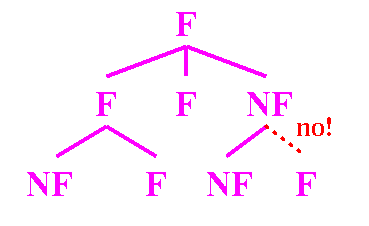
Leaves (URLs) are always NF
BO Algorithms
|
Traversal algorithm:
- While N the current node is not empty Do:
- If N's direct descendance has been modified:
- Find the nearest frozen ancestor, call it FA
- Apply the Frozen Node Algorithm to FA
- Let the new current node be FA's successor
in preorder traversal
- Else let the new current node be N's successor
in preorder traversal
|
|
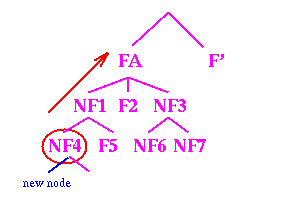
Frozen Node Algorithm
- For each child, C of FA do:
- If C is a leaf, Add C to a
document list DL
- If C is non-frozen, Collapse C's subtree and
Add all leaves to DL
- If C is frozen, Put it in a separate
list, FDL.
- Apply the Bookmark Clustering Algorithm on DL to form a new cluster hierarchy rooted at
a new node NEW-FA
- Apply the Frozen Node Algorithm
on all elements of FDL and add them as children of
NEW-FA
- Replace FA by NEW-FA
3. Cluster Analysis and Information Retrieval
Purpose of document clustering:
- primary use: "visualization of underlying structures of
explanation purposes"
- IR: efficiency and effectiveness of retrieval [Rasmussen 92]
Requirements:
- more informative
- more precise
Hierarchical Clustering
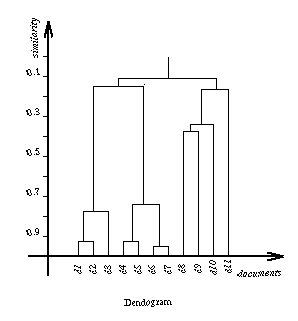
Typical cluster hierarchy (or dendogram)
- Start with a set of singleton clusters, each contains
one object (document)
- Repeat the following steps iteratively until there is
only one cluster
- Identify the two clusters that are the most similar
- Merge them together into a single cluster
Requires measure of similarity between documents' profiles
(Salton's vector space model)
Precise and Informative Clustering
- More precise:
Better measure of documents' profile similarity by using a less
ambiguous indexing unit: the lexical affinity (LA)
- More informative:
Associate to each cluster formed a list of key concepts
and a pseudo-title derived from the LA-based profiles
| single word |
norm. freq |
lexical affinity |
norm. freq |
| book | 0.399 | book softcopy | 0.346 |
| softcopy | 0.394 | cd rom | 0.336 |
| ibm | 0.343 | collection kit | 0.263 |
| library | 0.218 | ibm softcopy | 0.217 |
| cd | 0.161 | ibm library | 0.206 |
| rom | 0.154 | book library | 0.201 |
| bookmanager | 0.147 | ibm program | 0.191 |
| pc | 0.142 | library softcopy | 0.181 |
| bookshelf | 0.129 | bookmanager ibm | 0.170 |
| collection | 0.129 | book bookshelf | 0.165 |
| program | 0.127 | kit softcopy | 0.139 |
| kit | 0.127 | host system | 0.139 |
| information | 0.115 | collection softcopy | 0.134 |
| system | 0.100 | library program | 0.108 |
| host | 0.093 | library reader | 0.103 |
| product | 0.090 | book print | 0.103 |
| picture | 0.080 | cd softcopy | 0.098 |
Single word profile vs. LA profile for "IBM softocopy library package"
Controlling the size of the hierarchy
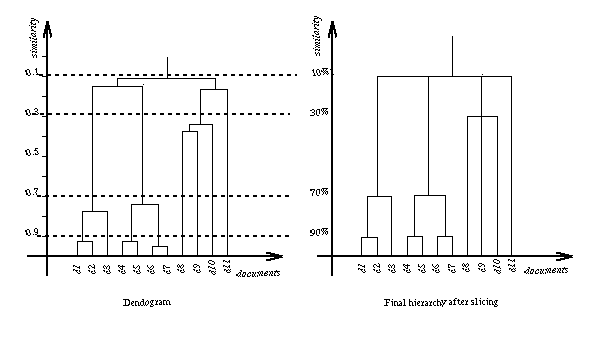
Slicing method
Enriching the hierarchy
Problem:
Cluster hierarchies are difficult to interpret (defined in extension,
rather than in intention).
We propose to add:
- Qualitative information
key concepts and pseudo-title expressed as LAs
- e.g.,
- (java,language)
- (application,development), (development, kit), (application
kit)
- Quantitative information
measure of intra-cluster similarity (expressed as %)
Bookmarks Clustering Algorithm
- For each URL in the collection, Access the source of the
corresponding HTML document
- Index each document and generate an LA-based profile
- Compute the pairwise similarity of all the documents
- Cluster by applying the HAC method in order to produce a
binary dendogram
- Collapse the dendogram into a
non-binary cluster hierarchy by applying the slicing technique
- Enrich the cluster hierarchy with conceptual information
4. A Typical Scenario
User w/ small bookmarks collection, gets interested in Java and
adds related sites
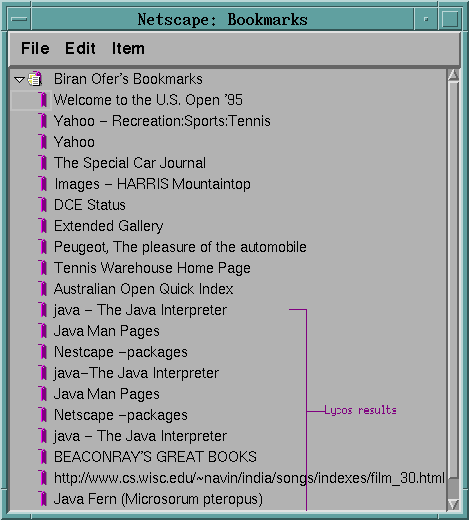
Typical Scenario: manual stage
User decides to get organized and creates two high-level folders
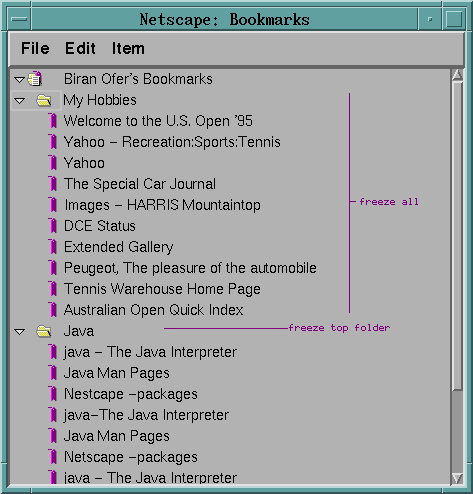
Typical Scenario: automatic stage
User decides to invoke BO, freezes the two high-level folders to
get Java-related URLs organized
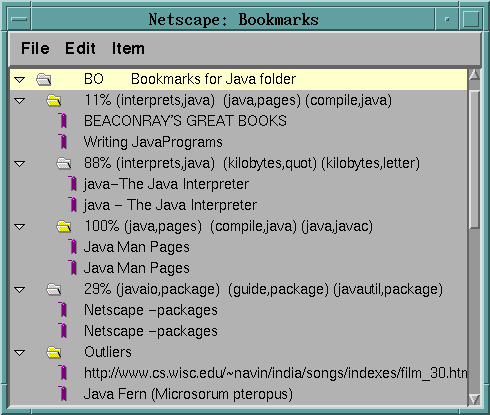
Implementation Notes
- BO is an external facility
- Typically invoked after several changes to the bookmark
repository
- Use checksum to discover new/moved/deleted URLs/folders
- Keep annotations (frozen and checksum status) inside
bookmark repository
- Implemented in C under AIX using Netscape Navigator 2.0
Bookmarks' format
5. Conclusion
- Hierarchical organization is useful, but only if documents are properly
classified
- Manual classification of URLs is difficult
- Automatic classification based on conceptual similarity
is a powerful browsing aid, but may be intrusive
- BO combines manual and automatic classification:
- Allow to protect prior manual classification
- Apply automatic classification selectively:
- Use Lexical Affinities as indexing unit
- Generate pseudo-titles
- Provide measure of similarity