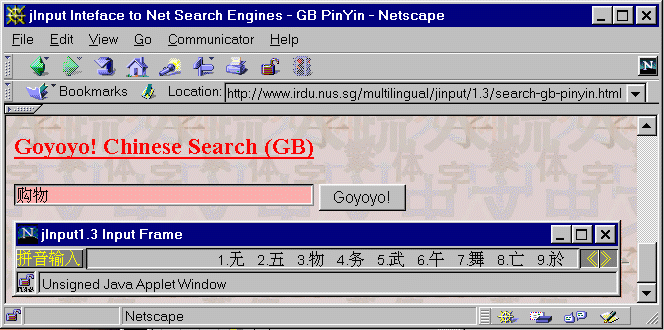
Fig. 1. Screen shot of jInput applet.
aInternet R&D; Unit, National University of Singapore
kokyong@irdu.nus.edu.sg and
liuhai@irdu.nus.edu.sg
bBioInformatics Centre, National University of Singapore
owu@bic.nus.edu.sg
Although the majority of Web used to be dominated by English HTML
documents using the ISO-8859-1 character set, HTML documents are
increasingly written in many other native languages and encoding as well.
Riding on this trend, major browsers like Netscape Navigator and
Microsoft Internet Explorer have included support for viewing I18N HTML
documents given that the appropriate fonts are installed. The creation of
such documents is also possible, although not without some level of
difficulty as we will explain later.
Prior to HTML 4.0, internationalization features are evidently missing from HTML 2.0 and HTML 3.2 [1]. There are no tags to specify character set of the document (the default charset is ISO8859-1). Neither are there tags to indicate the text direction which is especially important for right-to-left writings like Arabic and Hebrew.
In the days of HTML 2.0 and 3.2, users encountering multilingual HTML documents while browsing the Web may be subjected to do some guessing to determine the character set the HTML document is based on. The most intuitive guess would most probably be based on the top-level domain of the Website. For example, if the domain is .jp, the HTML documents would most likely be in one of the Japanese encoding — EUC-JP, SJIS or JIS. However, it is also possible that the HTML document could be in one of those double-byte encoding like Chinese GB or Korean KSC or maybe even another character set. Another approach is the HTML document contains a English statement informing the user what character set is used. The user will upon reading it, switch the browser to the appropriate character set viewing mode.
Along the way, some browsers like Netscape Navigator and Microsoft Internet Explorer begins to support the use of a FACE attribute to the FONT tag. With this, HTML authors can specify a particular font to use to view certain part of the text within a HTML document. This proves especially useful to 8-bit character set. However, the use of the FONT FACE [4] is considered harmful in many instances since we should not indicate which font set to use to display a document. Instead, we should specify the character set a particular HTML document is based on.
With HTML 4.0 public draft, W3C introduced international capability
into the Web. Browsers, including Netscape Navigator and Internet Explorer, can recognize
the character set specified in the HTML document header. If the user has
provided the appropriate font settings for each language encoding
supported, the browser will be able to automatically display the HTML
document in the specified language encoding.
The subsequent release — version 1.1 [5] — added more support to allow for the development of localizable applets and applications using Java. Enhancements include the display of Unicode characters, a locale mechanism, localized message support, locale-sensitive date and time, time zone and number handling, collation services, character set converters, parameter formatting, and support for finding character/word/sentence boundaries. This is a large step towards I18N in Java. The ability to add fonts to the Java runtime environment make it possible to display Unicode characters. Locales and related services also make it possible to write your application once and port them later to other language context through the use of resource bundles. The character set conversion (to and from Unicode) utilities made interchange between current widely used encoding and Unicode quite effortless.
However, one very important missing feature is the provision for
native keyboard input methods in Java version 1.1.
Languages that do not use the Roman alphabet require special keyboard mapping to achieve character input. If you are familiar with Chinese, Japanese or Korean (abbreviated as CJK), you'll understand that inputting these characters are not trivial using an English keyboard layout. You need a keyboard manager to trap your keystrokes sequence before transforming them into a valid character; some method requires the user to choose from a list of choices. This applies similarly for other languages as well. For example, some Indian languages have phonetic keyboard layout which are much more complex than direct keyboard mapping. Thai is another instance that needs a keyboard remap to type.
In many instances, a complete GUI applications written in Java will need to accept character input from the user through widgets like text field. Currently, such text entry mechanism is largely based on Roman characters (English keyboards) only. The initial core Java APIs framework did not support keyboard input methods for other languages and writing. Without input methods support in Java, applications cannot accept non-Roman keyboard input from users.
Because all AWT widgets are peer components, they rely on the host
platform widget's functionality. As such, if the Java application runs on
Japanese Windows95, there will be Japanese input methods but not Chinese
or Korean input methods and vice versa. A Java application running on
English platform will not enjoy any other input methods support except the
US-English keyboard. In short, Java applications will receive partial
input method support from the host platform in JDK 1.2. Perhaps, JFC may
overcome this restriction but most probably only in the next Java release.
JIME is being developed on many different fronts. When we started our implementation, due to limited support by browsers for JDK 1.1, we started with "Input", a Java applet using JDK 1.0. To extend its usefulness, we ported it to a Java plugin for Netscape Composer. Both applet and plugin supports various input methods for Chinese, Japanese and Korean.
Along the way, Netscape announced the finalization of JDK 1.1 support for Netscape 4.0 with a patch. As JDK 1.1 support improves, we are re-focusing our development effort toward JDK 1.1 and re-deploying our framework to make use of better I18N support from JDK 1.1. Support for more languages like Thai, French and German are added.
In the sections that follow, we start with introducing our design and
implementation of the JDK 1.0 model of our development before we move on
to describe the subsequent JDK 1.1 model design issues and implementation
we adopted.
Example 1: Extract of source for Pinyin method in GB encoding
static private String[] keys =
{
"a",
"ai",
"an",
"ang",
"ao",
........
};
static private String[] mappings =
{
"\ub0a2\ub0a1\ubac7\uebe7\ue0c4\uefb9\udfb9",
"\ub0ae\ub4f4\ub0a7\ub0a4\ub0ad\ub0a3\ub0a9\ub0ac\ub0a6\ub0ab\ub0a5\ub0a8\ub0aa\ub0af\uead3\uf6b0\udedf\ue0c8\ue8a8\ue6c8\uefcd\ue0c9\uedc1",
"\ub0b2\ub0b8\ub0b4\ub0b5\ub0b6\ub0b3\udacf\uf7f6\ub0b0\ub0b1\ue2d6\ue8f1\uf0c6\ub0b7\uefa7\udeee\ue1ed\udbfb\ub9e3\ub3a7",
"\ub0ba\ub0b9\ub0bb",
"\ub0c2\ub0c4\ub0c1\ub0be\ub0bd\ucff9\ub0bc\ub0c0\ub0c3\udbea\ue0bb\uded6\uf7e9\ue6f1\uf7a1\ub0bf\ue1ae\ue2da\ue5db\ue9e1\uf1fa\ue6c1\uf2fc\uf6cb",
........
};
For example, when the user keys in the character "a", the corresponding to display for the user to select are 0xb0a2, 0xb0a1, 0xbac7, .... etc. If the subsequent key pressed is "n", then the characters selection range will become another set — 0xb0b2, 0xb0b8, 0xb0b4, 0xb0b5, 0xb0b6, .... etc.
Example 2: Extract of source for Java bitmap font for Simplified
Chinese in GB encoding
static private final String[] bitmap = {
"\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000
\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u6000\u3000\u1000\u0000\u0000
\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u2000\u5000\u2000\u0000\u0000
\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0300\u0300\u0000\u0000\u0000\u0000\u0000\u0000\u0000
\u0000\u0000\u0000\u07c0\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000
....
};
We use a 16-by-16 bitmap for each CJK character. So the first 16
characters in the String above is the hex bitmap for the first
character 0xA1A1 in GB charset. The subsequent 16 characters is for 0xA1A2
and so on.
Usually, the users are expected to find their own ways to enter CJK characters into the text field in the HTML form to search for keywords. This does not pose a problem to those users on a native platform, but users on English platforms or other locale platforms will need to install their own third-party applications to input CJK text. Many third-party applications for Windows are available, usually running as a keyboard manager. But Macintosh has limited such applications. Moreover, such third party applications for Windows and Macintosh are usually either commercial ware or are available on a trial basis with expiry. There are various developments of IME servers for UNIX systems but these are not easy to set up for novice users. Users thus experience much inconvenience just to input a few characters for searching.
To assist those users on non-CJK locale platform, we developed a Java applet — jInput — allowing the user to input CJK text without having to install any third-party applications. Websites adopting this applet do not need elaborate instructions to user on installing third-party applications in order to input CJK text.
The advantage of this approach is the user is not expected to install any keyboard manager on their system. The user simply waits for the applet to be downloaded and enters the text into the Java applet. Before submitting the form, JavaScript will call a public method in the Java applet to retrieve the text content from the applet. Netscape LiveConnect [6] technology allows JavaScript to call methods in Java classes. In this way, the applet works seamlessly with the HTML form as if it is a plain text field. Both Netscape 3.0/4.0 and Internet Explorer 4.0 currently allow such JavaScript-to-Java communication.
The applet currently supports the following language encoding and input methods.
For a demo of the jInput applet, see http://www.irdu.nus.sg/multilingual/jinput/. See below for a screen shot of the applet.
The above-mentioned applet is ported to run as a Netscape Composer plug-in — named "JIMEPlug". This is especially useful for users on English or other non-CJK locale platform who wish to have the I18N capability. A user who sets up their Netscape Messenger to send HTML email message can even type an email message in CJK with the help of the plugin.
As with any plug-in, installing the plug-in involves just simply downloading a ZIP file to the plug-ins directory of where the Communicator application is installed. The plug-in is a self-contained unit with its own fonts and keyboard input methods supporting various Chinese, Japanese and Korean input methods and encoding. Because Netscape Composer uses Unicode for its internal representation of characters within an HTML document, authoring of CJK documents in Unicode is also possible.
A beta prototype of the plug-in is available at
http://www.irdu.nus.edu.sg/jime/jimeplug/.
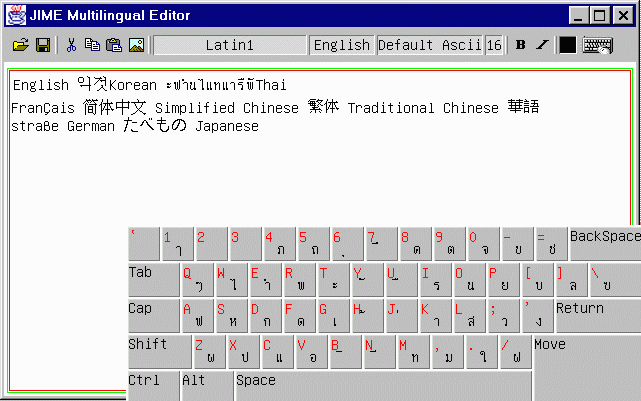
JIME consists of five packages.
Because of the complex nature of internationalization, it is not easy to get a perfect design. JIME is a good try because it does strive to meet its objective, and has an extensible structure. However, there will definitely be some limitations along the way. Currently, JIME API does provide extensible space for bi-directional horizontal text layout and edition, because they are all left to individual StringView to handle. No major changes are required other than just implementing another bidi-StringView type into the BlockView.
The classes in jime.widget package do not aim to rival Java2D API and JDK 1.2 advanced text layout features [9]. JIME framework design is focused on providing full input methods support to JDK 1.0 and JDK 1.1 applications given the unique feature of jime.imelib and jime.fontlib package.
We plan to make a JDK 1.0 applet which runs on all Java-enabled browsers (whether it contains a 1.0 or 1.1 Java VM). Assuming the host system has the appropriate native fonts installed and Netscape is configured to make use of them, the applet will try to use these fonts if the browser is JDK 1.1 enabled. If either native fonts are missing or a JDK 1.1 VM is not present, the applet will fall back to use our jime.fontlib packages' bitmap font classes. The wrapper applet should be able to dynamically load the correct Java codebase based on the situation described above.
To make the JIME code-base and framework reusable, we are in the process of porting it into JavaBeans. With JavaBeans, software developers can easily reuse JIME components and build native keyboard input methods into their Java 1.0/1.1 applications regardless of the locale of the host platform it will be running on.
To increase JIME support base, its extensibility has to be further enhanced through adding support for more languages to its portfolio. We are extending the framework to include more European languages, Indian languages (like Hindi and Tamil) and maybe even bi-directional writings like Arabic and Hebrew.
Java 1.2 input method framework is a step in the right direction. Unfortunately, only input methods supported by the host platform's native input method managers are available to Java applications. However, with Java 1.2 support of Java Foundation Classes (JFC), AWT peering widgets are being complemented by JFC peerless components. Because JFC widgets are lightweight standalone components, they do not rely on the host platform widgets' functionality. As such, it is expected (according to the Java 1.2 input method framework documentation) that future releases of Java and JFC may provide full input method support regardless of the host platform the Java application is running on.
In the meantime, JIME serves as a good transitional component for JDK 1.0 and 1.1 (or even 1.2) developers who need the native input methods support for their Java applications, especially since Web browser support for the latest Java VM do not catch up as fast as Javasoft's JDK releases.
In conclusion, the Web is moving towards a more "World Wide" reach and so is Java. With Java, we are close to realizing true internationalization of cross-platform applications. Java Input Methods will make your localized applications more complete.
Oliver P. Wu
was formerly attached to IRDU as a student researcher, working
on the very early design and implementation phase of JIME. He has since
joined the BioKleisli research group of the BioInformatics Centre (BIC) of
the National University of Singapore. He is currently a senior software
engineer at the Kent Ridge Digital Laboratories.
owu@bic.nus.edus.sg
[http://adenine.krdl.org.sg:8080/~owu/]
Research Unit, BioInformatics Centre, Institute of Systems Science /
Kent Ridge Digital Laboratories, 21, Heng Mui Keng Terrace, Singapore
119613
Liu Hai
is a student researcher working with IRDU I18N group. He is
completing his undergraduate degree course on Information Systems and
Computer Science in the National University of Singapore. After working on
JIME, he subsequently got an opportunity to be attached to Netscape
Communications Corp for a summer internship program for 3 months in May
1997.
liuhai@irdu.nus.edu.sg
[http://www.irdu.nus.edu.sg/~liuhai/]
Internet R&D; Unit, National University of Singapore, 10 Kent Ridge
Crescent, Singapore 119260