Decision Systems Lab, Department of Business Systems
The University of Wollongong,
Northfields Ave.,
Wollongong, NSW 2522, Australia
cfe01@wumpus.uow.edu.au
Supervisors: Dr. Joseph G. Davis and Dr. Aditya K. Ghose
joseph_davis@uow.edu.au and
aditya@uow.edu.au
The efficacy of the existing search engines based on keywords and subject directories has been under severe strain. An alternative approach that enables the database querying of Web data is proposed in our research. We address some of the conceptual and practical questions dealing with, developing and structuring ontologies within well-defined domains such as health care, universities, etc. The ontology model, structured as an object relational database schema, is used to develop an object-relational database query search engine entitled "UniGuide".
This paper is organised as follows: in Section 2 we present a brief overview of the relevant literature. A model that captures the core constructs and their inter-relationships (ontology) of the university domain, the architecture and components of the prototype are presented in Section 3. The usage of the prototype from an end-user perspective is outlined in Section 4. Sections 5 and 6 devoted to further research directions and conclusions respectively.
The WWW can be considered as a huge semi-structured database, presenting all the problems implicit in semi-structured data [1]. Extracting the structure of every HTML document is a challenging issue as there is no predefined standard and no predefined schema. Often the schema can be derived only after the existence of data as compared to conventional databases where the schema is defined before the database is populated, even though the schema can be very large and constantly evolving.
One feasible approach is to create a structured layer on top of the semi-structured layer along the lines proposed in [5] attaching metadata that describes the kind of contents of individual Web pages. This would permit us to view relevant information about Web pages as a series of structured tuples of data. The approach is partly based on the assumption that metadata will/should be treated as first class objects [8] and will serve as the interface from the semi-structured layer (the WWW), to a structured database. Because of the exclusive focus on metadata, there is no need for strict typing over the contents of the HTML documents but only over the required metadata. The type of metadata to be attached to Web pages are basic meta tags, name/value pairs that describe properties of the document.
We list some of the most common deficiencies implicit to current implementations:
Structured database querying on the WWW was proposed by Han, Zaiane and Fu [5]. A critical problem with their approach is that it was too generic, trying to model a schema that could represent the whole semantics of the WWW. A more realistic approach is to follow a strategy of "divide and conquer", identifying and isolating an arbitrary number of domains where a model can be derived and extracted.
P. Atzeni et al. [2] have proposed a data model and a view language in order to represent, query and restructure the information stored in structured Web servers. Generally these servers are characterised by having their Web pages stored in databases and having normalised not only the content of their Web pages but the hypertextual structure (i.e. HTML tags) as well. This feature permits that attribute values can be extracted automatically using a text restructuring language.
Our focus is on domains where semantic models can be extracted therefore considered as logically structured but having an unnormalised hypertextual structure, making it almost impossible to extract automatically attributes of a given Web page using text restructuring programs. This impossibility justifies our approach of attaching structured meta-tags to Web pages in order to extract the attributes of entity-instances represented in Web pages.
The framework proposed in this paper is predicated on two significant assumptions:
The word ontology refers to things that exist in a particular domain. For instance, it is reasonable to expect that the university domain will always have information regarding research entities, academic departments, courses, research outputs, and so on.
Our proposed method involves isolating a distinct domain, modelling its ontology using an object-relational data model, and storing structured data provided by UniGuide Scheme meta tags attached to the domain Web pages into database tables. The UniGuide scheme meta tags are generated using forms-based input and finally attached to the required Web pages in order to bring about the possibility of an indexing robot to populate the database automatically. This database becomes a resource that can be queried by end-users in a fashion that current search engines cannot match, allowing the execution of structured SQL3 queries.
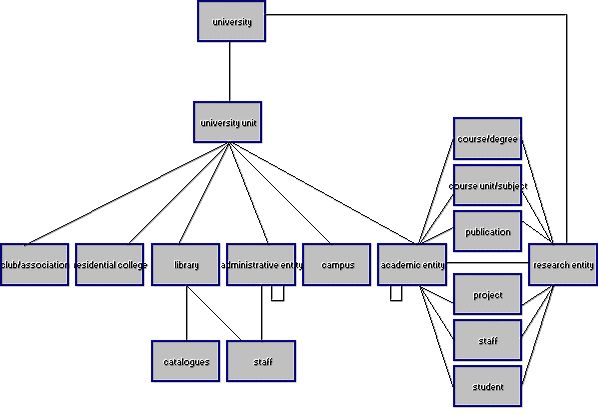
The object-relational model of UniGuide is shown in Fig. 1. It shows the current entities that have been modelled but the model is extensible. The objects in the model represent the Web pages of corresponding entities in the universities. Therefore there is a relation of 1:M relation (R[1:M]) between entity-instances and URLs. Generally, a Web page may contain many entity-instances but an entity-instance may have one and only one URL.
Fig. 1. Synthesised graphical representation of the object-relational model of UniGuide.
Finally we can distinguish relations between entities.
All entities contain a timestamp attribute in order to store date and time of last modification. This attribute will provide an effective mechanism for a customised indexing robot to decide whether a previously inserted entity-instance has changed or not, and may be updated or not. The same case applies for forms-based manual input.
A WWW search engine is defined as a retrieval service, consisting basically of a database, search software and a user interface [6]. UniGuide has similar components, with some subtle differences. The database (ILLUSTRA ORDBMS™), is an object-relational hybrid, with the capability to handle sets, arrays, abstract data types, object identifiers, references, relations, user defined functions, inheritance, rules, etc. [7].
The search software is based on SQL3 queries, SQL queries that can call to external C functions (ILLUSTRA API™) with the ability to run queries as well ("callback" feature), rules, ILLUSTRA Web Datablade® Applications and Javascripts®. For security reasons queries are actually generated on the server-side. Only the generation of the interface and the input/output of data are done on the client-side. The system comprises more than 100 rules used intensively in order to control referential integrity, constraints, uniqueness of sets, automatic actualisation of object references and hypertext links.
Our proposal is to include meta tags that simulate to be tuples or rows of data/metadata on a given range of particular Web pages. For instance one of the entities considered is academic_entity_course/degree, the following meta tag will express such entity:
<!-- mandatory columns marked with * --> <!-- Please Enter Values inside ' ' --> <meta name="academic_entity_course/degree" content= " (uni_id= 'University of Technology Sydney' [*university]), (academic_entity_type='Department' [*academic entity type]), (academic_entity_name='Computer Science' [*academic entity name]), (course_name= 'Bachelor of Science' [*course name]), (course_spec= 'Computing Science' [course speciality]), (course_type= 'Undergraduate' [course type]), (course_degree_type= 'Single' [course degree type]), (course_semesters= '6' [course semesters]), (course_credits= '144' [course credits]), (course_desc= 'This course aims to provide a sound education in all aspects of computing for students who intend to make a career in the profession' [course description])">
These meta tags can be generated automatically by the UniGuide Meta tag Generator. This may allow a customised indexing robot that indices only specific meta tags: UniGuide scheme meta tags.
There are three well-defined sub-sections: Submit URL, which allows the user to manually populate the database, Queries, and the Meta Tag Generator, that generates UniGuide Scheme meta tags. We shall describe only the query section.
Entities are grouped hierarchically by domain/sub-domains. When the user clicks on a given entity (left-frame), an HTML form is generated dynamically on the right hand-side (right-frame). The user can specify the range of values to search on the text boxes. The search options are contextual depending of the type of data of the column (i.e. LIKE option is activated only for columns of type text).
A simple query example follows: "Give me all the information available about Universities located in Sydney and are public". (see Fig. 2).
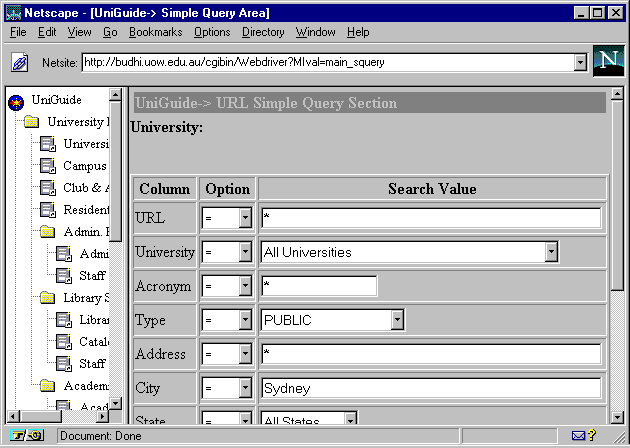
Fig. 2. UniGuide simple query form. Note: (*) accepts all values.
The output of a query is displayed in a tabular form. Other information includes the SQL query generated and the number of rows affected.
Some other examples can be:
From our viewpoint, predefined queries are complex queries, constructed in a similar way to parameterizable views. Queries can include summarised data, simulation of transitive closure, relations between entities, etc. Some examples of more elaborated queries can be:
End-users will configure and customise the required query. Our goal is to provide an interface similar to a typical Query By Example interface. Another option will be to provide a text area for advanced end-users to elaborate free SQL queries.
Developing an interface for UniGuide that fits the needs of both inexperienced and advanced users constitutes a challenge, especially in hiding the complexity of the schema. Also, currently we are in the process of experimenting with WebSQL [2] as an alternative to an indexing robot. With WebSQL we can generate a batch of controlled queries, retrieving only those Web pages that are within a particular domain, and contain the required meta tags. Other important issues are whether we should continue providing strict integrity rules to the system (i.e. reject tuples that violate referential integrity, or constraints) or should there be a natural evolution of the system towards "weaker" integrity rules, fuzzy referential integrity, etc.
A new kind of search engine has been proposed as an alternative to current implementations, with the ability to provide more structured and complex queries. This work is part of an ongoing research program exploring object-relational database approaches to searching the Web. The success of this project is partly dependent on the consensus of a given number of Australian Universities to adopt the use of UniGuide Scheme meta tags in order to populate the database automatically. Finally we conclude that although the proposed solution is domain-specific, wherever a model can be "extracted" and a standard can be established respect to metadata, our approach can be customised to adapt to the requirements of that specialised domain (i.e. ideal for large intranets: government departments, large companies, etc.).
|
[1] |
S. Abiteboul, Querying semi-structured data, in: ICDT 97 6th International Conference on Database Theory, Delphi, Greece, January 8–10, 1997, http://www-db.stanford.edu/~abitebou/pub/icdt97.semistructured.ps |
|
[2] |
G.O. Arocena, A.O. Meldelzon and G.A. Mihaila, Applications of a Web query language, in: Proc. of the 6th International World Wide Web Conference, April 7–11, 1997, Santa Clara, California, USA, http://www6.nttlabs.com/HyperNews/get/PAPER267.html |
|
[3] |
P. Atzeni, G. Mecca, P. Merialdo and E. Tabet, Structures in the Web, Technical Report RT-INF-19-1997, Department of Computer Science and Automation, January 1997, http://www.inf.uniroma3.it/tech-rep/inf-19-97.ps |
|
[4] |
K. Mahaligan and M. Huhns, A tool for organising Web information, IEEE Computer, pp. 80–83, June 1997. |
|
[5] |
J. Han, O.R. Zaïane, and Y. Fu, Resource and knowledge discovery in global information systems: a scalable multiple layered database approach, in: Proc. of a Forum on Research and Technology Advances in Digital Libraries (ADL'95), McLean, Virginia, May 1995. |
|
[6] |
A. Poulter, The design of World Wide Web search engines: a critical review, Program, 31(2): 131–145, April 1997. |
|
[7] |
M. Stonebraker and D. Moore, Object-Relational DBMSs: The Next Great Wave, Morgan Kaufmann Publishers, Inc., 1996. |
|
[8] |
W3C. Hypertext Links in HTML. W3C Working Draft 28-Mar-97, http://www.w3.org/TR/WD-htmllink-meta |