|
|
|
|
|
|
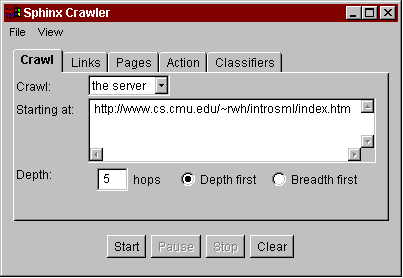
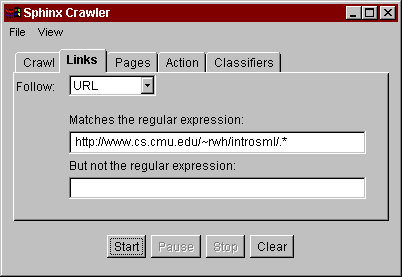
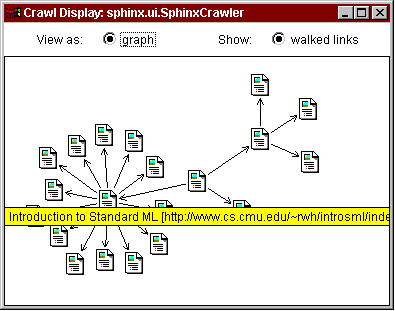
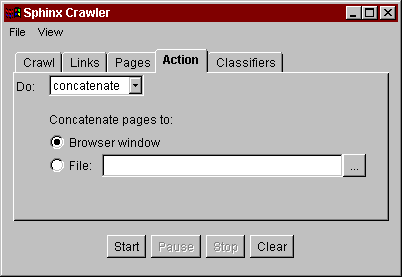
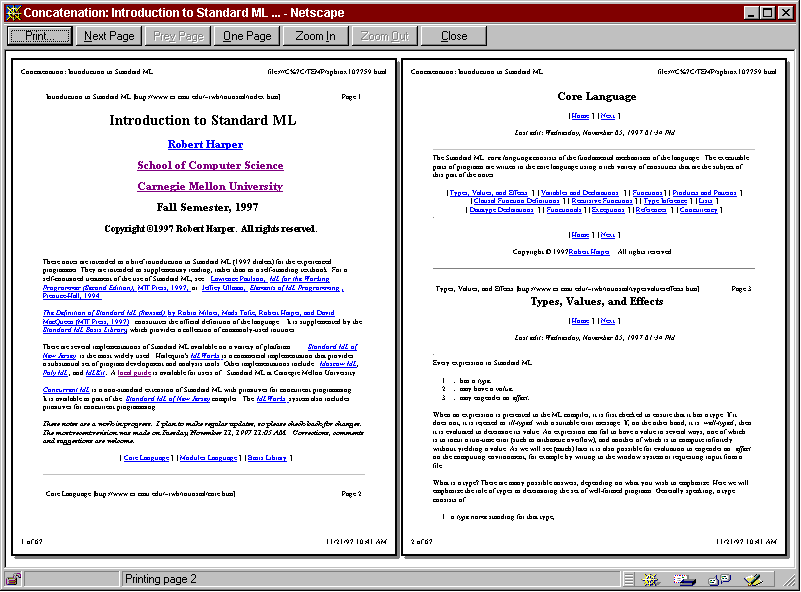
Fig. 1. Using the Crawler Workbench to linearize a document graph for printing.
aSchool for Computer Science,
Carnegie Mellon University
5000 Forbes Ave,
Pittsburgh, PA 15208, U.S.A.
rcm@cs.cmu.edu
bDigital Systems Research Center
130 Lytton Ave,
Palo Alto, CA 94301, U.S.A.
bharat@pa.dec.com
State-of-the-art Web crawlers are generally hand-coded programs in Perl, C/C++, or Java. They typically require the use of a network access library to retrieve Web pages, and some form of pattern matching to find links within pages and process textual content. With these techniques, even simple crawlers take serious work. Consider the following example: as a first step in creating a "photo album" of pictures of all the researchers at your institution, you might want the agent to crawl over the institution's list of home pages and collect all the images found. Unless your institution is enormous, coding this one-shot crawler in C or Perl could easily take longer than visiting each page in a browser and saving the images manually. For a novice programmer, writing a full crawler requires a substantial learning curve.
The picture-collection task is an example of a personal crawl. This is a task of interest to perhaps a single user, who may want to perform the operation only a small number of times. In other application domains, personal automation is often handled by macros or embedded scripting languages, but such facilities are not commonly available for the Web crawling domain.
Site-specific crawlers are also ill-supported by current crawler development techniques. A site-specific crawler is tailored to the syntax of the particular Web sites it crawls (presentation style, linking, and URL naming schemes). Examples of site-specific crawlers include metasearch engines [Selberg95], homepage finders [Shakes97], robots for personalized news retrieval [Kamba95], and comparison-shopping robots [Etzioni97]. Site-specific crawlers are created by trial-and-error. The programmer needs to develop rules and patterns for navigating within the site and parsing local documents by a process of "reverse engineering". No good model exists for modular construction of site-specific crawlers from reusable components, so site-specific rules engineered for one crawler are difficult to transfer to another crawler. This causes users building crawlers for a site to repeat the work of others.
A third area with room for improvement in present techniques is relocatability. A relocatable crawler is capable of executing on a remote host on the network. Existing Web crawlers tend to be nonrelocatable, pulling all the pages back to their home site before they process them. This may be inefficient and wasteful of network bandwidth, since crawlers often tend to look at more pages than they actually need. Further, this strategy may not work in some cases because of access restrictions at the source site. For example, when a crawler resides on a server [Maarek97] outside a company's firewall, then it cannot be used to crawl the Web inside the firewall, even if the user invoking it has permission to do so. Users often have a home computer connected by a slow phone line to a fast Internet Service Provider (ISP) who may in turn communicate with fast Web servers. The bottleneck in this communication is the user's link to the ISP. In such cases the best location for a user-specific crawler is the ISP or, in the case of site-specific crawlers, the Web site itself. On-site execution provides the crawler with high-bandwidth access to the data, and permits the site to do effective billing, access restriction, and load control.
This paper describes SPHINX (Site-oriented Processors for HTML INformation eXtraction), a Java-based toolkit and interactive development environment for Web crawlers. SPHINX explicitly supports crawlers that are site-specific, personal, and relocatable. The toolkit provides a novel application framework which supports multithreaded page retrieval and crawl visualization and introduces the notion of classifiers, which are reusable site-specific content analyzers. The interactive development environment, called the Crawler Workbench, is implemented as a Java applet. The Workbench allows users to specify and invoke simple personal crawlers without programming, and supports interactive development and debugging of site-specific crawlers. The SPHINX toolkit also provides library support for crawling in Java, including HTML parsing, pattern matching, and common Web page transformations.
This section describes the model of Web traversal adopted by the SPHINX crawling toolkit, and the basic Java classes that implement the model. The Java interface is used by a programmer writing a crawler directly in Java. Users of the Crawler Workbench need not learn it, unless they want to extend the capabilities of the Workbench with custom-programmed code.
SPHINX regards the Web as a directed graph of pages and links, which are reflected in Java as Page and Link objects. A Page object represents a parsed Web page, with methods to retrieve the page's URL, title, and HTML parse tree. Also among the attributes of Page is a collection of Link objects representing the outgoing hyperlinks found on the page. A Link object describes not only the target of the link (a URL), but also the source (a page and an HTML element within that page). Each Link and Page object also stores a set of arbitrary string-valued attributes, which are used by classifiers for labelling (discussed in the next section).
To write a crawler in SPHINX, the programmer extends the Crawler class by overriding two callback methods:
Here is an example of a simple crawler. This crawler only follows links whose URL matches a certain pattern, where pattern-matching is handled by the abstract Pattern class. Several subclasses of Pattern are provided with SPHINX, including Wildcard (Unix shell-style wildcard matching, used in the example below), Regexp (Perl 5-style regular expressions), and Tagexp (regular expressions over the alphabet of HTML tags).
class FacultyListCrawler extends Crawler {
// This simple crawler visits a certain university department
// and lists home-page URLs of the academic faculty. All the
// homepage URLs are assumed to obey the following pattern:
static Pattern facultyHomePage =
new Wildcard ("http://www.cs.someplace.edu/Faculty/*/home.html");
boolean shouldVisit (Link link) {
return facultyHomePage.match( link.getURL().toString() );
// match() returns true if the link's URL matches
// the facultyHomePage pattern
}
void visit (Page page) {
System.out.println ( page.getURL () );
// getURL() returns the URL that the page represents
}
}
The implementation of Crawler uses multiple threads to retrieve pages and links, and passes them to the callback methods according to the following scheme. The crawler contains a queue of "ready" links, which have been approved by shouldVisit but not yet retrieved. In each iteration, a crawling thread takes a link from this queue, downloads the page to which it points, and passes the page to visit for user-defined processing. Then the thread iterates through the collection of links on the page, calling shouldVisit on each link. Links approved by shouldVisit are put in the queue, and the thread returns to the queue for another link to download.
The ready queue is initialized with a set of links, called the starting points or roots of the crawl. The crawler continues retrieving pages until its queue is empty, unless the programmer cancels it by calling abort()or the crawl exceeds some predefined limit (such as number of pages visited, number of bytes retrieved, or total wall-clock time).
Since the links of the Web form a directed graph, one can usefully regard the SPHINX crawling model from the standpoint of graph traversal. Breadth-first and depth-first traversal are simulated by different policies on the ready queue: first-in-first-out for breadth-first, last-in-first-out for depth-first. In our implementation, the ready queue is actually a priority queue, so shouldVisit can define an arbitrary traversal strategy by attaching priority values to links. This facility could, for example, be used to implement a heuristically-guided search through the Web.
A traversal of the Web runs the risk of falling into a cycle and becoming trapped. This is especially true in cases where pages are dynamically created. SPHINX does simple cycle avoidance by ignoring links whose URL has already been visited. More insidious cycles can be broken by setting a depth limit on the traversal, so that pages at a certain (user-specified) depth from the root set are arbitrarily treated as leaves with no links. A better solution would be to use a classifier that detects if a "similar" page has been seen before to avoid visiting the same sort of page twice. A page resemblance technique such as [Broder97] can be used for this purpose.
Like other crawling toolkits, SPHINX also supports the informal standard for robot exclusion [Koster94], which allows a Web site administrator to indicate portions of the site that should not be visited by robots.
A site-specific crawler typically contains a number of rules for interpreting the Web site for which it is designed. Rules help the crawler choose which links on the site to follow (say, articles) and which to avoid (say, pictures), and which pages or parts of pages to process (body text) and which to ignore (decoration). SPHINX provides a facility for encapsulating this sort of knowledge in reusable objects called classifiers. A classifier is a helper object attached to a crawler which annotates pages and links with useful information. For example, a homepage classifier might use some heuristics to determine if a retrieved page is a personal homepage, and if so, set the homepage attribute on the page. (SPHINX's Link and Page objects allow arbitrary string-valued attributes to be set programmatically.) A crawler's visit method might use this attribute to decide how to process the page — for instance, if the homepage attribute is set, the crawler might look for an image of the person's face.
The programmer writes a classifier by implementing the Classifier interface, which has one method: classify(Page p), which takes a retrieved page and annotates it with attributes. Attributes may be set on the page itself, on regions of the page (represented as a byte offset and length in the page), and on outgoing links. A classifier is used by registering it with a crawler; the main loop of the crawler takes care of passing retrieved pages to every registered classifier before submitting them to shouldVisit and visit.
We have written a number of classifiers. The StandardClassifier, which is registered by default with all crawlers, deduces simple link relationships by comparing the link's source and target URLs. (For example, a link from http://www.yahoo.com/ to http://www.yahoo.com/Arts/ is labeled as a descendent link, because the source URL is a prefix of the target URL.) Another useful classifier is CategoryClassifier, which scores a page according to its similarity to various categories in some category hierarchy, such as Yahoo! [Yahoo97]. A category is represented by a collection of documents (e.g., documents in the Yahoo! category Sports:Baseball). The match between a page and a category is computed using a Vector Space document/collection similarity metric, commonly used in Information Retrieval [Salton88].
Classifiers are especially useful for encapsulating Web-site-specific knowledge in a modular way. This allows them to be interchanged when appropriate, and reused in different crawlers. For instance, we have a classifier for the AltaVista search engine, which detects and parses AltaVista query result pages. This classifier is used in several of our example applications that use a search engine to start the crawl (see Section 4). When AltaVista released a new page design during the summer of 1997, it was sufficient to fix the AltaVista classifier — no changes were needed to the crawlers that use it. We were also able to experiment with other search engines, such as HotBot, simply by writing a HotBot classifier that sets the same attributes as the AltaVista classifier. Thus the classifier mechanism makes it straightforward to build extensible meta-services, such as metasearch engines, in SPHINX.
SPHINX has a graphical user interface called the Crawler Workbench that supports developing, running, and visualizing crawlers in a Web browser. A number of commonly-used shouldVisit and visit operations are built into the Workbench, enabling the user to specify and run simple crawls without programming. The Workbench can run any SPHINX crawler, as long as it inherits from the basic Crawler class.
The Workbench includes a customizable crawler with a selection of predefined shouldVisit and visit operations for the user to choose from. For more customized operations, the Workbench allows a programmer to write Javascript code for shouldVisit and visit (if the Web browser supports it), manipulating Pages and Links as Java objects.
The built-in shouldVisit predicates test whether a link should be followed, based on the link's URL, anchor, or attributes attached to it by a classifier. The built-in visit operations include, among others:
Each of the visit operations can be parameterized by a page predicate. This predicate is used to determine whether a visited page should actually be processed. It can be based on the page's title, URL, content, or attributes attached to it by a classifier. The page predicate is needed for two reasons: first, shouldVisit cannot always tell from the link alone whether a page will be interesting, and in such cases the crawler may actually need to fetch the page and let the page predicate decide whether to process it. Second, it may be necessary to crawl through uninteresting pages to reach interesting ones, and so shouldVisit may need to be more general than the processing criterion.
An example of using the customizable crawler for a personal crawling task is shown in Fig. 1. The task is to print a hardcopy of Robert Harper's Introduction to Standard ML, a Web document divided into multiple HTML pages. In the Crawler Workbench, the user enters the first page of the document as the starting URL and sets some gross limits, constraining the crawler to a single Web server and pages at most 5 hops away from the starting URL (Fig. 1a). Unfortunately these limits are not sufficient, because the document contains links to pages outside the document (such as Standard ML at Carnegie Mellon) which we don't want to print. A little investigation indicates that all the relevant pages have the prefix "http://www.cs.cmu.edu/~rwh/introsml/", so the user specifies this constraint as a regular expression on URLs that the crawler may follow (1b). Running the crawler produces a graph visualization of the Web pages visited (1c), which the user can browse to check that the appropriate pages are being retrieved. This appears to be the case, so (1d) the user specifies that the crawler should now concatenate the visited pages together to make a single page that can be printed (1e). This example shows how the Crawler Workbench provides a visual, interactive, iterative development environment for Web crawling.
|
|
|
|
|
|
Fig. 1. Using the Crawler Workbench to linearize a document graph for printing.
When combined with a library of classifiers (which can be dynamically loaded into the Workbench), the customizable crawler enables some interesting crawls that would otherwise require programming. Let us suppose, for example, that the user wants to save all the pages found by an AltaVista query for off-line viewing or processing. Using the Crawler Workbench with the AltaVista classifier, the user can interactively specify a crawler that follows links labeled result (which point to pages that matched the query) or more-results (which point to more pages of query results), but not links to AltaVista's help documentation or advertisers. This kind of crawl would be difficult to specify in other site-download tools [BlueSquirrel97], which lack the ability to make semantic distinctions among links.
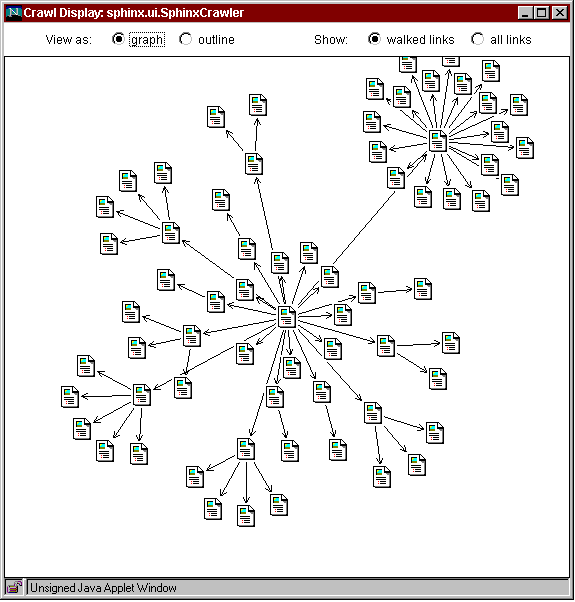
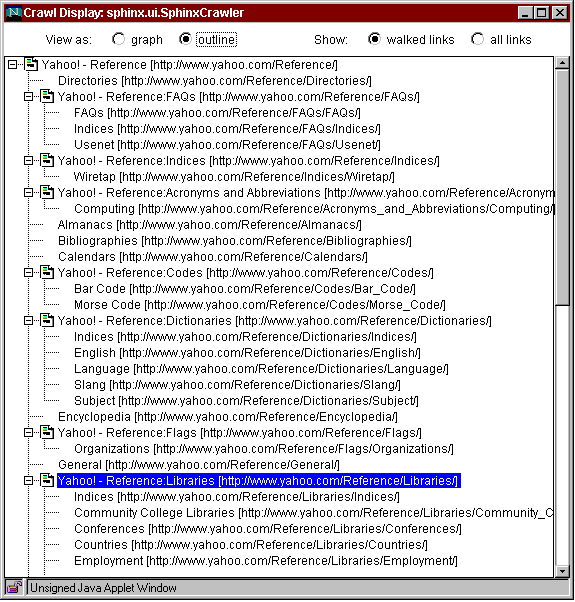
While a crawler is running, the Workbench dynamically displays the growing crawl graph, which consists of the pages and links the crawler has encountered. Two visualizations of the crawl graph are available in our prototype (Fig. 2). First is a graph view (Fig. 2a), which renders pages as nodes and links as directed edges, positioned automatically by a dynamic polynomial-approximation layout algorithm [Tunkelang97]. Nodes are displayed concisely, as icons. To get more information about a node, the user can position the mouse over an icon, and the page title and URL will appear in a popup "tip" window. The user can also drag nodes around with the mouse to improve the layout, if desired. The second visualization is an outline view (Fig. 2b), which is a hierarchical list of the pages visited by the crawler. A page can be expanded or collapsed to show or hide its descendents. Both views are linked to the Web browser, so that double-clicking a page displays it in the browser. The availability of dynamic, synchronized views of the crawl proves to be very valuable as the user explores a site and builds a custom crawler for it.
|
|
Fig. 2. A Web crawl visualized as (a) a graph, and (b) an outline.
The visualizations are connected to the crawler by event broadcast. When some interesting event occurs in the crawl — such as following a link or retrieving a page — the crawler sends an event to all registered visualizations, which update their displays accordingly. The visualizations also have direct access to the crawl graph, represented internally as a linked collection of Page and Link objects. This architecture enables visualizations and crawlers to be developed independently. Furthermore, since the Crawler implementation takes care of broadcasting events at appropriate times, the visualizations in the Workbench can be connected to any SPHINX crawler, as long as it inherits from Crawler.
Our graph visualization allows the programmer to create mappings between attributes of the Page object and presentation attributes such as colour, label, node size, and icon shape. There is much room for improvement. Data visualization techniques such as fisheye views [Furnas86], overview diagrams [Mukherjea95], cone trees [Robertson91], and hyperbolic trees [Lamping95], might greatly enhance our crawl display.
Some interesting crawlers written with the SPHINX toolkit are briefly described below.
The precision of search engine queries often suffers from the polysemy problem: query words with multiple meanings introduce spurious matches. This problem gets worse if there exists a bias on the Web towards certain interpretations of a word. For example, querying AltaVista for the term "amoeba" turns up far more references to the Amoeba distributed operating system than to the unicellular organism, at least among the first 50 results.
One way to avoid the polysemy problem is to allow the user to indicate a general-purpose category, such as Biology, to define the context of the query. This category is used to re-rank the results of a search engine query. We use the CategoryClassifier (described previously) to compute the page's similarity to a collection of pages considered representative of the category. In our implementation, we used page collections defined by Yahoo! to build up our predefined categories.
The category-ranking application shown in Fig. 3 is implemented as a SPHINX crawler that submits the user's query to a search engine and retrieves some number of results (usually 50, which corresponds to 5 result pages). For a fast approximation to the category ranking, the crawler first computes the category similarity of each page's brief description returned by the search engine. This allows a preliminary ranking of the results to be shown to the user immediately. Meanwhile, the crawler retrieves the full pages in the background, in order to compute the category scores more accurately. Pages are retrieved in rank order based on score computed during the initial ranking. Here SPHINX's priority-driven crawling scheme is exploited.
Note that category-ranking is not in any way restricted to search queries. The pages encountered in any crawl can be scored using the CategoryClassifier and presented to the user in decreasing order of predicted usefulness.
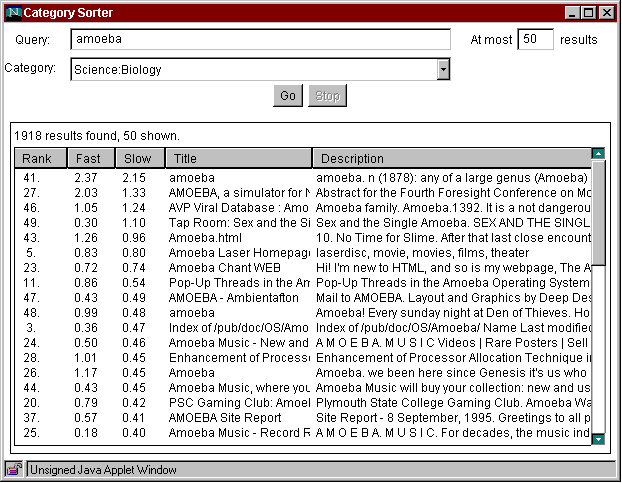
Fig. 3. Results of an AltaVista query, ordered by similarity to Biology. "Rank" shows AltaVista's original ranking (where the first result returned has rank 1). "Fast" shows the category-similarity score of the brief description. "Slow" shows the score of the full page. The three pages with the highest "Slow" scores are relevant to the unicellular organism, despite appearing rather late in AltaVista's ranking.
A matter of concern to the speech recognition community is how to deal with a "non-stationary" source: a source of words whose probability distribution changes over time. For example, consider a news broadcast. One minute, the broadcaster is reading a story on Iraq, in which the words "U.N.", "Albright", "ambassador", and "weapons" have higher probability of occurrence than in general. The next minute, the topic has shifted to the Iditarod dog sled race in Alaska, in which the words "snow", "cold", and "mush" are more probable than usual. Speech recognition systems which have been trained on a fixed corpus of text have difficulty adapting to topic changes, and have no hope of comprehending completely new topics that were missing from the training corpus.
A novel solution to this problem (described in [Berger98]) is just-in-time language modelling. A just-in-time language modelling scheme uses recent utterances to the speech recognition system to query a text database, and then retrains its language model using relevant text from the database. The prototype system actually uses the World Wide Web as its text database. A small SPHINX crawler submits the last utterance as a search engine query (with common words removed), then retrieves pages in order of relevance until enough words have been accumulated to retrain the language model.
In the course of developing this crawler, we experimented with several different search engines, in order to find the right balance of speed, precision, and recall needed to generate good training text. Since all search engine dependencies are encapsulated in SPHINX classifiers, it was straightforward to retarget the crawler to AltaVista, HotBot, and finally News Index, which proved best for the broadcast news domain.
This section describes features of the SPHINX crawling architecture that contribute to developing relocatable crawlers. Relocatable crawlers are capable of executing on a remote host on the network. We present some scenarios in which relocatable crawling is useful and discuss the issues involved in supporting them in SPHINX. Support for relocation is currently being added to the toolkit, so this discussion should be regarded as work-in-progress.
Relocation serves a variety of purposes, highlighted in the following scenarios.
Scenario #1: the crawler is downloaded to a Web browser. Consider a downloaded Java applet that does some crawling as part of its operation. WebCutter/Mappuccino [Maarek97], for example, is an applet that generates Web visualizations.Scenario #2: the crawler is uploaded to a "crawling server". When the user has a slow computer or a low-bandwidth connection, it may be desirable to upload a crawler to some other host with better speed or faster network links.
Scenario #3: the crawler is uploaded to the target Web server. For a site-specific crawler, the best possible bandwidth and latency can be obtained by executing on the Web server itself.
Much of the infrastructure for relocation is already implemented in Java, such as secure platform-independent execution, code shipping, object serialization, and remote method invocation. Two issues remain to be addressed by SPHINX: the network access policy for an untrusted crawler, and the user interface to a remote crawler. We consider each of these issues in turn.
In all three scenarios, the crawler may be untrusted by its execution host (the browser or server). We assume that the execution host has a local, trusted copy of the SPHINX toolkit. Since SPHINX handles network access for the untrusted crawler, it can filter the crawler's page requests according to an arbitrary, host-defined policy. For example, the page-request policy for Scenario #3 might restrict the crawler to pages on the local Web server, forbidding remote page requests. Other uses for the page-request policy include URL remapping (e.g., converting http: URLs into corresponding file: URLs on the Web server's local filesystem), load control (e.g., blocking the crawler's requests until the load on the Web server is light), resource limits, auditing, or billing. The page-request policy is implemented as a Java class registered by the execution host.
Turning to the second issue, a crawler uploaded to a remote server must have some means of communicating results back to the user. First, any events generated by the crawler are automatically redirected back to the user's Crawler Workbench to visualize the remote crawl. The remote crawler can also create HTML output pages and direct SPHINX to send them back to the Workbench for display. The user may choose to disconnect from a long-running crawl and return at a later point, in which case the crawling events and HTML pages are batched by the remote server and delivered at the user's request.
Relocatable crawlers combine local, interactive development with run-time efficiency. A crawler can be developed and debugged locally in the Crawler Workbench, and then shipped to a remote server, where it can run at maximum speed.
Most actual crawlers are written in languages such as Perl, Tcl, or C, using libraries such as the W3C Reference Library [Frystyk94] or libwww-perl [Fielding96]. These libraries typically do not provide an interactive development environment. Several interactive systems allow the user to specify a crawl and visualize the results, such as MacroBot [IPG97] and WebCutter/Mapuccino [Maarek97]. The TkWWW Robot [Spetka94] was the first system to integrate crawling into a Web browser.
Several authors have considered issues of mobile agents on the Web. Mobility is related to our notion of relocation, except that mobile agents are usually capable of migrating from host to host during execution. Lingnau et al [Lingnau95] described using HTTP to transport and communicate with mobile agents. Duda [Duda96] defined the Mobile Assistant Programming (MAP) model, a set of primitives for mobility, persistence, and fault-tolerance, and implemented a mobile agent in Scheme that moves to a remote server to search a collection of Web documents.
The SPHINX toolkit and Crawler Workbench are designed to support crawlers that are Web-site-specific, personal, and relocatable. In the SPHINX architecture, crawlers leverage off classifiers, which encapsulate Web-site-specific knowledge in a reusable form. The Crawler Workbench is the first general-purpose crawling tool that runs as a Java applet inside a Web browser. The Workbench provides the user with an opportunity to customize the crawler, and also several visualizations to gauge the effectiveness of the crawler and improve it iteratively. Relocatable crawlers can be developed and debugged locally in the Workbench, then uploaded and run on a remote server at full speed.
Running the Crawler Workbench inside a browser provides a fair level of integration between browsing and crawling, so that crawling tasks that arise during browsing can be solved immediately without changing context. Tighter integration between browsing and crawling would be desirable, however. For example, the user should be able to steer a running crawler by clicking on links in a browser window. Current browsers provide no way for a Java applet to obtain these kinds of events.
A prototype of SPHINX has been implemented, using Java version 1.0.2 and Netscape Communicator 4.0. Work is currently underway to prepare a version of SPHINX for public release, which is anticipated sometime in mid-1998. The public version will support relocatable crawlers and a wider variety of browsers. For more information, see the SPHINX home page at http://www.cs.cmu.edu/~rcm/websphinx/.
The authors heartily thank Daniel Tunkelang for his polynomial-approximated graph drawing algorithm and its Java implementation. Thanks also to Brad Myers, Eric Tilton, Steve Glassman, and Monika Henzinger for suggestions for improving this paper. This work was done during the first author's 1997 summer internship at DEC Systems Research Center.