Hewlett-Packard Laboratories, Bristol, U.K.
ak@hplb.hpl.hp.com
Applications on the World Wide Web use the Common Gateway Interface or Web server APIs in order to generate content dynamically in response to HTTP invocations. Typically program logic embeds the HTML document directly in the application source code but customizes it in small ways whenever the HTML is output in response to a request.
Experience with writing Web applications has demonstrated the importance of separation between program logic and presentation logic, the latter typically being in the form of HTML. This is especially true as applications get bigger and more mission critical. As the skills and tools required for writing Web application code and authoring the GUI are so clearly different there is a lot to gain from separating the two activities. First, the HTML code can be modified without access to the application source code and without needing to recompile and retest the application. Second, HTML and application code can be edited with whatever tools are most appropriate for each task. Third, localization is done on documents rather than on program code and is hence much easier and cheaper.
The request–response style of interactions between client-side user agents and server-side applications on the Web naturally leads to the application being structured as a finite state machine (FSM). When a client makes an HTTP request it triggers a state transition in the application which then returns a response in the form of a new HTML page. The FSM corresponding to a medium sized Web service could consist of, say, 5–10 nodes.
The notion of HTML templates relies on two observations. First, different invocations triggering a transition to the same "node" in the service FSM will receive roughly the same HTML page but with key bits differing, and second, HTML pages corresponding to different nodes will more often than not have markup such as headers, footers, and other structure in common. Defining such structures in one place guarantees consistency in the pages and simplifies maintenance.
The idea of templates is to separate the presentation logic from application logic. HTML documents are stored separately from program logic but contain special markup which places key parts of HTML code under application control. The typical scenario is that a Web server receives an HTTP request and passes the request on to the application. The application figures out which "node" (corresponding to an HTML template) to transition to next, computes the set of name-value parameters for this template, and asks the template processor to resolve the template in the context of these parameters. The result of this process, which contains no template markup, is what gets send back to the user-agent.
The template markup defined in this paper allows
The most basic function of the template language is variable substitution. A variable is a binding between a name and a value in some context. Variable names are URLs and values are pieces of content — text strings which can themselves contain markup including variable substitution and flow control directives.
The template mechanism described here has the following properties:
It is useful to contrast templates with a time-proven technology. The analogy between our template processor and the C preprocessor, cpp, is quite good. Template definitions are like macro definitions and flow control directives are like cpp conditional compilation (but allows more powerful conditions). However there are some important differences. First, unlike cpp the TRiX template processor respects the target language syntax by doing transformations on parse trees rather than source text. Second, the equivalent of macro definitions can have a number of sources, only one of which is the source text itself. And third, the TRiX framework is extensible in ways cpp is not; TRiX handlers are pieces of code and can thus do arbitrary transformations on the parse tree.
The rest of this paper is structured as follows. Section 2 discusses the template "lifecycle". Section 3 presents the Template Markup Language (TML), and Section 4 shows how this is realized in the TRiX framework. Section 4 also discusses how TRiX extensions are written and how they interact with each other, using a database access component for the purpose of illustration.
A template consists of "static" portions in the target language (e.g. straight HTML) together with dynamic template elements which are resolved at template load or write time.
Templates are loaded in a template context. The context associates variable names with values and knows about template handlers configured with the processor.
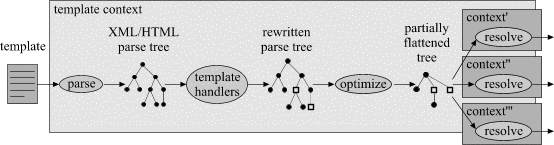
Figure 1 shows the steps taken by the TRiX engine in handling templates.
|
The steps are as follows:
Templates are resolved in a context but not necessarily the same one in which they were loaded. In Web applications we wrap the original context with a context which is specific to the HTTP request in question. Hence the internal representation of a template can refer to properties of HTTP requests yet to be received. This is discussed in more detail in Section 4.1.
The model doesn't assume a client–server content delivery model. Server-side template resolution is of interest to writers of server-side Web applications but templates could be interesting in other environments, e.g., as a client-side mechanism for dealing with variances in user–agent capabilities. Also, the distinction between template load-time and resolution-time is important for some applications, such as server-side Web applications, but for others a template may be resolved at the same time as it is loaded.
The template framework defined in this document is intended to be usable with a variety of target languages. The primary motivator is the need for HTML templates in Web services but we expect that the application of TML (or something similar) to XML languages will become increasingly important as the latter start to appear.
Template definitions are given as XML DTDs in the text. XML applications can use these elements without change to their DTD by using namespaces. Extending the HTML DTD to include the template DTD given here would be straightforward. The examples are given using HTML but sometimes with an XML syntax (without namespaces).
Within an HTML or XML document content can be associated with a variable name using the define element:
<!ELEMENT define (#PCDATA | subst | if)* >
<!ATTLIST define id ID #REQUIRED
href CDATA #IMPLIED
delayed (true|false) "false" >
|
Attribute definitions:
Upon encountering a define element the template
processor associates the definition with the id. The
contents of the define element isn't sent to a client or
written to an output stream until this is explicitly requested by the
subst element. The following example associates the
variable brown-addr with some HTML address markup:
<define id="brown-addr">
<address>
J. R. Brown<br>
8723 Buena Vista, Smallville, CT 01234<br>
Tel: +1 (123) 456 7890
</address>
</define>Unlike other TML elements the define element is typically interpreted and resolved at the time the template in which it occurs is loaded. Setting the delayed attribute to true changes this behaviour.
Before proceeding to present the subst element we need to discuss the nature of template variables and in particular how they are referenced in more depth.
We define the var URL scheme to denote TML variables. By denoting variables using a URL syntax the semantics of template elements can be extended to have a useful function for URLs in general — in particular anything in URL space can be assigned to variables.
The var form of URLs is one of:
var:<variable-name> var:<subscheme>:<variable-name>
It also means we can refer to template variables using relative URLs
and fragment identifiers as in
"../defs.tml#brown-addr". Such a reference causes the
template processor to load the resource defs.tml relative to
the template itself (typically from a file system) and search for an
element with the specified name within that resource.
Note that this scheme for variable substitution is readily
generalized to content defined using ordinary HTML/XML elements using
the id attribute or the name attribute of the
HTML a element. Assuming that the following markup is part
of file "foo.html":
<H1 id="title">My Beautiful Document</H1>
foo.html#title" and the template processor would evaluate
this to "My Beautiful Document".
The subscheme variation of var URLs can be used to allow access to an open-ended set of variable spaces. We have defined and implemented the following:
var:http:<variable-name> var:form:<variable-name> var:query-string:<variable-name> var:cookie:<variable-name> var:sys:time;format=d+m+y+H:M
The TRiX template resolution engine recognizes all of the above URLs and can be extended to understand more. Handlers implementing subschemes may define additional structure in the variable-name part of the URL, e.g. allowing the specification of a set of named parameters in the URL.
The subst element is defined as a simple XLL
link [XLL]. Attributes other than href
and cond are defined simply for conformance with XLL and all
have fixed values.
<!ELEMENT subst (#PCDATA | define | subst | if)* >
<!ATTLIST subst href CDATA #REQUIRED
cond CDATA #IMPLIED
xml-link CDATA #FIXED "SIMPLE"
inline (true|false) #FIXED "true"
show (embed|replace|new) #FIXED "embed"
actuate (auto|user) #FIXED "auto" >
|
An HTML DTD for subst would allow arbitrary HTML markup as element content. The intention is that if the subst operation fails, e.g. because the variable isn't defined, then the contents of the element is displayed. This is like the behaviour of the HTML 4.0 object element and again provides for a more robust protocol by including content for error messages.
Attribute definitions:
The following examples demonstrate different use of variable substitution.
<subst href="brown-addr"/> <!-- var defined in same doc --> <subst href="defs.tml#brown-addr"/> <!-- different doc; rel. URL --> <subst href="http://foo.net/scripts.js"/> <!-- entire remote resource -->
An XLL locator is a string which can be used to locate a resource. Locators are URLs with a (very) generalized notion of "#"-fragments. Locator "fragments" (XPointers) allow addressing part of a document in a number of ways based on the structure of the document. This allows us to address Web resources in a very powerful manner. The following is a simple example which expands into the title of a remote Web document (assuming it has one):
<subst href="http://www.acme.org/index.html#DESCENDANT(1,TITLE)"></subst>
Within attribute definitions in the target document variables are
dereferenced using syntax like "$var:name". The variable
name may be delimited by curly braces, as in "${var:name}",
to avoid ambiguities. Curly braces are considered unsafe in URLs so can
safely be used as URL delimiters [RFC1738].
What appears within the braces can be any URL, not just ones belonging to the var scheme (which is the default scheme). When a template document is loaded all attribute values are scanned for embedded variable references. The template is stored as a tree structure which supports efficient resolution.
An example of attribute-embedded variable references:
<a href="${var:http:path}?map=${map}&long=${longitude}&lat=${latitude}">
<a href="/servlets/maps?map=uk&long=2-33&lat=54-30">
The ability to dereference template variables within attribute values is important in many applications. It has a special role in TML as the conditional inclusion directives encode conditions in attribute values and need to refer to variables within these.
<subst href="$addr"></subst>
$addr" is first substituted to, say,
"brown-addr" which is then dereferenced to substitute
in the value that will actually appear on the output stream. Basically
both the subst element and the $variable
syntax provides a level of indirection and they can be combined to
achieve a double indirection.
The general format of the if element is:
<!ELEMENT if (#PCDATA | define | subst | if | elif | else)* > <!ATTLIST if cond CDATA #REQUIRED > <!ELEMENT elif (#PCDATA | define | subst | if)* > <!ATTLIST elif cond CDATA #REQUIRED > <!ELEMENT else (#PCDATA | define | subst | if)* > |
Attribute definitions:
An example of the if element in action:
<if cond="$tel-work && ${var:sys:time;format=H} < 17">
Work telephone number: <subst href="tel-work"></subst>.
<elif cond="$tel-home">
Home telephone number: <subst href="tel-home"/></subst>.
</elif>
<else>
No phone number available.
</else>
</if>
The sequencing rules of the if elements are those commonly found in programming languages. Any number of elif elements (possibly none) can follow the if element after which follows an optional else element. The conditions are evaluated in order and the content associated with the first condition which evaluates to true gets emitted by the template processor. if elements may be nested to any depth.
TML is recognized in TRiX (Template Resolution in XML/HTML). TRiX is a Java framework consisting of an XML parser with hooks for handling HTML, a parser for the TML condition language, and a set of interfaces and classes representing parse trees, var URLs, contexts, etc.
The framework has been used to create three incarnations of a
template processor: a standalone processor, a Web server filter which
resolves any files with the MIME type "text/x-thtml" as
template HTML before sending it to the client as
"text/html", and an API which can be used from Web
applications written to the standard servlet API [Servlet API]. We'll take a closer look at
the latter two.
The TRiX API allows any Java application use of its template model and is often useful when there's a need to generate text in a stylized form. It has, for example, been used to generate parameterized email messages.
As previously mentioned a typical Web application loads the set of templates it uses at startup and then repeatedly resolves them in the context of different HTTP requests. In TRiX templates are loaded and resolved via a TemplateContext object. Variables defined within template files are stored in the TemplateContext in which the template was loaded. These variables are shared amongst all HTTP invocations. Other variables are specific to individual requests; those assigned a value within the service logic or defined implicitly by properties of HTTP requests (e.g. var:http:user-agent URLs). A separate HttpContext object is constructed for each request. This wraps the orginal TemplateContext but additionally provides access to request-specific variables, see Fig. 2.
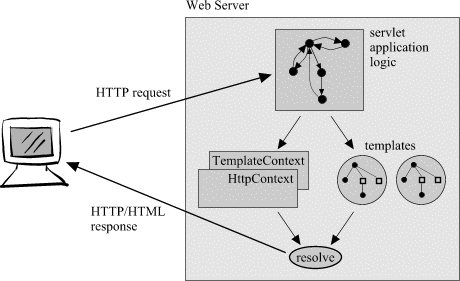 |
During resolution references to variables which are undefined in the HttpContext are dereferenced by the TemplateContext. This mechanism allows for sharing of variables across servlet invocations.
It's convenient to be able to include TML markup in Web pages without having to write, install, and manage any service logic. Although TML wasn't intended to replace Web application logic entirely — just separate logic from presentation — it's actually possible to do simple services without writing any code at all (apart from the template markup).
We have integrated a template processing filter servlet with the Nexus Web server which intercepts all requests for files with a particular suffix, e.g. ".tml", and resolves template markup in the context of the HTTP request without requiring additional application code.
The TRiX framework is extensible in two dimensions: by adding handlers for var URL subschemes and template elements. The framework is mostly independent of TML. TML is implemented simply as a particular set of template element handlers — one for each of the define, subst, and if elements. Handlers are registered with the TemplateContext by applications either explicitly through an API call or implicitly by adding the class name to the trix.handlers Java property.
A var subscheme handler is simply a factory for representations of URLs. This is realized by the VarScheme interface. Representations of var URLs themselves implement the VarURL interface and knows how to set and get values for that scheme. Having implemented these two simple interfaces the new var scheme can be used in subst template elements, in conditional expressions, and in other contexts expecting a var URL.
The TML elements are adequate for most applications, but the ability to add handlers for new template elements is quite powerful. It is fairly easy to implement new elements which mix well with existing ones.
The steps required for implementing a new template element are analogous to those for implementing a var URL handler: a method is invoked on the handler during template loading. The handler has access to the template node and the rest of the XML/HTML parse tree. The handler method returns a tree node which replaces the original node.
An example use of this extension mechanism is our database-to-Web connectivity markup. This allows content to be generated from a database by including query and iter elements in HTML pages (several commercial products work in a similar way). The query element associates a name with an SQL query, while the iter element causes the query to be executed and then iterates over all rows in the result set.
The following shows a full, working example:
<html><body>
<h1>JDBC Access from HTML Templates</h1>
<query id="books" datasource="jdbc:odbc:books-db">
select author,title,year from <subst href="var:form:database"/>
order by <subst href="var:form:sort-field"/>
</query>
<table>
<tr bgcolor="d0d0d0"><th>Author</th><th>Title</th><th>Year</th></tr>
<iter id="books">
<tr>
<td><subst href="author"/></td>
<td><subst href="title"/></td>
<td><subst href="year"/></td>
</tr>
</iter>
</table>
</body></html>
This retrieves a set of records from a database and displays the
result as an HTML table without requiring additional code to run. Note
that the query in this example is composed "dynamically" using
subst elements to retrieve information from a
just-submitted form. The query element handler must be
written so as to allow such "late binding" (this is exactly what the
define element does with the delayed
attribute).
Since all code runs in a single Java virtual machine the connection to the database can be shared amongst all requests for this page. Combined with query precompilation this potentially makes this type of database access very fast.
Displaying database query results by mapping directly onto HTML tables is quite natural and is a very common thing to do. However one might certainly want to display the result set in a different way. An example might be a set of reservations stored using one record per reservation. One might want to display the result as a table with a row per time-unit, rather than as a row per reservation.
There are (at least) two ways of accommodating such "alternative" styles. One is either to write custom template elements or extend existing ones to do what is needed. The other possibility is to use a client-side scripting language, such as JavaScript, to assign the result of the database query to an array and then use the scripting language to perform special-purpose layout in the client. The client-side code can itself be auto-generated from a GUI development environment but that is outside the scope of this paper.
XML has some support for macros and conditional inclusion through its notion of text entities and conditional sections. It is possible to share common elements between large document collections using only features build into XML. However this requires a declaration in the DTD section of documents for each "macro" used and an indirection in each use of the macro. HTML avoided using this mechanism and went for the simpler approach of using URLs directly in attribute values. As HTML authors and tools generally don't know about DTDs and probably doesn't care it is unnatural to base TML on entities. Another problem is that XML marked sections are too simple to make an appropriate basis for doing flow control in template documents.
It seems that an approach based on an XML language and namespaces is neater as it will be more readily approachable by most people and it would seem to be exactly the kind of application XML was designed to address.
Another important body of related work is that of commercially available Web-database integration tools, such as Bluestone's Sapphire Web, Allaire's Cold Fusion, Oracle's Developer/2000, etc. These tools provide functionality comparable to the database template elements presented in Section 4.4. However they don't typically provide such a high degree of openness and integration as is attainable in TRiX.
Mawl is a domain-specific language for programming form-based services [Atkins]. Like TRiX it attempts to solve the problem of separating application logic from presentation logic but in very different way. Being a special-purpose language Mawl has built-in support for setting and retrieving variables from forms, where forms is an abstraction covering, for example, HTML pages and IVR systems. A Mawl template contains GUI details and is specific to the medium on which the form is rendered. TRiX differs in allowing Web applications access to details of the request and can thus be highly protocol and media dependent. In our experience such low-level control is actually needed when writing Web applications.
Writing numerous Web applications has shown to us that TRiX does indeed solve the problem of entangled application and presentation logic. TML combined with the notion of variables as URLs provides for a powerful and general language for the construction of documents from templates on-the-fly. We applied it to server-side Web applications but it could equally well be applied on the client-side as an alternative to using scripting languages.
The major benefit of the TRiX framework lies in its extensibility,
both in the number of var URL subschemes and the set of
template elements it knows about, and in the high level of integration
that is readily achievable between template elements. Modelling
variables as URLs has proven itself very useful. The URL has the same
unifying role in the template processor as it has on the Web at large in
making TML elements independent of the sources of data they operate on.
XML and XLL has made it possible to define languages which extend
HTML in various ways. We believe it would be worthwhile standardizing
TML and var URL schemes pertaining to different
environments such as Web servers and browsers. Later more specific
extensions for vertical domains, such as server-side database access
markup, could be standardized.
The TML language and the notion of the template processor were first proposed on the servlet API mailing list. The work described in this paper evolved partly from feedback from people on that list. Particularly, thanks goes to Cimarron Taylor for his interesting ideas on arrays and iteration and to Dave Hollander for numerous helpful comments on this paper.
| Apache SSI | http://www.apache.org/docs/mod/mod_include.html |
| The Nexus Web Server | http://www-uk.hpl.hp.com/people/ak/java/nexus/ |
| Bluestone Sapphire/Web | http://www.bluestone.com/ |
| Allaire Cold Fusion | http://www.allaire.com/ |
| Oracle Developer/2000 | http://www.oracle.com/products/tools/dev2k/ |
 Anders Kristensen is a senior member of technical staff at
Hewlett-Packard Laboratories in Bristol, U.K. He has been working in
the telecoms area of intelligent networks and has more recently been a
co-developer of the Keryx Internet Notification Service. Over the last
couple of years Anders has been developing a wide array of Web-related
technologies, e.g. the Nexus Web server, in Java. He has a strong
background in object-oriented technologies and distributed systems.
Anders holds a B.S. in mathematics and an M.S. degree in computer
science from Aarhus University, Denmark.
Anders Kristensen is a senior member of technical staff at
Hewlett-Packard Laboratories in Bristol, U.K. He has been working in
the telecoms area of intelligent networks and has more recently been a
co-developer of the Keryx Internet Notification Service. Over the last
couple of years Anders has been developing a wide array of Web-related
technologies, e.g. the Nexus Web server, in Java. He has a strong
background in object-oriented technologies and distributed systems.
Anders holds a B.S. in mathematics and an M.S. degree in computer
science from Aarhus University, Denmark.