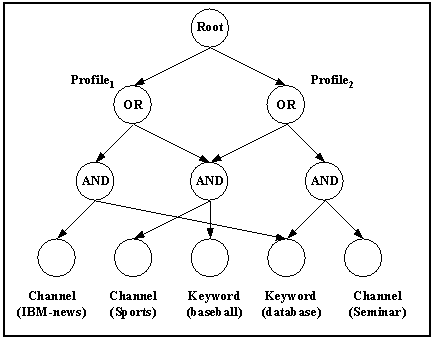
Fig. 1. Node sharing example.
Qi Lu,
Matthias Eichstaedt and
Daniel Ford
IBM Almaden Research Center,
650 Harry Road,
San Jose, CA 95120, U.S.A.
qilu@almaden.ibm.com,
eichstam@almaden.ibm.com and
daford@almaden.ibm.com
Webcasting, or Internet push, has attracted growing attention because of its potential for re-shaping the Internet. Pioneered by PointCast (1) and other ensuing products (2, 3), Webcasting systems automatically deliver information to the users based on user profiles, which record the Web channels subscribed by the users. Information frequently updated and of regular interest to the users becomes prime target for Webcasting delivery such as headline news and stock quotes. More and more digital content is being offered in Webcasting channels to Internet users or in corporate intranets for productivity enhancement.
One of the main problems in Webcasting today is the lack of sufficient support for personalization. As most Webcasting users can attest to, a subscribed channel often contains a significant amount of information irrelevant to their interest. For example, users cannot customize their subscription to only receive information about their favourite teams when subscribing to a sports channel. Moreover, the bandwidth wasted by delivering irrelevant content exacerbates the burden on network infrastructure, preventing widespread deployment. The solution is enabling users to filter subscribed channels according to their needs in their profile, and more importantly matching profiles against available content on the server side. Thus, only information pertaining to the user's personal interest needs to be displayed and delivered over the network, significantly enhancing usability while reducing network traffic.
As the foundation of content personalization, profile matching techniques [1, 2, 3] must be revisited to answer the challenges presented by Webcasting such as content diversity and large subscription volume. This paper presents a new solution that can efficiently match a variety of digital content against a large collection of user profiles in the context of Grand Central Station (GCS) [4, 5], a recent project at the IBM Almaden Research Center. We first provide an overview of GCS and its Webcasting mechanisms. We then describe detailed design and evaluation, and finally conclude with status and future work.
GCS combines both information discovery and Webcasting-based information dissemination into a single system. This section presents an architectural overview to provide a specific context for subsequent discussions of the GCS profile matching algorithms.
The GCS information discovery infrastructure inherits and extends the Harvest (4), [6] model of using distributed Gatherers/Collectors to systematically gather and summarize data. The GCS Gatherer can gather from most common sources such as HTTP, FTP, News, database, and CICS servers and summarize data in a variety of formats such as HTML, GIF, Power Point, PostScript, VRML, TAR, ZIP, JAR, Java Source, JavaBeans, and Java class files. Represented in the XML (5) format1, a GCS summary contains the metadata for each gathered item2 and its salient features that are useful for search purposes. This allows the users to search diverse information with uniform queries.
GCS broadens the scope of Webcasting by making data from anywhere in any format available as channel content. It also provides fine-grain personalization capabilities for the users to specify filters in any subscribed channel. The heart of GCS Webcasting is the profile engine, which maintains a large profile database and matches it against incoming data received from GCS Collectors. Data satisfying certain profiles will be automatically delivered to the corresponding users. Users interact with the GCS client to subscribe to Web channels, specify filters to personalize a subscribed channel, and display delivered information in various forms. The profile engine consults the channel database to automatically compile data into a hierarchy of channels. System administrators can define channels using the channel administration tool according to the specific needs from where the system is deployed. For example, the initial GCS deployment at Almaden offers a channel called AlmadenEvents containing meeting and seminar announcements. Individual users are allowed to define their own Web channels.
The foundation of GCS personalization is its profile language (GCSPL) used for specifying content filters and for defining channels. GCSPL is a Boolean structured language employing parameterized predicates as the tool for content selection. Its extensible structure is designed to accommodate the diversity of Webcasting content. If an image channel wishes to allow users to filter content based on image characteristics, we simply need to extend GCSPL with a set of image selection predicates. Table 1 explains the current GCSPL predicates designed after Rufus [7].
|
Predicate |
The predicate is True when applied to an item I iff: |
|
Keyword(x) |
I contains the word x. |
|
Adj(x,y) |
Words x and y are adjacent in I in the given order. |
|
Near(x,y) |
Words x and y are adjacent in I in any order. |
|
Channel(x) |
I satisfies the definition of channel x. |
|
MediaType(x) |
The media type of I is x. |
|
Time(x) |
I was last modified within x days. |
|
Source(x) |
The URL of I is x. |
Using GCSPL, a sample profile can be:
Channel(AlmadenEvents) AND Adj(database, technology) OR
Channel(Sports) AND Keyword(baseball)
And the definition of channel AlmadenEvents can be:
Source(nntp://news.almaden.ibm.com/ibm.csconf.talks) OR
Source(nntp://news.almaden.ibm.com/ibm.almaden.calendar)
Our first design objective is scalability. This is because Webcasting systems can typically expect tens of thousands, even up to millions, of subscribers as witnessed by PointCast. It is imperative that the profile engine gracefully scale up, absorbing new subscribers without severely degrading performance. The second is high performance because delay-sensitive information such as stock quotes must be matched and delivered in a timely manner. The third is adaptability because the profile matching mechanisms must dynamically adjust to evolutions in digital content and user profiles to sustain high scalability and performance.
The foundation of GCS profile matching algorithms is a compact data structure for representing a large collection of profiles called profile index (PI for brevity).
The design principle of PI is coalescing multiple appearances of any predicate P into a single representation. Its main benefit is that P will be evaluated only once when PI is matched against any incoming item. This is the key to achieving high scalability because users have shared interests. After reaching a certain scale, most common interests expressed in predicates such as Channel(Sports) and Keyword(baseball) will have ample representations in PI. This means that admitting new subscribers is unlikely to introduce new predicates into PI. Thus, the performance degradation incurred by adding subscribers will be limited because no new predicates need to be evaluated, allowing the system to scale up.
The data structure of PI is an AND/OR DAG, where each internal node is marked by a Boolean operator AND or OR. Note that we do not discuss the NOT operator here as it is easily handled by a special tag for reversing the truth value of a node. Each profile corresponds to a node and there is a special ROOT node serving as the parent of all the profile nodes. The graph structure parallels the logical structure of the profiles with each Boolean operator represented by an internal node while each predicate by a leaf node. PI may not be a tree because leaf nodes and even internal nodes can be shared by multiple profiles as shown in Fig. 1. Any predicate Channel(x)is dynamically substituted by a subtree representing the definition of x during profile matching.
The initial state of PI contains only the ROOT node. For the purpose of node sharing, we associate a ref_count to each node. A leaf node has a predicate attribute and an internal node has an operator attribute. In addition, a profile node has a profiles attribute which is a list containing the IDs of all the profiles that share the same Boolean expression. The algorithm for inserting a profile is described by the following pseudo-code. Routine Profile_Insertion calls an auxiliary routine Boolean_Expression_Insertion which inserts the subtree of a Boolean expression recursively while trying to share leaf and internal nodes.
|
void Profile_Insertion(Profile P) { E = the Boolean expression of P; N = Boolean_Expression_Insertion(E); add P to N.profiles; if (N is not a child of ROOT) { set N to be a child of ROOT; } } |
|
Node Boolean_Expression_Insertion(Boolean_Expression E) { if (E is a predicate) { if (E is already in PI represented by node N) { /* by hash table lookup */ increment N.ref_count; /* share leaf node */ } else { create a new leaf node N; N.ref_count = 1; N.predicate = E; } return N; } if (E is E1 op E2) { /* where op is a Boolean operator AND or OR */ N1 = Boolean_Expression_Insertion(E1); N2 = Boolean_Expression_Insertion(E2); if (there is already a node N where N.operator is op and has exactly the same two children N1 and N2) { /* by checking the intersection of N1 and N2�s parents */ increment N.ref_count; /* share internal node */ } else { create a new internal node N; N.operator = op; N.ref_count = 1; set N1 and N2 to be the children of N; } return N; } } |
The Profile_Deletion and its recursive auxiliary routine Remove_Node_Expression removes a profile from PI.
|
void Profile_Deletion(Profile P) { find profile node N for P; E = the Boolean expression of P; Remove_Node_Expression(N, E); remove P from N.profiles; if (N.profiles is empty) { remove node N from PI; } } |
|
void Remove_Node_Expression(Node N, Boolean_Expression E) { if (E is a predicate) { verify that N is a leaf node with E as its predicate; decrement N.ref_count; if (N.ref_count == 0) { remove N from PI; } return; } if (E is E1 op E2) { verify that N has children N1 and N2 corresponding to E1 and E2; Remove_Node_Expression(N1, E1); Remove_Node_Expression(N2, E2); decrement N.ref_count; if (N.ref_count == 0) { remove N from PI; } } } |
With the above two algorithms, replacing an old profile with a new one can be done by removing the old profile first and then inserting the new one.
The GCS profile engine matches incoming items against all the profiles in PI sequentially, one item at a time. We use the term profile evaluation or just evaluation to refer to the process of evaluating a particular item against PI to determine which user profiles are satisfied by the item. The basic evaluation process consists of two phases. The first phase is evaluating the truth value for all leaf nodes. Every predicate is associated a pre-defined procedure that can compute its truth value when applied to a given item. The second step is propagating the truth value from leaf nodes upwards following the Boolean operators of internal nodes until all the profile nodes receive their truth value.
Upward propagation plays a decisive role in evaluation performance because not all leaf nodes need to be evaluated. In fact, when a leaf node evaluates to a propagatable value (True when the parent is an OR node, False when the parent is an AND node), there is no need to evaluate its siblings. As soon as an internal node receives a propagated truth value, it triggers downward propagation, which traverses recursively downward through all the un-evaluated nodes and marks them as nodes that no longer need to be evaluated (see Fig. 2).
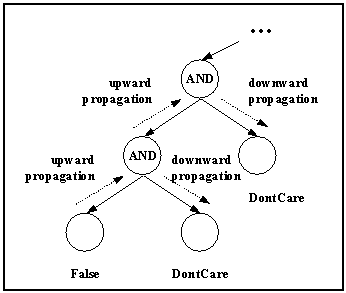
Fig. 2. Upward and downward propagation.
We attach three additional attributes to each node N for describing the evaluation algorithm. N.value stores the truth value of N; N.p_count represents the number of parents of N; N.pvk_count records the number of N�s parents whose truth value is known. The following pseudo-code describes the evaluation, upward and downward propagation processes. Routine Evaluation iterates through all the leaf nodes in a chosen order, evaluating a node�s truth value when necessary and invoking the Upward_Propagation routine afterwards, which recursively propagates the truth value upwards. The Downward_Propagation routine recursively traverses downwards and assigns the DontCare value to nodes whose parents all have known truth value.
|
void Evaluation(Item I, Profile_Index PI) { for (every node N) { N.value = UnKnown; /* initialization */ } put all leaf nodes into a list N1,N2,�,Nk; for (i = 1; i<=k; i++) { if (Ni.value != UnKnown) continue; Ni.value = evaluate Ni.predicate on I; Upward_Propagation(Ni); } } |
|
void Upward_Propagation(Node N) { for (each parent node P of N) { if (P.value != UnKnown) continue; /* skip P because its value is already known */ if (N.value is propagatable with respect to P) { P.value = N.value; Downward_Propagation(P); Upward_Propagation(P); /* recursively propagate upwards */ } } } |
|
void Downward_Propagation(Node N) { if (N is a leaf node) return; for (each child C of N) { increment C.pvk_count; if (C.value != UnKnown) continue; /* skip C because its value is already known */ if (C.pvk_count == C.p_count) { /* all the parents of C have known values so we can assign DontCare to C */ C.value = DontCare; Downward_Propagation(C); /* recursively propagating downwards */ } } } |
Note that the propagation algorithms are linear because each node can be propagated at most once. Due to the structural characteristics of PI, the truth value of all the profile nodes is guaranteed to be known when the Evaluation routine completes.
The performance of profile evaluation is largely dependent upon the order of leaf nodes, which is unchanged during the evaluation. This is because following a different order will cause a different set of leaf nodes to skip over evaluation via propagation. In fact, for any given item, there exists an optimal order such that the least amount of computation is needed for the evaluation. We employ a cost/credit-based leaf node ranking algorithm that is capable of achieving strong performance over time.
The design rationale of the ranking algorithm can best be explained by regarding the evaluation process as assigning True, False, or DontCare to all the leaf nodes. The cost of assigning a value to a node N is the elapsed time of computing N�s predicate applied to the current item. As a result of propagation, a set of other un-assigned nodes {N1, N2, .., Nk} will be assigned the DontCare value. We will attribute the total cost of {N1, N2, ..., Nk} as a credit to N, representing N�s contribution towards the goal of assigning values to all leaf nodes. To minimize the overall cost of evaluation, we must favour nodes with high credit and low cost. Thus, our ranking function is simply credit/cost.
We rank leaf nodes based on their past performance by recording an evaluation history. Every time a node N is evaluated, we dynamically compute its cost and credit and average them over time. To describe the ranking algorithm, three additional attributes are needed. N.eval_count records the number of times N is evaluated; N.cost is the average cost of N; N.credit is the average credit of N. The cost is obtained by measuring the runtime cost and adjusting for average. The computation of credit is more complicated and requires a credit attribution process during truth value propagation. Its first phase is computing the total cost of all the leaf nodes that are assigned DontCare due to downward propagation from an internal node, which can be integrated in the following updated Downward_Propagation routine, where the changes are highlighted.
|
int Downward_Propagation(Node N) { if (N is a leaf node) return 0; int total_credit = 0; for (each child C of N) { increment C.pvk_count; if (C.value != UnKnown) continue; if (C.pvk_count == C.p_count) { C.value = DontCare; if (C is a leaf node) total_credit = C.cost + total_credit; else total_credit = Downward_Propagation(C)+ total_credit; } } return total_credit; } |
Once the total amount of credit is computed by downward propagation, we invoke the Attribute_Credit routine to attribute credit to the deserving leaf nodes. Note that siblings may need to share credit as shown by Fig. 3, where the two leaf nodes equally share the credit because the propagation leading to the credit is resulted from both being evaluated to True.
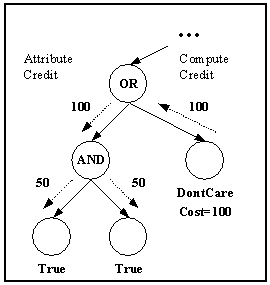
Fig. 3. Credit attribution example.
|
void Attribute_Credit(Node N, int credit) { if (N is a leaf node) { N.credit = (N.credit * N.eval_count + credit) / (N.eval_count + 1); /* assign updated average credit for N */ } else { /* compute the number of children that deserve credit */ int deserving_children_count = 0; for (each child C of N) { if (C.value == N.value) increment deserving_children_count; /* C has the same value as N so */ /* it contributed to the credit */ } int shared_credit = credit / deserving_children_count; /* recursively attribute credit downwards */ for (each child C of N) { if (C.value == N.value) Attribute_Credit(C, shared_credit); } } } |
With the above extensions for credit computation and attribution, the previous upward propagation and evaluation algorithms need to be adjusted accordingly with changes highlighted in the following updated routines:
|
void Upward_Propagation(Node N) { for (each parent node P of N) { if (P.value != UnKnown) continue; if (N.value is propagatable with respect to P) { P.value = N.value; int credit = Downward_Propagation(P); Attribute_Credit(P, credit); Upward_Propagation(P); } } } |
|
void Evaluation(Item I, Profile_Index PI) { for (every node N) { N.value = UnKnown; } order leaf nodes into N1,N2,�,Nk based on credit/cost ranking; for (i = 1; i<=k; i++) { if (Ni.value != UnKnown) continue; Ni.value = evaluate Ni.predicate on I; int cost = the runtime cost of evaluating Ni; Ni.cost = (Ni.cost * Ni.eval_count + cost) / (Ni.eval_count + 1); increment Ni.eval_count; Upward_Propagation(Ni); } } |
Assigning the initial cost to leaf nodes is relatively simple. For every predicate in PI, we evaluate it against sample items and use the average runtime cost. Assigning initial credit is more difficult without any history. A simple approach is using the total cost of a node�s siblings. Fortunately, the ranking algorithm adjusts itself as the evaluation history progresses. Therefore, any reasonable initial credit will suffice for the long haul.
One of the drawbacks of ranking leaf nodes relying on history information is the possibility of sustaining a sub-optimal order against a pathological sequence of incoming items which will assign a fixed pattern of truth values to a group of leaf nodes. Consider the example in Fig. 4 where past performance favours N1 over N2.
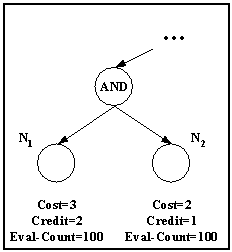
Fig. 4. Sub-optimal ranking example.
Suppose that the next incoming items will all assign False to both N1 and N2 while keeping cost the same with no credit to N1 and N2. Despite the fact that N2 is cheaper than N1, it will not get a chance ahead of N1 because its past performance. This stranglehold can possibly leave out the more deserving N2 indefinitely. Another sustainable sub-optimal order can occur if all the incoming items will assign True to N1 and False to N2, with the same costs and no credit for N2. Both N1 and N2's average credit will decline, but at the same rate. This may keep N1 ahead of N2 for long even though N1's evaluation is wasted.
To break up these kinds of strangleholds, we must inject factors beyond history into the ranking function. A simple mechanism is giving higher priority to nodes that have not been evaluated for the last K consecutive items, where K can be configured for a desired history sensitivity. In addition, we can assign more weight to credit that is attributed recently or in particular situations, making it easier for the leaf node ranking to forget history.
So far, our algorithms regard items as independent of each other, meaning that the evaluation of one item has no effect on another. In fact, it is often possible to take advantage of one item's evaluation to reduce the cost of another. As shown by previous research [8], checking for multiple keywords can be done much faster than checking for one keyword at a time. We are currently working on mechanisms for seamlessly incorporating group evaluation for keyword predicates.
GCS profile matching is designed to handle diverse data even including a catalogue, a collection of indexed items. By representing evaluation results as bit-vector and treating the AND and OR operator as bit-wise AND and bit-wise OR respectively, propagation can be conducted in the same fashion as shown in Fig. 5. Credit attribution can also be extended accordingly to work with catalogues.
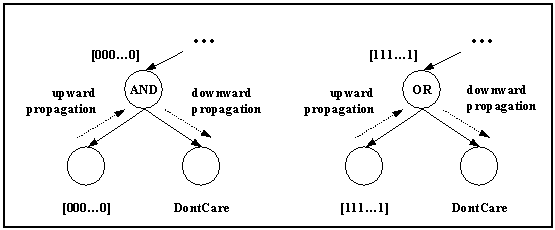
Fig. 5. Propagation for catalogue.
The GCS profile matching algorithms, along with the rest of the GCS system, have been implemented using the Java programming language (7) and operational since summer 1997. This section presents an initial performance evaluation based on the current implementation. More detailed results from our experiments will be available in a separate IBM Research Technical Report.
The performance evaluation focuses on verifying whether the main design objectives of GCS profile matching algorithms have been achieved. Specifically, we would like to answer the following two questions: Can the GCS profile matching algorithms dynamically adapt to incoming items to achieve good performance over time? How much performance degradation is incurred by admitting new subscribers after reaching a certain scale?
To answer the question on performance and adaptability, we first measure the actual performance by recording the elapsed time of evaluating a sequence of items against a specific PI. Recall that the key to achieving good performance is through dynamic adaptation based on the cost/credit history. To quantify its effect, we measure the performance of matching the same items against the same PI without adaptation by randomly ordering the leaf nodes before evaluating each incoming item. We then characterize the performance and adaptability of GCS profile matching algorithms by comparing the actual performance against the no-adaptation performance.
To answer the question on scalability, we first measure the performance of evaluating a sequence of items against a large-sized PI. We then conduct the same measurement by successively adding a fixed number of profiles to the PI, and assess the scalability based on the relative distance among the measured performances.
The experiments run the current GCS profile engine on the following platform: 200MHz Pentium-Pro CPU, 64 MB RAM, 2GB disk, and NT 4.0. The runtime uses Sun�s JDK 1.1.4 (8, 9) with maximum heap size of 50MB, and the Java Performance Runtime for Windows (10). For accuracy, the machine was disconnected from the network during the experiments and only a minimum set of necessary NT services were running in the background. Furthermore, asynchronous Java garbage collection and class garbage collection were disabled with the -noasyncgc and -noclassgc switches.
To yield realistic results, data items used in the experiments come from channel content offered in the initial GCS deployment. They are collected between November 3rd and November 15th, 1997 from the following six newsgroups: comp.lang.java.programmer, misc.entrepreneurs, misc.consumers, bionet.molbio.methds-reagnts, ibm.csconf.talks, and ibm.csconf.k5x. Each group carries between 22 and 4507 articles during the period and the average article size ranges from 1.5 to 2.6 KB.
Due to the lack of deployment size, we use randomly generated profiles to populate a large PI. We developed a tool to generate random profiles that are a conjunction of the following predicates or expressions:
Words used in the text predicates are randomly selected from a dictionary containing words collected from articles in the newsgroups mentioned above. The random selection is weighted with word occurrence frequency, and guarantees that there are no duplicates in any generated profile. The following is a sample random profile.
|
Channel(Calendar) AND Time(5) AND (NOT MediaType(application/pdf)) AND (NOT Source(news://news.almaden.ibm.com/ibm.almaden.calendar)) AND (Near(virginbrazil,eagantech) OR Keyword(adrian)) |
Figure 6 shows the no-adaptation performance and the actual performance of matching 250 items from newsgroup comp.lang.java.programmer against a PI with 500 randomly generated profiles. The X-axis represents the sequence number of items evaluated in that order while the Y-axis represents the elapsed time measured in seconds. Comparing the two performance curves, the effect and advantage of dynamic adaptation is very clear because the actual performance is able to significantly improve itself over time while the no-adaptation performance stays relatively flat and 3 to 5 times more costly. The initial decline in the no-adaptation performance can be explained by corrections to the inaccuracy in initially assigned predicate costs. Recall that the accuracy of predicate cost is improved by averaging over the actual runtime cost. This means that the initial sharp decline in the actual performance is accounted for by two factors, dynamic adaptation and cost correction. Figure 7 shows the same measurements except that the items come from all six newsgroups mixed in random order. In this case the performance is slightly worse but the effect of adaptation remains the same.
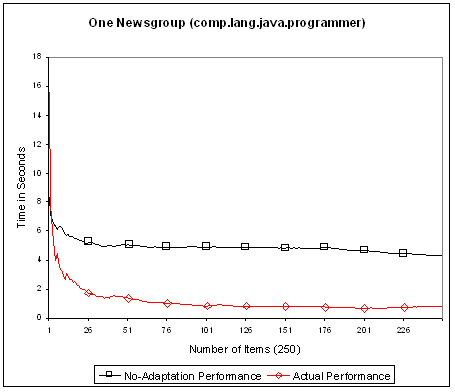
Fig. 6. Performance measurement.
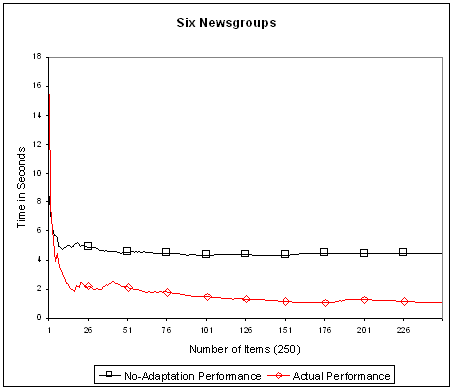
Fig. 7. Performance measurement (cont.).
The lower curve in Fig. 8 shows the actual performance of matching 250 items from comp.lang.java.programmer against a PI with 2500 random profiles. The upper curve shows the actual performance of matching the same items against the same PI while adding 500 new profiles at the 50th, 100th, 150th, and 200th item. Note that there are 500 predicates used in the initial PI with no new predicates introduced by the additional profiles. The narrow distance between the two curves clearly indicates the small impact of admitting new profiles, which is the key to good scalability.
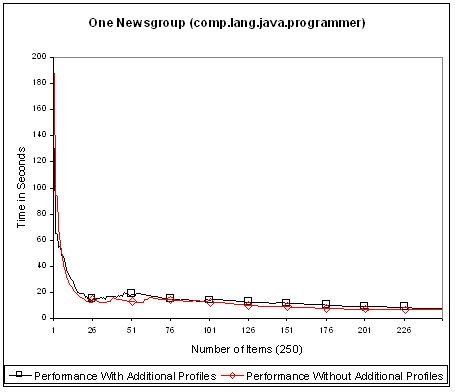
Fig. 8. Scalability measurement.
This paper has presented a new technology for efficiently matching diverse digital content against user profiles in large-scale Webcasting systems. The implementation in GCS and initial performance evaluation has demonstrated its ability to scale up and achieve strong performance via dynamic adaptation. It is widely applicable in any Webcasting system as long as a Boolean structured profile language is employed.
The authors wish to thank Joe Gebis, Toby Lehman, Udi Manber, Ron Pinter, Gunter Schlageter, Neel Sundaresan, ShangHua Teng, and John Thomas for their contributions to the GCS project development and for their helpful discussions and comments.
[1] T.W. Yan and H. Garcia-Molina, SIFT – a tool for wide-area information
dissemination, in: Proceedings of the 1995 USENIX Technical
Conference, pp. 177–186, 1995.
[2] T.W. Yan and H. Garcia-Molina, Index structures for selective dissemination
of information under the Boolean model, ACM Transactions on Database
Systems,
19(2): 332–364, 1994.
[3] J.M. Hellerstein, Practical predicate placement,
in: Proceedings of
1994 ACM SIGMOD, pp. 325–335, 1995.
[4] Information on
the fast track, IBM Research Magazine, 35(3): 18–21,
1997.
[5] IBM: all searches start at
Grand Central, Network World, November 11, 1997, front page.
[6] C.M. Bowman, P.B. Danzig, D.R. Hardy, U. Manber and M.F.
Schwartz,
The Harvest information discovery and access system, Computer Networks
and ISDN Systems, 28: 119–125, 1995.
[7] K. Shoens, A. Luniewski, P. Schwarz, J.
Stamos and J. Thomas, The Rufus
system: information organization for semi-structured data, in: Proceedings of
19th International Conference on Very Large Data Bases, Dublin,
Ireland, Aug. 1993.
[8] S. Wu and U. Manber, A fast algorithm for multi-pattern
searching,
Technical Report TR94-17, Department of Computer Science, University of Arizona,
Tucson, May 1994.
(1) http://www.pointcast.com/
(2) http://www.backweb.com/
(3) http://www.datachannel.com/
(4) http://harvest.transarc.com/
(5) http://www.w3.org/XML/
(6)
http://harvest.transarc.com/Harvest/brokers/soifhelp.html
(7) http://java.sun.com/
(8)
http://java.sun.com/products/jdk/1.1/
(9)
http://java.sun.com/beans/index.html
(10)
http://java.sun.com/products/jdk/1.1/jre/index.html


