Effective personalization of push-type systems
— visualizing information freshness
Hidekazu Sakagami,
Tomonari Kamba,
Atsushi Sugiura, and
Yoshiyuki Koseki
C&C; Media Research Laboratories, NEC Corporation,
4-1-1 Miyazaki, Miyamae-ku, Kawasaki, Kanagawa 216 Japan
sakagami@ccm.cl.nec.co.jp,
kamba@ccm.cl.nec.co.jp,
sugiura@ccm.cl.nec.co.jp, and
koseki@ccm.cl.nec.co.jp
- Abstract
-
This paper discusses an effective personalization method,
especially on push-type systems.
Many conventional personalization systems rely strictly on personal
interests during information presentation,
but the "freshness" of information is often as
important as the relation to personal preferences.
For example, a user who accesses a WWW newspaper several times a day,
expects to see fresh articles displayed in prominent positions rather than
"hidden" among articles that may be more relevant but that have already
been read.
This paper therefore presents a novel personalization method incorporating
"information freshness" and that is extremely useful for the ever-growing
number of push-type systems.
Information freshness is indicated by using a perspective representation
which shows virtual depth on the screen: fresh articles seem "closer"
to the user,
while old articles seem farther away.
This representation allows us to simultaneously display both
the personal relevance and the freshness of the information.
We have successfully implemented two applications using this technique:
a personalized newspaper service and an easy-to-use scrapbook for Web pages.
- Keywords
-
Personalization; Information freshness; Perspective visualization;
Push-type systems; World Wide Web
1. Introduction
The rapid growth of the World Wide Web (WWW) has made it possible
for a large amount of information resources on the Internet
to be accessed easily,
but it is becoming more and more difficult
to pick the pieces that are really useful or important from this
sea of information.
Helping people to get relevant information easily is an important goal
of Internet technology, and we are approaching this goal from two directions
that are closely related to each other:
push-type information delivery, and information personalization.
Push-type delivery reduces the amount of physical and/or mental work
required for accessing information.
Once the user registers which information
resources (sometimes called "channels") the user wants to subscribe to,
the system automatically delivers new items of information and stores
them on the user's computer.
This kind of delivery was originally used for a news delivery service
by PointCast Network [II]
and has since been applied to the delivery of WWW pages
in popular browsers such as the Microsoft Internet Explorer and
the Netscape Navigator.
This delivery technique has also been used for delivering
application programs, as in Marimba Castanet [III].
One limitation of the push-type delivery technique, however,
is that continually increasing the number of channels will result in
a situation similar to that recently resulting from the explosive growth of
Web pages.
That is, it will become extremely difficult for the user to choose which
channels to subscribe to and which pieces of delivered information to read.
Personalization technology helps the user get
useful information easily.
On most personalized WWW pages, the selection of information
is customized according to each user's preference or interest.
The personalized Internet newspaper that we have developed [1,2] is
one of the systems using automatic personalization.
It creates personalized newspaper pages for each user on the fly
using a user profile to evaluate the user's expected interest
in each article.
(The learning engine and the scoring engine used in this evaluation
process were developed by Nakamura et al. [3])
Since personally important articles are located in a prominent
position (upper left-hand corner) and take up more space than
unimportant articles, the user can find them easily.
The user profile is created automatically and is automatically updated
according to the user's operations on the newspaper pages.
This system, originally called ANATAGONOMY,
is already in practical use in Japan,
where it is called Yomiuri-COLiNS (Customized OnLine News Service) [I].
Every day it provides each user 100-150 articles from the Yomiuri Shimbun,
the most popular daily newspaper in Japan.
More than 20,000 users have registered with this service since it
was opened to the public a year ago,
and about 1,000 people access the site on a daily basis.
We planned to get the advantages of both push-type delivery and
personalization by developing a personalized push-type system.
That is, the information would be filtered using our
personalization technology and would then be delivered automatically
using the push mechanism.
Through our personalized newspaper service, however,
we found that our personalization technique was not sufficient.
When creating the personalized newspaper pages, we had considered only
each user's preference, but a lot of users said that the articles
they actually wanted to read were not always the ones that
matched their interest.
They usually accessed our newspaper site several times a day
to see if any new articles had arrived,
and they were often more interested in knowing which articles were
new rather than which ones matched their preferences.
We therefore decided that our personalized push-type system
should consider "information freshness" in addition to personal preference.
In the following sections we will describe how we visualized two factors
— information freshness and personal preference — at the same time,
will present two push-type applications that use our visualization
technique, and will discuss the effectiveness of our technique
in helping people get useful information from the WWW easily and efficiently.
2. Visualization of information freshness
This section explains how information freshness is visualized
in conventional pull-type systems and
how it is visualized in our push-type system.
2.1. Information freshness in pull-type systems
Some WWW pages have a "What's New" section in the most prominent position,
and most online newspaper pages have "Dispatches" or "Latest News" sections.
And on some WWW pages a "New" mark is attached when a newly registered
information piece is presented.
The mark remains attached for certain time although the duration
depends on the characteristics of the information.
These simple and useful methods have two limitations.
One is that it is difficult to show the degree of freshness
with these simple marks: some information pieces of featuring "New" marks
have just been registered while others
have been registered a week ago.
Many different marks could be used to show the freshness
of each piece of information more accurately,
but the user would then have to evaluate freshness by distinguishing
the many marks.
The second limitation in these methods is that the personal freshness
of information is not considered.
For example, a news article registered on the server five minutes ago
will be presented with a "New" mark,
even if the user has already read it two minutes ago.
From the user's point of view,
an unread article that was registered an hour ago is often more
important than an article that was registered only two minutes ago
but has already been read.
Information freshness should thus depend on each user's
operation history.
Our personalized newspaper Yomiuri-COLiNS solves this second problem
by attaching "New" marks only to articles
that have been registered on the server since the user's previous access
(Fig. 1).
This technique is useful but does not solve the first problem.
That is, it does not show the degree of freshness.
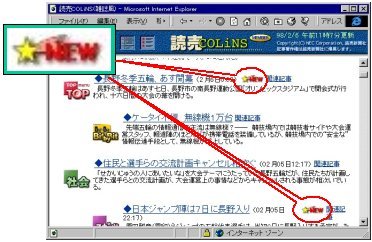
Fig. 1. "New" marks in Yomiuri-COLiNS.
The first problem can be solved by sorting the information pieces
according to their freshness.
On some WWW newspaper pages, for example, new articles are displayed
at the top of their article lists.
This method is effective but unfortunately cannot be easily applied
in a personalized system,
since these articles are often sorted and displayed according to
personal preference.
2.2. Information freshness in push-type systems
The presentation of push-type systems is different
from that of pull-type systems.
That is, it is often required to show as much information as possible
with few operations by the user.
One of the common presentation styles of push-type systems
is a screen saver.
The information shown on the screen saver automatically moves,
and user can see most of the information without performing any operations.
We present the information freshness in perspective because
the virtual depth of the screen is not used yet in most systems
and can therefore be used to present a new feature.
In addition, the depth can be used to show the relative freshness easily
since it is continuous.
Because a computer display is two-dimensional,
it is difficult to present information in perspective.
In the painting and the drawing, the following perceptual depth cues
are often used to show perspective [4].
- Interposition
- Partial blocking of a more distant object by a nearer object.
When one object partially obscures another,
the blocked object is perceived to be behind the
blocking object.
- Relative size
- The larger of two otherwise identical objects appears to be
closer than the smaller one.
- Aerial perspective (contrast, clarity, and brightness)
- Sharper and more distinct objects appear to be nearer,
and duller objects appear to be further away.
- Shadow
- Shadows cast by an object provide cues to the relative
position of objects.
- Texture gradient
- Most surfaces — such as those of walls and roads and fields —
have a texture. And the texture of a surface farther away from
us gets finer and appears smoother [5].
Of these depth cues,
we use size and brightness to represent the perspective
because they are easy to implement.
In addition, since the displayed information on our push-type system
will move on the screen automatically,
we will also use the motion parallax technique.
That is, we will take advantage of objects farther away appearing to
move more slowly than objects that are closer.
The size of an object size on the screen is calculated
on the basis of a perspective projection like that shown in Fig. 2.
Object brightness and speed are also defined by a simple
linear calculation:
as the distance between the object and the viewpoint increases,
both the brightness and the motion speed of the object decrease linearly.
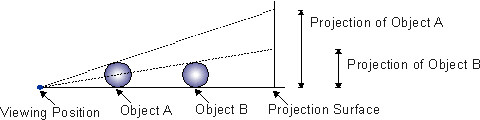
Fig. 2. Use of perspective.
3. ANATAGONOMY/SS: a personalized push-type system delivering
news articles
3.1. System overview
The server side modules of a push-type system using technique for visualizing the freshness of the news articles it delivers are based on the pull-type personalized newspaper described in the first section, Yomiuri-COLiNS.
As a first example of personalized push-type systems using technique for
visualizing the information freshness,
we have developed a news article delivery system called ANATAGONOMY/SS.
Its server-side modules are based on the pull-type personalized
newspaper described in the first section, Yomiuri-COLiNS.
We chose a news article delivery system as our first
implementation for the following reasons:
- Many articles are delivered irregularly but repeatedly.
In addition, freshness is important for news articles.
- Personalization is useful because articles have various topics.
- People are used to push-type delivery of newspapers
(i.e., delivery of the morning paper to your doorstop),
whereas they use pull-type mechanisms for getting other kinds of
information (e.g., going to a bookstore).
Here is a list of basic features of our system, which is called ANATAGONOMY/SS.
- It is a push-type system.
That is, news articles are automatically delivered
to each user's computers according to a predefined schedule.
- It provides automatic personalization.
That is, the screen display of the news articles is customized
for each user.
User operations on the articles are sent back to the server
and are reflected in the user's profile.
- Its presentation reflects information freshness as well as
user preferences.
3.2. System architecture
The system has a client-server architecture (Fig. 3).
The client-side program fetches news articles from the server
according to a predefined schedule and presents them on the screen.
Personalization is done on the server side,
and some presentation parameters are given to the client-side program.
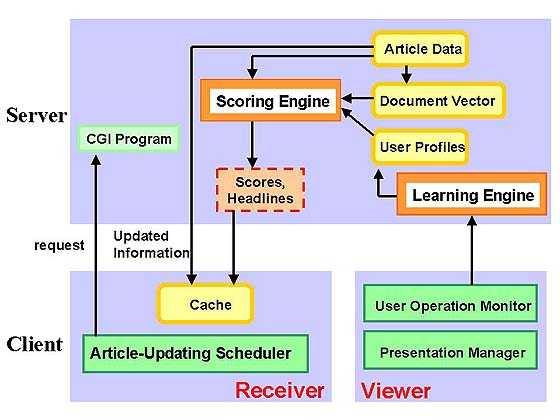
Fig. 3. System architecture of ANATAGONOMY/SS.
3.2.1. Relevance calculation and information delivery
The server side has a scoring engine and a learning engine,
and it stores user profiles and document vectors.
The document vector of each article is a set of words extracted from
that article, although common words and stop words are omitted.
The user profile is a set of words and weights.
When a user is interested in topics related to certain words,
the weights of those words will be high.
The scoring engine anticipates each article's personal importance
by comparing the article's document vector and the user profile.
Roughly speaking, articles that include many highly weighted words
get high scores.
The learning engine builds and modifies a user profile according to the
user's behaviors.
Roughly speaking, when a user does such operations as scrolling and
choosing on an article,
the system regards that the user is interested in the article and modifies
the user profile so that it reflects the user's interest more precisely.
The client side has two program modules, a receiver and a viewer.
The receiver is in charge of information delivery and the viewer
is in charge of presentation.
The receiver module first sends an article updating request
to a Common Gateway Interface (CGI) program on the server
according to the predefined schedule.
Then the headlines of all the articles on the server and
their anticipated scores are sent to the client
and stored in the cache.
If the receiver finds article headlines that it gets for the first
time, it requests the article bodies from the server
and stores them on the client.
This mechanism is usually called push-style,
although in a technical sense, it is an automatic pull or scheduled pull.
3.2.2. Information presentation and user preference extraction
The viewer program is in charge of presenting the information and
monitoring user behavior.
Presentation decisions are based on the anticipated article scores
and the information freshness, which itself is based not only on its
dispatch time but also on whether or not it has already been read
by the user.
Information freshness F is defined by the following equation,
where Tc is the current time, Td is the dispatch time,
and a(alpha)
is a coefficient that is 0.5 or 1.0 depending on whether or not
the user has already read the article.
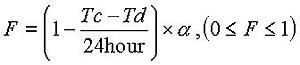
The article freshness (F) is 1.0 when it has just been
dispatched,
and it decrease from 1.0 to 0.0 linearly within twenty-four hours.
When the user has read an article, its freshness is decreased by half.

Fig. 4. A screenshot of ANATAGONOMY/SS.
Figure 4 shows a screen shot of ANATAGONOMY/SS.
All the article titles are moving from right to left.
The anticipated article scores — in other words, personal preferences —
are reflected in the vertical height of the articles,
and the freshness of each article is reflected in its virtual depth on the
screen.
From the user's viewpoint, the fresher an article is,
the closer its headline appears.
Size, brightness, and the motion parallax are used to create this depth.
That is, the closer a headline should appear,
the larger and brighter it is displayed and the faster it moves.
This presentation lets the user easily see both the personal preference
and the article freshness.
Perspective is used to display the relative and personal freshness of
articles as well as their absolute freshness.
Once the user reads an article,
its freshness decreases and when it comes up on the screen next time
it is displayed far from the user.

Fig. 5. User interface of ANATAGONOMY/SS.
The articles are presented in three steps.
First, only article headlines move on the screen from right to left
(Fig. 5a).
Then when the user moves the mouse cursor over one of the article
headlines, the article's first sentence appears (Fig. 5b).
Finally, when the user clicks a mouse button while an article's first
sentence is being shown,
the whole text of the article is displayed (Fig. 5c).
These three steps help the user to get relevant information efficiently
since the limited screen space is used to show as much relevant
information as possible.
In addition, these three steps help the system to extract
the user preference.
When the user has read only the first sentence of an article,
it will show that the user got interested in the article only a little;
when the user has looked at the whole text of an article,
it will show that the user got more interested in the article.
These assumptions may not be always true,
but according to our experience in the pull-type personalized newspaper,
the user preference can be learned fairly well by using this method [2].
ANATAGONOMY/SS client-side modules are implemented on Windows95 and
WindowsNT,
and it can act both as a screen saver and as an application program.
It works by communicating with the ANATAGONOMY/SS server-side modules
on our Internet server.
Since the receiver is implemented as a resident program,
it constantly updates articles even when the viewer is not running.
Currently, ANATAGONOMY/SS client-side modules are open to public
as a freeware program [V] and had been downloaded by more
than 3,000 people within three months of its being announced.
4. Push-type Internet Scrapbook
4.1. Internet Scrapbook
Internet Scrapbook [6] is a program product that provides functions
that a user can use to create her/his own WWW page from portions of multiple
WWW pages.
The created page of the Internet Scrapbook (we will call it a scrapbook page)
can be updated when the original pages are modified
because the scrapbook page records the portions of the original pages
not as the content but as the HTML patterns within the pages.
The patterns are extracted using an example-based or demonstration-based
programming technique [7].
As shown in Fig. 6, the user first selects a desired
portion of data on a browser
and then copies the selected data to another browser for
the scrapbook page.
Every time the user performs the selection and the copy operations,
the system generates a matching pattern that can specify the selected
portion of the page.
When the original page is modified, the system extracts a portion
of the same page again using the matching pattern, and recomposes
the scrapbook page with the latest information.
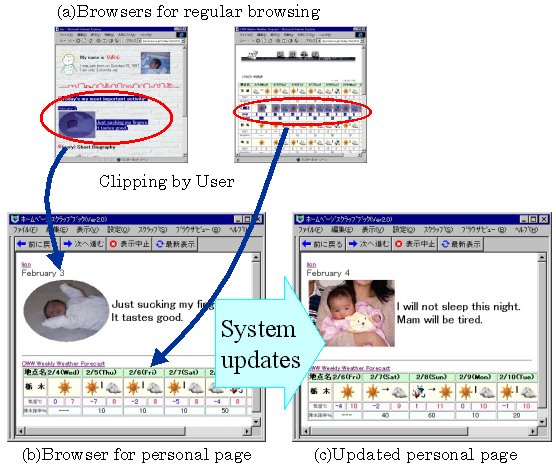
Fig. 6. Overview of Internet Scrapbook.
Internet Scrapbook is a useful tool for creating a personalized WWW page
but it still lacks some functions.
First, since it is a pull-type system, the user has to select the
scrapbook page and update it when she/he wants to see the latest
information.
These operations seem simple but become tedious if the user wants
updated information throughout the day.
Second, in the Internet Scrapbook, it is difficult to know which
information pieces are new.
We have used our freshness visualization technique to solve these problems.
4.2. Push-type Internet Scrapbook
In the push-type Internet Scrapbook,
once the user creates a scrapbook page,
the contents of the page are automatically updated and displayed
on the screen saver as in ANATAGONOMY/SS.
Figure 7 shows the system architecture of Internet Scrapbook.
The main difference from ANATAGONOMY/SS is that
all the program modules are on the client side,
and they get content from ordinary WWW sites.
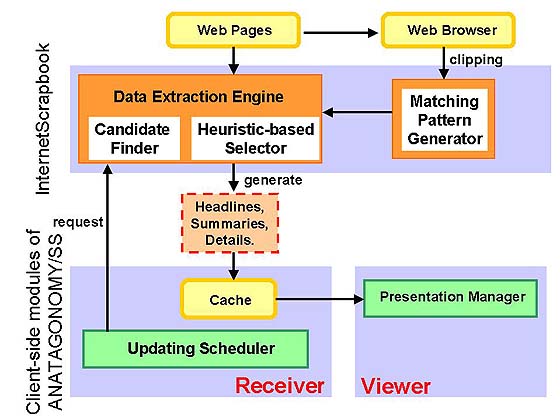
Fig. 7. System architecture of push-type Internet Scrapbook.
4.2.1. Information delivery
Information delivery in this system is almost same as that in
ANATAGONOMY/SS.
First, the receiver module sends an information request
to the data extraction engine according to the predefined schedule.
In this system the updating schedule can be specified for each information
clip, which is a portion of a WWW page collected at one time.
Then the data extraction engine downloads the latest contents from their
original WWW pages; picks out each clip's headlines,
summaries, and details using sub-modules called the candidate finder
and the heuristic-based selector [6];
and saves them in the cache.
Since all the processes are done automatically,
the information pieces in the cache are kept up-to-date all the time.
4.2.2. Presentation and user interface
The user interface of this system is also similar to that of
ANATAGONOMY/SS.
Each information clip is presented in three steps:one each for the
headline, summaries, and details.
The headlines move on the screen automatically from right to left.
When the user puts the mouse cursor on a headline,
the summary of the focused clip appears immediately;
and when the user clicks a mouse button on the summary,
its details are shown.
In ANATAGONOMY/SS the displayed contents are only article text files,
but in this system the contents can be HTML documents (see Fig. 8).
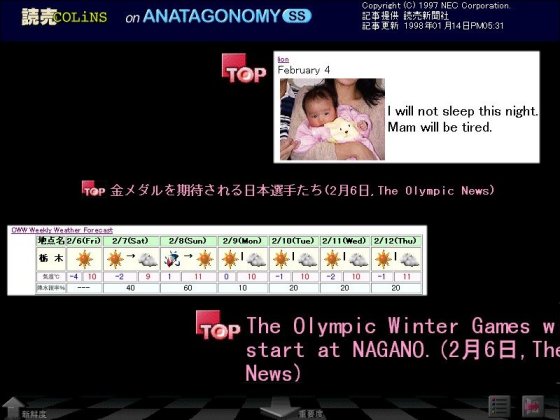
Fig. 8. A screenshot of push-type Internet Scrapbook.
5. Discussions
5.1. Freshness visualization
We implemented two applications using our information freshness technique.
In ANATAGONOMY/SS, both personal preference and information freshness
could be visualized effectively by using the height and the depth of
the screen.
The main difference between the presentations of ANATAGONOMY/SS and the
push-type Internet Scrapbook is that the vertical position of each article
on the screen does not have any meaning in the Internet Scrapbook.
In ANATAGONOMY/SS all the article scores are calculated
and reflected in the vertical position, but in the push-type Internet
Scrapbook the contents are selected by the user explicitly
and are not ordered according to importance.
This means that we could use either vertical position or depth to represent
the freshness of each information clip's.
We selected depth for the following reasons:
- If a height were used to show the absolute information freshness,
only the lower area of the screen would be used when all the
information was rather old.
- If a height were used to show the relative information freshness,
the user could not see the absolute freshness of each information.
That is, the newest information piece would always be shown
at the top of the screen regardless of its actual freshness.
These problems are avoided by using depth to show freshness.
When there are many new information pieces, they will look bright
and large and will move fast.
Old articles will look dark and small and will move slowly.
In any case, the whole screen will be used to display information.
Most of the members of our laboratory use ANATAGONOMY/SS or push-type
Personalized Scrapbook as a screen saver.
According to our informal observation,
people usually read personally interesting articles quickly
everyday just after they arrive at the office in the morning.
Then the screen saver automatically starts running
some time during the day, and when someone finds new articles or
information contents, she/he clicks and reads them.
This suggests that personal preference is an important
filtering factor when people see many articles at one time,
and freshness is important when new information comes in sporadically.
5.2. Depth presentation for WWW contents
In our current implementation of the push-type Internet Scrapbook,
when the information clip consists of text data,
the system uses depth cues such as the object size, brightness,
and the motion parallax for presenting virtual depth on the screen.
When the information clip contains image data, on the other hand,
the system controls the depth cues only on the "category icons" presented on
the left side of the clip (see Fig. 8),
and the system does not change the presentation of the clip itself
and show it as it is.
This is because the size and the brightness of images on WWW
pages are defined in the original pages, and also because their impression
would be wrongly affected by changing their size and brightness.
It is difficult, however, to recognize the differences between the depths
of objects when they are indicated only by category icons.
Therefore, there is yet room for improvement in displaying the
freshness of image-based information clips.
In presenting the freshness of image-based information clips,
it is desirable to maintain the appearances of the original contents.
One way to avoid changing the original contents is by using shadow depth
cues because a shadow cast by an object does not affect its original
appearance.
Figure 9 shows an example the illusion of perspective being presented
by using the shadow depth cues.
As this figure shows, depth can be comparatively distinguished by
controlling the thickness of the shadow and the distance between an
object and its shadow.

Fig. 9. Perspective illusion enhanced by shadow depth cues.
(The right image appears to be closer than the left object.)
5.3. Related work
PointCast Network's system [II] delivers news articles in push-style
and the contents can be personalized,
but the user has to read the same article many times since
the system does not consider information freshness.
Ishizaki visualized temporal attribute in his news viewer [9].
When an article comes in on his world map, a news article pops up
at the place on the map where the incident happened,
and then it shrinks although it does not disappear.
This system will be good when the user is looking at the display
all the time, but a user who misses an article when it comes
in does not know which article is new any more.
In addition, personal interest is not reflected on the presentation.
Galaxy of News [8] provides a progressive zooming function that
enables the user to read the details of information progressively
in a hierarchical information structure.
Utilizing the depth of the screen and a top-down view,
the system offers a very effective way of presenting the available
information in an interactive information retrieval environment.
Our system, however, is used for automatic rather than interactive
information delivery and has to present all available information
directly to the user,
thus rendering the use of hierarchies is impractical.
6. Conclusion
We developed a technique for visualizing information freshness
by using perspective,
and we have applied the technique to WWW-based personalized
push-type systems.
There are various types of information on the WWW.
Some pages are updated very often, and some pages are updated only a few
times a year or less.
Conventional personalized services consider only the personal interest
when filtering or sorting information, but our experience in a
personalized newspaper service showed that more than
personal interest needed to be considered in order to help users
to get relevant information.
The freshness of the information needed to also be considered,
especially in push-type services.
Using the screen depth to represent the freshness enables
the limited screen space to be used efficiently and other
attributes, such as the positions in the screen,
can be used for visualizing the personal importance
of information.
References
- Kamba, T., Sakagami, H., and Koseki, Y.,
ANATAGONOMY: a personalized newspaper on the WWW,
International Journal of Human-Computer Studies,
Special Issue on Innovative Applications of the World Wide Web, 1997.
- Sakagami, H., Kamba, T., and Koseki,Y.,
Learning personal preferences on online newspaper articles from
user behaviors, in: 6th International World Wide Web Conference,
1997, pp. 291–300.
- Nakamura, A., Mamizuka, H., Toba, H., and Abe, N.,
Learning personal preference functions using boolean-variable
real-valued multivariate polynomials, in: 52nd National Convention of the
Information Processing Society of Japan, 1995 (in Japanese).
- Preece, J., Human–Computer Interaction, Addison-Wesley, reading, MA, 1994.
- J.J. Gibson, The Perception of the Visual World, 1950.
- Sugiura, A., and Koseki, Y.,
Internet Scrapbook: creating personalized World Wide Web pages,
CHI 97 Extended Abstract, 1997, pp. 343–344.
- Cypher, A. (Ed.), Watch What I Do: Programming by Demonstration,
MIT Press, 1993.
- Rennison, E., Galaxy of news: an approach to visualizing
and understanding expansive news landscapes, in: UIST'94 Proceedings,
1994, pp. 3–12.
- Ishizaki, S., Multiagent model of dynamic design:
visualization as an emergent behavior of active design agents,
in: CHI'96 Proceedings, 1996, pp. 347–54.
URLs
-
Yomiuri-COLiNS(http://pnews.cplaza.ne.jp/)
-
PointCast Network(http://www.pointcast.com/)
-
Marimba(http://www.marimba.com/)
-
Yahoo(http://www.yahoo.com/)
-
ANATAGONOMY/SS Freeware Download Site(http://www.labs.nec.co.jp/freesoft/ANATAGONOMY/)
Vitae
 |
Hidekazu Sakagami
received B.E. and M.E. degrees in mechanical engineering from the
University of Tokyo in 1989 and 1991.
He then joined NEC Corporation, where he is currently a researcher at
the C&C; Media Research Laboratories.
His research interests include human computer interactions,
personalization, and multimedia information services.
He is a member of the Information Processing Society of Japan and the
Japan Society for Software Science and Technology. |
| |
 |
Tomonari Kamba
received B.E., M.E., and Ph.D. degrees in electronics from the
University of Tokyo in 1984, 1986, and 1997.
He joined NEC Corporation in 1986, and there he has been engaged
in user interface design methodology, multimedia user interfaces,
software agents, and Internet information service technology.
From 1994 to 1995 he was a visiting scientist at the Graphics,
Visualization & Usability Center at the College of Computing,
Georgia Institute of Technology.
He is now an assistant research manager at NEC Corporation's C&C; Media
Research Laboratories and is a member of ACM SIGCHI and the Information
Processing Society of Japan.
|
| |
 | Atsushi Sugiura
received B.E. and M.E. degrees in electric engineering from the
University of Osaka in 1988 and 1990.
He then joined NEC Corporation, where he is currently an assistant
research manager at the C&C; Media Research Laboratories.
His research interests include human computer interactions,
visual programming, programming by demonstration, and software agents.
|
| |

| Yoshiyuki Koseki
received his B.S. degree in computer science from the Tokyo Institute
of Technology in 1979 and his M.S. degree in computer science from
the University of California at Los Angeles in 1981.
He received his Ph.D. in System Science from Tokyo Institute of
Technology in 1993.
He joined NEC Corporation in 1981, and he has since been engaged
in research on artificial intelligence,
expert systems, visual programming, information visualization,
and WWW-based agent technology.
He is now Research Manager of C&C; Media Research Laboratories
and is a member of the IEEE, the AAAI,
the Japanese Society for Artificial Intelligence,
and the Information Processing Society of Japan.
|