
Arun Katkere
-
Jennifer Schlenzig
-
Ramesh Jain
Praja, Inc.
5405 Morehouse Drive, Suite 330
San Diego, CA 92121, USA.
katkere@praja.com, schlenz@praja.com, jain@praja.com,
http://www.praja.com
The World Wide Web (WWW) as a mechanism for providing access to "real world" information in the form of live or recorded video and audio data is becoming more common. However, access to this information is limited to simple playback. In this paper, we present an architecture and a WWW implementation of Multiple Perspective Interactive Video, (MPI Video), an infrastructure to access these new forms of information in more useful ways. Using an information system to merge the sensory and virtual data into a coherent, accessible, dynamic database, MPI Video provides content-centric interactivity. Multiple users can access this database to retrieve disparate information at the same time. Most interactions occur in a three-dimensional interface (a natural medium for interacting with real-world data) which combines relevant real and virtual components. This approach is useful in several applications including teleconferencing, remote monitoring, and interactive entertainment. In this paper, we present the concepts of MPI Video and describe the latest implementation, a Web-based Remote Access, Monitoring, and Presence (RAMP) system.
The sharing of information among people located across different space and time zones has been a strong motivation behind the World Wide Web. Clearly the Web has been extremely successful in achieving this goal so far. It has become a major mechanism for collaboration and it appears that what we have seen is only the beginning. In this paper we present an advancement of collaboration techniques that allows for people to share not only virtual documents and virtual objects, but also real objects and environments by introducing telepresence mechanisms. The proposed approach uses content-centric interactivity to provide a smooth merger of real and virtual environments and content-based access to real (and possibly live) data. We describe the latest implementation of Multiple Perspective Interactive Video [3], MPI Video, as an example of a system which provides content-centric interactivity for remote events, such as sports broadcasts, that are typically captured from multiple perspectives.
The current WWW is dominated by documents. Multimedia documents are becoming more prevalent, but these are typically authored by hand. The documents may represent three-dimensional (3D) dynamic worlds but are based on hand-built models. VRML[7] has played a key role in bringing Three-dimensionality to the web by providing a standard means of describing these "virtual worlds." At the same time, cameras are becoming more prevalent in the real world. The reduction in the cost of cameras and computers is leading to multiple cameras being deployed in the same environment providing one with the capability to select a particular camera to view a region of interest. It is becoming an accepted fact that soon cameras will be in many public places. Not surprisingly, the next major change is said to be the exploitation of the Web as a distribution system for real-time multimedia content[16]. Many groups have begun solving the problems of Web-based video delivery [11, 1, 13]. Consequently, the first generation of WWW tools for streaming video and live video are now available. Many individuals and groups have started using these tools to place live cameras on the Web. A recent check of an index of live cameras on the Web[12] revealed hundreds of entries.
Just as search engines were required to handle the deluge of text-based documents, this next wave demands sophisticated access tools. Simple VCR-like playback mechanism is as lacking as hyperlink-based navigation was for the text-based static Web. MPI Video provides the infrastructure to access sensor-derived data, live or archived. Using an information system to mediate between the variety of sensors (e.g., cameras, microphones) and the multitude of users, MPI Video provides powerful content-centric interactivity to smoothly combine the real world with the virtual world. For example, a user can select a viewpoint of choice and can also navigate at the desired speed within the 3D scene without disturbing the events in the environment. Mechanisms to overcome the limitations and misconceptions due to our single perspective are provided by the information assimilated from multiple sensors and a priori known data.
Many issues which arise in implementing MPI Video are dependent on specific applications (e.g., remote surveillance and monitoring, telepresence, education and training, or entertainment), but there are several core issues that must be addressed to successfully implement any application. In this paper, we present a brief overview of MPI Video, explain concepts of content-centric interactivity and gestalt vision[2], and the current implementation.
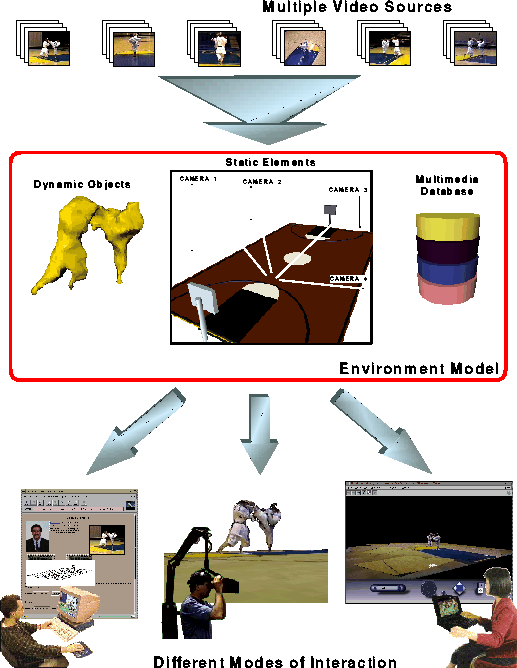
Figure 1. The MPI Video conceptual architecture: a task-specific environment
model is constructed automatically from the multi-perspective,
multi-modal data. The environment model is used to personalize the way the
underlying data are presented to the user. The user has access to both
the uninterpreted data as well as the MPI Video-generated
abstractions.
Multiple Perspective Interactive Video provides a framework for the management of and interactive access to multiple streams of video data capturing different perspectives of related events[6]. MPI Video has dominant database and hypermedia components which allow a user to not only interact with live events but to browse the underlying database (which is automatically generated from the sensory data) for similar or related events or to construct additional queries. By processing the video to extract information about the captured scenes, MPI Video allows a user to interact with the system on a semantic level. This differs greatly from typical scenarios where the queries are based on keywords entered by a person and are subject to his/her interpretations. Instead, our users are able to make queries base on the actual activity occurring in the video data. For example, in a football application the user may ask to see the closest view of the quarterback. The response to the query is an MPI Playback, which includes automatic switching of cameras to provide the best view, where what is best is defined by the user[6].
This new camera-switching capability represents a shift in access mechanism. In many applications, such as sports broadcasts, traffic monitoring, and visual surveillance, multiple cameras are placed at strategically selected points to provide an operator a global view of events. In all these applications, different cameras are fed to one location where all of the views are displayed. In a broadcast application, one of these views is selected by the editor or producer of the program to be broadcast to consumers. Our system eliminates this centralized control without transferring the tedious task of camera selection to the consumer. MPI Video system handles the low-level control in response to high-level requests by the user.
Content-centric interactivity can be implemented by combining the tools and techniques that are being developed in different aspects of computer science, including evolving information systems and the delivery mechanisms created by the network infrastructure commonly available today. The image stream from each camera is processed to extract task-dependent information from it and is fed to an information system, called the Environment Model (EM). The EM is a coherent, dynamic, multilayered, three-dimensional representation of the content in the video streams. It is this view-independent, task-dependent model that bridges the gap between two-dimensional image arrays, which by themselves have no meaning, and the complex information requirements placed by users as well as other components on the system. The environment modelis an active real-time database containing spatial and object information at several levels of abstraction. The assimilated information contained in the environment model allows us to achieve gestalt vision[2] where the whole is greater than the sum of the parts.
The EM information system offers two major facilities. A user may interact with the EM at many different levels of information abstraction. A user can view the information of interest in a visualization mode preferred by the user for that information, ranging from simple text to immersive environments. Also, a user can view any information of interest from any viewpoint of interest. Thus the human multiplexor is removed and the user becomes the producer of information. Another major advantage is that the EM can be used by several users to view different information at the same time. Because the EM is an information system, it can be designed to reside at one or multiple locations and satisfy information or entertainment needs of a diverse, distributed group of users at one time.
The transformation of video data into objects in the environment model has been an ill-posed and difficult problem to solve. With the extra information provided by the multiple-perspective video data, and with certain realistic assumptions (that hold in a large class of applications), however, it is possible to construct accurate models in a robust and quick fashion. In our current MPI Video systems, we assume that certain information is available[5]: In addition, we use the following sources of information extensively:
New interface mechanisms and metaphors are required to allow proper interfaces for content-centric interactivity and gestalt vision. We believe that in addition to menu-based selections, new methods of spatiotemporal interactions will be required to allow intuitive access to the objects and events in the scene[4].
Expressiveness of interaction is fundamental to the design of any user-interface model. This expressiveness can be achieved by adopting a 3D information visualization metaphor as used by several database browsing and visualization groups[14]. Our motivation for developing a three-dimensional interface for MPI Video stems from the intuition that if a user were given a three-dimensional world changing dynamically with time, he or she would meaningfully operate in this world (i.e., can specify an object, a space, or a search condition) only when he or she has the ability to navigate and act within it.
Some of the areas in which a three-dimensional interface would be extremely useful are:
Some of the specific instances of the three-dimensional interface are:
The environment model, presented in Section 2, forms the basis for the creation of this three-dimensional interface. Components of the interface reflect the current state of the environment.
With the latest VRML standard, VRML 2.0[15], the ability to model and interact with dynamic three-dimensional scenes on the WWW has increased manyfold. It has enough expressibility to specify the three-dimensional model-based interactions described in the previous section. MPI Video uses VRML for representing scene geometry- static scene geometry, camera geometry, iconic representations of the dynamic objects, overlays such as trajectories, velocity vector, etc.- and for providing user interactions such as drawing regions of interest, selecting objects of interest, sketching queries, etc.
Virtual worlds use the concept of avatars to display positions of objects in the virtual world. An avatar allows a user to see the relative positions of objects in the space. This aids navigation and allows more natural interactions with other users who may be literally thousands of miles and several time zones away. Most of the avatars are currently preselected objects that have a limited set of motions and facial expressions. Though current avatars are very limited in their functionality; most are only adequate to show the relative position of objects. It is clear that soon machine-vision techniques will be combined with the graphics techniques to create avatars that will be related to the facial expressions of a user and may even look like the user, if so desired.
Since we are dealing with real worlds and are displaying real scenes, the objects must look realistic. The best avatar for a person in this situation is the person himself. Thus, depending on the application, one should try to use the model of the person, or pictures of the person, as his avatar and show all facial expressions and motions for the person. This can be done in some situations, but in others it may be very difficult.
The interface should provide powerful and flexible navigation mechanisms, much like video games. In most telepresence applications, it is essential that a user feels as if he is navigating through the environment following all physical rules. In some cases, navigation may involve just expressing a desired point of view with respect to some objects or events. This will usually require the combination of visual mechanisms offered by VRML and symbolic methods.

Figure 2. Layout of the office used for this example and the location of
the cameras in the scene.
Our test environment is an office with two rooms. Six cameras are used to cover the environment. The layout of the room and cameras is shown in Figure 2. Figure 3 shows the high-level architecture of the current implementation. Different components of this architecture roughly correspond to the different components shown in the conceptual architecture (Figure 1).
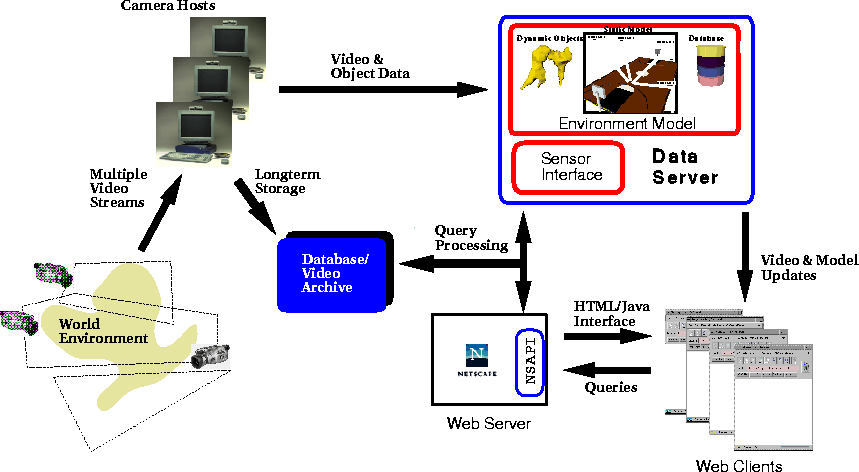
Figure 3. Overview of the WWW version of MPI Video.
The current implementation consists of the following components:
The current implementation uses "Motion JPEG"[10] for video compression and RTP/RTCP[9] for video delivery. Use of other compression algorithms more suited for video is being investigated.
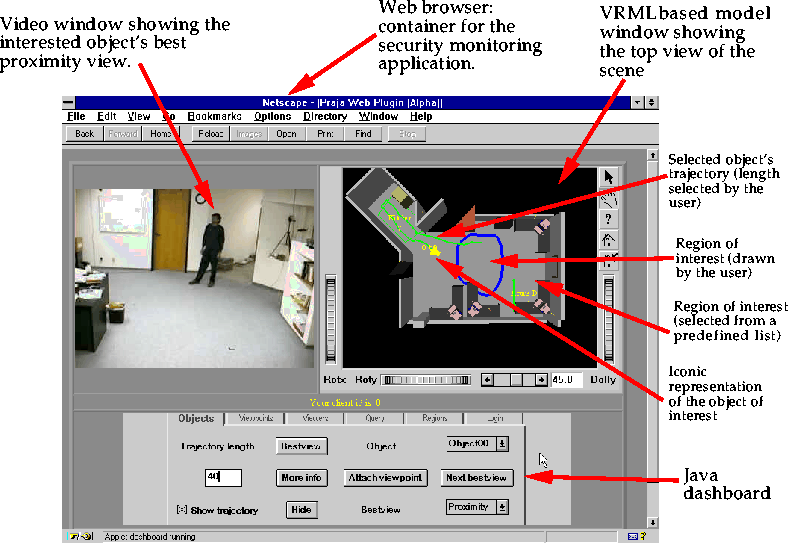
Figure 4. Sample screen of the MPI Video client showing the different
components of the interface and some queries.
The client interface to the system is shown in Figure 4. This interface allows the user to perform a variety of queries related to the position and velocity of the dynamic objects (people) in the environment. As illustrated in Figure 4, queries include requesting notification when a person enters a selected region and maintaining the trajectories of selected objects. The system also allows the user to request several different types of best view (e.g., proximity, frontal, etc.). The result of a proximity best view request is given in Figure 5.

Figure 5. An example of "best proximity view": A sequence of camera changes
that occurred when the user requested that the view from the closest camera to the
selected object be shown.
The World Wide Web has proved itself as an important means of distributing many forms of information. The next step is to make that information more accessible. MPI Video includes an environment model which stores information in such a way that there is a smooth merging of real and virtual worlds. Queries to the system are based on the user's interest in the content of the video rather than through predefined keywords that tell more about the person designing the system than about the video they are meant to describe. The user can access the information in several ways, including via the World Wide Web. MPI Video provides motivation to the many people working on web-based video delivery that moves beyond video-on-demand and point-to-point video conferencing. Future applications of MPI Video include telemeeting systems which merge virtual- and real- world information to yield a productive, collaborative environment of people, objects, documents and other assorted media. In addition, this technology can remove the elitist nature from surveillance systems by permitting wide access to the video data covering public spaces. It is expected that new forms of entertainment will be discovered as the power and flexibility of the Environment Model and MPI Video are explored and exploited.
Several people have assisted in developing and implementing the ideas reported in this paper. We would like to acknowledge Don Kuramura, David Kosiba, John Studarus, David Lehman, and C. K. Prahalad at Praja and Edd Hunter, Patrick Kelly, Saied Moezzi, and Andy Tai at the Visual Computing Laboratory.