2. URI content permanence
Because the content of a WWW document can be updated at any time, the content of the document is unreliable. Consequently it is difficult to use such a source as a reliable reference due to the changeability of its content. A technical solution is needed to keep the content referenced by a link the same even when the corresponding document needs to be updated. This can be done by retaining revisions of the document and referencing the appropriate one. The solution proposed here involves extending URIs to include date or version information, which the server uses to obtain the appropriate revision of a document. (The syntax for the extended URI is described in Section 3.) Hypermedia authors can use this capability to ensure that links in their authored documents continue to refer over time to the same content that they originally referred to. Thus authors who refer to WWW documents could rely on the permanence of the contents of those documents similarly to how they would rely on the permanence of the contents of printed documents.
In our system, the client requests a URI augmented with a suffix that is a date or version description, and the server provides the appropriate version of the requested resource. The server does this by extracting the requested version from a file containing the document and its revision history. In this system the WWW document provider must store documents using the RCS revision control system. In conjunction the Apache server must be configured to use the new module described in this paper.
The source code for the content permanence functionality is currently being drawn directly from the Unix rcs command co (check out) [11]. This functionality has been added to the Apache WWW server as a special Apache "module," per the Apache Applications Program Interface (API).
Our design falls squarely in the category of distributed version maintenance systems. Every site wishing to have support for links to permanent content must run a server that supports version retrieval. Centralized version maintenance would also be possible. Under a centralized approach, a site might contract with an external version maintenance service to archive the various revisions of their resources and make them available over the WWW. This would reduce the possibility of document providers altering preexisting document versions.
In both the distributed system and the centralized system the server is altered to provide the particular version of interest to a requesting client. Alternatively the server could provide the entire contents of the RCS file letting the client extract the desired version. This method would use a WWW client plugin that understands either RCS files or some other format such as non-standard HTML tags that denote version-specific information, as in [ 19]. Two major disadvantages of the client approach compared to our server approach are (1) the WWW contains more installed clients than servers, so a server-based solution such as ours has a wider impact per installation, and (2) the client approach implies that the proper version is extracted after transmission of all versions over the Web, leading to higher network traffic and slower response times compared to a server approach such as we describe here.
Another design issue concerns security. Should archived versions be authenticated in some way? If not, archived versions could be surreptitiously changed. An authentication system such as that sold by Surety [13] could be integrated into a version archiving solution to alleviate this type of problem.
Each of the above mentioned approaches uses extended
URIs that contain date or version specifications. We define the syntax
for these extended URIs in the following section.
Since our system supports URIs augmented with date
or version specifications, it is important to describe the syntax and
semantics of these augmentations.
In order to augment URIs with revision information,
each actual version must have some unique version designation. Version
information can be specified by actual version number or by a date. To
make sense of URIs augmented with a date specification, there must be a
mechanism at the server for translating the date specification into the
proper version number. The version number received is the most recent
version saved prior to the date specified. This implies that many date
specifications may map to one version.
Since HTTP GET requests by the client must contain a
version or date specification in our system, a mechanism for this is
necessary. One possibility is through a new HTTP request-header field.
Link specifications in an HTML document could include the information,
the client could use that information in the link (when it is provided)
and put it in the HTTP request-header field, and finally the server
could use the new request-header field to help in extracting the proper
version to serve. Alternatively the URI can be extended to include the
date or version desired. This eliminates the need for an additional
request-header field. The server then simply parses out that information
from the URI and uses it to extract the proper version. We have
established a scheme for this, as follows.
First, to ensure backward compatibility, we specify
appropriate handling of a request for a URI having no appended version
or date specification. Such a request would return either the most recent
version in the case of multiple versions or the only available version
in the case of a single version. A request of this type is depicted in
Fig. 1.
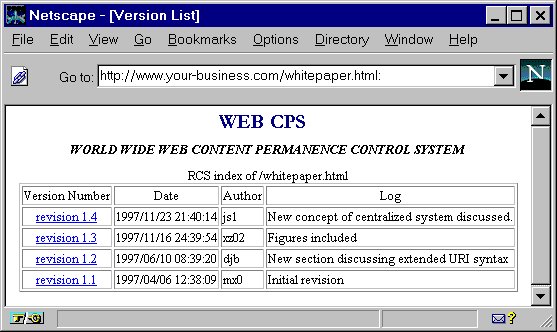
We specify that appending a colon (":") to a
URI causes the server to serve a listing of all versions and their
associated dates. This of course requires the server to respect the ":"
as a reserved character in the syntax of URIs with version or date
specifications. The results of such a request are shown in
Fig. 2, which contains a list of clickable
version links. This is useful when referring to all versions or when
uncertain as to which version to reference.
A version number following a ":" causes the server to
serve the specified version. An example is provided in
Fig. 3. A
document discussing the revision history of another document could
benefit from this syntax. Links referring to a particular
version of source code would be another case in which this syntax
might be useful.
We specify that appending a date spec to the URI
causes the server to serve the version that was current as of that
date. This would be the most recently saved version prior to the date
specification. Versions appearing later than the requested date
specification would be unsuitable because they would contain changes
that occurred after the time at which the content was cited by the
link. The date specification format should comply
with RFC 1123 [23] or ANSI C's
asctime() except that spaces are replaced by underscores. A
date extended URI is shown in Fig. 4.
Date specifications might be used when referring to
documents that are time sensitive. A weather bulletin is such an example
because of its time dependent nature. Date specifications might also be
used when attempting to provide a sense of the time relation between
separate documents. This might apply when reviewing the work histories
of two groups with competing patent claims. Lastly a writer may find
it easier to just append the current time to a URI to reference the
current version of a document.
As a heuristic guideline, the syntax used should
reflect whether the revision history is of more interest (suggesting
the version syntax) or whether the currency is of more interest
(suggesting the time syntax). For both syntaxes, the mechanism
for retrieval of the appropriate revision is similar. We discuss the
mechanism our system uses next.
Due to the popularity of the Apache server and the
availability of its source code, we decided that Apache with its API was
an appropriate server for adding the necessary functionality for
handling version and date extended URIs. Apache's modular software
design allows second party modules to be easily incorporated into the
server. System administrators can install Apache with the modules of
their choosing providing the server with the functionality necessary for
their particular site.
In designing a new module to handle
content permanence, it is desirable to follow the API that Apache
provides for module design [24]. Apache
modules are designed with one or more standard functions. Each function
is associated with some stage of the request processing. During each
stage the corresponding functions from each module are called by the
server core. The stages that the new content permanence module uses are
fixup, handler, and logger. These stages are called
in the following order.
The fixup routine for the new content permanence
module checks to determine if the requested document is under RCS
control. It does so by checking for an RCS file with the same name as
the requested document followed by a ",v" extension. This file if it
exists resides in the RCS subdirectory under the directory from which
the document is being requested. If the file is under RCS control, the
fixup routine in the new module calls code to extract the appropriate
revision of the file from the RCS revision repository and store it in
a temporary file. The server then is internally redirected to access
this file. In the event that the request was for a revision listing,
such a listing is returned and no redirection is necessary. When the
request is completed, the new module's logger routine removes the
temporary file.
Various configuration file commands control the new
module. One specifies the directory for storing temporary files. Another
enables or disables the module. The system can be configured to allow or
disallow override of this command in .htaccess files.
In conjunction with this software, software has been
developed to process an HTML document and add date specifications to
each URI. Currently the date specifications represent the time at
which the software was run. This software is being augmented to check
each link to determine if it points to a document under revision
control and if so what the most recent version is. Only links to
documents under revision control will be considered by this program
for augmentation with date specifications. Those links could either
be augmented by default or augmented if the user responds positively
to a prompt.
This paper describes our approach to supporting
permanence in the content referred to by links in HTML documents. Thus
it aims at preserving the traditional approach of new work building upon
an unchanging foundation of previous work.
In our solution, the server retrieves the correct
version of a document based on the version or date specification
suffix appended to a URI. Documents under revision control must be
maintained using systems based on RCS. Other revision systems could be
used but would require modifications to the new content permanence
Apache module. The new module is build using the standard Apache API.
This new module uses code from the generally available RCS revision
control system. Because it supports serving URIs augmented with date
or version specifications in a distributed manner, using the existing
Apache module API for accessibility and low cost, it is suitable for
widespread, incremental application. It requires no special client
programs. The modified Apache server we have developed also
understands ordinary URIs without version or date suffixes. We also
described our working prototype program for transforming ordinary URI
links in an HTML file into URIs containing appropriate date
specifications. The additional features that we plan to add to the
existing system will serve to better meet the goal of an accessible,
workable system for encouraging content permanence.
The importance of having links refer to content which
is permanent is simply, and importantly, to preserve the traditional
system of supporting new work by referencing previous work despite the
ongoing transition to a cyberspace era of digitally stored
references. If referred-to work can change, as is currently the case on
the WWW, that traditional and important system is in jeopardy.
The new Apache module will soon be thoroughly tested
and documented, and submitted for distribution as an officially
sanctioned Apache module. Our approach and syntax need to be developed
into a form suitable for consideration and approval by the IETF. Work is
need toward gaining acceptance of the system for use in a digital
library of significant size and impact, and more generally toward
obtaining general acceptance in the WWW community, with all of the
technical development and public acceptance measures that entails.
The Netscape browser frame is a trademark of
Netscape Communications Corp.
*Citations of electronic sources
follow the format described by J. Walker, Walker/ACW Style Sheet
(Columbia Online Style), January 1995,
http://www.cas.usf.edu/english/walker/mla.html (February 10, 1998).
The format has been endorsed by the Alliance for Computers and
Writing.
He received the Ph.D., M.S., and B.S. degrees in electrical
engineering from the
University of Illinois at Urbana-Champaign
in 1996, 1991 and 1986, respectively. During his
graduate studies he was a research assistant in the
Center for Reliable and High-Performance Computing
at the University of Illinois.
From 1986 to 1989 he worked for
Convex Computer Corporation, now a division of
Hewlett Packard, on
the design of Convex's C2 and C3 Supercomputers.
3. Date and version extended URIs



4. Apache module design and supporting software
5. Conclusion
Acknowledgements
References*
Persistent URL home page, Online Computer Library Center,
Inc. (OCLC), December 1997,
http://purl.oclc.org (February 10, 1998).
PURL free on Web, Information Retrieval and Library
Automation, 32(2): 3, July 1996.
OCLC offers its PURL software for free on the World
Wide Web (WWW), Online Libraries, and Microcomputers,
14(8–9): 7, September 1996.
S. Weibel, The changing landscape of network recourse
description, Library Hi Tech, 14(1): 7–10, 1996.
K. Sollins and L. Masinter, Functional requirements for
Uniform Resource Names, Request for Comments (RFC) 1737, Internet
Engineering Task Force, December 1994,
ftp://NIS.NSF.NET/internet/documents/rfc/rfc1737.txt (February 10,
1998).
Uniform Resource Name (URN) charter, Internet
Engineering Task Force, January 1998,
http://www.ietf.org/html.charters/urn-charter.html (February 10,
1998).
Internet Engineering Task Force home page, Internet
Engineering Task Force, May 1997,
http://www.ietf.org (February 10, 1998).
B. Kahle, Preserving the Internet, Scientific
American, 276: 82–83, March 1997,
http://www.sciam.com/0397issue/0397kahle.html (February 10, 1998).
Building a digital library for the future, Internet
Archive, San Francisco, CA,
http://archive.org/home.html
(February 10, 1998).
W. F. Tichy, RCS – A system for version control,
Software – Practice and Experience, 15(7):
637–654, July 1985.
P. Eggert and W. F. Tichy, rcsintro(1), 1991,
http://pardis.sas.upenn.edu/man.shtml/rcsintro(1) (February 10,
1998).
S. Haber and W. S. Stornetta, How to time-stamp a
digital document, Journal of Cryptology, 3(2): 99–111, 1991.
Surety Technologies, Surety
Technologies, Inc., December 1997,
http://www.surety.com (February 10,
1998).
B. Menkus, A secure electronic document audit trail
product, EDPACS, 22(12): 15–16, June 1995.
Surety Technologies teams with Research Libraries
Group to protect scholarly research information online, Surety
Technologies, Inc., January 1997,
http://www.surety.com/in_news/RLG.html (February 10, 1998).
Surety Technologies joins Research Libraries Group,
Computers in Libraries, 17(4): 44, 1997.
A. Haake, Under CoVer: the implementation of a
contextual version server for hypertext applications, in: European
Conference on Hypertext Technology (ECHT '94), September, 1994,
Edinburgh, Scotland, pp. 81–93.
WWW distributed authoring and versioning (WebDAV)
charter, Internet Engineering Task Force, January 1998,
http://ietf.org/html.charters/webdav-charter.html (February 10,
1998).
F. Vitali and D. G. Durand, Using versioning to
provide collaboration on the WWW,
in: Proc. 4th International World Wide Web Conference, Boston, MA, December,
1995, World Wide Web Journal, pp. 37–50,
http://www.w3.org/WWW4/Papers/190 (February 10, 1998).
J. Whitehead, Versioning and configuration management
of World Wide Web content, February 1997,
http://www.ics.uci.edu/~ejw/versioning (February 10, 1998).
R. Pettengill and G. Arango, Four lessons learned from
managing World Wide Web digital libraries, in: The Second Annual
Conference on the Theory and Practice of Digital Libraries,
Austin, TX, June, 1995,
http://csdl.tamu.edu/DL95/papers/pettengill/pettengill.html
(February 10, 1998).
Apache HTTP server project, Apache Group,
http://www.apache.org (February 10,
1998).
R. Braden, (Ed.), Requirement for Internet hosts:
application and support, Request for Comments (RFC) 1123, Internet
Engineering Task Force, October 1989,
ftp://NIS.NSF.NET/internet/documents/rfc/rfc1123.txt (February 10,
1998).
B. Laurie and P. Laurie, Apache: The Definitive
Guide, O'Reilly and Associates, Inc., Sebastopol, CA, 1997.
Vitae
 Jonathan Simonson is an Assistant Professor in the
Department of Computer Systems Engineering at the University of
Arkansas, Fayetteville. His research interests include
computer architecture, real-time systems, multiprocessor design, memory
system management and design, compilers, and the World Wide Web.
Jonathan Simonson is an Assistant Professor in the
Department of Computer Systems Engineering at the University of
Arkansas, Fayetteville. His research interests include
computer architecture, real-time systems, multiprocessor design, memory
system management and design, compilers, and the World Wide Web.
 Daniel Berleant is an Associate Professor at the University of
Arkansas, Fayetteville. He publishes in the areas of information
customization, text processing, qualitative and numerical simulations,
interval mathematics, and computer assisted language learning. His
teaching activities include a course on the future of computing. He
received the Ph.D. and M.S. degrees in computer science from the
University of Texas at Austin in 1991 and 1990, respectively, and the
B.S. degree in computer science and engineering from the Massachusetts
Institute of Technology in 1982.
Daniel Berleant is an Associate Professor at the University of
Arkansas, Fayetteville. He publishes in the areas of information
customization, text processing, qualitative and numerical simulations,
interval mathematics, and computer assisted language learning. His
teaching activities include a course on the future of computing. He
received the Ph.D. and M.S. degrees in computer science from the
University of Texas at Austin in 1991 and 1990, respectively, and the
B.S. degree in computer science and engineering from the Massachusetts
Institute of Technology in 1982.
 Xiaoxiang Zhang is receiving the M.S. degree in
computer systems engineering at the University of Arkansas, Fayetteville
in Spring 1998, and received the B.S. degree in electronics engineering
from Tsinghua University, Beijing in 1996. His primary area of
interest is Internet programming.
Xiaoxiang Zhang is receiving the M.S. degree in
computer systems engineering at the University of Arkansas, Fayetteville
in Spring 1998, and received the B.S. degree in electronics engineering
from Tsinghua University, Beijing in 1996. His primary area of
interest is Internet programming.

