Object-oriented modeling of multimedia
documents
Thuy-Linh Nguyen,
Xindong Wu and
Sayed Sajeev
School of Computer Science and Software Engineering, Monash
University,
900 Dandenong Road, Caulfield East, VIC 3145, Australia
Thuy.Linh.Nguyen@csse.monash.edu.au,
Xindong.Wu@csse.monash.edu.au and
Sayed.Sajeev@csse.monash.edu.au
- Abstract
-
This paper describes an object-oriented model for paper-based
multimedia documents such as a textbook with embedded graphics. This
model is the first step towards building a manageable authoring system
for the Web, in which documents can be easily built, extended,
truncated, reordered, assembled and disassembled on a component basis,
and the document components can be reused. The model will also make
accessible properties which might be significant or important to the
user, especially in searching or classifying documents, such as the
document title and author. The model design is explained, and the
class hierarchy for the model is presented.
- Keywords
-
Object-orientation; Modeling; Multimedia; Documents
Electronic publishing has grown enormously since the coming of the
World Wide Web. An important characteristic of this new industry is
the dynamics of the publication. While the content of paper-based
documents is fairly fixed, electronic content can be changed at any
time. The current World Wide Web system however, does not provide ways
to manage such changes. A document is normally structured, but the Web
is not aware of this. The current practice is to either hard code the
document components into an HTML source file, or use the file system
of a server machine to express it. For instance one might put each
component in a separate directory, such as ../mybook/chapter1/ for
Chapter1, and and ../mybook/chapter2/ for Chapter2. Changes to a
structured document often need to be synchronised among its
components. For example, the removal of Chapter1 would require all
following chapters to be renumbered, all references to Chapter1
removed, and a new table of contents generated. These maintenance
operations are typically carried out manually using commands and tools
native to the server machine, ie. orthogonal to the Web [ING95]. If
the file system has been used to represent the document structure,
manipulations to Web resources are required in both the file system
and the Web system, which are essentially two disjoint domains
[ING95]. This process is expensive and prone to mistakes and
inconsistencies. Its problems are well documented [ING95, GEL97,
ING97].
This paper presents a manageable multimedia document model, using the
proven object-oriented technology. Documents can be built, extended,
truncated, reordered, assembled and disassembled on a component basis,
and document components can be reused. The model also makes accessible
properties that might be significant or important to the user,
especially in searching or classifying documents, such as the document
title and author.
The design criteria of the model are completeness, compactness, and
simplicity. The model attempts to cover all types of existing
paper-based documents. The number of classes, their attributes and
methods are kept to the minimum. Generic classes are used wherever
possible, distinct document types may be merged into one class, and
convenience functions and attributes are ideally kept to none. The
system derived from this model is meant to be an open system,
ready for use by the public. Implementations of this specification
must be easy for general users to carry out. This model is designed
for electronic publishing, but is based purely on traditional
paper-based publishing. Factors relating to hyperlinks and distributed
environments are not covered. It is to be used as the base for
integrating traditional publishing into electronic publishing.
2. The Multimedia Document Model (MDM)
2.1. The MDM classes
The MDM model is object-oriented. Figure 1 shows the object diagram of
the model, using the Object Modeling Technique (OMT) notation [RUM91].
In this model, a document is decomposed into objects, holding its
internal state and a well-defined behaviour. The internal state of an
object is defined by a set of attributes and its behaviour by a set of
methods.
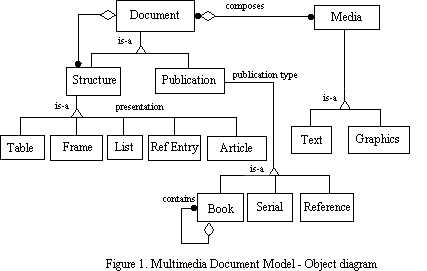 A document object represents the entirety of a
publication, and is constructed by the basic building block of
structure. Instances of the document class correspond to
the loosest form of publication. It is designed to cover all types of
documents in the traditional document system, be it an unbounded
draft, letter or bounded journal. The document object can be
composed of only structure objects, or some structure
objects and some media objects (structured documents), or just
media objects (unstructured documents). The only two attributes
that require non-null values are contents, as we do not allow
empty documents, and title, which is used to enforce that its
content is semantically complete, ie. it must not contain just
fragments of text or graphics which are not comprehensible to human
readers. The title also serves as a mnemonic identifier to
human readers, but does not have a significant meaning to the system,
and is not required to be unique in any domain.
A document object represents the entirety of a
publication, and is constructed by the basic building block of
structure. Instances of the document class correspond to
the loosest form of publication. It is designed to cover all types of
documents in the traditional document system, be it an unbounded
draft, letter or bounded journal. The document object can be
composed of only structure objects, or some structure
objects and some media objects (structured documents), or just
media objects (unstructured documents). The only two attributes
that require non-null values are contents, as we do not allow
empty documents, and title, which is used to enforce that its
content is semantically complete, ie. it must not contain just
fragments of text or graphics which are not comprehensible to human
readers. The title also serves as a mnemonic identifier to
human readers, but does not have a significant meaning to the system,
and is not required to be unique in any domain.
A structure object, inheriting the aggregation relationship to
itself from document, can in turn contain itself recursively.
A document is therefore composed of a recursive chain of
structure objects, which can be assembled, disassembled, and
reordered, allowing for the whole document to be modified, extended,
or truncated on a component basis, without losing the coherence of its
overall structure. Structure is the generic class for all
structural components of a document, such as volumes, parts, chapters,
and sections. Our model therefore allows for organisation such as a
volume containing several parts, a part containing several chapters, a
chapter containing several sections, etc., commonly found in
paper-based documents. Since all these structural components share the
same properties and behaviour, it is most appropriate to have one
single representative class. This design makes the model simpler and
more compact. It also gives authors more flexibility when defining
their own document since the model does not differentiate between
various structural components.
The model also makes available presentation components, by defining
them as children classes of structure. A structure
object can thus be presented in a number of different formats: text
chunk, table, frame, list, reference entry,
and article. Text chunk is a sequence of one or more
ASCII characters. It is essentially a section of text, with a heading
and one or more paragraphs. Table, frame, list, reference entry
and article, are all defined in common sense as have been used
in the traditional publishing industry. Text chunk is the
default presentation for a structure or document
object. That is, with reference to Fig. 1, when a structure
or document object is resolved to one or more media
objects (see Section 2.2 for explanations about document
resolution), it will assume a text chunk presentation. If an
object of a descendant class of structure is resolved, it will
take other presentations according to the class to which it belongs.

Media objects hold the real contents that make up the
whole system. Their content is unstructured, raw materials that will
be used to fill in the document objects or their structural or
presentational components. The actual data type of the content will be
defined in the offspring classes of media. In the current
version of MDM, it can be either text or graphics. This content can be
semantically incomplete, ie. not meaningful to human readers. For
example, it can be a fragment of text, which is a part of chapter of a
book. This semantic incompleteness is reflected in the object design
by the fact that no title or heading is required for an
object of the media branch. Offspring objects of the media
class, representing different media types, can therefore be inserted
at arbitrary places in a document object. This concept is
applicable to all kinds of media types, although at the moment it is
meaningful to the text object only. Consider a chapter in a textbook
with an image inserted halfway. If the chapter is defined as one
document object, then it must consist of three media
objects of two broken text pieces and one graphics (see Fig. 2).
Publication is the generic class for all types of published
materials. In real life it generally corresponds to any publication,
normally bounded, that can be identified by an international
identification number, usually ISBN (International Standard Book
Number) or ISSN (International Standard Serials Number). There are
more specific classes inherited from Publication, designed to
handle other specific features of different document types. All of
these classes are designed based on the existing paper-based document
system as found in most libraries nowadays. For compactness and
simplicity purposes, several library categories are merged into one
single class in our model.
Book includes such publications as textbooks, storybooks,
manuals (non-references), the Bible, and picture books. A book
object normally has only one authorship (with one author and possibly
co-authors, but all cooperating in one work) and typically contains
items that are closely related to each other. For example, there are
normally references to other sections from one section in a
textbook. A book is typically a non-collective, non-recursive
entity. Some exceptions are the Bible, a book of short stories, a
condensed book, etc, which can contain other books.
Serial includes magazines, newspapers, journals, conference
proceedings, research reports, bulletins, newsletters, etc. They are
published periodically and all have some method for sequential
ordering, either by numbers or dates, and their contents are
collectively authored. They typically contain a collection of
independent writings, each of which is complete and comprehensible
without the need to refer to or understand other items in the
collection (although they can use other references outside the
collection as references). Some examples are articles, technical
papers, reports, lecture notes, advertisements, and meeting notices. A
collection of serials can be bound into a volume, identified by a
volume number.
Reference covers all reference materials, such as dictionaries,
handbooks, calendars of events, directories, and reference manuals.
They normally contain many reference entries, which can be grouped
into sections. Each entry usually consists of a reference term and its
explanation or specification. The reference class has a special
method, sortEntry().
The design of our model allows the mapping of all existing document
types. The book, serial and reference classes cover most library
printed materials. The publication and document classes account for
any other types, both published and unpublished. Each offspring class
of publication is actually a merge of many library categories, and new
classes are created only if there are important properties or methods
that need to be distinguished between them, such as the issue number
for serial objects, or the sortEntry() method for
reference objects. The model is thus both complete and compact,
since it covers all document types while the number of classes are
kept to minimal. Simplicity is achieved by compactness, and also by
the fact that the model design is based on the familiar and
well-developed traditional paper-based system, with many defacto
standards for structural and presentational components. This provides
a solid base, making the model robust to changes and simple to use.
2.2. Document resolution
Objects of the document class (and all objects of its offspring
classes) are composed of text and graphics objects,
which belong to the offspring of the media class. Every object
of the document branch must be resolved to one or more
objects of the media branch. In other word, the document
object can be considered the virtual container of the
system contents, holding only references to media objects,
which keep the real contents of the system. The need for
separating between media and document is to support the
three views of the document (see Section 2.3), making both media and
structural components accessible. It also allows for media
objects, which are pieces of text or graphics to be reused in more
than one document. This feature shall reveal an even more important
role in the distributed environment, where virtual contents can be
distributed.
2.3. Three views of the MDM
In the MDM, a document is viewed in three dimensions:
structure, media and presentation.
In the structure view the document is broken up into building
blocks, such as volumes, parts, chapters, sections, and
paragraphs. The decision of the level of granulity is the result of a
tradeoff of two major influencing factors: the simplicity and
compactness of the whole system, and the dynamics of the component
under consideration. In Fig. 1, the structure view is represented by
the generic class structure. This class is defined to cover up
to the section level (see Section 2.1). Thus in normal terms we can
say that the basic building block of the MDM is section. (Note
that in our model the term section has been changed to the
generic term structure). This view makes the structural
components of the document accessible, allowing for the document to be
managed structurally on a component basis (see Section 2.1).
The media dimension accounts for different media types that
compose a document, such as text, graphics, sound, and video. Only
text and graphics are considered in this system, since it is
restricted to the current paper-based document system. Other media
types however, can be easily added in the next version of MDM, because
of the extensibility characteristic of object-oriented systems. In
Fig. 1, the media view is represented by the class media and
its offspring classes. This dimension is a necessity in the multimedia
environment. As media components are made independent entities,
separate from structure components, each can have its own
properties and behaviour specific to its media type, and their layout
in relation to other objects can be controlled. For example the
alignment of a graphics object can be specified relative to other text
objects surrounding it with the hAlign and vAlign
attributes. The separation of media from document also
allows for media objects to be reused in more than one
document. This is especially useful in the World Wide Web environment
where graphics such as a company logo and a navigation bar, can be
included for every Web page. This sense of separation is stronger in
the Web, where objects of different media types must be saved in
separate files and treated independently, for example, text is stored
in text files, and graphics in GIF files.
The presentation view looks at various ways in which
information is presented to human readers. Presentation has only
limited support in the current version of MDM. Other format and
presentation issues are intentionally left out for the next version,
or for use of other mechanisms such as the Cascading Style Sheet (CSS)
[CSS97]. All the offspring classes of the structure class, table,
frame, reference entry, and article, represent the
presentation view in our model. The presentation view makes it
possible to present structural components in different formats.
In summary, the three dimensions together make the document components
accessible in various ways, allowing for the document to be assembled
or disassembled structurally, its layout suitably controlled for
components of different media types, and various formats can be
presented.
3. Related work
There have been several research efforts in the literature on
integrating object-orientation into the Web to solve management and
maintenance issues, each with its own emphasis on a different
perspective. The WebComposition model [GEL97] mentioned
above uses databases to hold Web application components, which
are non-standard, must be finely defined, and will likely be extended
indefinitely for new components. Our model uses only features
native to the Web, which does not require high-end tools or systems for authoring and management processes. It defines classes based on the components of standard paper-based document, which are more generic,
compact, stable and simple. The W3Object [ING95] on the other hand, encapsulates objects based on their functionalities, not resource components, and must also be extended when new functions are developed. The
WebObjects [NEX97] also uses non-native Web systems to manage
Web application components. Of the three, our model is more compact, simple, and publicly open, a feature that has won HTML the popularity over the world.
Other related works include the metadata initiatives such as the Dublin Core (DC) [W3C98]. DC and our work are similar in an interesting aspect in that they both use data to describe data. A document object holding information about itself is essentially a set of metadata. DC and MDM however, come from two completely different aspects of software engineering, with two different types of model. MDM also has a broader goal for the management and maintenance of the whole system, not just for resource discovery and cataloging as does the DC.
4. Conclusion
An important characteristic of electronic publishing is the constant
changes of contents. Information about content design and structure
however, is often hard coded in the document or inappropriately
represented by the underlying file system on which the document is
housed. As a result, the maintenance of these resources is expensive,
difficult and error prone. Our MDM model addresses these issues by
making accessible the structural, presentational and media components
of a multimedia document, allowing for the document to be presented,
managed and maintained on a component basis. Integrated into the World
Wide Web, it will provide an information management and maintenance
layer that the current Web system lacks. It can be implemented as a
servelet operating inside the http server, transparent to the Web,
which can take MDM objects and generate HTML code. This approach has
proved workable in a similar project, WebComposition model
[GEL97]. Alternatively we can make browsers to parse and render MDM
objects directly, eliminating the use of a large part of HTML code
embedded in Web resources.
References
[RUM91] Rumbaugh, J., Object-Oriented Modeling and Design, Prentice Hall, 1991.
[CSS97] Cascading Stylesheet (CSS2) Specification, W3C Working Draft, 1997, http://www.w3.org/Style/
[GEL97] Gellersen, H.-W. et al., WebComposition: an object-oriented
support system for the Web engineering lifecycle, in: Proc. WWW6 International
Conference, 1997,
http://www6.nttlabs.com/HyperNews/get/PAPER232.html
[ING95] Ingham, D.B. et al., Bringing object oriented technology to
the Web, in: Proc. WWW4 International Conference, 1995,
http://w3objects.ncl.ac.uk/pubs/bootw/; also at
http://www.w3.org/pub/Conferences/WWW4/Papers2/141/
[ING97] Ingham, D.B. et al., Supporting highly manageable Web
services, in: Proc. WWW6 International Conference, 1997,
http://w3objects.ncl.ac.uk/pubs/shmws/; also at
http://proceedings.www6conf.org/HyperNews/get/PAPER27.html
[NEX97] WebObjects, http://www.apple.com/webobjects/
[W3C98] W3 Consortium, http://www.w3.org/