aInformation and Computer Science,
University of California, Irvine,
Irvine, CA 92697-3425, USA
kistler@ics.uci.edu
bDIGITAL Systems Research Center
130 Lytton Avenue,
Palo Alto, CA 94301, USA
marais@pa.dec.com
Some of the characteristics of the Web, like its wide area distribution, unreliable services, lack of referential integrity, security model, and lack of data typing, differ immensely from those of traditional programming models, which presupposes a non-distributed, well-structured, and predictable infrastructure. Furthermore, because of the Web's geographical distribution, latency and bandwidth — not CPU speed and memory size — become the limiting factors that need to be addressed. So what kind of programming models and programming constructs are needed to compute on the Web? To understand this question, we first have to study typical Web computations. In our view, a typical Web computation can be divided into three phases.
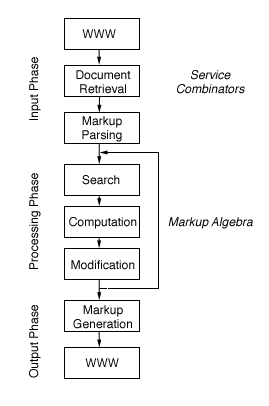
The input phase involves fetching one or more Web pages for processing. During this phase we have to contend with the Web's geographic distribution and architectural inefficiencies. For example, one or more of the following situations might apply when retrieving a page from a Web service:
The processing phase of a typical Web computation involves extracting data values from pages and performing computations on these data values. We assume pages to be marked-up in either XML or HTML, so as to exploit the structural content of the page. The difficulties encountered in this phase include poorly structured pages, HTML markup that does not reflect the document structure (for example, misuse of tables for presentation effects), and pages that change format regularly or unexpectedly. Our data extraction technique is based on a markup algebra that performs operations on sets of elements in a page (see Section 4).
The output phase of a typical Web computation covers the generation of Web documents from values computed during the processing phase, and storing them back on the Web (for example, by publishing the page on a Web server).
Figure 1 depicts this general model of a Web computation. Web pages flow through a pipeline of service combinators for fetching pages, a markup parser, the markup algebra for extracting (or "searching" for) data values from (on) a page, computing on those values, and page manipulation. Searching, computing and manipulation is repeated as often as needed. Finally the page is regenerated from its internal representation by the markup generator, and stored back on the Web.
We implemented our WebL prototype in Java. The core functionality consists of libraries that implement the parsers, service combinators and markup algebra. The idea is that programmers that don't want to use the WebL language, could eventually use these libraries directly in their Java programs without penalty (except for giving up the compact syntax).
Although we regard the language as secondary to the novel features we introduce, the language has grown over time to support many conventional languaging features like dynamic typing, objects, modules, closures, exceptions, sets, lists, associative arrays, multithreading, etc. These features make it a convenient language for prototyping computations on the Web and quite a useful tool for Web masters.
Some of the applications we constructed with WebL so far include:
In the remainder of the paper we will concentrate on only two novel aspects of WebL, namely service combinators (Section 3) and the markup algebra (Section 4). These sections are followed by related work (Section 5) and conclusions (Section 6). An Appendix lists example programs.
For the remainder of this section S and T denote operands (called services), which may contain primitives to fetch pages or general WebL computations.
Services
The getpage function fetches with the HTTP GET protocol the resource associated with the string URL. The result returned is a page object that encapsulates the resource. The function fails if the fetch fails. The second and third arguments to getpage are optional — when specified, they provide the server with query arguments and HTTP headers respectively. A similar function called postpage uses the HTTP POST protocol, used to fill in Web-based input forms.
// This program looks up the word "java" on the
// AltaVista search engine.
page := getpage("http://www.altavista.digital.com/cgi-bin/query",
[. pg="q", what="web", q="java" .])
WebL's data extraction language addresses these problems with the notion of a markup algebra. The markup algebra is based upon the concepts of pieces, piece-sets and algebraic operators that are applied to piece-sets.
First, we define a piece as a contiguous text region in a document, identified by the starting and the ending position of the region. For this paper we can imagine positions as indices that indicate a character offset in the page, which makes it easy to determine by numerical comparison the relationship between two regions, such as whether two pieces overlap, are contained in each other, or follow each other. (Our WebL implementation uses a more complicated data structure for pieces that simplifies searching and page modification.) We further define a piece-set as a collection of pieces. Pieces within piece-sets may overlap, be nested, or may belong to different pages. However, unlike mathematical sets that do not impose a particular ordering on their elements, piece-sets are always in a canonical representation in which pieces are ordered according to their starting position, and then their ending position in the document. This allows iterating over pieces in a set in the sequence they appear in the document, and also to pick the nth occurrence of a pattern (by indexing into the piece-set). Both pieces and piece-sets are mapped to special objects in WebL, which means that they can have attributes and be manipulated by programs.
A common way to create a piece-set is to search for all the HTML or XML elements with a specific name (we call this a structured search). For example, the following program returns all the anchors (hyperlinks) that occur on the DIGITAL homepage by calling a method called Elem of the page object P:
Another way to create a piece-set is to search for character patterns, ignoring the markup (we call this unstructured search or pattern search). The Pat method of a page object extracts all the occurrences of a Perl 5-style regular expression [Fri97] in the text of a page. The following example extracts the occurrences of the word "Digital" or "digital" in the Digital home page.
Finally, we define a set operator S ¤ T as an algebraic operation ¤ between two piece-sets S and T that returns a third piece-set as a result. For the remainder of this section, S and T denote piece-sets, the elements of S and T are referred to as s and t, and P stands for a page object. WebL divides set operators into groups of basic set manipulation operators, positional set operators, and hierarchical set operators, which will be discussed in the following sections. In the interest of conciseness, we will not describe the negated operators (those starting with an exclamation point), as their behavior is easy to deduce.
| Union | S + T |
| Intersection | S * T |
| Exclusion | S - T |
Basic set operators are used for basic set manipulation. They contain a set union operator, a set intersection operator, and a set exclusion operator. The set union operator merges the two sets S and T and eliminates duplicate pieces. The set intersection operator returns the set of all pieces that are contained both in S and T, and the set exclusion operator calculates the set of pieces that are contained in S but not in T. As an example, the following program retrieves all the level one and level two headings in a page:
| S before T | S !before T |
| S after T | S !after T |
| S directlybefore T | S !directlybefore T |
| S directlyafter T | S !directlyafter T |
| S overlap T | S !overlap T |
Positional operators provide functionality to query on the locality property of pieces, such as searching for pieces that are located above or below other pieces in the linear text flow of the document.
The before operator computes the set of pieces in S that are located before some piece in T. We define a piece s to be located before a piece t if the ending position of s precedes the starting position of t. Correspondingly, the after operator returns the set of pieces in S that are located after some piece in T. Although they are very effective, these two operators are not always sufficient. As an example, in some cases we might not be interested in all the occurrences of a link after a special keyword, but only in the very first occurrence of a link after the special keyword. In this case, we use the stronger operators directlybefore and directlyafter that return the set of only the closest pieces in S that follow or precede some piece in T. We also call the latter non-transitive versions of the before and after operators. The following example depicts the differences between these operators:
| S in T | S !in T |
| S contain T | S !contain T |
| S directlyin T | S !directlyin T |
| S directlycontain T | S !directlycontain T |
In contrast to positional operators that provide functionality for expressing locality relationships between pieces, hierarchical operators provide functionality for expressing containment and inclusion relationships between piece.
The in operator returns the set of pieces in S that are contained in some piece in T. We define a piece s to be contained in a piece t if the starting position of s follows or is equivalent to the starting position of t, and the ending position of s is at most the ending position of t. Equivalently, the contain operator returns the set of pieces in S that contain some piece in T. As an example, to search for all the rows in the third table of a page, we write,
rows := P.Elem("TR") in P.Elem("TABLE")[2]
and to search for all the level two headings that mention the word UCI we write
titles := P.Elem("H2") contain P.Pat("UCI")
As for positional operators, we define two stronger, non-transitive operators, directlyin and directlycontain, that address direct containment and direct inclusion properties (between parents and their direct children in the parse tree of a page). For example, directlyin reduces the result x of the in operator to the "outermost" pieces of x that are not contained in other elements of x. The following example depicts the differences:
// retrieves all the subsections -> {LI1, LI2,
LI3, LI4, LI5, LI6}
subsections := P.Elem("LI") in P.Elem("UL")[0]
However, in many cases we are not interested in nested lists and would only like to retrieve the list items of the top-level list. Therefore we use the directlyin operator and write:
// retrieve only the toplevel subsections ->
{LI1, LI2, LI3, LI6}
subsections := P.Elem("LI") directlyin P.Elem("UL")[0]
A popular technique for searching in text is regular expressions [Fri97, IEEE92]. The limitations of regular expressions are twofold: they lack information about the structure of the document and they apply a "leftmost longest match" rule that is inappropriate for nested data structures. Searching for a table, for example, only returns a correct match if there is only one table in the document. This problem is described by Clarke and Cormack [CC97].
The prominent techniques for information extraction from structured text are tree matching, grammar parsing, and set algebras.
In tree matching, the search problem is reduced to searching a subtree in a parse-tree [Kil92]. The disadvantage of tree matching is the lack of orthogonality and compositionality regarding different views. Queries that search for character patterns cannot be mixed with searches for special structures in the document. Many of the tree matching problems cannot be solved in linear time.
Context free grammars pursue an approach in which the search pattern is specified as a context free grammar [ST96]. The result of a search query are all the substrings in the document that are accepted by the specified grammar. Context free grammars are very expressive in that they allow the definition of recursive search queries, but they suffer from the same problems as tree matching: they cannot express view-spanning and overlapping queries.
Several new techniques are based on set algebras [ST92, JK95, CCB94]. The Standard Document Query Language (SDQL) of the Document Style Semantics and Specification Language [DSSSL96] introduces the concepts of nodes and node-lists, which are loosely related to our pieces and piece-lists. Some of the WebL operators are provided and the user can also program new ones in a Lisp-like language. The data structures on which SDQL operates — called groves — are trees of nodes corresponding to elements in the document, and thus multiple views and overlapping elements cannot be modelled. PAT expressions [ST92] use a set-at-a-time algebra for manipulating sets of match-points and sets of regions. In contrast to the WebL search algebra, PAT expressions do not support an orthogonal and unified model. Sets of match-points and sets of regions cannot be arbitrarily composed and, in regard to document transformation, match points are not very practical since only the starting position of a match is recorded. However, most of these problems can be avoided. Clarke, Cormack, and Burkowski propose a compositional structured text algebra that is based on the notion of sets and ranges [CCB94]. Apart from the WebL set-algebra, this is the only other approach that supports overlappings between views. Although the model supports overlappings, the language does not. Additionally, nestings are avoided by selecting the minimal segments from those set elements that nest. Concerning runtime complexity, all of the set algebra problems can be solved in linear time if no two elements in a set overlap [NY96]. In the unlikely worst case, when all the elements in the set overlap with each other, the runtime complexity is quadratic in the number of elements in the set.
There are also efforts to specify low-level programming APIs that provide users with the functionality for document navigation and manipulation. The prominent activity in this area is W3C's document object model [DOM97]. In contrast to WebL, DOM is restricted to manipulating and searching single HTML and XML elements, does not provide a notion of character patterns, does not support multiple overlapping views, and inherently cannot perform computation.
There are also recent proposals for automating tasks on the Web. The Web Interface Definition Language (WIDL) [MA97] enables automation by mapping Web content into program variables using declarative descriptions of resources. WIDL provides features to submit queries and to extract features from the resulting pages. WIDL does not determine itself how search is to be done, but rather uses the Java Page Object Model [JS] or the Document Object Model [DOM97]. Page manipulation is not supported. WebSQL [AMM97] is a declarative query language for extracting information from the Web. The language emphasis is on extracting connectivity information from pages (i.e. pages that are two hops away from a specific page). WebSQL regards HTML documents as monolithic objects, and its analyses are limited to simple text matching techniques.
We currently plan to build larger applications with WebL and to extend it with additional libraries in the domain of information retrieval. One of the extensions we are currently investigating is to generate WebL scripts automatically by demonstration.
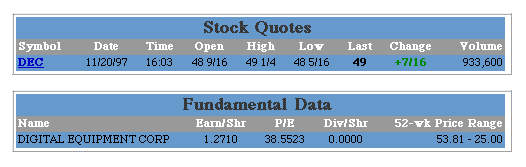
stockQuote := fun(symbol)
page := getpage("http://fast.quote.com/fq/quotecom/quote",
[. symbols=symbol .]);
(page.Elem("B") in
(page.Elem("TABLE") contain page.Pat("Stock Quotes"))[0])[1].Text()
end;
s := stockQuote("DEC")

shopAmazon := fun(title, authorfirst, authorlast)
books := [];
params := [. .];
params["author"] := authorfirst + " " + authorlast;
params["author-mode"] := "full";
params["title"] := title;
params["title-mode"] := "word";
params["subject"] := "";
params["subject-mode"] := "word";
page := postpage("http://www.amazon.com/exec/obidos/ats-query/", params);
items := page.Elem("dd");
every book in items do
info1 := substring(book.Text(),
`\w*([^/]*) (/ ([^/]*))?(/ [^\d]*(\d*))?`)[0];
info2 := substring(book.Text(), `Our Price: \$(\d*.\d*)`);
if (size(info2) > 0) and (info1[3] != "Audio Cassette") then
books = books + [[.
title = (page.Elem("a") directlybefore book)[0].Text(),
link = (page.Elem("a") directlybefore book)[0].href,
author = info1[1],
type = info1[3],
year = (select(info1[5],-2,-1) ? "N/A"),
price = info2[0][1]
.]]
end
end;
books
end
| [AMM97] | G.O. Arocena, A.O. Mendelzohn, and G.A. Mihaila. Applications
of a Web query language, in: Proceedings of WWW6, 1997, Santa Clara, California,
http://atlanta.cs.nchu.ed u.tw/www/PAPER267.html |
| [CC97] | C.L.A. Clarke and G.B. Cormack, On the use of regular expressions for searching text, ACM Transactions on Programming Languages and Systems, 19(3): 413–426, March 1997. |
| [CCB94] | C.L.A. Clarke, G.V. Cormack, and F.J. Burkowski, An algebra for structured text search and a framework for its implementation, Department of Computer Science, University of Waterloo, Canada, Technical Report CS-94-30, August 1994. |
| [CD97] | L. Cardelli and R. Davies, Service combinators for Web computing,
Research Report 148, Digital Equipment Corporation Systems Research Center,
Palo Alto, California, June 1997,
ftp://gatekeeper.dec.com/pub/DEC/SRC/research-reports/abstracts/src-rr-14 8.html |
| [CDF97] | Channel Definition Format (CDF), published by Microsoft Corp., September,
1997,
http://www.microsoft.com/stand ards/cdf.htm |
| [DOM97] | W3C DOM working group, Document Object Model Specification,
October 1997,
http://www.w3.org/TR/WD-DOM/ |
| [DSSL96] | Document Style Semantics and Specification Language (DSSSL),
ISO/IEC 10179, 1996,
http://www.jclark.com/dsssl/ |
| [Fri97] | J.E.F. Friedl, Mastering Regular Expressions: Powerful Techniques for Perl and Other Tools (Nutshell Handbook). O'Reilly and Associates, 1997. |
| [IEEE92] | IEEE 1992. Standard for information technology – Portable Operating System Interface (POSIX) – Part 2 (Shell and utilities) – Section 2.8 (Regular expression notation). IEEE Std 1003.2, Institute of Electrical and Electronics Engineers, New York, NY, 1992. |
| [JK95] | J. Jaakkola and P. Kilpelainen, SGREP, University of Helsinki,
Department of Computer Science, 1995,
http://www.cs.helsinki.fi/ ~jjaakkol/sgrep.html |
| [JS] | Netscape Corp., JavaScript Guide,
http://developer.netscape.com/library/documentation/communicator/jsgu ide4/index.htm |
| [Kil92] | P. Kilpelainen. Tree matching problems with applications to structured text databases, Ph.D. Dissertation, Department of Computer Science, University of Helsinki, Report A-19992-6, Helsinki, Finland, November 1992. |
| [MA97] | P. Merrick and C. Allen, Web Interface Definition Language
(WIDL), published by webMethods Inc., September 1997,
http://www.w3.org/TR/NOTE-widl |
| [NY96] | G. Navarro and R. Baeza-Yates, A class of linear algorithms to process sets of segments, in: Proceedings of PANEL'96, Vol. 2, 1996, pp. 671–682. |
| [ST92] | A. Salminen and F. W. Tompa, PAT expressions: an algebra for text search, Acta Linguistica Hungarica, 41(1–4): 277–306, 1992–93. |
| [ST96] | A. Salminen and F.W. Tompa, Grammars++ for modelling information in text, Department of Computer Science, University of Waterloo, Canada, Technical Report, CS-96-40, November 1996. |
| [XML] | World Wide Web Consortium, Extensible Markup Language (XML),
http://www.w3.org/XML/ |
 Thomas
Kistler received the M.S. degree in computer science in 1995 from
the Swiss Federal Institute of Technology (ETH) in Zurich, Switzerland.
He is currently a Ph.D. student in the Department of Information and
Computer Science at the University of California, Irvine.
His research interests include programming languages, compilers, and dynamic runtime optimization. Thomas
Kistler received the M.S. degree in computer science in 1995 from
the Swiss Federal Institute of Technology (ETH) in Zurich, Switzerland.
He is currently a Ph.D. student in the Department of Information and
Computer Science at the University of California, Irvine.
His research interests include programming languages, compilers, and dynamic runtime optimization. |
 Hannes Marais is a member of the research staff at DIGITAL's Systems
Research Center (SRC) in Palo Alto, California. He holds a Ph.D from the
Swiss Federal Institute of Technology (ETH) in Zurich. His interests
include user interfaces, programming languages, and information
retrieval applications on the Web. Hannes Marais is a member of the research staff at DIGITAL's Systems
Research Center (SRC) in Palo Alto, California. He holds a Ph.D from the
Swiss Federal Institute of Technology (ETH) in Zurich. His interests
include user interfaces, programming languages, and information
retrieval applications on the Web.
|