HP Labs (Bristol),
Filton Road, Bristol BS12 6QZ, U.K.
cal@hplb.hpl.hp.com and
lbt@hplb.hpl.hp.com
Telephony and teleconferencing create an illusion of proximity. In current implementations there is no environment (other than the imagination) in which users can be said to be "proximate". In a typical teleconference all participants share the same null space somewhere inside a telephone ear piece.
One of the most exciting developments in the Internet and the WWW is the perception of the network as a place. This approach has been described as "social virtual reality" [Curt94] [Wat96] and "social computing" [Rock97]. The combination of computing and networking provides the means to create rich synthetic environments where people can meet, communicate and socialise. Early examples such as Internet Relay Chat concentrated on text, but more recent applications such as Sony's Community Place and Online! Traveller integrate synthetic visual environments based on VRML [VRML97] with audio conferencing.
A great deal of research in the Internet community has concentrated on the mechanics of transmitting digitised and compressed audio across an IP Wide Area Network (WAN). Voice over IP (VoIP) applications in general adopt the user interface assumptions of traditional telephony — that is, the network is a technology for delivering a monaural stream of audio into an ear piece (but see [Hard96]) .
In this paper we intend to show how something richer than traditional telephony can be provided to a collection of communicating individuals without impacting the delivery of audio — that is, we are concerned with the presentation of audio to the user. Distributed audio rendering is the presentation of sound to a collection of users in a way that creates the collective illusion that they occupy a shared physical space. It combines ambient sound, incidental ("Foley") sounds, and real-time voice communication, and uses sound spatialisation algorithms and environmental acoustic effects (such as reverberation) to provide a convincing sense of a place that is shared by users who may be half the world apart.
The work presented in this paper straddles the divide between audio conference sessions based on multimedia session protocols developed by the Internet multimedia community, and distributed virtual environments. We wanted to create distributed 3D audio rendering abstractions that could be used in conjunction with a number of distributed virtual environment technologies, but were consistent with existing multimedia protocols. Although we have multi-user VRML developments in mind (such as Living Worlds [Liv97]), there is no strong bias towards 3D visual environments.
In Section 2 we discuss the technology behind sound spatialisation. In Section 3 we go on to review the use of audio in social virtual reality/distributed virtual environments, and identify how communication sessions are established. In Section 4 we discuss the concept of the multimedia conference session. In Section 6 we go on to show how the familiar idea of a conference or session can be employed in the context of distributed audio rendering, and in Section 7 we discuss what kind of audio rendering information needs to be communicated between session participants. Lastly, we outline the implementation of these ideas, and present our conclusions.
Synthetic sound spatialisation is the processing of monaural sound in such a way that when it impinges on our ears, it reproduces the characteristics of a sound located in a 3D space external to the listener. A detailed explanation of the psychoacoustics of spatial hearing can be found in [Beg94]. Briefly, sound travelling to our ears will usually arrive at one ear sooner than the other. Sound is also diffracted by the head and shoulders so that there are frequency-dependent intensity differences at the two ears. Some sound is reflected by the structure of the ears, and this introduces spatially-dependent notches in the sound frequency spectrum. These timing, intensity and spectral effects are transformed by the brain into a perception of sound in space.
These effects are modelled by a Head-Related Transform Function (HRTF). A digitised monaural audio stream can be convolved with an artificial HRTF to create a binaural audio stream that reproduces the timing, frequency and spectral effects of a genuine spatial sound source. Environmental acoustic effects such as reverberation can also be added. For ideal results an HRTF needs to be tailored to the physical characteristics of person, but dummy-head HRTFs can still produce highly pleasing results.
Low cost consumer hardware that can carry out a spatialised mix of several concurrent streaming and static sound sources (for example, boards based on the A3D chip set from Aureal) has become available for the Wintel platform. Microsoft has defined the device-independent DirectSound interface for spatial sound as part of DirectX [DirX], and although this interface is Wintel specific, the PC games market alone will ensure the widespread acceptance and use of low-cost spatial sound hardware.
A spatial mix of several sources of sound is hardware intensive, and must be recomputed relative to each audio observer. This has important implications for a distributed audio rendering architecture which will be discussed later.
Much of the agenda for social virtual reality has been spelled out as part of the Jupiter [Curt95] project. Jupiter is an extension of the MUD concept [Curt94], which in its original form consisted of a multi-user environment in which text was used both for the description of places and objects, and also as a means of communication between participants. Behaviours can be added to objects and places using a built-in programming language, and multi-user aspects such as ownership, modifiability, extensibility, and concurrency are handled with a relatively high level of sophistication.
Jupiter has a highly developed model for audio and video conferencing. Microphones and cameras are modelled as sources, and video and speaker panes as sinks. Sources and sinks communicate through a channel, which corresponds to a multicast address. The membership of a communication session is modelled through the dual abstractions of a channel manager and a key manager. The latter manages encryption key notifications to ensure that sessions are private. Although any object may own a channel, the normal convention is for a channel to be owned by a room or place so that all the people in the room can communicate. Jupiter is based on dumb client software; the object model shared by the users of the environment resides in a single server.
Open Community [Wat97][Yer97] is a distributed virtual environment (DVE) infrastructure based on SPLINE [Wat96]. SPLINE provides a distributed shared object model, and is optimised to reduced the overhead and latency associated with achieving a consistent view across multiple clients. As DVEs are communication intensive, the unit of scaling in SPLINE is the locale. Each locale corresponds to an IP multicast group, and an observer in one locale need not observe the communication traffic corresponding to another locale. Audio classes such as sources and observers are derived from the top-level class in the object architecture, and so are subsumed within the overall architecture. Audio can consist of ambient, Foley and real-time sources, and sounds are rendered within the spatial context of the enclosing locale, using a multicast group for the real-time audio streams, which are mixed and rendered with other sounds at the client. Open Community provides a very complete solution, with the disadvantage (if it can be called that) that the distributed audio rendering is embedded within the whole, and although the internal protocols have recently been published [Wat97a], the architecture is relatively monolithic.
Other research DVEs we have studied which incorporate audio communication are MASSIVE and DIVE. MASSIVE [Green95] makes extensive use of a spatial extent called an aura to manage communication through multicast groups. DIVE [Hag96] assigns a multicast address to a spatial extent called a world, and resembles Open Community in this respect.
An example of a commercial solution incorporating audio conferencing within a DVE is the Online! 3D Community Server and Online! Traveller. From the information available it appears that multiple VoI audio streams are mixed using a central mixing server, an approach which is practical for monaural sound, but less practical for a spatial mix, where each client needs a computationally intensive individual mix. Sony's Community Place VRML browser and accompanying Community Place Bureau server permit monaural audio chat within a VRML context.
In each of these architectures similar questions and themes emerge:
Similar concerns can be found in discussions of conferencing or multimedia sessions. This is not surprising, as a multimedia session can be viewed as a form of distributed virtual environment (or vice-versa). We now go on to discuss this area.
The distinction between a conference and a multimedia session verges on the theological, and in what follows we use the following definition [Hand97a]: a multimedia session is a set of multimedia senders and receivers and the data streams flowing from senders to receivers. A review of Internet standardisation activities in this area can be found in [Hand97].
The set of issues dealt with by multimedia session/conference control can be decomposed as follows [Jacob93]:
There is a wide divergence in the solutions proposed and adopted. Two representative extremes are T.124 [T.124], the ITU-T's recommendation on generic conference control, and tools such as vat in daily use on the MBONE [Mac94]. T.124 has a specified solution to each of the issues above, but it sacrifices scalability. MBONE tools are known to scale to several hundred participants, but pay the price of a relaxed view of who is participating. On the MBONE it is possible to participate in a conference simply by knowing the multicast addresses used for its transmissions. Attendance information is propagated lazily via multicast using Real Time Control Protocol (RTCP) messages as part of the Real Time Transport Protocol (RTP) [Schu96]. In T.124 membership can be restricted by requiring a password to join. On the MBONE encryption is used, and a mechanism for distributing encryption keys is needed.
Our approach to distributed audio rendering builds on current standards for VoIP audio conferencing. The RTP and associated RTCP protocols provide the foundation. We prefer a loosely consistent session view that can be implemented directly using RTCP, an approach that has been developed and advocated on the MBONE. This approach is known to work, and is known to scale to very large numbers of participants. When one makes the assumption that audio conferencing is part of a larger environment (for example, a shared virtual environment displayed using 3D graphics), the state that is shared by participants is much more than the audio session state. Shared (distributed) virtual environments always have protocols to ensure consistency of shared state, and burdening the audio layer with protocols to provide consistent audio session state is unnecessary overkill.
We assume that users have workstations with sufficient power to spatially render 2–3 real time audio streams, and several ambient and Foley sounds. We also assume that users are connected to an IP mutlicast network with sufficient bandwidth to receive 2–3 audio streams simultaneously. In normal conversation only one person talks, and a silence detection algorithm is used to mute traffic from non-talking participants, so multiple simultaneous audio streams will be the occasional and brief exception, not the rule.
The session concept is a means of limiting the distribution of real-time information to a specific group of recipients. In a virtual environment one does not join a conference or a multimedia session: one joins a group of people, or one walks into a room where conversations are going on. We do not think of our daily coffee-machine discussions as "multimedia sessions". The session mechanism should be invisible to an inhabitant of a virtual environment.
In Open Community [Yer97] a session is implicitly associated with a spatial locale, in that each locale defines a multicast address to be used for audio streams. In Jupiter [Curt95] any object can act as the manager of a multimedia channel, and that owner is typically a room. In MASSIVE [Green95] an aura defines a spatial extent; sources of sound contained within an audio aura will be heard.
As we are particularly interested in interworking with a VRML 2.0 DVE (e.g. a Living Worlds [Liv97] implementation) it is useful to discuss sessions in this context. In VRML 2.0 it is possible to associate a variety of sensors with VRML nodes. When a sensor is triggered, it can route an event to another VRML node. If that node is a SCRIPT node, then arbitrary logic can be invoked. For example, a room can be associated with a proximity sensor with the same spatial extent as the room, so that when the viewpoint of a user enters that space, an event is triggered. This ability to trigger events within VRML using a variety of criteria makes it possible to set up and tear down sessions without the user having to be involved. When I walk into a room, or approach another user's avatar, I trigger a script which establishes whether a session exists for that location. If there is no session, one can be created, and if there is a current session, I can be issued an invitation to join.
Unlike current MBONE or T.124 conferences, details of these lightweight, spontaneous conferences are unlikely to be found in a registry — they could be, but announcing to the world using a session announcement protocol that I have bumped into Jim at the virtual coffee machine seems excessive. In the absence of an explicit session description, there has to be a way of associating a session with the context in which it takes place. When I walk into a virtual location titled "Coffee Area", then out of all the sessions that might be taking place concurrently, I would like to identify the one currently associated with "Coffee Area". Each session has to be named in a way that is both unique and meaningful within the external context, in this case a VRML 2.0 world. If we assume that each participant in a shared VRML 2.0 world sees the same graph of VRML nodes, then it is straightforward to extract contextual information which can be used to identify a session associated with a node.
Race conditions will be the norm, not the exception. When two avatars A and B approach, then both auras will intersect "virtually simultaneously". If I am avatar A, then I will trigger a proximity sensor associated with my local copy of avatar B, and I will create a session (named after A) and invite B to join. User B will experience the same situation in reverse; he or she will trigger a proximity sensor associated with avatar A, create a session (named after B), and invite me to join.
Our session abstractions (see 6.2 below) make heavy use of opaque identifiers which have no significance within the conference session layer other than to provide an external context in which to identify sessions and audio entities, and to resolve race conditions associated with session creation.
An audio session is a set of audio entities that exchange audio and audio rendering streams. Section 7 discusses the content of these streams. In this section, we summarize the abstractions and the programing interface used by an application running in a client workstation.
We define the following object classes:
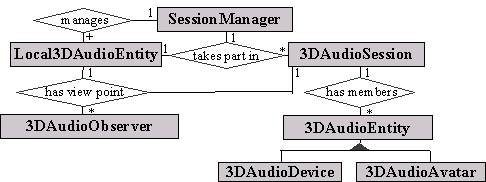
To enable the correlation of objects which exist in an external context (e.g. a room in a shared virtual environment) with the audio environment, a 3DAudioEntity is assigned a unique ID taken from an external context. A 3DAudioSession and a Local3DAudioEntity are also identified in the same way.
Fig. 1. Object relationship diagram.
The relationship of these classes is shown above in Fig. 1. In the following, we outline each object. What follows does not cover interfaces for permission, privacy etc.
Each potential session participant requires a local SessionManager component. The SessionManager maintains the pool of current sessions associated with a participant. The participant is represented by a Local3DAudioEntity. Each participant registers one or more Local3DAudioEntity objects with the SessionManager. The Local3DAudioEntity represents the user as a potential participant in a session. It contains the state needed to represent a participant, which could be a person, a robot, or devices such as an audio mixer or sound recorder.
The SessionManager is used to create 3DAudioSession objects. The session is initialised with an opaque uniqueID associated with an external context, such as the name of a room. The session is associated with a set of audio environment parameters as discussed in Section 7.1.
A participant in a session can issue an invitation to join the session. This invitation contains an opaque uniqueID derived from a context external to the SessionManager, such as a name extracted from a VRML node representing a potential participant. This invitation is disseminated to all SessionManagers.
We use a publish-and-subscribe, multicast-like notification service [Bra97] to implement this. SessionManagers subscribe to invitations concerning the Local3DAudioEntity(ies) they are managing, using the uniqueID of the Local3DAudioEntity as a subscription filter. In this way the rendezvous between an existing session and a potential participant can be made by using a piece of shared information (e.g. an arbitrary text string) from an external context, such as a VRML world. As well as listening for invitations, a SessionManager also publishes invitations emanating from Local3DAudioEntity(ies).
The underlying protocol for issuing this invitation could be the proposed Session Initiation Protocol (SIP) [Hand97b], which includes a full session description as specified in the proposed Session Description Protocol (SDP) [Hand97a]. As we have discussed, an invitation model is an attractive way of extending conference sessions in a virtual environment, and the SIP invitation model is a convenient fit.
3DAudioSession contains sessionParameters that describe the audio environment and information about the underlying transport used to carry audio and rendering streams. These parameters are discussed in Section 7. It also contains operations for:
The most contentious operation is enumerating the members, which returns a sequence of 3DAudioEntity. The result of this operation depends on the underlying implementation — if we adopt a the relaxed approach to membership typical of MBONE conferencing applications, then the result means "these are the members I currently know about".
A Local3DAudioEntity represents a potential session participant. It contains state needed to participate in a session — textual identification, preferred communication modes etc. The Local3DAudioEntity contains audioSourceParameters for describing the emission model of the audio source. These are outlined in Section 7. It is also the rendezvous used to receive invite notifications to join a session.
A 3DAudioObserver defines a point-of-view (POV) for an observer. Each participant in a session requires an audio viewpoint (analogous to the visual viewpoint in VMRL) from which to listen to a session. This is done by creating a 3DAudioObserver and registering with the corresponding 3DAudioSession. The POV can then be updated as the participant moves around in the virtual audio space. In practice the audio POV might be attached to the same spatial position as the visual POV, so that sound and vision coincide. An observer is characterised by position, orientation, and velocity.
A 3DAudioEntity represents a member of a 3DAudioSession. When a Local3DAudioEntity joins a session it supplies information about the participant which is made available to other participants as a 3DAudioEntity.
In summary, 3D audio session management shares similar concerns with any multimedia session management system, with the following additions:
We have not so far discussed how multiple audio streams from several sources are rendered in a spatial context. The abstractions defined in the previous section were a deliberate attempt to avoid confronting this detail — so long as a 3DAudioEntity updates its position, orientation and other parameters, we assume that sound can be correctly rendered so that each participant hears the correct spatial mix with respect to his or her audio POV.
We now discuss our "preferred implementation", with the caveat that there are several other possibilities. We assume that a session corresponds to a dynamically obtained IP multicast address, and that each participant in a session binds to that multicast address and receives RTP packets [Schu96] containing an audio payload in the same way as several MBONE tools. The audio streams from different participants are then mixed in the participant's workstation, rendering each participating 3DAudioEntity at the correct spatial position relative to the local POV. To do this the mixer needs to be continuously updated with the spatial rendering parameters corresponding to each audio stream.
We suggest that spatial rendering parameters should be an RTP payload type, and that each source of spatial audio should originate a corresponding RTP stream of rendering parameters. Each recipient can then synchronise an RTP audio payload with the corresponding RTP 3D audio rendering payload and carry out a spatial mix. This is similar to techniques used to synchronise RTP audio and video payloads.
In order to communicate 3D audio rendering information, a source and recipient must agree
An environment model defines a coordinate system, an origin, and a unit of measure. It also describes audio propagation characteristics such as the speed of sound, the dispersiveness of the medium, and Doppler effects. An environment will also introduce complex diffraction and reflection effects which cumulatively result in reverberation. Each order of reverberation is characterized by its decay time and the reflection coefficient. The decay time is dependent on the distance to the reverberating surface. The detailed computation of environmental effects on propagation is directly analogous to ray-tracing in 3D graphics and is often referred to as auralisation. It is important to note that while most people would not know the difference between a crude reverberation filter and sophisticated auralisation, environmental acoustic effects are important in disambiguating location in the vertical/front-back plane, and also for determining the distance of the source from the listener.
We assume that all the members of a session share the same environment model, and this is communicated as part of joining a session.
The emission model for a sound source describes the directional properties of the source, and how the sound is attenuated with distance. Sound sources, like light sources, occur in the literature in three forms:
Examples of directional emission models can be found in Intel RSX [Int96] and VRML 2.0 [VRML97], which use an ellipsoid model, and Microsoft DirectSound [DirX] and SUN's Java3D [Java3D] which use a cone model.
The authors are currently investigating these audio rendering models as a basis for an RTP audio rendering payload.
Our ongoing implementation has been heavily influenced by the detailed design of MBONE tools such as RAT [Hard96] and Nevot, which in turn are oriented around the session model of RTP and the associated Real Time Control Protocol (RTCP). We have adopted this model, and extended it with the session abstractions as defined above.
Our end-user application carries out 3D spatial mixing of participant voices by interfacing with Microsoft's DirectSound [DirX] interface. We are currently defining a strawman RTP audio rendering payload which will be incorporated into the prototype. Our current generation of hardware is Diamond's Monster 3D Sound card for the Wintel platform.
At the time of writing, an MBONE-style VoIP conferencing application with full 3D spatial positioning of participants in virtual audio space is near to completion. Initial trials have been very encouraging. Unlike similar applications we have not defined a user interface — our distributed 3D audio conferencing kernel is decoupled from the presentation of session state to the user. We use a control interface based around an open notification service [Bra97], and the object abstractions defined in Section 6.2 to add 2D and 3D (e.g. VRML) interfaces.
Several distributed virtual environments (DVE) we have investigated incorporate streaming audio between participants. A DVE requires internal protocols to maintain consistency between replicated copies of the object database used in the DVE, and the audio session model tends to be subsumed within the overall DVE structure.
Our approach is closer to the Internet multimedia community, in that we try to avoid making assumptions about an enclosing DVE, and extend the familiar multimedia session concept to include spatial audio rendering for multiple participants in a distributed environment. Integration between distributed spatial sound sessions, and multi-user visual environments based on Internet standards such as HTTP and VRML, results in sessions that are lightweight and triggered implicitly by criteria which could include spatial proximity and location.
[Beg94] D. Begault, 3D Sound for Virtual Reality and Multimedia, Academic Press, 1994
[Bra97] S. Brandt and A. Kristensen, Web Push as an Internet notification service, W3C Push Workshop 1997, available at http://keryxsoft.hpl.hp.com/
[Curt94] P. Curtis and D.A. Nichols, MUDs grow up: social virtual reality in the real world, in: COMPCON '94, available at ftp://ftp.lambda.moo.mud.org/pub/MOO/papers/
[Curt95] P. Curtis, M. Dixon, R. Frederick and D.A. Nichols, The Jupiter Audio/Video architecture: secure multimedia in network places, in: Proceedings of the ACM Multimedia '95, available at ftp://ftp.lambda.moo.mud.org/pub/MOO/papers/
[DirX] Microsoft DirectX 5.0 Software Development Kit, currently at http://www.microsoft.com/directx/resources/devdl.htm
[Green95] C. Greenhalgh and S. Benford, MASSIVE: a distributed virtual reality system incorporating spatial trading, in: IEEE 1995.
[Hag96] O. Hagsand, Interactive multiuser VEs in the DIVE system, in: IEEE Multimedia, Spring 1996.
[Hand97] M. Handley, J. Crowcroft, C. Bormann and J. Ott, The Internet Multimedia Conferencing architecture, IETF DRAFT draft-ietf-mmusic-confarch-00.txt, available at http://www.ietf.org/ids.by.wg/mmusic.html
[Hand97a] M. Handley and V. Jacobson, SDP: Session Description Protocol, Internet Draft, 1997, draft-ietf-mmusic-sdp-04.ps, available at http://www.ietf.org/ids.by.wg/mmusic.html
[Hand97b] M. Handley, H. Schulzrinne and E. Schooler, SIP: Session Initiation Protocol, Internet Draft, 1997, draft-ietf-mmusic-sip-04.ps, available at http://www.ietf.org/ids.by.wg/mmusic.html
[Hard96] V. Hardman and M. Iken, Enhanced reality audio in interactive networked environments, in: Proceedings of the Framework for Interactive Virtual Environments (FIVE) Conference, December 1996, Pisa Italy; also available at http://www-mice.cs.ucl.ac.uk/mice/rat/pub.html
[Int96] Realistic 3D sound experience, Intel RSX Software Development Kit, Intel Inc., 1996, available at http://developer.intel.com/ial/rsx/papers.htm
[Jacob93] V. Jacobson, S. McCanne and S. Floyd, A conferencing architecture for lightweight sessions, MICE Seminar Series, 1993, available at ftp://cs.ucl.ac.uk/mice/seminars/931115_jacobson/
[Java3D] Java 3D API specification, Version 1.0, 1997, Sun Inc, available at http://java.sun.com/products/java-media/3D/forDevelopers/3Dguide/
[Liv97] Living Worlds, Making VRML 2.0 worlds interpersonal and interoperable, specifications available at http://www.livingworlds.com
[Mac94] M.R. Macedonia, D.P. and Brutzman, Mbone provides audio and video across the Internet, IEEE Computer, April 1994.
[Rock97] R. Rockwell, An infrastructure for social software, IEEE Spectrum, March 1997.
[Schu96] H. Schulzrinne, S. Casner, R. Frederick and V. Jacobson, RTP: A transport protocol for real-time applications, RFC 1889, 1996.
[T.124] Generic Conference Control, ITU-T T.124, 1995.
[VRML97] The Virtual Reality Modeling Language, ISO/IEC DIS 14772-1, April 97, available at http://www.vrml.org/Specifications/VRML97/
[Wat96] R. Waters, D. Anderson, J. Barrus, D. Brogan, M. Casey, S. McKeown, T. Nitta, I. Sterns and W. Yerazunis, Diamond Park and Spline – a social virtual reality system with 3D animation, spoken interaction, and runtime modifiability, TR-96-02a, Mitsubishi Electric Research Lab 1996, available at http://www.merl.com/projects/dp/index.html
[Wat97] R.C. Waters and D.B. Anderson, The Java Open Community, Version 0.9 Application Program Interface, Mitsubishi Electric Research Lab 1997, available at http://www.merl.com/opencom/opencom-java-api.html
[Wat97a] R.C. Waters, D.B. Anderson and D.L. Schwenke, The Interactive Sharing Transfer Protocol 1.0, TR-97-10, Mitsubishi Electric Information Technology Center America 1997, available at http://www.meitca.com/opencom/
[Yer97] B. Yerazunis and B. Perlman, High level overview of Open Community, Mitsubishi Electric Information Technology Center America, 1997.
Aureal: http://www.aureal.com
Community Place: http://vs.spiw.com/vs/
Nevot: http://www.cs.columbia.edu/~hgs/rtp/nevot.html
Online!: http://www.online.com
 |
Colin Low is a Senior Engineer at Hewlett Packard Laboratories Bristol, UK. He has been working in the computer industry since 1976. |
 |
Laurent Babarit is a research scientist at Hewlett-Packard Laboratories in Bristol, UK. Laurent graduated from the Ecole Nationale Supérieure des Télécommunications de Bretagne, France, in 94 with a specialization in Networks and Multimedia Information Systems. WWW: http://www-uk.hpl.hp.com/people/lbt |