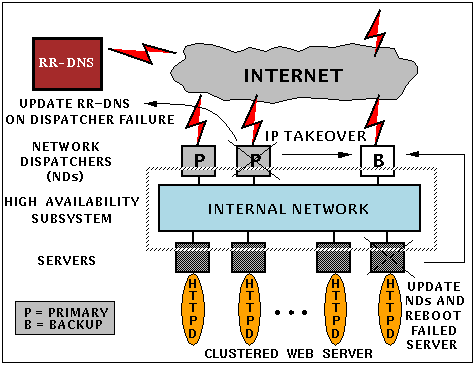
Fig. 1. High availability in a scalable Web server.
aIBM T.J. Watson Research Center,
Yorktown Heights, NY, U.S.A.
gdhh@watson.ibm.com,
gsg@watson.ibm.com and
rpk@watson.ibm.com
bIBM Almaden Research Center,
San Jose, CA, U.S.A.
rajat@almaden.ibm.com
At many Internet sites the workload required of various services, has grown to the point where a single system is often unable to cope. Offering the same service under a number of different node names is a solution that has been used by a number of sites, for example, by Netscape for its file transfers. Round-robin DNS [3] can also be used for much the same purpose, and allows the servers to publish a single name by which the service is known.
Neither of these approaches spreads the load evenly as the number of servers providing the service increases. In the first approach clients manually pick from a list of names providing the service. In all probability the names at the top of the list, or with some other feature, will be chosen. Whatever attribute is chosen it is unlikely to be related to the current load on the servers. The list can be manipulated to put lightly loaded nodes in a place where they are most likely to be picked, but this cannot necessarily be done on a timely basis. Round-robin DNS eliminates psychology as an issue, but replaces it with IP address caching. Once a particular client or proxy has received an IP address for a service, that IP address may be cached for hours, or even days. Intermediate name servers and gateways also frequently cache IP addresses and usually ignore any time-to-live limits suggested by DNS. With either method, control over the number of request per server is limited, which causes the load to be unevenly spread.
As the Web matures, the ability to react to load imbalances becomes increasingly important. Initially, most Web servers delivered content based on more or less uniformly small files. Consequently, if the number of requests was evenly distributed, the load on the servers would be relatively uniform. However today, and increasingly in the future, Web servers hand out more dynamically-generated results with substantial graphics content and a wide variation in the computation required to produce the results. This variation of content and effort makes it much more difficult to keep a group of servers evenly loaded.
Network Dispatcher is our solution to the problems of keeping the load evenly spread or balanced on a group of servers. Network Dispatcher is integrated with the TCP/IP stack of a single system. It acts as a dispatcher of connections from clients who know a single IP address for a service, to a set of servers that actually perform the work. Unlike other approaches, only the packets going from the clients to the server pass through Network Dispatcher; packets from the server to client may go by other routes, which need not include Network Dispatcher. This reduces the load on Network Dispatcher, allowing it to potentially stand in front of a larger number of servers.
Network Dispatcher has been used to spread the load as part of several large-scale Web server complexes, for example the 1996 Summer Olympic Games, Deep Blue vs Kasperov, and the 1998 Winter Olympic Games Web sites. These systems handled millions of requests per day, going to dozens of servers at a time. Network Dispatcher has also been successfully used with heterogenous servers.
The remainder of this paper is organized as follows. Section 2 describes how packets are captured by Network Dispatcher and forwarded to servers. Section 3 is about how the manager and its advisors control the sharing of load. Configuration of Network Dispatcher and the servers is discussed in Section 4. Section 5 explores keeping a server complex that uses Network Dispatcher running in the face of various failures. Section 6 considers the need for affinity between different TCP connections from the same client. Section 7 explores how we eliminated the configuration limitations discussed in Section 4. Section 8 presents the results of some performance measurements. Finally, we discuss related work in Section 9, and conclude in Section 10.
The part of Network Dispatcher which distributes incoming connections and packets to hosts that are part of the cluster is called the Executor. The Executor handles connection allocation and the forwarding of packets for each TCP connection. Network Dispatcher supports Virtual Encapsulated Clusters (VEC), which are collections of hosts providing services on a single IP address. The Executor maintains a connection table, VEC table for each VEC, a port table for each VEC, and a server table for each port within a VEC.
The Executor checks the IP address to see if an arriving packet is for a VEC; if it is not it is immediately queued to the local TCP stack. The next check is to verify that the requested VEC is providing service on the indicated TCP port and that there are servers defined. If not, the packet is discarded. If the packet is for an existing connection the connection entry is time stamped. If the packet does not contain a RST, SYN, or FIN flag bit, it is forwarded to the associated server. Otherwise, the connection-state checks (described below ) are made and the packet is forwarded.
Packets for non-existing connections must contain a SYN and a server must be available (non-zero allocation weight) or they are discarded. Otherwise a connection table entry with the IP address of the selected server is created, time stamped, and then the packet is forwarded to the selected server.
The Executor forwards packets to cluster members without modifying the IP header in the source packet. Consequently the packet received by the target server will contain a header addressed to the VEC.
The Weighted Round Robin (WRR) connection allocation algorithm is efficient and maintains the following conditions. All servers with the same weight will receive a new connection before any server with a lesser weight receives a new connection. Servers with higher weights get more connections than servers with lower weights and servers with equal weights get an equal distribution of new connections. Finally, an eligible server will be returned on each invocation of the allocation function or an indication that there are no eligible servers. A more detailed description of the WRR algorithm contained in [19].
The Executor maintains each entry in the connection table in one of two states: active or finished. Only three flag bits from the TCP header are use to control state transition, RST, FIN, and SYN. RST always causes a connection to be purged. SYN always causes a connection to become active and FIN always causes a connection to become finished. Packets without these bits are passed through without additional processing. Because of the conditions described below, conversation cleanup for connections which are not reset is done by background garbage collection driven off of the slow TCP timer.
The Executor participates in only the client-to-server half of each TCP conversation. Therefore conversation termination cannot be completely determined because each half of a TCP conversation can be terminated independently of the other [20]. If the server does an active close then the Executor could safely purge its connection table when it sees the client FIN. However, when the client does an active close, this implies that the server is to do a passive close when it completes the client request. Consequently, the Executor cannot purge its connection until the last ACK has flowed from the client. A second problem is that if a client crashed or loses connectivity there may be no FIN or RST to indicate that the conversation is done. The servers will properly time out their connections and send RST to the clients. However the Executor will not see this. To solve these two problems the Executor maintains distinct timers which indicate how long a conversation may remain inactive in finished state how long a conversation in active state may remain inactive.
The Executor maintains the total number of connections received and the total number of connections completed as counters. It also maintains the number of connections in active state and the number of connections in finished state as gauges. Additional counters are maintained for diagnostic purposes. All counters and gauges can be examined by the manager.
The service time and resources consumed by each type of TCP connection request varies depending on several factors. These factors include request specific parameters (type of service, content) and currently available resources (CPU, bandwidth). For example, some requests may perform computationally intensive searches, while others perform trivial computation.
A naive distribution of TCP connections among the back-end servers can (and often does) produce a skewed allocation of the cluster resources. For example, a simple round-robin allocation may result in many requests being queued up on servers that are currently serving ``heavy'' requests. Obviously, such an allocation policy can cause underutilization of the cluster resources, as some servers may stay relatively idle while others are overloaded. This condition, in turn, will also produce longer observed delays for the remote clients.
Load-balancing and load-sharing are two main strategies for improving performance and resource utilization [5]. Load-balancing strives to equalize the servers workload, while load-sharing attempts to smooth out transient peak overload periods on some nodes [11]. Load-balancing strategies typically consume many more resources than load-sharing, and the cost of these resources often outweigh their potential benefits [12]. We found this to be the case in allocating TCP connections for HTTP requests; therefore, the first Network Dispatcher prototype implemented a load-sharing allocation policy.
The Manager component implements policies for dynamic load-sharing connections among the VEC servers according to their real-time load and responsiveness. Advisor processes collect and order load metrics from the VEC servers. The Manager combines this data with additional data provided by the Executor to compute new weights for all VEC servers. These weights are used by the Executor to allocate new TCP connections.
The Network Dispatcher Manager implements a dynamic feedback control loop that monitors and evaluates the current load on each server. The Manager computes and adjusts the weights associated with each service instance in the WRR algorithm, so that incoming TCP connections are allocated in proportion to the current excess capacity of the servers. The Manager estimates the current state of each server using computed load metrics and administrator configurable parameters such as time thresholds. Load metrics are classified into three classes: input, host, and service. The details of the metrics used by Network Dispatcher are given in [19].
There are three parts of deploying Network Dispatcher: configuring the Network Dispatcher machine, configuring the servers to work with Network Dispatcher, and deciding on the network configuration between Network Dispatcher, the servers, and the Internet. To configure the Network Dispatcher machine you must assign the VEC addresses, ports for each VEC, and servers for each port. After Network Dispatcher is operational, VECs, ports, and servers can be dynamically added or removed as necessary.
Configuring the servers is only slightly more complex. Because the servers accept packets for the same IP address as Network Dispatcher, the VEC address, they must be configured in a way that does not cause conflicting ARP entries to be generated. When Network Dispatcher delivers a request to a server via the same network on which it receives the request, each server must alias the loop-back device to the VEC addresses for which it is providing services. When a separate network is used between Network Dispatcher and the servers the same configuration technique can be used or ARP can be disabled on the network, in which case the interfaces can be directly aliased.
Because packets are forwarded to destination servers without modifying the IP headers, unless additional support is provided (described in Section 7), the servers must be on a local Network with the Network Dispatcher machine.
Network Dispatcher can be configured with multiple network interfaces and can be optionally co-located with a server. Packets from Network Dispatcher to the servers can follow a separate network path than the response packets from the servers to the clients. This enables better use of network bandwidth. For example, the 1996 Olympic Web site had a Network Dispatcher node on the public network, a separate token ring network between Network Dispatcher and the servers, and the servers attached to the public network via ATM. This takes advantage of the fact that Web responses are generally much larger than the corresponding requests.
Figure 1 illustrates a scalable Web server [24] with a set of Network Dispatchers routing requests from multiple clients to a set of server nodes. While a single Network Dispatcher node can handle the routing requirements of a large site, multiple Network Dispatchers may be configured for high availability and non-disruptive service. Recovery programs, as depicted in Fig. 2, consist of multiple steps, and each step, which can be a single command or a complex recovery script, can execute on a different node of the system. Recovery steps can be forced to execute in sequence via barrier commands that are used for synchronization.
For the configuration shown in Fig. 1, either a server or an Network Dispatcher node can fail (node-down event). The steps involved in recovery from an Network Dispatcher node failure are: (i) Changing the configuration of RRDNS to exclude the failed node (i.e., new Web client requests will be sent to the remaining Network Dispatcher(s)); (ii) IP take-over of the failed Network Dispatcher node, so that clients that have cached the IP address of the failed Network Dispatcher now go to a replacement; (iii) take-over of Network Dispatcher functionality by the replacement so it routes Web requests to the server nodes and (iv) automatic reboot of the failed node (possible on SP-2, but may not be possible in general clusters).
When the rebooted node rejoins the cluster, a node-up event will be generated and a set of actions initiated by the recovery driver will (i) restart the SP switch/networks on the rebooted node (ii) take-back the IP address from the buddy/spare (iii) take-back Network Dispatcher functions from the buddy/spare. and (iv) reconfigure RRDNS to resume giving out the IP address to new clients.
When a server node fails, there are a different set of recovery actions to be performed: (i) the configuration of all Network Dispatcher nodes is changed to exclude the failed server node so no Web requests are routed to it, (ii) Database software (and what ever else is required) is moved over from the failed node to a spare/buddy, and (iii) the failed node is automatically rebooted (on SP-2). Similarly, when a failed server node reboots, the node-up event causes (i) restart of the SP switch/ networks on the node (ii) reconfiguration of the Network Dispatchers to include the newly functioning node.
Figure 2a and b depicts recovery programs that indicate the sequences of steps described above. Recovery scripts only perform those steps which are appropriate for the type of node being recovered. The config_file is used by the recovery driver to evaluate the node relationships for recovery.
Fig. 2. Recovery programs for node failure event (a) and node up
event (b).
Up to this point, we have assumed that each TCP connection is independent of every other connection, so that each can be assigned a server independently of any past, present, or future assignments. However, there are times when either for functional or performance reasons, that two connections from the same client must be assigned to the same server. In cases where this is done for performance, the quality of the load sharing may suffer slightly, but the overall performance of the system improves.
FTP is an example of a functional requirement for connection affinity. The client and server send command information on a control connection, port 21, but they make bulk transfers on a separate data connection, port 20. The packets coming on the data connection from the client must go to the same server as it is connected to on its control connection.
For active FTP, the data connection is initiated by the server. The connection starts with a SYN packet coming from the server's port 20 and going to some agreed upon port of the client's. Since Network Dispatcher only participates in the client to server half of the TCP conversation, it has no knowledge of this connection until the first packet returns from the client to the server. This SYN-ACK packet is dealt with using the knowledge that an FTP server uses ports 21 and 20. Instead of looking for an existing connection on a server's port 20, Network Dispatcher's connection table is searched for one on port 21.
For active FTP, Network Dispatcher could, conceivably, examine the packet coming from the client that informed the FTP server of which client port to connect to; this information would allow Network Dispatcher to anticipate the first client-to-server packet of that connection. But for passive FTP, which is used, for example, by Netscape Navigator, that is simply impossible, since it is the server that picks an ethereal port and informs the client of its choice in a packet that does not flow through Network Dispatcher.
Our current solution to this problem is to allow a VEC to be designated as willing to accept client FTP connections on any ethereal server port as long as there is an open command connection from the same client. There is no additional risk over any normal server running passive FTP without Network Dispatcher and this approach could be extended to explicitly exclude access to any port for security reasons.
SSL is an example of a protocol which offers a performance benefit for recognizing affinity between a given client and a particular server. Specifically, when an SSL connection is made, usually to port 443 for Web servers, a key for the connection must be chosen and exchanged, unless a previously agreed upon key is available. Key negotiation is expensive, and worth avoiding even at the cost of some slight imbalance in load. Note, however, that an SSL key has a life span of 100 seconds after the end of a connection which uses it, after which it expires; consequently, there is no advantage to preserving the affinity beyond that point.
Network Dispatcher allows a port to be designated as "sticky". A record is kept in Network Dispatcher of old connections on such ports, along with the time when they were closed. If a request for a new connection from the same client on the same port arrives before the affinity life span for the previous connection expires, the new connection is sent to the same server that the old connection used.
Certain configurations of database servers provide another example of where affinity can be used. A shared data server pays a substantial cost to move data locked and resident in one server node over to another. It would be advantageous to make the port by which the server is accessed sticky, if clients were likely to make a series of requests that relate to the same data.
Network Dispatcher gains performance by only participating in the client to server half of the TCP conversation. By leaving the clients' packets unchanged as they pass through Network Dispatcher on their way to the servers, the response packets sent from the servers need not pass back through Network Dispatcher along the way back to the clients. This performance benefit implies a configuration limit: Network Dispatcher and each server must be directly connected to one another by a single, uninterrupted segment of a local-area network. By staying on the same LAN segment, packets can be sent from Network Dispatcher to the servers by controlling the hardware (MAC) addresses used when sending the packets over the link.
Disobeying this limitation would cause a packet loop between the gateway and Network Dispatcher. The obvious solution is to rewrite the packets on their way to the servers and rewrite them again on their way back to the clients. The cost of this solution is the reduced performance of having all of the server-to-client traffic passing through Network Dispatcher. For some types of traffic, e.g. Web applications, server-to-client traffic is usually much heavier than the client-to-server traffic.
Our solution combines these two approaches eliminating the Network Dispatcher configuration limit and it does not require that server-to-client traffic pass through Network Dispatcher. Packets from the clients are modified by putting the IP address of the chosen server in place of the target VEC address. However, the source address is left unchanged. The packet is then sent to the server using the normal mechanisms for passing an IP packet through an arbitrary interconnection network. The target server is another Network Dispatcher which is configured to change the destination IP address back to the original VEC address. The packet is then forwarded to the eventual server assigned to it by the second Network Dispatcher.
In addition to relieving our configuration constraints, this method also offers opportunities for wider load distribution. For example, suppose there is a group of nodes in location A, acting as one large-scale server and another group of nodes in location B, with both groups serving out the same information. If the group in A becomes overloaded, its Network Dispatcher could be configured to send some fraction of new connections to Network Dispatcher in B. This traffic would be taking an extra set of hops from client to server, but the return traffic would be just as efficient as if a direct connection had been made. If there is only one, or a very few, servers at the far end of the network from the first Network Dispatcher, co-locating the second Network Dispatcher with the servers eliminates a node and a hop.
In this section, we present packet rates, as well as HTTP connection rates for a set of Web workloads. Because Network Dispatcher only participates in the client-to-server half of a TCP conversation it does not process the large packets which typically result from Web requests.
These measurements were performed by driving large Web workloads through Network Dispatcher to a set of servers using WebStone [17], a Web benchmark using a high bandwidth switch on an IBM SP-2 system. Network Dispatcher executed on one of the SP-2 node, an POWER2 67Mhz CPU (equivalent to a RS6000 Model 39H) with 2MB L2 Cache and 256 Mbytes of memory. At close to 100% CPU utilization Network Dispatcher could handle a maximum of about 22000 total packets per second (11K incoming packets per second). This corresponds to about 2200 HTTP TCP connections per second (Tcps) for small files (2 bytes). On a less powerful CPU (e.g an RISC/6000 Model 580), using a shared Token Ring for inbound and outbound traffic, a peak connection rate was measured of about 815 Tcps for the same workload.
Table 1 presents the packet and connection data for different workloads (with different file sizes) that were used to drive Network Dispatcher and associated servers using WebStone 1.1. For this data set, 6 SP-2 server nodes were configured with Netscape Enterprise servers, and 248 Web clients were configured on 6 other nodes. Workloads with larger files were also used, including Silicon Surf and Photo, two workloads shipped with WebStone 1.1.
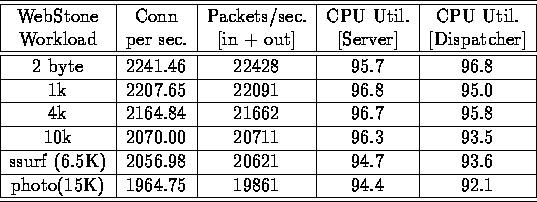
We also drove similar workloads, using WebStone 2.0, on an SP-2 with a TBS switch and TB2 adapters. The overall projected performance is very similar to that presented in Table 1. On a smaller system with 4 server nodes and 80 Web clients, the projected connection rate at 100% utilization was about 2165 connections/second.
The measurements presented above were performed on an early version of Network Dispatcher. Newer versions with performance enhancements are available [22]. The maximum connection rate observed during peak periods of the 1996 summer Olympics was about 600 connections per second, compared with the 2200 connections/second measured in the lab.
The WebStone benchmark differs from real-life workloads in several ways. First, although several hundred clients can be simulated, they share only a small set of independent IP addresses (WebStone client nodes). Another important difference is that all WebStone connections are fast connections that hold resources for shorter durations than, say, connections that are initiated via 14.4 Kbit or 28.8 Kbit modems. Network Dispatcher uses a hash function to locate existing connections for forwarding packets. This hash function was shown to be to be very efficient. At a large popular Web site it was measured to have a 2% collision rate while handling over 40 million connections per day.
Network Dispatcher provides configurable timeout for cleaning connections in the finished and active states. While our experiments with varying these timeouts did not affect overall Network Dispatcher performance with WebStone, they could have significant effects in real-life deployments.
Many Internet sites rely on DNS-based techniques to share load across several servers, e.g., NCSA [10]. These techniques typically include modifications to the DNS BIND code, like Beecher's Shuffle Addresses, Rose's Round-Robin code (RR-DNS), Brisco's zone transfer changes [3], and Schemers' lbnamed [15].
There are several drawbacks to all DNS-based solutions. All DNS variations may disclose up to 32 IP addresses for each DNS name, due to UDP packet size constraints. Knowledge of these IP addresses may creates problems for clients (e.g., unnecessary reload of HTML pages in cache), and also for network gateways (e.g. for filtering rules in IP routers). Any caching of IP addresses resolved via DNS creates skews in the distribution of requests. Consequently, Mogul suggested that the ``DNS-based technique cannot provide linear scaling for server performance at peak request rates'' [13]. Notice that while DNS supports a ``no name caching'' option, this is regularly ignored.
DNS-based solutions are very slow (or unable) to detect server failures and additions of new servers. Furthermore, while the server host may be running properly, the specific server software (e.g. httpd) may have failed. In a pathological case, a load balancing DNS tool may see that a server is under-loaded (because the httpd demon failed) and give it even higher priority.
During 1996 several packet forwarding hardware products have been introduced, e.g., Cisco's LocalDirector [4]. These devices translate (rewrite) the TCP/IP headers and recompute the checksums of all packets flowing between clients and servers in both directions. This is similar to Network Address Translation (NAT) [6], adding the choice of the selected server. Notice that this device quickly becomes the main network bottleneck. HydraWeb [7] is a similar device that also requires installing software agents at each server to analyze their load.
Resonate Dispatch [14] is a software tool that supports content-based allocation of HTTP requests. TCP connections are accepted at the ``Scheduler'' host which examines the URL and then transfers the TCP connection to a host that can serve the request. This method, however, requires modifying the IP stack of all the server hosts (SPARC/Solaris) to support the TCP connection ``hop''.
A few research projects have also reported similar features. The Magicrouter [1] translates the TCP headers in both directions and allocates connections randomly or based on incremental load. Yeom et al. [18] proposed a port-address translator gateway that assigns a different port number to each connection.
ONE-IP [16] presents two techniques for building scaleable Web services. Both ONE-IP and Network Dispatcher use IP aliasing and as implemented, both approaches are transparent to clients and servers. However, the use of aliasing in Network Dispatcher is more clever, consequently no ARP packets are generated by the servers and no modifications or permanent ARP entries are requried at the IP router. ONE-IP uses a hash function to partition the client request space accross servers and proposes modifying the hash function when a server becomes disabled. In order for the hash in ONE-IP to acheive the same degree of load sharing as Network Dispatcher it would have to accurately partition the client request space for all possible request sequences and all possible server loads. Instead, Network Dispatcher dynamically adjusts the distribution of incomming requests based on the server' load and their availablitiy. Network Dispatcher uses hashing for routing subsequent packets to the selected server and only at the Network Dispatcher node. Finally with broadcast based dispatching under ONE-IP, every server must receive and filter every request. Filtering reduces the capacity of each server to serve requests. As the load on the cluster increases the ratio of requests processed to requests received per server decreases idicating that a larger number of servers is required to acheive the same level of service as Network Dispatcher.
The basic IP packet forwarding technology of Network Dispatcher was originally developed as part of the Encapsulated Cluster (EC) project [2]. In this system, incoming IP packets were routed into a cluster of servers, and outgoing packets had their IP addresses rewritten.
Network Dispatcher processes only the client-to-server half of a TCP conversation. For protocols where the server-to-client traffic is larger than the client-to-server traffic, this method provides a performance benefit. Because of the characteristics of Internet traffic Network Dispatcher supports dynamic, real-time feed-back to assess and respond to the current traffic pattern. It uses an efficient algorithm to allocate new connections based on the available server capacity. A product based on Network Dispatcher is available from IBM [22]. Network Dispatcher was developed for and evaluated with highly loaded real-life Web sites. It was found to be effective in handleing tens of millions of connections per day. It is also useful for any site wich required multiple servers to respond to the client request load. Network Dispatcher can be used to do load sharing accross these server for most TCP based services (such as the Web).
Wide area network support allows the forwarding of TCP packets to VECs located anywhere in the Internet. Network Dispatcher's affinity support broadens the types of TCP applications that can be supported, as long as the affinity requirements are known. Network Dispatcher has affinity support for SSL and FTP. It is possible to build TCP based protocols with implicit affinity rules which Network Dispatcher cannot currently support.
UDP presents a completely different affinity problem. Without the explicit markers that identify architected into TCP packets, there is no general way to tell when Network Dispatcher should regard one packet as related to another. Consequently there are only ad hoc solutions for individual UDP-based services.
Some problems are very common. The most common problem to solve with UDP packets is packets that are never interrelated at all. Some implementations of the Radius Authentication Server (RFC 2058) is an example of a use of UDP for which this is true. For this type of UDP based service our solution is to assign each packet independently of the others.
Generally Network Dispatcher can be used with UDP services that are written to work properly on a multihomed host. In particular, the server has to bind the socket used to reply to the client to the specific IP address the client connected to. When this is done correctly the socket will be bound to the VEC address and the client will be able to receive the reply. for a more detailed explination see TCP/IP Illustrated, Volumn 2, page 779 (W. Richard Stevens, Addison Wesley, Reading, MA).




