 |
 |
| Fig. 1. Uncorrelated, THETA = 0.8, 2 levels. | Fig. 2. Positive, THETA = 0.8, 2 levels. |
Philip S. Yu and Edward A. MacNair
IBM Research Division, T.J. Watson Research Center
Yorktown Heights, NY 10598
The recent increase in popularity of the World Wide Web (WWW) has led to a considerable increase in the amount of traffic over the Internet. As a result, the Web has now become one of the primary bottlenecks on network performance. When documents or information are requested by a user who is connected to a server via a slow network link, there can be noticeable latency at the user end. Further, transferring the document or information over the network leads to an increase in the level of traffic over the network. This reduces the bandwidth available for other requests. In order to reduce access latencies, it is desirable to store copies of popular documents or information closer to the user, from which the access latencies are more acceptable.
Web caching has become an increasingly important topic [AbSA95, BrCl94, CaIL97, Glas94, MaLB95, Mark96, Nabe97, PiRe94, ScSV97, WoAb97]. The caching can be implemented at various points on the network. It is often desirable to actually implement specialized servers in the network which are called caching proxies, which act as agents on the behalf of the client in order to locate the cached copy of a document if possible. More information on caching proxies may be found in [LuAl94, YeMc96]. Usually caching proxies serve as secondary or higher level caches, because they are concerned only with misses left over from client caches.
Generally speaking, a hierarchy of proxies can be formed between the Web servers and client stations. In a strict hierarchy, when a cache miss occurs, the proxy requests the missed object from the immediate higher level hierarchy through the caching proxy HTTP interface, as used in the CERN HTTP cache. An important issue affecting the effectiveness of the caching hierarchy is the duplication of the cached content in the hierarchy. If upon a cache miss, the child proxy caches each Web object passed down from its parent proxy which also caches the object, the amount of duplication between a child and its parent (and other higher level) proxies will be large and the number of distinct Web objects cached in the proxy hierarchy will be reduced. This issue also occurs in distributed caching in a client server environment [FCL92, LWY93]. In this paper, we focus on collaboration between parent and child proxies in a proxy hierarchy to reduce replication, when appropriate.
Recently, there has been various work on proxy collaboration to resolve a cache miss in the proxy hierarchy. In Harvest [BoDH94, ChDN95], the sibling or neighborhood caches are allowed to be interrogated upon cache misses. Squid [Wes97] which is derived from software developed on the Harvest project further enhances the neighbor selection algorithm. In either case, the caching decision at each proxy is a local decision. Each proxy does not track what is cached in other proxies to make its own caching decision. It makes caching decisions solely based on the local cache contents and/or object characteristics. Thus the focus of the previous work is on protocol or method [WesC97a, WesC97b] to locate a missed object in the hierarchy upon a cache miss, while the focus of our work is to reduce replication between a proxy and the higher level proxies in the hierarchy when making a caching decision. This is complimentary to the previous work on proxy collaboration.
Section 2 summaries some of the related work on caching algorithms. Section 3 describes the collaborative protocol to reduce content duplication. The performance results are presented in Section 4. A summary is given in Section 5.
There are various schemes being proposed on how to make this type of local caching decision. In [AbSA95, WiAS96], LRU thresholding and LRU-MIN cache replacement policies have been discussed to take object size into account in the decision making process. Abrams et al. [AbSA95], concluded that the LRU-MIN is the better policy over most workloads, since (unlike LRU-THOLD) there are no parameters to be chosen, and it achieves better performance most of the time, even when optimal thresholds are used for the LRU-THOLD policy. In fact, the optimal value of the thresholds to be used for the LRU-THOLD policy would completely depend upon the nature and type of the underlying data, which may vary from one system to another.
In Aggarwal et al. [AgWY96], and Aggarwal and Yu [AgYu96], a caching method for Web servers is described which takes into account the object size, time since last reference (or the reference frequency) and time since last update (or the update frequency) in making caching decisions. An admission policy is used to decide whether an object should be cached. Once a decision is made to cache the object, a replacement policy is used to select the object to be replaced.
The collaborative method discussed in this paper provides for a method of passing caching information down the proxy hierarchy for the lower level proxies to make improved caching decisions. The method does not require any additional message exchange or probing of cache contents among the proxy servers to get the caching information. The cache manager at each proxy will take into account the caching status at the higher level proxies in deciding whether to cache an object and which objects to be replaced in the replacement policy. One way to pass this caching information on an object in its header is based on an existing Web protocol know as PICS ("Platform for Internet Content Selection"). PICS specifies a method of sending meta-information concerning electronic content. PICS is a Web Consortium Protocol Recommendation [WCPR97]. PICS was first used for sending values-based rating labels, but the format and meaning of the meta-information is fully general. The PICS protocol can be generalized to pass the caching information down the proxy hierarchy.
The collaborative method is divided into three parts:
The admission control policy can also use additional criterion to assess the value of the newly accessed object. The object is admitted to the cache, only if it is more valuable than the set of objects it is going to replace (as identified by the replacement algorithm to be described next). Otherwise, the object will not be cached. One simple value criterion is the dynamic frequency [AgWY96, AgYu96], where the dynamic frequency of a set of objects is the sum of the access frequencies of each object in the set. (The access frequency can be estimated as the inverse of the time since last reference.) Assume that object Oi is with access frequency fi and size si. Furthermore, assume s3 equals to s1+s2. If the replacement candidates to admit O3 are O1 and O2, O3 will be cached only if f3 is larger than f1 + f2. So based on the dynamic frequency criterion, the admission policy reduces the expected number of misses.
In order to assess the object value, additional information needs to be maintained using an auxiliary stack. In addition to the identities or URL and the caching status at the higher proxy hierarchy, time stamps of the last access are also maintained in the stack. Since the admission policy needs the last reference time to estimate the object value, an object may be admitted to the cache only if it appears on the stack. Even if an object is not cached, it is still recorded in the auxiliary stack so that it can be cached upon the next reference if the next access time is relatively close. This auxiliary stack is maintained in LRU order, and since it contains only identities and a little information about objects rather than the objects themselves, the space required is relatively small, when the number of objects in the auxiliary stack is of the same order as that in the main cache. Further details can be found in [AgWY96].
We comment that more sophisticated caching policies can also be used. If the access times to the different caches in the proxy hierarchy are vastly different due to network bandwidth constraint, a proxy may want to cache an object, even if it is already cached by a higher level proxy in the hierarchy. In that case, we need to define the caching-value of each object that factors into the access cost. This can simply be the access frequency divided by the object size and multiplied by the access cost if not cached locally as in [AgWY96]. The replacement policy would then be to identify cached objects with lower caching values than the newly requested object. If there are enough lower caching-value objects identified to make room for the newly requested object, that object will be cached replacing the lower caching value objects identified. If the presence of a copy of an object in one of the higher level nodes in the proxy hierarchy can greatly reduce the access time from a lower level node, its caching-value function at the lower level node will be very low and is unlikely to get admitted into the cache.
In this section we compare the collaborative method with the independent method, where no caching information from the higher levels of the proxy hierarchy is passed down with the object. We are interested in examining the sensitivity of the two methods to various numbers of hierarchical levels, cache sizes, skews in frequency of objects, and changes in the work load. To focus on the content duplication issue, we consider a strict proxy hierarchy, i.e., when a cache miss occurs, the proxy requests the missed object from the immediate higher level hierarchy through the caching proxy HTTP interface. (No interrogation of neighboring proxies is considered which is an orthogonal subject.) Furthermore, it is assumed that the access time or cost will be small as long as the requested object can be satisfied by the proxy caching hierarchy. We use the overall hit ratio in the caching hierarchy as the primary performance measure.
We test the caching methods on objects of sizes uniformly distributed between 100 and 500000. That is, we assume that there are 5000 different objects, with one object of each size i. The objects were chosen to have a Zipf-like frequency distribution [Knut73]. The reason that we chose a Zipf-like distribution was to study the effect of frequency skew on the caching methods. Thus the frequency of object i is proportional to 1/PI(i)THETA, where THETA is the Zipf parameter, and PI is a permutation vector. By varying PI we can affect the relationship between the size and frequency.
We test three different relationships between the frequency of an object and its size.
The contents of the Web environment can be changing, and changes in the workload can affect the hit ratio. To simulate this, after an interval of a specified number of arrivals, referred to as the shift interval, we discard some number N of the least popular URLs and insert new URLs with fairly high frequencies. The new URLs are inserted in the frequency distribution at random in the first M positions. We used values of N = 20 and M = 60.
The simulation program has separate structures for every proxy server node in the hierarchy. Each node has its own cache and auxiliary stack. The Web page requests enter at the leaf nodes of the hierarchy and funnel up through the hierarchy until a cache hit occurs or the page is requested from the Web server.
The model contains a number of parameter values. We varied the cache size from 20 MB to 120 MB. We looked at three correlation schemes between object size and access frequency: uncorrelated, positive, and negative. The model allows the specification of the number of levels in the hierarchy. We simulated conditions where the contents of the caches at different levels were independent and where there is collaboration between the caches. The THETA for the Zipf distribution was varied from 0.0 to 0.8. The length of the shift interval for when to shift in new URLs was varied from 100 to 2000 arrivals, or no shifting at all.
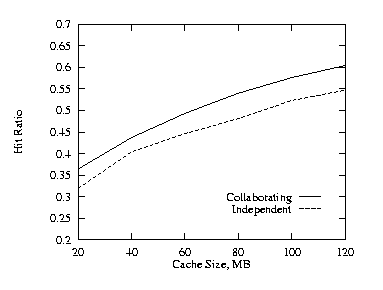
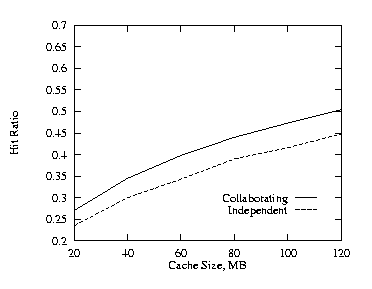
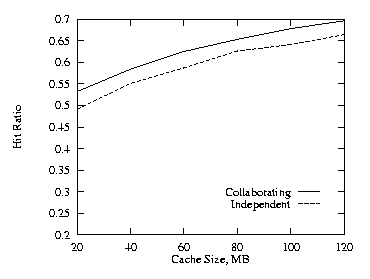
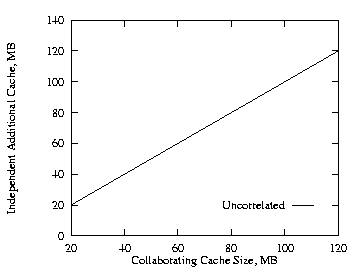
In this subsection we discuss the effects of cache size on the hit ratio when there are two levels in the hierarchy with equal cache size. At both levels, the cache size was varied from 20 MB to 120 MB. The plots compare the collaborating method with the independent method, and show the collaborating method is better. We used THETA = 0.8 for these runs. Figures 1–3 show the results for the uncorrelated, the positive, and the negative cases. Figure 4 shows the additional cache requirement on the proxy path that would be needed with the independent method in order to achieve the same hit ratio as with the collaborating method for the uncorrelated case. Here the x-axis is the cache size of the lower level proxy and the y-axis is the additional cache required by both the lower level and its higher level (parent) proxies under the independent approach, i.e., the y-axis represents the total amount of cache encountered by an object request on its proxy path in the hierarchy. From Fig. 4, the independent approach needs to increase the cache size at each level by roughly 50% in order to achieve the same hit ratio as the collaborative approach. There are similar cache requirements for positive and negative correlations.
|
|
| Fig. 1. Uncorrelated, THETA = 0.8, 2 levels. | Fig. 2. Positive, THETA = 0.8, 2 levels. |
 |
 |
| Fig. 3. Negative, THETA = 0.8, 2 levels. | Fig. 4. Additional cache, THETA = 0.8, 2 levels. |
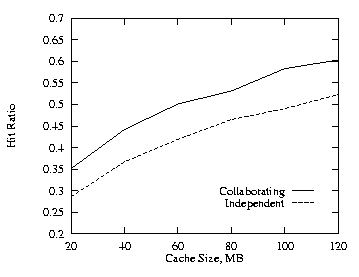
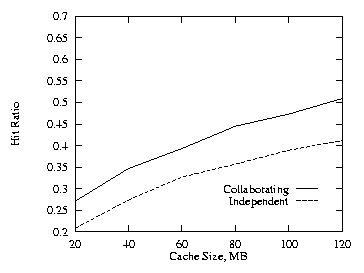
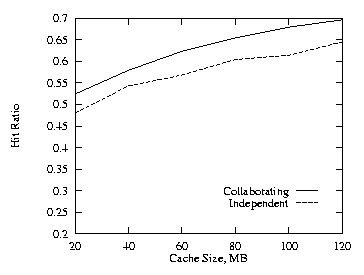
With three levels of cache the collaborating method performs even better than the independent method as compared to the two level runs. For these three level runs we used half as much cache at the higher two levels (the levels nearest the root nodes) as was used at the lowest level. This produces a total cache size for the three levels on the proxy path encountered by an object request through the proxy hierarchy equal to the total cache size encountered for the two level case. The cache size at the lowest level was varied from 20 MB to 120 MB. We used THETA = 0.8 for these runs. Figures 5–7 show the results for the uncorrelated, the positive and the negative cases. Figure 8 shows the additional cache requirement on the proxy path under the independent method in order to achieve the same hit ratio as with the collaborating method for the uncorrelated case. Here the x-axis is the cache size of the lowest level proxy and the y-axis is the additional cache required by the lowest level and its two higher level (parent) proxies. The cache size at each level needs to be increased by more than 50% under the independent approach.
 |
 |
| Fig. 5. Uncorrelated, THETA = 0.8, 3 levels. | Fig. 6. Positive, THETA = 0.8, 3 levels. |
 |
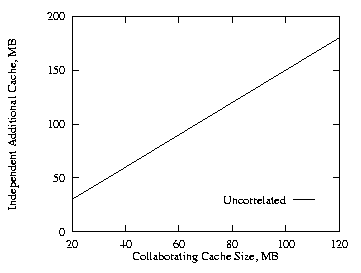 |
| Fig. 7. Negative, THETA = 0.8, 3 levels. | Fig. 8. Additional cache, THETA = 0.8, 3 levels. |
We next consider the case where all three levels have the same cache size. The cache size level was varied from 20 MB to 120 MB. Figure 9 shows the additional cache requirement on the proxy path under the independent method in order to achieve the same hit ratio as with the collaborating method for the uncorrelated case. Comparing Figs. 8 and 9, the additional cache required is 50% higher for this case.
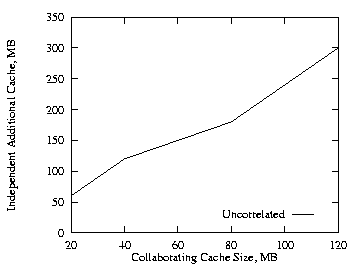 |
 |
| Fig. 9. Additional cache, THETA = 0.8, 3 levels same size. | Fig. 10. LRU-MIN uncorrelated, THETA = 0.8, 2 levels. |
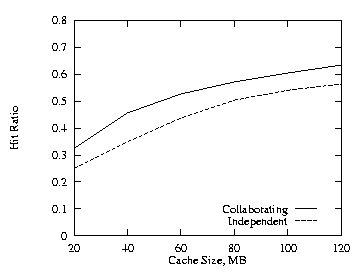
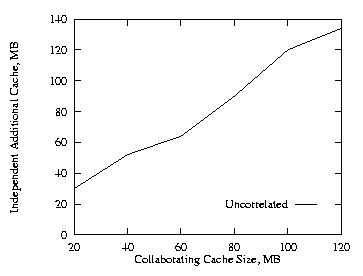
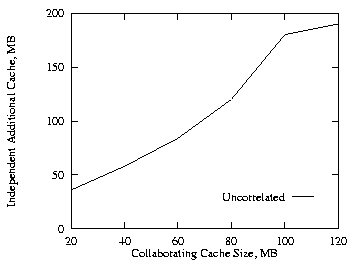
We also made the above runs using the LRU-MIN replacement policy [AbSA95]. Figures 10–13 show the comparable results. Comparing Figs. 13 and 4, the additional cache required are slighter higher for LRU-MIN. Compared to the LRU replacement policy, LRU-MIN is better for the negatively correlated case and worse for the positively correlated case. Except for small cache size, LRU-MIN is better in the uncorrelated case.
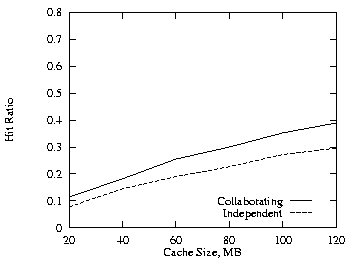 |
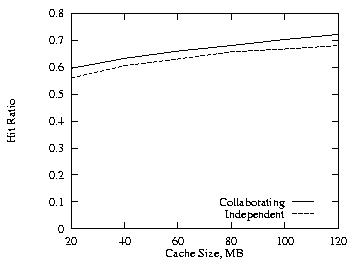 |
| Fig. 11. LRU-MIN, positive, THETA = 0.8, 2 levels. | Fig. 12. LRU-MIN, negative, THETA = 0.8, 2 levels. |
 |
 |
| Fig. 13. LRU-MIN, additional cache, THETA = 0.8, 2 levels. | Fig. 14. LRU-MIN, additional cache, THETA = 0.8, 3 levels. |
Next we consider the three level case. For this case, we used half as much cache at the higher two levels (the levels nearest the root nodes) as was used at the lowest level. The cache size at the lowest level was varied from 20 MB to 120 MB. In Fig. 14, we see the additional cache requirement on the proxy path under the independent method in order to achieve the same hit ratio as with the collaborating method for the uncorrelated case. Comparing Figs. 8 and 14, the additional cache required is again slightly higher for LRU-MIN than LRU. For the remaining of the paper, we will be focus on the LRU.
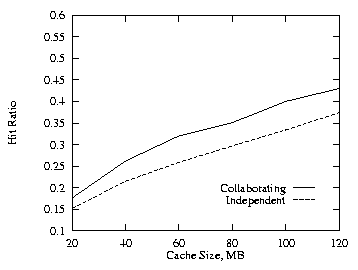
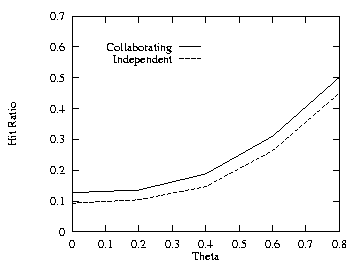
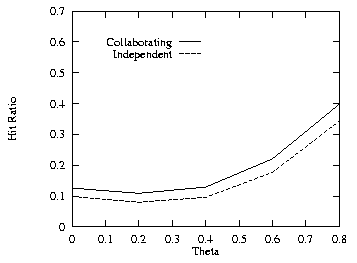
In order to see the effects of the skew on the Web page requests, we first set THETA = 0.6 and varied the cache size. Figure 15, which should be compared to Fig. 1, shows that a lower value of THETA results in a lower hit ratio. Next we set the cache size to 60 MB and varied THETA from 0 to 0.8. Figures 16–18 show the effects of varying THETA with two levels for the uncorrelated, positive, and negative cases. Figure 19 shows the additional cache requirement on the proxy path that would be needed with the independent method in order to achieve the same hit ratio as with the collaborating method for the uncorrelated case. The additional cache requirement first increases with the workload skew (THETA) and then comes down a bit.
 |
 |
| Fig. 15. Uncorrelated, THETA = 0.6, 2 levels. | Fig. 16. Uncorrelated, cache size = 60 MB, 2 levels. |
 |
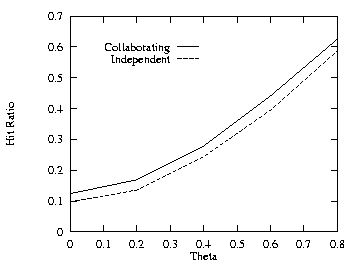 |
| Fig. 17. Positive, cache size = 60 MB, 2 levels. | Fig. 18. Negative, cache size = 60 MB, 2 levels. |
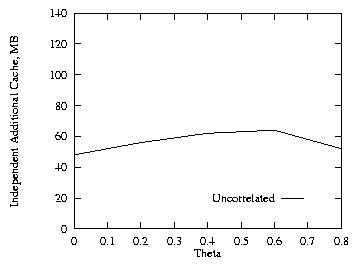
Fig. 19. Additional cache, varied THETA, 2 levels.
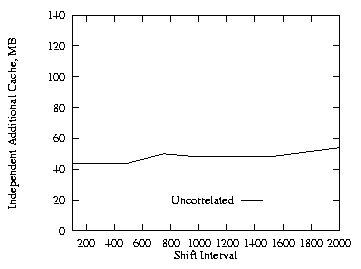
Up to this point no shifting of workload had been done in the runs. To see the effects of work load variations, we varied the shift interval from 100 to 2000 arrivals. We fixed the cache size at 60 MB and THETA = 0.8. Figure 20 shows the effects of varying the shift interval with two levels for the uncorrelated case. Except for a rapidly changing workload represented by a small shift interval, the improvement of the collaborating scheme is relatively stable. Figure 21 shows the addional cache requirement on the proxy path that would be needed with the independent method in order to achieve the same hit ratio as with the collaborating method for the uncorrelated case. The additional cache requirement is fairly constant and insensitive to the length of the shift interval.
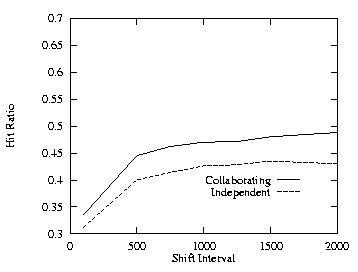 |
 |
| Fig. 20. Uncorrelated, THETA = 0.8, cache size = 60 MB, 2 levels. | Fig. 21. Additional cache, varied shift interval, 2 levels. |
In this paper we have examined the issue of reducing duplicated caching in a proxy hierarchy. A new collaborative approach is presented which passes caching information along with the requested object down the proxy hierarchy. We compared the hit ratios of the collaborative approach with the traditional approach through event driven simulations. Based on these experimental results, we conclude that the collaborative method is a practical and viable caching algorithm for a hierarchy of proxy servers to achieve more effective caching.
We would like to thank B. Schloss and P. Malkin for discussions about using PICS to support collaborative caching. We would also like to thank C. Aggarwal for discussions of the caching algorithm.
[AbSA95] M. Abrams, C. Standridge, G. Abdulla, S. Williams, and E.A. Fox, Caching proxies: limitations and potentials, in: 4th International World Wide Web Conference, Boston, MA, December 1995.
[AgWY96] C.C. Aggarwal, J.L. Wolf, P.S. Yu, and M. Epelman, On caching policies for Web objects, IBM Research Report, Yorktown Heights, NY, November 1996.
[AgYu96] C.C. Aggarwal and P.S. Yu, On disk caching of Web objects in proxy servers, IBM Research Report, Yorktown Heights, NY, November 1996.
[BoDH94] C.M. Bowman, P.B. Danzig, D.R. Hardy, U. Manber, and M.F. Schwartz, The Harvest Information Discovery and Access System, in: 2nd International World Wide Web Conference, Chicago, IL, 1994, pp. 763–771.
[BrCl94] H. Braun and K. Claffy, Web traffic characterization: an assessment of the impact of caching documents from NCSA's Web server, in: 2nd International World Wide Web Conference, Chicago, IL, 1994.
[CaIL97] S.J. Caughey, D.B. Ingham, and M.C. Little, Flexible open caching for the Web, in: 6th International World Wide Web Conference}, Santa Clara, CA, 1997.
[ChDN95] A. Chankhunthod, P.B. Danzig, C. Neerdaels, M.F. Schwartz, and K.J. Worrell, A hierarchical Internet object cache, Technical Report 95-611, Computer Science Department, University of Southern California, Los Angeles, CA, 1995.
[FCL92] M.J. Franklin, M.J. Carey and M. Livny, Global memory management in client–server DBMS architectures, in: 18th VLDB Conference, 1992.
[Glas94] S. Glassman, A caching relay for the World Wide Web, in: 1st International World Wide Web Conference, Geneva, 1994, pp. 69–76.
[Knut73] D. Knuth, The Art of Computer Programming, Vol. 3, Addison Wesley, Reading, MA, 1973.
[LWY93] A. Leff, J.L. Wolf, and P.S. Yu, Replication algorithms in a remote caching architecture, IEEE Transactions on Parallel and Distributed Systems, 4(11), 1993, pp. 1185–1204.
[LuAl94] A. Luotonen and K. Altis, World Wide Web proxies, in: 1st International World Wide Web Conference, Geneva, 1994; also in ISDN Systems 27(2), 1994.
[MaLB95] R. Malpani, J. Lorch, and D. Berger, Making World Wide Web caching servers cooperate, in: 4th International World Wide Web Conference, Boston, MA, December 1995, pp. 107–117.
[Mark96] E. Markatos, Main memory caching of Web documents, Computer Networks and ISDN Systems, 28, 1996, pp. 893–905.
[Nabe97] M. Nabeshima, The Japan Cache Project: an experiment on domain cache, in: 6th International World Wide Web Conference, Santa Clara, CA, 1997.
[PiRe94] J.E. Pitkow and M.M. Recker, A simple yet robust caching algorithm based on dynamic access patterns, in: 2nd International World Wide Web Conference, Chicago, IL, 1994.
[ScSV97] P. Scheuermann, J. Shim, and R. Vingralek, A case for delay-conscious caching of Web documents, in: 6th International World Wide Web Conference, Santa Clara, CA, 1997.
[WCPR97] Web Consortium Protocol Recommendation, http://www.w3.org/PICS.
[Wes97] D. Wessels, Configuring hierarchical squid caches, August 1997, http://squid.nlanr.net/Squid/Hierarchy-Tutorial/.
[WesC97a] D. Wessels and K. Claffy, Internet Cache Protocol (ICP), Version 2, RFC 2186, National Laboratory for Applied Network Research, UCSD, Sept. 1997.
[WesC97b] D. Wessels and K. Claffy, Application of Internet Cache Protocol (ICP), Version 2, RFC 2187, National Laboratory for Applied Network Research, UCSD, Sept. 1997.
[WiAS96] S. Williams, M. Abrams, C.R. Standridge, G. Abdulla, E.A. Fox, Removal policies in network caches for World Wide Web documents, in: Proceedings of the ACM SIGCOMM, 1996, pp. 293–304.
[WoAb97] R.P. Wooster and M. Abrams, Proxy caching that estimates page load delays, in: 6th International World Wide Web Conference, Santa Clara, CA, 1997.
[YeMc96] N.J. Yeager and R.E. McGrath, Web Server Technology: The Advanced Guide for World Wide Web Information Providers, Morgan Kaufmann Publishers, Los Altos, CA, 1996.
Philip S. Yu received the Ph.D. degree in E.E. from Stanford University. Currently he is manager of the Software Tools and Techniques group in IBM Thomas J. Watson Research Center. He has published more than 220 papers in refereed journals and conferences, and holds or has applied for 54 US patents. Dr. Yu is a Fellow of the ACM and the IEEE.
Edward A. MacNair joined IBM in 1965. He is a Research Staff Member in the Systems and Software Department at the IBM T.J. Watson Research Center. He is currently in the Software Tools and Techniques group.