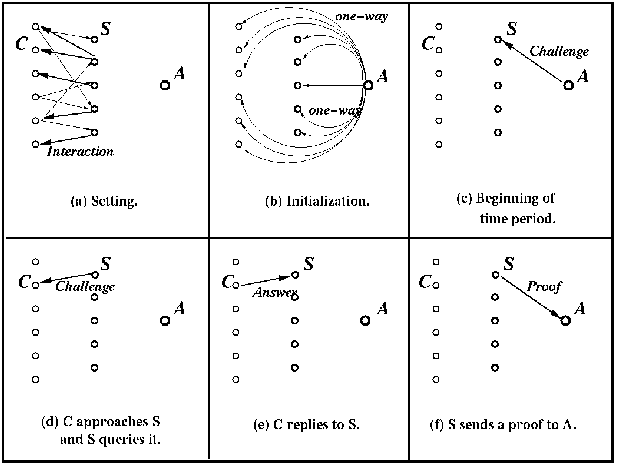
Fig. 1. The setting of the metering scheme.
Department of Applied Mathematics and Computer Science,
Weizmann Institute of Science,
Rehovot 76100, Israel
naor@wisdom.weizmann.ac.il and
bennyp@wisdom.weizmann.ac.il
There has been a considerable amount of work on securing online payments. However most of the revenues from Internet ventures do not come from direct sales: the largest sums of money are by far those paid for advertising and for connectivity to the Internet. There are many different forecasts for the future distribution of Internet revenues (see [12] for a discussion of some of these projections), but many of them agree that advertising and connectivity will remain the major sources of income from the Internet. In light of these figures it is surprising how little research has been conducted towards securing the accounting mechanisms that are used by advertising and connectivity providers.
We propose schemes that validate measurements of the amount of service that servers perform for their clients, in a manner which is efficient and is secure against fraud attempts by servers and clients. There are two main applications for such schemes: a certified measurement of the usage of Web sites, and measurement of the amount of traffic that a communication network delivers. Both these applications have a tremendous financial importance which makes them targets for fraud and piracy, as was the case with software and pay TV piracy which became multi-million dollar businesses (see for example [10] for a detailed description of TV piracy practices). It must be concluded that it is essential to develop mechanisms that ensure the authenticity and accuracy of usage measurements against malicious and corrupt parties. We further demonstrate the necessity for secure metering in Section 2, where we present some additional applications.
The principal property of the metering schemes which we introduce is that the server is able to present to an auditor a short proof for the number of services it has performed. This proof can be verified by an auditor. Suppose that a Web server generated a proof for serving one million different clients. Then in our schemes this is a proof in its mathematical sense, i.e. its security is based on mathematical (cryptographic) principles, and a legitimate proof cannot be generated unless the server has actually served one million clients. The proof is short, i.e. the length of a proof for serving n clients is fixed (independent of n) or is at most logarithmic in n. This is essential since otherwise the task of sending and verifying such proofs would burden the auditor, since they would be of the same order of complexity as the original services. It is also important that the clients would not be overloaded by this auditing process. In the schemes we propose the modifications the clients should perform are minimal (e.g. a simple plug-in in the client's browser) and there is no need to change the communication pattern. Each client should obtain (only once) some personalized information from the auditor, which requires a single message to be sent from the auditor to the client. The schemes can also be extended to protect the user's privacy and not enable a mechanism for tracing their activities. We describe the different properties that the proofs should attain in Section 3.2.
For the application of Web site usage metering we also present a method to measure the turnover of clients. That is, to determine the rate with which new clients approach the site. This data is important for advertisers. Such measurement can also prevent sites from using a fixed group of (possibly corrupt) clients to prove high popularity.
We are in the process of implementing a prototype of a secure Web site usage metering system. See Section 4.7 for details.
Most of the revenues of Web sites come from advertisement fees. Although there are different forecasts for the market share of online advertising, the estimations are that very large sums of money will be invested in this media (e.g. the spending in year 2000 on online ads is estimated by a Cowles/Simba forecast from June 1997 to be $2.57 billion, and by a February 1997 forecast of Jupiter Communications to be $ 5.7 billion). Like in every other advertising channel, Web advertisers must have a way to measure the effect of their ads, and this data affects the fees that are charged for displaying ads. Advertisers must therefore obtain accurate and impartial usage statistics about Web sites and about page requests for pages which contain their ads. Web sites on the other hand have an obvious motivation to inflate their usage reports in order to demand more for displaying ads.
In the pre-Web world there were two main methods for measuring the popularity of media channels, sampling and auditing. Sampling, like the Nielsen rating system for TV programs, is survey based. It picks a representing group of users, checks their usage patterns and derives usage statistics about all the users. In traditional types of media like television this method makes sense since users have a relatively limited number of viewing options to choose from. These types of media use broadcast, which operates in a one-to-many communication model. The Web operates in a many-to-many communication model and offers millions of Web pages to visit. Therefore although sampling based metering services are offered for the Internet, they do not provide meaningful results for any but the most popular Web sites.
Auditing is performed by trusted third party agencies, like the Audit Bureau of Circulations (ABC) which audits print circulation. Although such information regarding Web sites is often offered by the sites themselves, it should be taken with a grain of salt. The Coalition for Advertising Supported Information and Entertainment (CASIE) states in its guidelines for interactive media audience measurement [2] that ``Third party measurement is the foundation for advertiser confidence in information. It is the measurement practice of all other advertiser supported media''. There are a number of companies (like Nielsen/IPRO, NetCount, etc.) which offer third party based audit services for the Internet. They typically install some monitoring software at the server that operates the site. However, the reliability of such audit data depends on the site providing accurate data or not breaking into the monitoring module. Sites have a huge financial interest to exaggerate their popularity. The lesson learnt from software and pay-TV piracy (e.g. [10,1]) is that such financial interests lead to corrupt behavior which overcomes any ``lightweight security'' mechanism.
Today most Web advertising is displayed on a very small number of top popularity Web sites, like Yahoo! or CNN. It may be plausible that in spite of the great financial motivation such established sites will not provide inflated usage reports or break into audit modules that report their activities. In fact, Rick Boyce, vice president and director of advertising sales at HotWired, has been quoted as saying that ``No one has come up to me yet and said `We won't buy your site because you haven't had an independent audit' '' [13]. However, while this may be true for the big sites, a large amount of advertising is displayed on smaller scale sites. It can also be argued that one of the main reasons that drive advertisers to use only the biggest sites is the lack of reliable audit data on smaller scale sites. The Web is so attractive because one can set a site of interest to say, 10,000 users worldwide. This number may suffice to attract some advertisers, provided there are reliable usage statistics.
Advertisers can learn about the exposure of their ads by counting ``click throughs'', i.e. the number of users who clicked on ads in order to visit the advertiser's site. Doubleclick reported in 1996 that 4% of the visitors who view an ad for the first time actually click on it. This ratio changes according to the content of the ad, and therefore gives very limited information to the advertiser. Another method that advertisers can use is to display the ads from their own server (even when they are displayed in other sites) and eliminate the risk of unreliable reports from sites. However, this method burdens the advertiser with sending its ads to all their viewers and prevents the distribution of this task. The original communication pattern is not preserved since a new channel (between the advertiser and the client) is used. The load on the advertiser's server is huge and is surely not acceptable for a one-time advertiser. This solution is non-scalable, introduces a single point of failure (the advertiser), and is also insecure against ``fake'' requests created by the site displaying the ads.
Currently there is no single accepted standard or terminology for Web measurement. Novak and Hoffman [15] argue that standardization is a crucial first step in the way for obtaining successful commercial use of the Internet. They also claim that interactivity metrics rather than the number of hits or the number of visitors should be used to meter a site's popularity. We define our schemes to count the number of visits that a Web site receives. For the purpose of this exposition we do not need to define a visit precisely. For example, it can be set to be a click, a user, a session of more than some threshold of time or of page requests from a single user, or any similar definition. The main requirement is that the measurement be universal to all clients and can be consolidated (for instance, a detailed report of the path of pages that each client went through in its visit cannot be consolidated into a single result. The number of clients whose visit lasted more than 15 minutes can be represented as a single number). The emphasis in this paper is in obtaining reliable usage statistics even when servers may try to act maliciously, and not in defining the type of statistics that are needed.
Previous work (e.g. [16]) discussed the problems caused by caching and by proxy usage, which hide usage information from Web servers. Possible solutions like temporal analysis, cache busting, and sampling were suggested.
We are only aware of a single attempt to handle the problem of corrupt servers who present exaggerated usage statistics. Franklin and Malkhi [8] were the first to consider the secure metering problem in a rigorous theoretical approach. Yet their solutions only offer ``lightweight security'' and as such can be circumvented. Such solutions cannot be applied if there are strong commercial interests to falsify the metering results.
This paper presents the motivation and the basic ideas of secure metering schemes. A companion paper [14] gives more technical details about these schemes.
The Internet is based on packet switching, i.e. there is no dedicated path between two parties which are communicating through the Internet, but rather each packet of information is routed separately. The Internet is essentially a network of networks and packets are typically routed through several different networks. These properties complicate pricing and accounting mechanisms for Internet usage, and indeed the most common pricing method is to charge a fixed price which is independent of the actual number of packets which are transferred. Pricing theory based analysis [9,6] indicates that pricing Internet services according to the actual usage (at least at times of network congestion) is superior in terms of network efficiency. Usage based pricing has a disadvantage of incurring accounting and billing costs. It is impractical to create detailed account reports (similar to telephone accounts) due to the huge number of packets. Some are suggesting to measure usage using sampling [4] or only at times of congestion (however, even producing reports for a sample of say, 1/1000 of the packets creates inconceivably large reports). MacKie-Mason and Varian [9] also expect breakthroughs in the area of in-line distributed accounting that will lower the costs of Internet accounting.
The problem of designing accounting mechanisms which will operate with the existing infrastructure of the Internet attracted some previous research [5,7]. Our schemes are innovative in providing an efficient and secure measurement of the number of packets that a network transfers for other networks, and producing a short proof for this count. The schemes are secure against tampering attempts by networks which try to inflate the count of the packets which they communicated. Considering the amount of money that is expected to be paid for Internet connectivity (e.g. 50 million users who pay $20 per month equal $12 billion annually), it is apparent that secure accounting is essential.
A few other applications for the metering schemes can be
In this section we describe the general setting in which the metering schemes operate and give a high level description of their operation. We also specify the requirements which the schemes should satisfy. In order to be more specific we concentrate from now on on schemes for metering visits to Web sites.
The setting and the general operation of the metering schemes are depicted in Fig. 1. There are servers (denoted S) and clients (denoted C), which interact, and the metering scheme should measure this interaction (Fig. 1a). We introduce a new party, the audit agency A which is responsible for providing measurement reports about all servers. The audit agency is trusted by all parties for the task of providing accurate reports (but not for other tasks, e.g. servers do not want to provide a full list of all their clients to A). The metering system measures the number of visits that each server receives in a certain period of time (e.g. a day). Alternatively, the system can be set so that each server will provide a proof to the audit agency as soon as it receives k new visits (where k is a system parameter). We do not define what a visit is, and it can be any unit which is of of interest (e.g. a ``hit'', a ``click'', a page visited by a user, a session of a single user, a session of more than some threshold of time or hits, etc.).
The operation of the system is divided into the following stages:
This is the most general form of a metering scheme. In order to save communication rounds it is preferable (and can be achieved with the schemes we describe) that no explicit challenges are sent, but rather the challenges can be implicitly computed by the servers and clients.
Note that the only communication between the audit agency and the clients is a single one-way initialization message in the initialization stage. The changes in the operation of the client are minimal. They should ideally be coded in the Web browser but can also be operated from a plug-in or a helper application (see Section 4.7).
Fig. 1. The setting of the metering
scheme.
A metering scheme should be designed to satisfy the following requirements:
We found several directions for designing secure and efficient metering schemes, based on hash trees, pricing-via-processing, secure function evaluation and micropayments. They are described in the detailed technical manuscript [14]. The metering schemes with the best properties are based on secret sharing. We describe these schemes in this section, but refer the reader to [14] for more technical details.
A k-out-of- n secret sharing scheme enables a secret to be divided into n shares such that no k-1 shares reveal any information about the secret, but any k shares enable to recover it. We start our construction from the secret sharing scheme of Shamir [17]. In this scheme the secret can be any value V in a finite field F (e.g. V is an integer between 0 and p-1 where p is prime). The party that wishes to perform the secret sharing chooses a random polynomial Q(x) of degree k-1, subject to the condition Q(0)=V. The n shares are the values Q(1),Q(2),...,Q(n). Given any k of them it is possible to perform a Lagrange interpolation and obtain Q and V=Q(0). It is easy to verify that no k-1 shares define Q(0).
The rational behind establishing metering schemes on secret sharing is to give each client a share, which it will send to a server when visiting it. Then after serving k clients the server recovers the secret, which is the proof for serving k clients. However, this straightforward implementation has only a single secret and cannot be used by many servers or for several measurements. There is also the problem of protecting the server from malicious clients who send incorrect shares which cause an incorrect ``secret'' to be computed. Our schemes solve these problems and others.
The basic scheme has three parameters, k, d, and p. It enables servers to prove that they received k visits, where k is a predefined parameter (we show how to adapt the system to measure different numbers of visits in Section 4.5). The parameter d defines the number of measurements for which the scheme can be used, and p is the probability with which a server can generate a proof without serving k clients. Following is a description of the scheme set to enable servers to prove that they served k visits during a day.
Initialization: The audit agency generates a random polynomial Q(x,y) over the field Zp, of degree k-1 in x and d-1 in y. Each client C receives the polynomial Qc(y)=P(C,y) which is constructed from P by substituting C for x, and is of degree d-1 in y.
Operation: A client C that visits server S at date t should send it the value Qc(St) =P(C,St) (assuming for simplicity that St, the concatenation of S and t, is in Zp).
Proof generation: Consider the polynomial (in x) P(x,St). After serving k clients in day t, S can interpolate this polynomial and calculate P(0,St). This is the proof for serving k clients in day t. The audit agency can verify this value by evaluating the polynomial P at this location (this can be done efficiently since every summand in which x is of degree higher than 0 equals 0).
The scheme is depicted is Fig. 2. The security of the system is analyzed in [14]. We emphasize that if the scheme is used for at most d measurements, a server who is not being helped by other servers or clients has a probability of at most 1/p in generating a correct proof without serving k visits. The scheme is also secure against a coalition of b corrupt servers for at least d/b measurements by each of them.
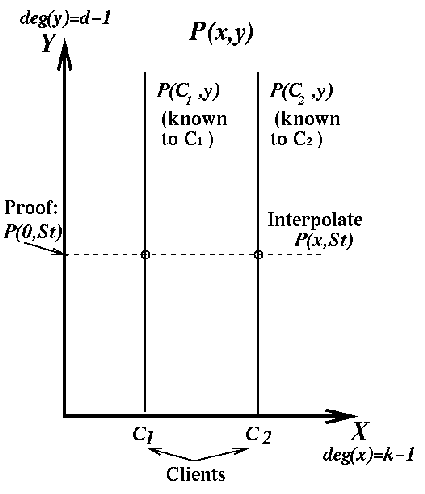
Fig. 2. The basic secret sharing based
metering scheme.
It is possible to add further features to the basic scheme, while conserving or improving its efficiency. The details of the implementation of these features are described in [14].
Robustness: The basic scheme is insecure against clients who send incorrect values instead of their shares, which cause the server to compute an inaccurate polynomial and a false proof. The error correcting properties of Reed-Solomon codes can be used to reconstruct the secret even in the presence of several corrupt shares [11], but this does not help if there are too many corrupt shares.
We can enable the server to verify the correctness of the information it receives from clients. To achieve this property the servers and clients are only required to evaluate a single additional polynomial (of small degree).
Increased efficiency and lifetime (using classes or polling):
A client who sends a share to a server has to evaluate a polynomial of
degree d-1, a computation which requires d multiplications
using Horner's rule. The basic operations can be very efficient since they
are performed in the field Zp where 1/p is the error probability
and can be set to be 32 bits long (they should not be confused with the
operations required for public key cryptography, since the latter are over
a large field (e.g. field elements are 768 bits long)). The server should
perform a polynomial interpolation which requires ![]() multiplications. The amortized cost of a visit is therefore
multiplications. The amortized cost of a visit is therefore ![]() modular multiplications of say, 32 bit numbers. This cost is relatively
small, but for large values of k it might be significant.
modular multiplications of say, 32 bit numbers. This cost is relatively
small, but for large values of k it might be significant.
It is possible to decrease the the overhead of the scheme using the following idea: Assume that clients are divided at random into n classes, then instead of proving a total of k visits the server can be asked to prove k/n visits from a random class. An application of this idea reduces the overhead and increases the lifetime of the scheme by a factor of about n.
A scheme for unlimited use: The number of measurements in which the scheme could be used is of the same order as d, the degree of y in P, times the number of classes n. This number can be large enough for many applications (e.g. when d=100 and n=100). However, as was suggested to us by Omer Reingold, it is also possible to construct a metering scheme which can operate for a virtually unlimited number of time periods. The security of the scheme is based on the Diffie-Hellman assumption [3]. It requires the parties to perform in each visit an exponentiation (over a large finite field, e.g. of length 768 bits).
Anonymity: Many clients wish to remain anonymous. An even stronger property is unlinkability which prevents identifying different visits as originating from the same clients. It might seem that secret based metering schemes cannot obtain this property since a client C\ always sends a share which is a value of the polynomial P at a point whose x coordinate is C. However, it is possible to change the scheme and obtain unlinkability of visits without considerably affecting the complexity.
Assume that a metering scheme is set to measure whether sites receive k=100,000 visits. The scheme is used for 100 measurements (e.g 100 days), and should be secure against coalitions of up to 10 sites.
A straightforward implementation of the basic scheme uses a polynomial P(x,y) in which x is of degree k=100,000 and y is of degree 1000 (the number of days times the maximum size of a corrupt coalition). If we require the probability with which the scheme can be broken to be one to four billion the polynomial can be defined over a field whose elements are 32 bits long. Each client receives a polynomial of degree 1000 whose storage requires 4 Kbytes and whose evaluation requires 1000 modular word multiplications. After 100,000 visits a server should perform an interpolation of a polynomial of degree 100,000 which requires about 275 word multiplications per visit. The proof that the server generates can be verified by the audit authority by evaluating a polynomial of degree 1000.
If the scheme is implemented using 100 classes then it is possible to use a polynomial in which x is of degree 1000 and y is of degree 10 (or just a little more). The overhead of the client is negligible. The interpolation that the server performs requires about a single multiplications per visit.
Compare these figures to public key operations, for example when each
client performs an RSA signature with a 1024 bits modulus. This operation
requires about ![]() 32000
multiplications of 32 bit words and modular reductions modulo a 1024 bit
number.
32000
multiplications of 32 bit words and modular reductions modulo a 1024 bit
number.
The schemes that we describe only check whether a server had k visits, where k is a predefined parameter. A more fine grained measurement can be achieved by using a smaller value of k (e.g. k=1000). In this case the server is required to provide a different proof for every 1000 visits by presenting different values P(0,Hi) of the polynomial at different locations (Hi is a random challenge picked by the audit agency and the location (0,Hi) is used for proving the 1000 visits between visit 1000(i-1)+1 and visit 1000i). This variant requires the server to send to its clients the value Hi which is relevant at the time of their visits.
Secret sharing based schemes have the property that a server which received almost k visits cannot generate any partial proof and is in the same position as a server which received no visits. However, a server which received only k'<k visits, where k-k' is small, can ask the audit agency to send it k-k' shares. It can then recover the secret and prove k' visits.
An important data for advertisers is the rate with which the visitors to a site change (whether the site has loyal clients or whether most of the clients do not return). This measurement is also important against organized groups of clients which might offer their service as visitors-for-pay in order to increase the popularity count of sites. A site which bases its popularity on such visitors will not be able to show a nice turnover of clients.
Following is a coarse description of a system for checking client turnover. Suppose a server is proving k visits per day. Then the audit agency can use a one-way hash function h with a range of say 10k. The server is given a challenge t between 1 and 10k and is required to present, as soon as possible, a share of a client (from a later time period) which is mapped by h to t. If the clients of a server constantly change then this share is expected to be found after about 10 time periods. If the server has a low turnover than it would need considerably more time periods to present a suitable share.
We are currently implementing, with Reuben Sumner, a prototype of a Web site usage metering system.
The server-end of the system can be coded rather simply as a CGI script. There can be many approaches for implementing the client-end of the system:
After the client has sent the required metering information to the server it might try to approach different pages on the same site, or try to receive the same page at a later time during the same day. For these operations it might be required to send again the same metering data. A simple solution is to store the metering data in a cookie. The server will automatically receive the cookie, check its validity, and only if it is not updated would demand new information from the client (we assume, and it is easy to ensure this at the client side, that the client machine can verify that it is not being ``milked'' by the server for information which the server should not receive).
There are a few design problems which should be resolved at the implementation stage: (a) Should the user be required to actively acknowledge each transmission of metering data? (b) It should be ensured that servers cannot ``milk'' from clients metering data that they are not entitled to receive. (c) It should be ensured that a server cannot ask for metering data for a URL different than its own (this can be verified rather simply by receiving from the browser the URL that asked for the data).
Although we have not yet invested much effort in optimizing the code that performs the mathematical calculations, it is obvious that it has very good performance (much faster than public key cryptographic operations).
We have presented the notion of secure and efficient metering of the amount of service requested from servers by clients, and demonstrated its Web applications. Such metering schemes can be realized without substantial changes to the operation of clients and servers (though they do require a change in the clients software and a registration process) and to their communication patterns. This paper described a realization of a metering scheme, and we are currently working on implementing a prototype.
There are two main technical properties that can be improved in our construction. The scheme can be operated for only a limited (but large) number of time periods. It is interesting to design an efficient scheme (using only private key cryptographic operations) which can be used for an unlimited number of measurements. It is also preferable to design schemes which measure any granularity of visits, rather than measure a predefined quota of k visits.
A related and interesting problem is the problem of licensing: suppose that some software or content is bought by a client under a license which limits the maximum allowed usage (e.g. no more than two copies can be used concurrently). One could design a cryptographic scheme which enforces this policy.
 Moni Naor
obtained his B.A (Summa Cum Laude) from the Technion – Israel
Institute of Technology in 1985 and his PhD from University of California
at Berkeley in 1989, both in Computer Science. After spending 4 years
at the IBM Almaden Research Center he joined the department of Applied Math
and Computer Science of the Weizmann Institute of Science, Rehovot, Israel,
where he is currently an Associate Professor. His research interests
include Cryptography and Computer Security, Randomness in Computation and
Concrete Complexity. He is on the editorial board of the Journal of
Cryptology and Siam Journal on discrete Math and has recently served
on the program committees of Crypto'97, Computational Complexity'98 and
Financial Crypto'98.
His research was
supported by a grant from the Israel Science Foundation
administered by the Israeli Academy of Sciences.
Moni Naor
obtained his B.A (Summa Cum Laude) from the Technion – Israel
Institute of Technology in 1985 and his PhD from University of California
at Berkeley in 1989, both in Computer Science. After spending 4 years
at the IBM Almaden Research Center he joined the department of Applied Math
and Computer Science of the Weizmann Institute of Science, Rehovot, Israel,
where he is currently an Associate Professor. His research interests
include Cryptography and Computer Security, Randomness in Computation and
Concrete Complexity. He is on the editorial board of the Journal of
Cryptology and Siam Journal on discrete Math and has recently served
on the program committees of Crypto'97, Computational Complexity'98 and
Financial Crypto'98.
His research was
supported by a grant from the Israel Science Foundation
administered by the Israeli Academy of Sciences.
|
 Benny Pinkas
is a Computer Science doctoral student at the Department of
Applied Math and Computer Science of the Weizmann Institute of
Science, Rehovot,
Israel. He received his B.A. (Summa Cum Laude) and his
M.Sc., both in Computer Science, from the Technion – Israel
Institute of Technology, in 1988 and 1991, respectively. During 1991-1996
he served in the Israel Defense Forces, where he worked in computer
science and communications research and development. His main research
interests are Computer Security and Cryptography, and in particular communication
efficient security protocols. His research is supported by an Eshkol
Fellowship from the Israeli Ministry of Science.
Benny Pinkas
is a Computer Science doctoral student at the Department of
Applied Math and Computer Science of the Weizmann Institute of
Science, Rehovot,
Israel. He received his B.A. (Summa Cum Laude) and his
M.Sc., both in Computer Science, from the Technion – Israel
Institute of Technology, in 1988 and 1991, respectively. During 1991-1996
he served in the Israel Defense Forces, where he worked in computer
science and communications research and development. His main research
interests are Computer Security and Cryptography, and in particular communication
efficient security protocols. His research is supported by an Eshkol
Fellowship from the Israeli Ministry of Science.
|