategy that is adapted to typical WWW access patterns. In fact, we propose
the following: (1) a cache contents control that selects only frequently
accessed WWW pages, and (2) an automatic configuration mechanism that enables
the efficient sharing of the cache space among multiple caching proxies.
A statistical analysis shows that our approach can reduce the required
cache space. It consumes only 1/10 the cache space of current typical proxies
while retaining the same cache hit rate. The reduced cache space enables
the use of fast DRAMs in the caching proxies and solves the disk I/O problem.
In the next section, WWW traffic is reanalyzed, and Section 3 presents
our memory based caching strategy. Section 4 explains the experimental
results, and Section 5 discusses related research issues.
2. WWW traffic analysis
It has been reported [7] that WWW access patterns follow Zipf's law. Our
research confirms this with additional findings. In this section, we reanalyze
characteristics of WWW traffic, and also estimate the performance of conventional
caching strategies using the reanalyzed WWW traffic characteristics.
2.1. Characteristics of WWW traffic
Zipf's law is an empirical law about the word frequency in a document.
The following Eq. 1 expresses the law:
frk = C(1)
Here, f is the frequency of a word, and r is the rank
of the word sorted in the decreasing order of frequency. C and k
are constants.
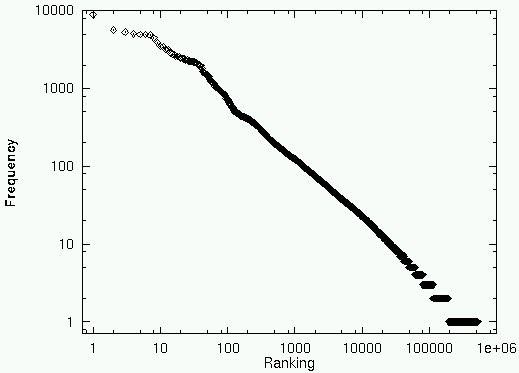
The frequency of WWW pages also follows Zipf's law. Figure 1a shows
the relationship between the access frequency of WWW pages and their rankings.
Although [7] reports k as 1.0 in their traffic, it is 0.75 in the
traffic shown in Fig. 1.
Note that k is an important parameter which characterizes the
distribution of the WWW pages. The WWW access log which we analyzed to
draw Fig. 1a was a 16-day access log involving over 2 million WWW accesses,
which went through our WWW proxies on a firewall machine. The smaller proxy
tended to have a higher k (~0.8) due to the focused interests of
the users whose traffic was supported by the proxy. The larger proxy tended
to have a lower k (~0.6) due to the scattered interests of the users.
|
|
(a)
|
 |
| (b) |
Fig. 1. WWW access frequency distribution.
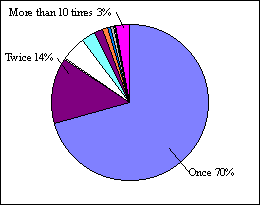
Figure 1b shows the same frequency information as in Fig. 1a but
through a different perspective. As shown in this figure, 70% of the WWW
pages were accessed only once, 14% were accessed twice, and only 3% were
accessed more than 10 times. Note that all of the data involved observations
of more than 2 weeks, and more than 90% of the pages were accessed less
than one time a day.
The important findings are that the WWW pages accessed only once are
meaningless as cache content, and that the more than 90% of pages that
accessed less than 10 times are not important. Therefore, we designed a
caching proxy that only stores frequently accessed pages, to decrease the
required cache space while retaining the same cache hit rate (see Section
3).
2.2. Estimation of cache hit rate and cache capacity
Before explaining our approach, we show some estimations on the required
computing resources using Eq. 1. First, we estimate the cache hit
rate of typical caching strategies with a given cache space.
-
TTL based strategy:
The major caching proxies available today use the TTL based cache replacement
strategy. With this strategy, when the cache storage is full, the cached
pages whose TTL values have expired are replaced with new WWW pages. Since
the TTL of each page is independent from the access frequency of the page,
the caching proxies with this strategy do not distinguish frequently accessed
WWW pages from the rest. They tend to use a huge cache space for less accessed
WWW pages, and remove cached pages randomly when their cache space is exhausted
with unexpired pages. Therefore the hit rate with the TTL based strategy
is:
HTTL(S) = kS/C1/k (2)
Here, S is the size of the cache space, i.e., the cache can store
S WWW pages.
-
Frequency based strategy:
If we know the access frequency of each WWW page, we can improve the
cache hit rate by caching only frequently accessed WWW pages. The hit rate
of this frequency based strategy is:
HFreq(S)=C(k–1)/kS1–k
– (1 – k)SC–1/k (3)
Although an estimation method for the access frequency should be developed,
this strategy gives a better cache hit rate with the same cache space.
Using the above equations, let us compare the hit rates of both strategies.
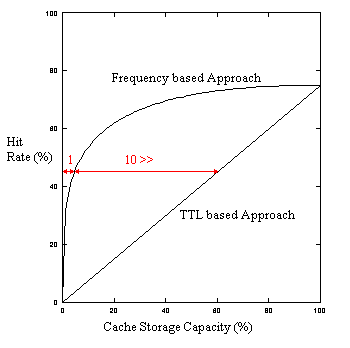
Figure 2 compares the TTL based strategy and frequency based strategy.
Here, the value of constant k is 0.75. As shown in this figure,
the hit rate of the TTL based strategy increases linearly. On the other
hand, the hit rate of the frequency based strategy increases rapidly with
a small cache storage. If we can maintain a caching proxy to keep a 40%
cache hit rate, the frequency based strategy will use less than 1/10 the
caching space of the TTL based strategy while retaining the same cache
hit rate.
 |
|
Fig. 2. Comparison of hit rates (estimated).
|
Table 1 shows the cache space required to achieve a 40% hit rate with
the frequency based strategy (k = 0.75). As shown in this table,
the required cache space is much smaller than that for conventional TTL
based proxies. This table induces us to confirm the possibility of a memory
based architecture.
Table 1. Size of WWW cache storage
|
No.
|
Network bandwidth
|
Total volume of traffic
per week (bytes)
|
Size of cache space
for all pages (bytes)
|
Size of cache space for
40% hit rate (bytes)
|
|
1
|
128 Kbps
|
9.7 G
|
2.4 G
|
62 M
|
|
2
|
1.5 Mbps
|
113.4 G
|
28.4 G
|
725 M
|
|
3
|
45 Mbps
|
3.4 T
|
850 G
|
21.8 G
|
|
4
|
1 Gbps
|
75.6 T
|
18.9 T
|
484 G
|
2.3. Disk I/O limitation
Table 2 shows the number of accesses, i.e., the number of WWW pages that
pass through the proxy, in one second and the number of disk I/O operations
needed for caching, provided a hard disk is used for storing the cache.
If we assume the average WWW page size as 10 Kbytes, a T3 line (i.e.,
45 Mbps line) can transfer 560 pages/sec (= 45 Mbits /(10 Kbytes * 8
bits)). Since the maximum number of disk I/O operations per second is about
100 (i.e., 1 sec = 100 * (8 msec seek time + 2 msec transfer time))
and each WWW access needs at least one disk I/O operation (i.e., read or
write caching operation), a caching proxy for a T3 line needs at least
6 (>5.6) disks. The numbers in Table 2 are calculated in the same way.
The average size of a WWW page is 10 Kbytes in the access log. However,
the extremely large contents, e.g., audio data and video data, make this
value large. If we ignore such large data, the average size of a WWW data
is approximately 3 Kbytes. To create a design with some margin, Table 2
also shows the number of disks for a 3 Kbyte average.
Table 2. Number of WWW access and required disks
|
No.
|
Network bandwidth
|
No. of accesses/sec
|
No. of disks
|
|
10 Kbytes
|
3 Kbytes
|
10 Kbytes
|
3 Kbytes
|
|
1
|
128 Kbps
|
1.6
|
5.3
|
1
|
1
|
|
2
|
1.5 Mbps
|
18.8
|
62.5
|
1
|
1
|
|
3
|
45 Mbps
|
560
|
1.9 K
|
6
|
19
|
|
4
|
1 Gbps
|
12.5 K
|
41.7 K
|
125
|
417
|
We believe that Table 2 clearly shows the limitation of a disk based
proxy architecture. Since Table 1 seems to suggest the possibility of a
memory based architecture, we propose a memory based architecture with
a mechanism that allows the cache space to be shared among multiple caching
proxies.
3. Memory-based distributed caching proxy
3.1. Basic concept
Though Tables 1 and 2 show the adequacy of a memory based caching architecture,
we still need a distribution mechanism to have DRAMs be shared among multiple
caching proxies. The important characteristics of the proposed caching
architecture are as follows:
-
Hierarchical configuration of caching proxies:
The network in a large organization tends to take a hierarchical structure
and therefore multiple caching proxies can be used in a hierarchical configuration.
Our design is aimed to be used in such a hierarchical configuration.
-
Frequency based cache contents control:
Since Fig. 2 showed us the advantage of a frequency based cache replacement
strategy, we choose this as our main strategy. Our approach tries to cache
only frequently accessed pages by analyzing past access logs. Actually,
we only cache WWW pages of frequently accessed sites instead of
frequently accessed pages. This reduces the traffic of the frequency
information exchanged between proxies.
-
Automatic cache distribution control:
Since the maximum DRAM size of low-end computers is 1 Gbyte, we have
designed a distributed cache architecture to use Gbyte level DRAMs by sharing
the storage among proxies. The characteristics of our approach include
automatic cache contents sharing and load balancing among multiple proxies.
3.2. System configuration
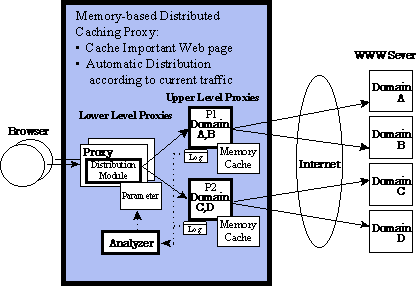
Figure 3 shows the configuration of the proposed distributed caching proxy.
In Fig. 3, the upper level proxies (P1 and P2) construct the distributed
memory cache, and the lower level proxies with a distribution module control
the request flow. The distribution module of the lower level proxies selects
the appropriate upper level proxy. This shows that the contents of a cache
can be distributed and shared among multiple upper level proxies. In Fig.
3, the requests to domain A and B are thrown to upper level proxy P1, and
the requests to domain C and D are thrown to upper level proxy P2.
-
Analyzer:
In most cases, the access patterns of WWW traffic change day by day.
Therefore, the system configuration should be tuned periodically. In order
to achieve automatic reconfiguration, we have designed an analyzer
that generates a new system configuration based on the WWW access logs.
The analyzer adopts the following policies during the generation of each
new configuration:
-
Make the loads of each of the upper level proxies even by making the sum
of past access counts of WWW pages for each proxy even,
-
If a WWW page is cached in the current configuration, assign the same upper
level proxy to the same WWW page in future configurations.
We also proposed a different method to generate system configurations [8].
Although it can automate the configuration for a complex network topology,
it lacks the second feature.
-
Distribution module:
The distribution module which gives each request to an appropriate
upper level proxy follows the configuration generated by the analyzer.
This module periodically checks if the configuration has changed or not.
If the configuration has changed, it reloads the new configuration from
the analyzer. To reduce the amount of configuration information, it only
holds information on frequently accessed WWW sites instead of frequently
accessed WWW pages. Thus, the upper level proxies only cache WWW pages
of frequently accessed sites instead of frequently accessed pages.
-
Upper/lower level proxies:
The upper level and lower level proxies have two important features:
(1) they use DRAM memory for cache storage, and (2) they use an LRU (Least
Recently Used) based cache replacement strategy. Although this strategy
has a worse cache hit rate with a very small cache space S, the
experimental results in the next section show that the use of a configuration
generated by the analyzer and careful tuning of the cache storage size
make this strategy a good substitute for a pure frequency based strategy.
 |
|
Fig. 3. Configuration of memory based distributed caching
proxies.
|
4. Experimental results
Although the advantage of the frequency based strategy over the TTL based
strategy is a statistical fact, we have to estimate the frequency of each
WWW page. A site based frequency analysis and the LRU based caching strategy
are the methods we employ to estimate the frequency. This section describes
results from experiments we performed to evaluate our strategy using simulation.
4.1. Conditions of the simulation
Figure 4 illustrates the system configuration we assumed for the simulation
study. In this simulation, we assumed a hierarchical caching system in
a large organization. The lower level proxies (D1–D3) represents the
caching proxies running at the department level in a company. The upper
level proxies (F1–F4) represent the proxies on the firewall of the company.
In the simulation, we assumed every three departments had 13 browsers.
Note that the apparent redundancies in the WWW accesses were removed by
the local caches of the browsers (C1–C39); therefore achieving a high
hit rate for the upper level proxies was to be quite a difficult task.
To make a simulated WWW load, we assumed the requests of the browsers
by dividing the accesses in the log described in Section 2. We used a subset
of the log which corresponded to accesses over 10 days. Therefore, the
simulation assumed a virtual WWW access load from 39 browsers over 10 days.
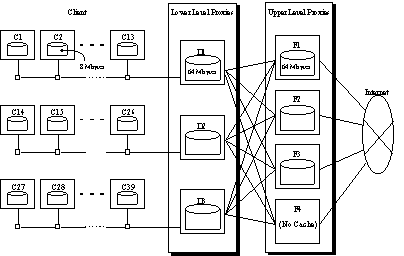 |
Fig. 4. System configuration for the simulation.
In the simulation, we measured the cache hit rate and the traffic reduction
of (1) a hierarchical caching system involving the proposed approach, and
(2) a similar hierarchical caching system which involving a simple round-robin
distribution.
-
Detailed settings for the proposed approach
We assumed 8 Mbyte local cache for each browser, and 64 Mbyte cache
storage for the upper and lower level proxies. These numbers were selected
to be small enough to enable typical computers (e.g., machines used as
user terminals and departmental severs) to use DRAM memory for the caching.
Since we assumed the use of standard browsers, we assumed that the browser
level caches used the standard LRU caching strategy. However, we applied
the frequency based cache contents control to the lower level caching proxies,
and the frequency based distribution to the upper level proxies. In other
words, if the access frequency of a URL's site was within the top 10% of
all sites, the lower level proxies would try to cache them. The upper level
proxy will be selected based on the configuration generated by the analyzer.
The system configuration specifies the proxy for each URL of the frequently
accessed sites. F1, F2, and F3 are selected based on the configuration.
Other requests, i.e., for the non-frequently accessed URLs, are forwarded
to the proxy F4. Here the proxy F4 has no cache storage because it is assumed
that the access frequencies of the URLs requested through proxy F4 are
low and caching these URLs will have no effect. The access frequency is
assumed to be calculated from the access logs gathered from all of the
upper level proxies (F1–F4), and the analyzer generates the system configuration.
The configuration is updated every day from the access logs of the past
seven days. Since the first day in the simulation lacks such access information,
F4 treats all of the requests on this day. Therefore, only the browser
level caches are used on the first day.
-
Detailed settings for the round-robin method
To compare with traditional methods, we also measured the cache hit
rate and the traffic reduction with the round-robin distribution method.
We assumed the same cache capacities, i.e., an 8 Mbyte local cache for
each browser, and 64 Mbyte cache storage for the upper and lower level
proxies. Therefore, the only difference was in the cache control strategy.
In this method, all requested URLs were cached, and the LRU based cache
replacement algorithm was used. To distribute all requests to the upper
level proxies, each lower level proxy performed distribution to each upper
level proxy in a sequence. Since it was difficult to implement a shared
LRU cache with this round-robin distribution method, we assumed that the
cache storage for the upper level proxies was not shared. Note, however,
that this method still has a higher hit rate than the traditional distributed
cache approach which uses a TTL-based strategy.
In both cases, we did not consider the revalidation of the cached documents.
If a page was in the cache, the cache returned the page to the requester;
therefore, the traffic to the upper level proxies is not mentioned.
4.2. Results
Cache hit rate of the client caches
Table 3 shows the average hit rate observed for the client caches during
10 days. The average hit rate was approximately 16.3%.
Table 3. Average hit rates for client caches
| Dept. name |
No. of clients |
No. of requests |
No. of requests
to dept. proxies |
Hit rate |
| D1 (C1-13) |
13 |
255,040 |
213,601 |
16.2% |
| D2 (C14-26) |
13 |
373,731 |
313,600 |
16.0% |
| D3 (C27-39) |
13 |
266,355 |
188,077 |
16.9% |
| Total |
39 |
855,126 |
715,278 |
16.3% |
Cache hit rate of the proxies
Figure 5 shows the transition of the hit rates for the lower level
proxies. As shown in this figure, the hit rate of our approach (average:
10.6%) is higher than that of the simple round-robin distribution approach
with LRU based strategy (average: 7.9%). The selection of the frequently
accessed sites by the analyzer contributed to this improvement.
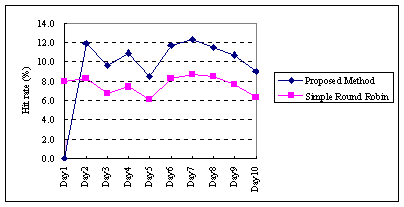 |
Fig. 5. Hit rates of lower level proxies.
Figure 6 shows the transition of hit rate for the upper level proxies.
As shown in the figure, the hit rate of the round-robin method (average:
1.9%) is much worse than that of our approach (average: 8%). This figure
clearly shows the advantage of our approach. Note that the first day's
hit rate of our approach is 0 because there is no distributed information
and all requests are forwarded to proxy F4 which has no cache. However,
this difference does not appear in the continuous operation of proxies.
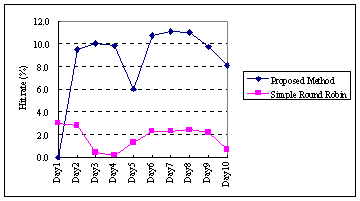 |
Fig. 6. Hit rates of upper level proxies.
Request distribution
Figure 7 shows the number of requests to each of the upper level proxies
(our approach only). As shown in the figure, the loads of caching proxies
F1 to F3 are balanced. The load of proxy F4 is higher than those of the
other proxies, because of the forwarding to proxy F4 of all requests to
URLs of lower access frequency sites (i.e., not the cache candidate URLs).
However, proxy F4 is free from the overhead of caching operations.
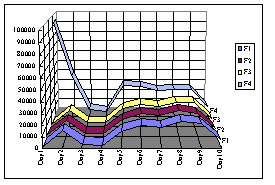 |
Fig. 7. Loads of each upper level proxy.
Traffic reducing rate by distributed caches
Figure 8 shows the transition of the total hit rates for the hierarchical
caching systems. The average rates of our approach and the round-robin
approach are 30.4% and 25.4% respectively.
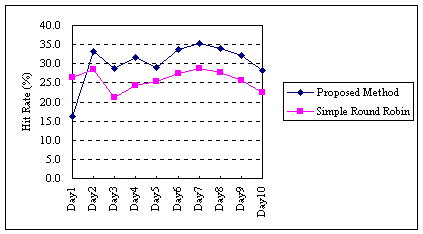 |
Fig. 8. Rate of traffic reduction.
In summary, the simulation results show the following advantages of our
approach:
-
Frequency based cache content selection improves the hit rate of the lower
level proxies 2.7% (i.e., from 7.9% to 10.6%).
-
A frequency based cache distribution improves the hit rate of the upper
level proxies 6.1% (i.e., from 1.9% to 8%).
-
The overall traffic reduction rate (30.4%) of the proposed method is 1.2
times higher than that (25.4%) of the simple round-robin LRU method.
Note that the simple round-robin LRU method has a higher hit rate than
the traditional cache system which uses a TTL based strategy. The cache
hit rate of a TTL based system is negligible with a storage that gives
a 25% hit rate for an LRU based system (see Fig. 2). This significant
difference in the cache hit rate with a relatively small cache storage
makes our DRAM-based caching architecture feasible.
5. Discussion
5.1. Comparison with ICP-based approach
Internet Caching Protocol (ICP) [6] based distributions are widely used
to share the cache contents among the caching proxies. Multiple caching
proxies can use this special protocol to exchange their cache contents.
However, Zipf's law suggests a drawback of this approach. According
to Zipf's law, there are only a few frequently accessed WWW pages but many
rarely accessed WWW pages. The common interests of users of a proxy determine
the few frequently accessed WWW pages. If the common interests of user
groups are different for the caching proxies, the ICP can not improve the
cache hit rate because the cache contents are very different. In such a
case, the ICP will only slow down the system response by waiting for sibling
responses which tends to make requests fail.
To improve the cache hit rate by the ICP, careful coordination of the
sibling proxies is indispensable. Since our approach can increase the similarity
of cache contents, it is possible to use our approach with an ICP based
method. However, such an implementation remains as a future issue.
5.2. Comparison of modeling methods
According to [10], Zipf's law underestimates the cache hit rate for the
LRU strategy. They proposed another estimation method [9] to treat this
phenomenon. We also confirmed their finding with our proxy logs.
Our hypothesis behind this reason is the effect of users who do not
use the local cache. A single user tends to access the same page repeatedly
at short intervals, and this makes the LRU's cache hit rate higher than
expected by shortening the average access interval. If we were to modify
the access log so that accesses to the same WWW pages from the same clients
were removed, the result of the simulation would match Zipf's law's estimation.
This supports our hypothesis.
This phenomenon still requires further investigation. However, Zipf's
law overestimates the cache space for particular cache hit rates but such
overestimation do not obstruct our memory based architecture. We still
use modeling techniques based on Zipf's law. Note that our approach is
suitable for hierarchical cache configurations.
To estimate the cache hit rate of upper level proxies, which treat the
traffic affected by lower level proxies, using Zipf's law seems to be adequate.
5.3. Data size
The size of the data transferred between the analyzer and proxies should
be considered for implementation. The size of the logs and control information
are about the following values from our simulation described in Section
4.
-
Size of logs:
If a proxy uses the CERN type log format, the average size of one record
is about 100 bytes. According to the access logs in Section 2, the average
WWW access per day is about 140,000. Therefore, the log size transferred
to the analyzer is about 14 Mbytes per day.
-
Size of control information:
On the other hand, the number of sites accessed per day is about 20,000.
If we assume that distributed caches store only WWW pages of the top 10%,
and the average size of a record is 50 bytes, the control information,
which specifies the frequently accessed WWW pages and the upper level proxies
for the pages is about 100 Kbytes.
From the discussion above, the size of the control information is small
enough. However, the size of the logs is not. Therefore, summarization
and/or compression of the logs is desirable. This also remains as a future
issue.
6. Conclusion
This paper proposed the concepts of a DRAM based distributed cache system,
and showed some experimental results.
We showed that a frequency based cache replacement strategy can reduce
the required cache space to 1/10, for a 40% hit rate, that of the typical
TTL based cache algorithm. Furthermore, we showed a possibility of the
fast speed for the DRAM based distributed architecture. The characteristics
of the proposed architecture are (1) a cache contents control that retrieves
only frequently accessed WWW pages, and (2) an automatic distribution mechanism
that enables the efficient sharing of the cache space among multiple caching
proxies.
We compared the performance of the proposed method and a simple round-robin
based method through simulations. The experimental results showed that
the significant improvement of the cache hit rate with a relatively small
cache storage enables our architecture to use DRAMs for cache storage.
References
| [1] |
Wide Project, Wide Project Research Report, 1995,
1996 (in Japanese). |
| [2] |
A. Chankhunthod, P. B. Danzig, C. Neerdaels, M. F. Schwarts, and K.
J. Worrill, A hierarchical Internet object cache, in: USENIX
'96, 1996, pp. 153–163.
|
| [3] |
J. Gwertzman and M. Seltzer, The case for geographical push-caching,
in: HotOS Conference,
ftp://das-ftp.harvard.edu/techreports/tr-34-94.ps.gz |
| [4] |
Microsoft: Microsoft proxy server, http://www.microsoft.com/proxy/default.asp |
| [5] |
Squid Internet object cache, http://www.nlanr.net/squid/ |
| [6] |
Internet Cache Protocol (ICP), Version 2, 1997, http://ds.internic.net/rfc/rfc2186.txt
|
| [7] |
S. Glassman, A caching relay for the World Wide Web,
in: Proc. 1st International
Conference on the World Wide Web, 1994, http://pigeon.elsevier.nl/cgi-bin/ID/WWW94
|
| [8] |
K. Yoshida, WWW cache layout to ease network overload, in: Proc.
of AISTATS'97, 1997, pp. 537–548. |
| [9] |
R. Mattson, J. Gecsei, D. Slutz and I. Traiger, Evaluation techniques
and storage hierarchies, IBM System Journal, 9: 78–117,
1970. |
| [10] |
V. Almeida, A. Bestavros, M. Crovella and A. de Oliveira, Characterizing
reference locality in the WWW, in: Proc.
of PDIS'96, The IEEE Conf. on Parallel and Distributed Information
Systems,
1996. |
Vitae
 Norifumi Nishikawa is a research scientist of Systems Development Laboratory, Hitachi
Ltd. He received the M.S. degree in computer science in 1991 from University
of Kobe. His current research interest includes networked-based application
systems and database management system. He is a member of the Information
Processing Society of Japan.
Norifumi Nishikawa is a research scientist of Systems Development Laboratory, Hitachi
Ltd. He received the M.S. degree in computer science in 1991 from University
of Kobe. His current research interest includes networked-based application
systems and database management system. He is a member of the Information
Processing Society of Japan.
|
| |
 Takafumi Hosokawa is a research scientist of Systems Development Laboratory, Hitachi
Ltd. He received the M.S. degree in physics in 1996 from University of Kyoto.
His current research interests are network-oriented service application
systems for general public. He is a member of the Information Processing
Society of Japan.
Takafumi Hosokawa is a research scientist of Systems Development Laboratory, Hitachi
Ltd. He received the M.S. degree in physics in 1996 from University of Kyoto.
His current research interests are network-oriented service application
systems for general public. He is a member of the Information Processing
Society of Japan.
|
| |
 Yasuhide Mori is a research scientist of Advanced Research Laboratory, Hitachi
Ltd. He received the M.S. degree in physics in 1991 from University of Tokyo.
His current research interests are pattern recognition, neural networks,
and nonlinear dynamics. He is a member of the Physical Society of Japan,
and Japanese Neural Network Society.
Yasuhide Mori is a research scientist of Advanced Research Laboratory, Hitachi
Ltd. He received the M.S. degree in physics in 1991 from University of Tokyo.
His current research interests are pattern recognition, neural networks,
and nonlinear dynamics. He is a member of the Physical Society of Japan,
and Japanese Neural Network Society.
|
| |
 Kenichi Yoshida is a senior research scientist of Advanced Research Laboratory,
Hitachi Ltd. He received his Ph.D. in computer science from Osaka University.
He received the best paper awards from Atomic Energy Society of Japan,
from The Institute of Electrical Engineers of Japan, and from Japanese
Society for Artificial Intelligence. His current research interest includes
machine learning, knowledge representation, and expert systems.
Kenichi Yoshida is a senior research scientist of Advanced Research Laboratory,
Hitachi Ltd. He received his Ph.D. in computer science from Osaka University.
He received the best paper awards from Atomic Energy Society of Japan,
from The Institute of Electrical Engineers of Japan, and from Japanese
Society for Artificial Intelligence. His current research interest includes
machine learning, knowledge representation, and expert systems.
|
| |
 Hiroshi Tsuji received the B.E., M.E., and Ph.D. degrees from Kyoto Univ. in 1976,
1978 and 1993, respectively. In 1978, he joined Sys. Dev. Lab, Hitachi, Ltd.
In 1987 and 1988, he was a visiting researcher at Carnegie-Mellon University.
Hiroshi Tsuji received the B.E., M.E., and Ph.D. degrees from Kyoto Univ. in 1976,
1978 and 1993, respectively. In 1978, he joined Sys. Dev. Lab, Hitachi, Ltd.
In 1987 and 1988, he was a visiting researcher at Carnegie-Mellon University.
His research interests includes knowledge-based system and groupware
such as workflow and information sharing. He is a member of the ACM, IEEE-CS,
IPSJ, and JSAI. Now he is engaged in social information sharing architecture
at Kansai Systems Lab., Hitachi, Ltd.
|