May 6-10, 1996, Paris, France
Arun Katkere - Jennifer Schlenzig - Amarnath Gupta - Ramesh Jain
Contact email: katkere@ucsd.edu
Visual Computing Laboratory
University of California, San Diego
9500 Gilman Drive, Mail Code 0407
La Jolla, CA 92093-0407, USA
The WWW is evolving into a predominantly visual medium. The demand for access to images and video has been increasing rapidly. Interactive Video systems, which provide access to the content in video archives, are starting to emerge on the WWW. Partly due to the two-dimensional nature of the web, and partly due to the fact that images that comprise the video are two dimensional, most of these systems provide a VCR-like interface (play, fast-forward, reverse, etc., with additions like object selection, motion specification in the image space, and viewpoint selection). The basis of this paper is the realization that the video streams represent projections of a three-dimensional world, and the user is interested in this three-dimensional content and not the actual configuration of pixels in the image space. In this paper, we justify this intuition by enumerating the information-bearing entities that the user is interested in, and the information specification mechanisms that allow the user to query upon these entities. We will describe how such a intuitive system could be implemented using WWW technologies -- VRML, HTML, and HTTP -- and present our current WWW prototype which is based on extensions to some of these standards. This system is built on top of our multiple perspective interactive video (MPI Video) paradigm which provides a framework for the management of and interactive access to multiple streams of video data capturing different perspectives of related events.
In a very short time, the World Wide Web has emerged as the most powerful framework for locating and accessing remote, distributed information. A number of protocols and interfaces have been designed for each of the many different kinds of information. For navigational access to documents with text, images and references, the hypertext metaphor for information request has been most popular. While for database-style search, both keyword and forms-based interfaces have been developed and are essentially Web-extended (or HTML enhanced) versions of individual native database languages[1, 24]. For most applications, these different needs of information access and manipulation do not cross boundaries. Thus virtual reality users do not make information browsing queries and hypertext document surfers typically do not navigate in a three-dimensional world. But why not? A truly collaborative virtual work environment must allow users to access documents, and 3D visualization of schema would surely improve user-database interaction. The purpose of this paper is to advocate the use of three dimensional user interfaces as a means of accessing various types of data on the World Wide Web. Specifically we address these issues in the context of multiple perspective interactive video (MPI Video)[6, 9].
Currently, the popular interface to interactive video resembles a enhanced VCR interface which allows only brief, sporadic feedback from the user. This limited interaction provides no support for the purpose of querying a database beyond simple who queries. To achieve interactive video we must empower the user with the capability of manipulating the spatio-temporal content of the video. In addition, it is within the province of the interface to offer more than button clicks and mouse movements. Environments such as ALIVE and those that incorporate gesture understanding[17] will have the greatest potential as an interactive interface.
It is the paradigm of MPI Video, described in more detail in Section 2, which demands and in fact enables this level of interaction. More than just a collection of video streams, the MPI Video environment is a heterogeneous, distributed information structure. The primary source of information is a number of live video streams acquired from a set of cameras covering a closed environment such as a football game. This environment has a static component consisting of a model of the environment which resides on a server. The server also contains a library of possible dynamic objects that can appear in the environment. Multiple sensors capture the event and the system dynamically reconstructs a sequence of camera-independent three-dimensional scenes from the video streams using computer vision techniques[7]. In MPI Video the role of the user is to view and navigate in this world as the real-life event unfolds. While remaining in this world, the user may also request additional information on any static or dynamic object. Secondary information resources such as hyper-linked HTML documents, databases of static images, and ftp sites of reference archives are available to the system and may need to be accessed either to initiate a user query or as the result of a query.
In Section 3 of this paper we propose a set of information classes that can be formulated in the MPI Video environment. We demonstrate why without a three-dimensional interface the user would lose the potential expressive power required in this paradigm. In Section 4, we elaborate on our information exchange architecture and how it supports the current query specification interface. In Section 5 we conclude the paper with a discussion of our future work plan.
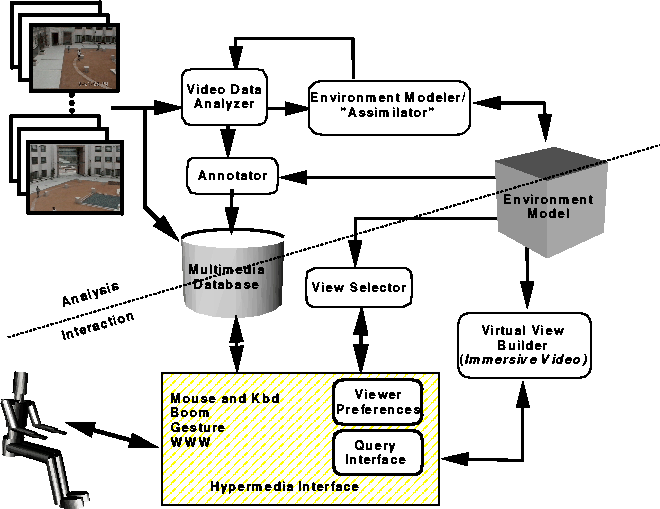
Figure 1: MPI Video System Architecture Overview
Multiple Perspective Interactive Video[6], MPI Video, provides a framework for the management of and interactive access to multiple streams of video data capturing different perspectives of related events[9]. MPI Video has dominant database and hypermedia components which allow a user to not only interact with live events but browse the underlying database for similar or related events or construct interesting queries.
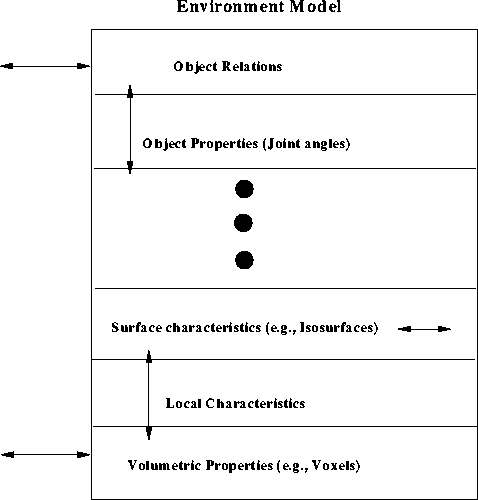
Figure 2: Different Layers of the environment model. Arrows indicate data
input either from other layers or from sensors.
The MPI Video architecture shown in Figure 1[6, 9] has the following components:
Three aspects central to this architecture are[9]:
In this paper, we describe an interface to MPI Video in which the user primarily interacts with the system using an intuitive three-dimensional metaphor[8]. A basic WWW system has been built using behavior-enhanced VRML (e.g., VRBS[13], the upcoming VRML 2.x standard, etc.), HTML forms, and CGI scripts. Extensions to some of these are suggested in order to achieve a functional interactive video interface on the WWW.
An important component of an MPI Video system is the Environment Model, a coherent, dynamic, multi-layered, three-dimensional representation of the content in the video streams (Figure 2[7]). It is this view-independent, task-dependent model that bridges the gap between two-dimensional image arrays which by themselves have no meaning and the complex information requirements placed by users and other components on the system.
The transformation of video data into objects in the environment model has been an ill-posed and difficult problem to solve. With the extra information provided by the multiple perspective video data, and with certain realistic assumptions (that hold in a large class of applications), however, it is possible to construct accurate models in a robust and quick fashion. In our current MPI Video systems, we make the following assumptions[8]:
In addition, we use the following sources of information extensively:
Expressiveness of interaction is fundamental to the design of any user interface model. This expressiveness can be achieved by using an information visualization metaphor as used by several database browsing and visualization groups[3]. Our motivation for developing a three-dimensional interface for MPI Video stems from the intuition that if is user is given a three-dimensional world changing dynamically with time, he or she would meaningfully operate in this world (i.e., can specify an object, or a space, or a search condition) only when he or she has the ability to navigate and act in it.
Intuitively, a three-dimensional interface would be extremely useful because:
To substantiate this intuition, let us first specify the information-bearing entities in MPI Video.
Raw video can also be used for directed searching for some information that is not already extracted from the video. For instance, the system cannot be expected to have readily available information to answer an atypical query such as ``what is the dominant color of clothing among the crowd in the east side of the field?''. The querying client could apply this directed searching criterion to the raw video to obtained desired results.
Next, let us explore what operations need to be performed in the World Wide Web to define, update and manipulate the above information categories. The interface needs to allow:
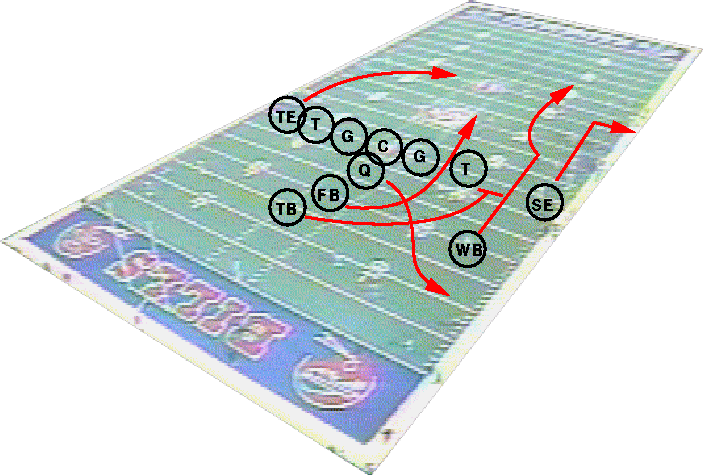
Figure 3: Queries about entities such as plays are best described from a
camera independent perspective
For a large number of users to access MPI Video archives, in addition to being intuitive and easy to use, the interface has to be widely accessible. In this section, we will describe how we can accomplish the user interactions described in Section 3 using the existing WWW protocols (such as HTTP) and languages (such as HTML, VRML, Java). With languages such as VRML and Java in a nascent stage, some enhancements are needed to implement even a rudimentary system. Wherever possible, our current implementations and proposed systems are based upon expected language enhancements.
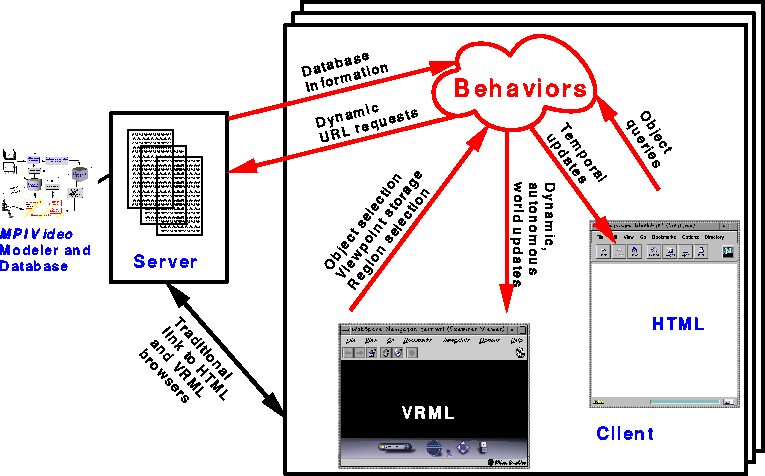
Figure 4: Schematic of MPI Video interface showing the video data streams and
the remote server, and the interface at the local user site. The local
interface uses a HTML browser for initiating form-based queries and
displaying text and image based system information, and a VRML browser
for interacting with a three dimensional dynamic model of the underlying
video data. Interactions between the different components are also shown.
The client side is made dynamic and intelligent using
behaviors.
Figure 4 shows schematically the various components of a WWW-based MPI Video system and some interactions between the components. To implement such a WWW-based MPI Video system, we need technologies for:
Unfortunately, the current WWW technology is designed to present and provide rudimentary interactions with two dimensional layouts. While this has proven to be sufficient for most of the current set of WWW-based interactive video and video database systems[23, 19], our user information specification paradigm, which allows the users to interact with the system at a content level instead of at the data level, cannot be easily implemented with this technology.
VRML[14], which is being designed primarily for multiuser interactions (``a scalable, fully interactive cyberspace''[15] such as Stephenson's Metaverse[20]), is currently usable as a way of presenting static 3D content on WWW. For our current implementations, we use a behavior-enhanced VRML prototype, VRBS[13] to present dynamic 3D content as well as provide rudimentary 3D interactions. Because this implementation uses VRBS[13], a experimental VRML behavior system that is not widely used, we cannot make it available on the WWW for wide accessibility until it is reimplemented using VRML 2.0 in a few months. At the time of writing, standardization of behaviors in VRML is underway, and the features we need to provide complex user interactions are being discussed (e.g, Moving Worlds proposal[18]).
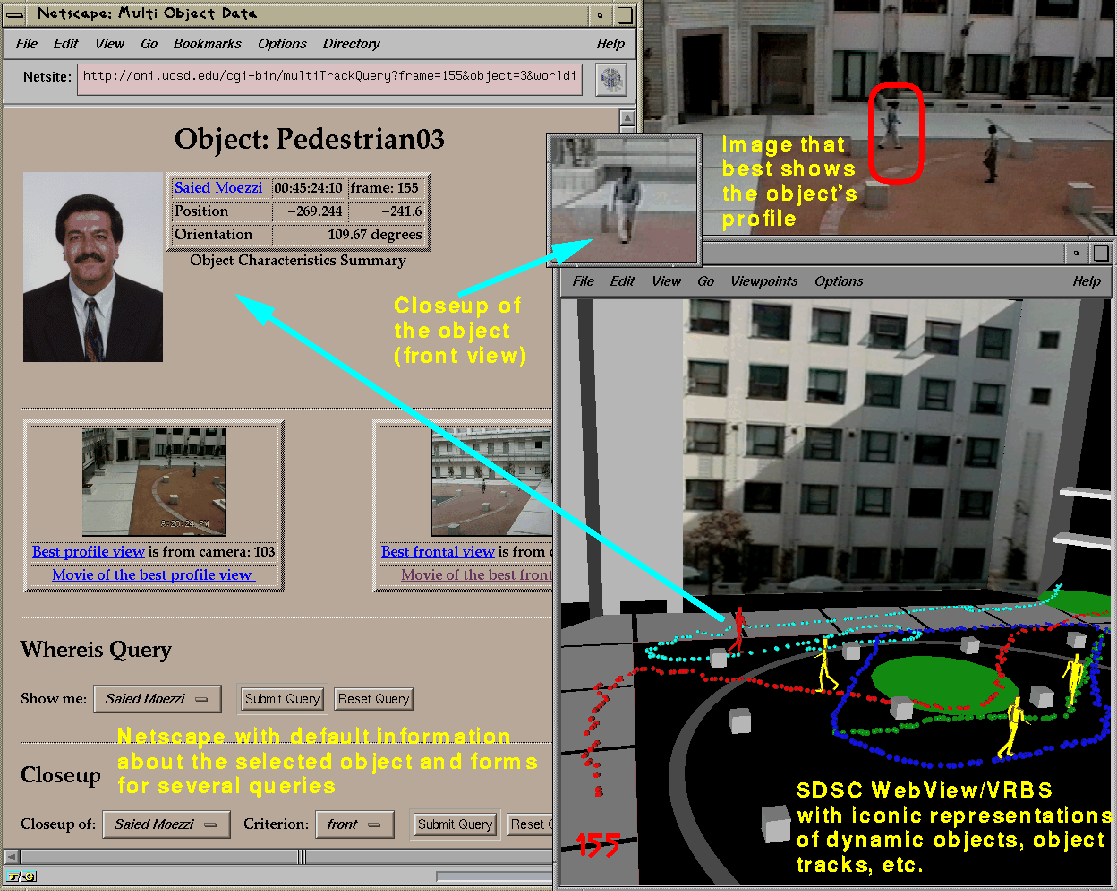
Figure 5: Snapshot of an MPI Video WWW interface prototype showing
dynamic models based on live events in a 3D (VRML) browser, a set of
associated queries in an HTML browser and results of some queries.
Figure 5 shows a sample session at a client (user) site which uses the VRML browser, the HTML browser, and other applications[8]. The information is presented using the VRML browser, with interesting dynamic and static portions of the scene hyper-linked to either related VRML worlds or HTML query forms.
For the session shown in Figure 5, we used a campus courtyard with pedestrians covered with six video-resolution cameras. The video sequence was digitized at 10 frames per second and processed by the MPI Video modeling system. (A Quicktime video segment is available). The dynamic objects in the environment were detected and tracked to create a database of object ids, object locations, video clips, and related information built using flat files and dbm files.
Interface to this database is at two levels: via CGI scripts that interact with the underlying database, and via the VRML and HTML browsers that construct queries based on user input. All context information required to answer these queries is encoded as parameters to the CGI programs. Currently, the server answers all queries. As we will discuss in the Section 4.3, since information about objects, their locations, and their structure is continuously sent to each client, the client has the necessary information to answer a large class of queries without going to the server.
Using a combination of VRML and HTML browsers, the current system handles several types of queries:
Instead of selecting from a small number of real camera perspectives, a generalization of this query[7] would be to combine the virtual camera concept of Immersive Video[12] with an unconstrained or loosely constrained best-view criterion. Two examples of this type of query would be: show me this play from a panoramic point[25], and show me this play from the viewpoint of Player Z.
To handle these queries, two client-side behaviors are implemented:
While the prototype described above is useful in testing all forms of communication -- server and VRML browser, server and VRML behaviors, VRML behaviors and browser, server and HTML browser, VRML browser and HTML browser, etc. -- it contained only limited user interaction in 3D: viewpoint control and object selection. Even with the other queries being handled using HTML forms, this prototype is a significant step forward towards intuitive interactive video interfaces. To further advance the interface, we need to handle the types of user interactions described in Section 3.2 using VRML. The discussion in this section is based on the current version of one of the VRML 2.0 proposals[18]. We can safely assume that the VRML 2.0 standard will provide similar functionality.
A toolkit of editable basic shapes (such as lines, cubes, cylinders) is used to define paths, regions, and volumes of interest and to construct query objects. With a version of VRML that supports scripting, it is possible to implement a simple object construction suite. A more interesting question is how these are associated with queries. For example, if a user wants to ask the system ``did anybody come here, the user's definition of here has to be somehow associated with the form where the query is being constructed. A somewhat circuitous but feasible method is to ask the user to label each object she creates and to use the same label as parameters to queries. A more elegant solution is to allow the user to drag and drop objects. This requires the browsers to espouse a standard such as OpenDoc[16] or different browsers to be integrated.
WWW is currently based on a client-server model[4]. A MPI Video system could be implemented in this framework. Our current prototypes use this model of interaction. When the system is to be accessed by a large number of users, especially in a live-event scenario, several problems arise: the load on the server increases as the number of querying clients increases, the problem of handling user's context information using a protocol free of context such as HTTP becomes more difficult, appreciable delay in the query response is counterproductive.
In our case, since the server is already sending the clients information about object position and structure continuously, if each client caches this information and has intelligence to answer frequently asked queries by itself, the load on the server will be reduced. The response to the query in this case is faster than the case where the client has to forward the query to the server and wait for a response. The user's context in this case is stored at the client, and this information is passed when necessary to the server. This model raises two key issues: specifying client side intelligence, and determining the default environment model entities that are sent to a client at every time instant so that most queries are handled by the client.
Client-side intelligence is specified using a safe language such as Java. Typically this is the same language as the one used for scripting behaviors in VRML. Because we do not want to send a general-purpose query handling engine to each client, to a certain extent, the client-side query handling logic is domain dependent. Determining the default environment model is a much harder problem. This is highly domain dependent. For example, the frequently queried upon entities in a football game are not the same as the entities queries upon in a interactive drama. An interesting strategy the could be followed is to start with a minimal default set, with minimal client query handling, and to incrementally enhance both based on server access statistics. How this is exactly achieved is currently being investigated.
If we have the client-side functionality described above, for live events, incremental updates to the default environment model may be multicast to the clients. This approach reduces the load on the server and engenders scalability. In this scenario, a new client joining the multicast session contacts the server (a nearby server in case of multiple servers) to download the current environment model and a default context. Alternatively, the client may choose to download the environment model and the context from a nearby ``friend''. After this bootstrapping, the client may monitor the current state by listening to the multicast channel for environment model updates. When the user queries, the client first checks its local environment model to check if it could answer the query locally. If the design of the system is correct, the information will be available locally most of the times. Queries that cannot be handled will be passed off to the server. The client may chose to augment its environment model with the results of this query.
This approach can be extended to handle clients (and networks) with different capabilities. Environment model, shown in Figure 2, is made up of easily decomposable layers. Hence, akin to the layered video concept of MBONE[10], we can multicast the environment model on several channels. Based on the client's capabilities (whether it can handle 10k polygons per second or a 4-joint articulated model) or the network bandwidth, the client can choose to listen to a subset of available channels.
Information in the MPI Video paradigm is shared using the environment model. How can this information be exchanged on the WWW? VRML, which is convenient for representing graphical entities is a good start for this. In addition, we need the ability to represent multi-modal information seamlessly, both in the continuous and discrete domain (``all media are equal''[11]). We also should be able to add semantics into the environment model which establishes links between different entities in the environment (e.g., this set of polygons is Person A's left hand).
Another issue is the decoding and the encoding of the environment model. In a WWW-based scenario, the server should spend time on the creation of the environment model if this helps the client in transforming the environment model into usable information faster. For instance, several higher-level entities in the environment model are deducible from the voxels that represent occupancy. But, from a WWW perspective, it is more efficient to compute these higher-level entities at the server.
Video is spatio-temporal data. To fully access the available information we must move beyond the preconceived notions of the VCR interface and keep in mind that: